 UPDF for Windows
UPDF for Windows UPDF for Mac
UPDF for Mac UPDF for iPhone/iPad
UPDF for iPhone/iPad UPDF for Android
UPDF for Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Edit PDF
Edit PDF Annotate PDF
Annotate PDF Create PDF
Create PDF PDF Form
PDF Form Edit links
Edit links Convert PDF
Convert PDF OCR
OCR PDF to Word
PDF to Word PDF to Image
PDF to Image PDF to Excel
PDF to Excel Organize PDF
Organize PDF Merge PDF
Merge PDF Split PDF
Split PDF Crop PDF
Crop PDF Rotate PDF
Rotate PDF Protect PDF
Protect PDF Sign PDF
Sign PDF Redact PDF
Redact PDF Sanitize PDF
Sanitize PDF Remove Security
Remove Security Read PDF
Read PDF UPDF Cloud
UPDF Cloud Compress PDF
Compress PDF Print PDF
Print PDF Batch Process
Batch Process About UPDF AI
About UPDF AI UPDF AI Solutions
UPDF AI Solutions AI User Guide
AI User Guide FAQ about UPDF AI
FAQ about UPDF AI Summarize PDF
Summarize PDF Translate PDF
Translate PDF Chat with PDF
Chat with PDF Chat with AI
Chat with AI Chat with image
Chat with image PDF to Mind Map
PDF to Mind Map Explain PDF
Explain PDF PDF AI Tools
PDF AI Tools Image AI Tools
Image AI Tools AI Chat Tools
AI Chat Tools AI Writing Tools
AI Writing Tools AI Study Tools
AI Study Tools AI Working Tools
AI Working Tools Other AI Tools
Other AI Tools AI Bookmark Generation
AI Bookmark Generation AI Bookmark Summary
AI Bookmark Summary AI Watermark Generation
AI Watermark Generation AI Background Generation
AI Background Generation AI Sticker Generation
AI Sticker Generation AI Stamp Generation
AI Stamp Generation AI Editing Suite
AI Editing Suite UPDF Copilot
UPDF Copilot AI Page Management
AI Page Management AI Semantic Search
AI Semantic Search PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF to PowerPoint
PDF to PowerPoint User Guide
User Guide UPDF Tricks
UPDF Tricks FAQs
FAQs UPDF Reviews
UPDF Reviews Download Center
Download Center Blog
Blog Newsroom
Newsroom Tech Spec
Tech Spec Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
OCR PDF with UPDF on Mac
OCR feature in UPDF for Mac allows you to convert scanned or image-only PDF documents into searchable and editable documents. Moreover, it allows you to convert your searchable and editable PDF to image only. You can click the below button to download UPDF on Mac and follow the steps below to learn how to use it.
Now, we'll guide you through using UPDF OCR feature on Mac.
Windows • macOS • iOS • Android 100% secure
Step 1. Download and Install OCR (For New Users Only)
If you are the first user to use this tool, you need to download OCR plugin in UPDF. For this, navigate to the Tools option from the top left side and choose OCR option under Edit PDF section.
- Continue the process by clicking the Install button in the pop-up window.
- You will be automatically redirected to the next window, which will display the installation progress of the feature. Let the feature install successfully on your Mac device before using it.
Step 2. OCR PDF With UPDF for Mac
After installation, close the window, navigate to the same Tools option, and press the OCR option from the menu.
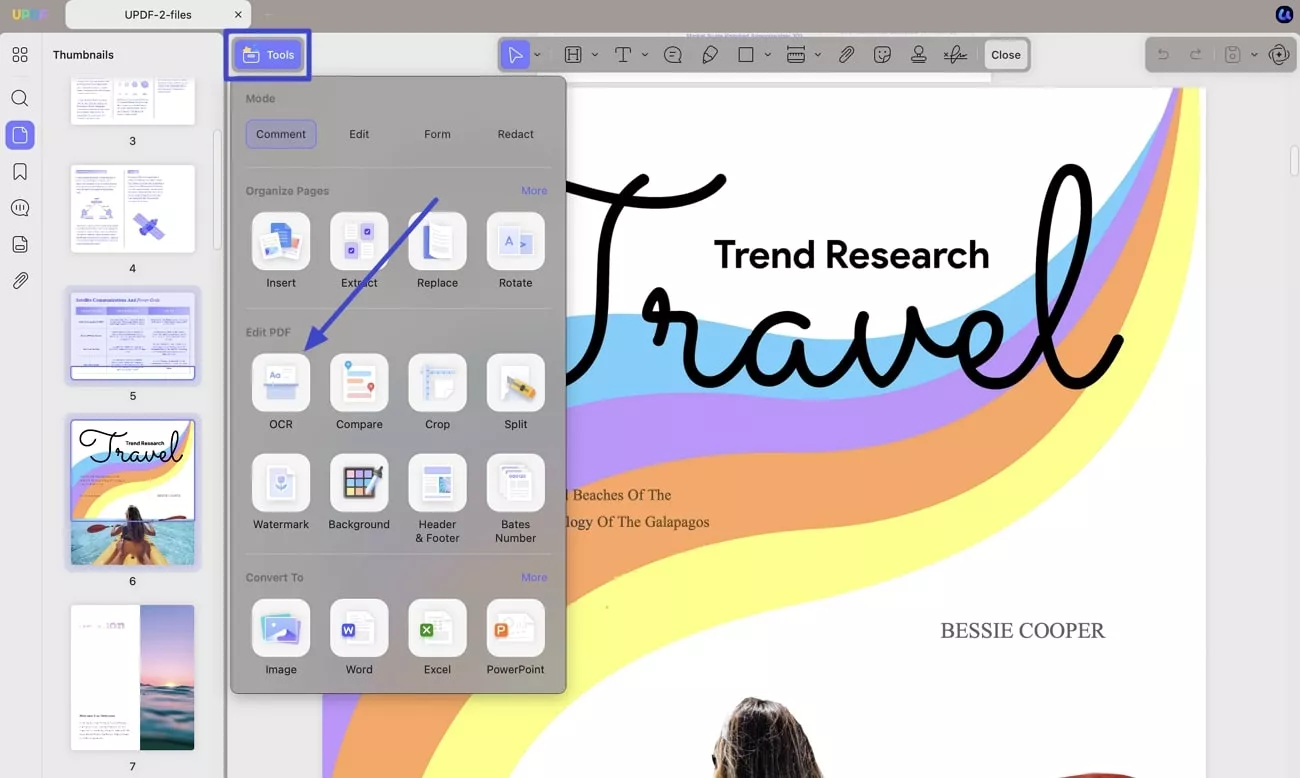
Following this, a new window will open, providing you with 3 options for Document Type.
1. Editable PDF (Dual Layer OCR)
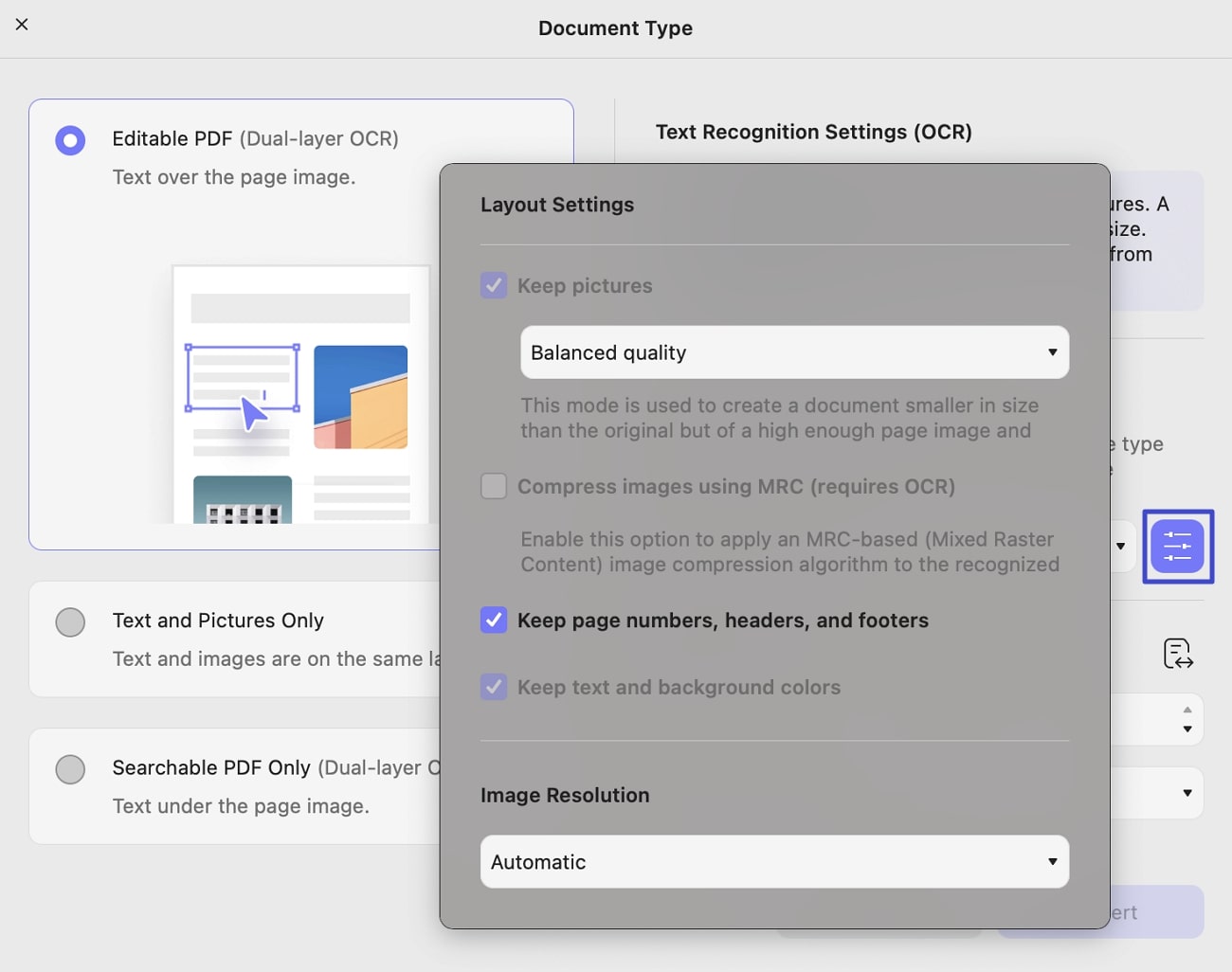
When you choose this mode for OCR, it saves the recognized text and pictures, which are slightly different from the original document. However, before performing OCR, you can set the properties as shown in the image and discussed briefly.
- Layout Settings: In the Layout settings window, you can adjust the quality with options including Balanced Quality, High Quality, and Low Quality for keeping the images.
It provides options to check Compress images using MRC, Keep page numbers, headers, and footers, or Keep text and background colors.
Besides this, you can improve the Image Resolution from Automatic, 300,150, and 72 DPI.
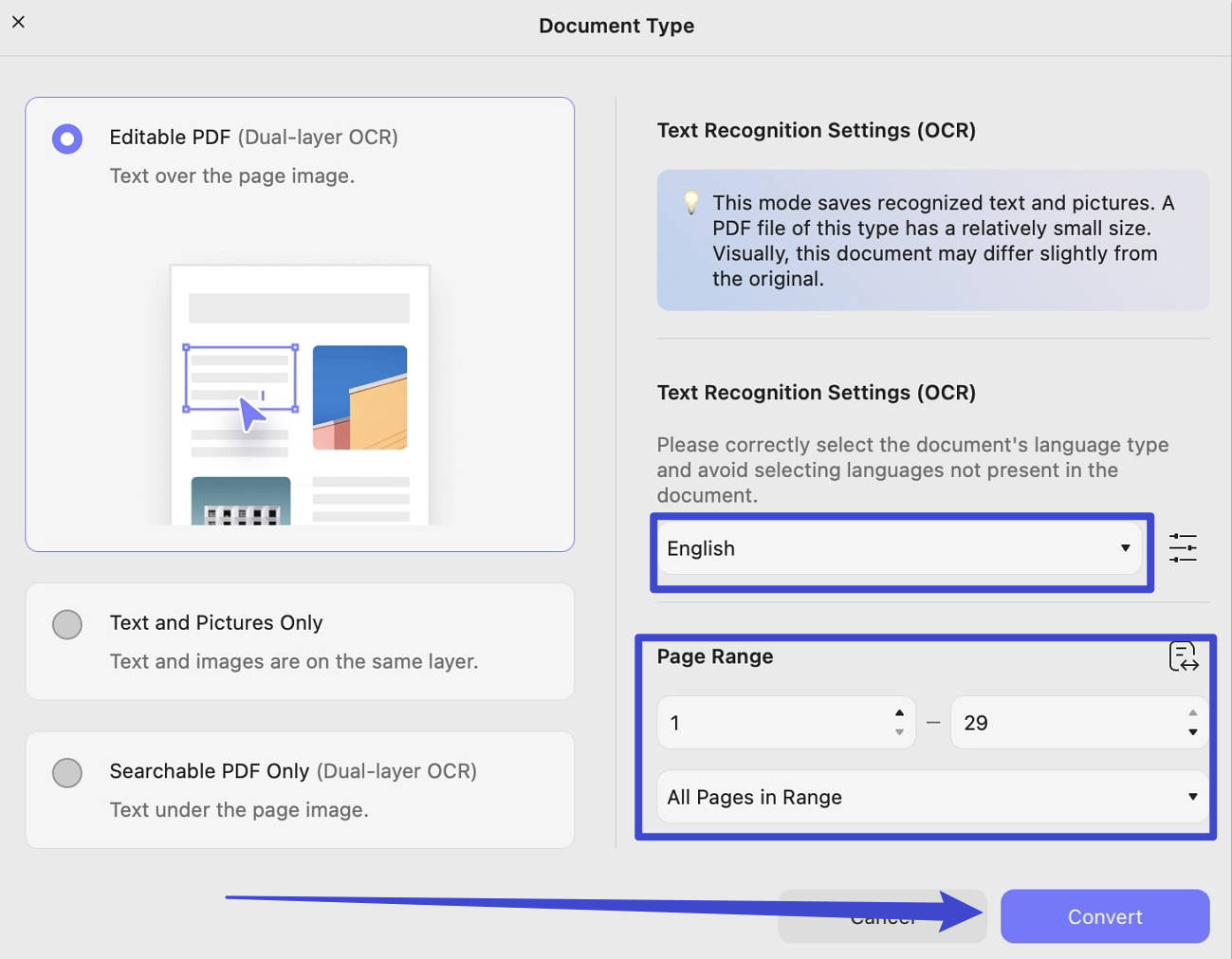
- Document Language: UPDF provides 38 languages for you to select before OCR.
- Page Range: With this option, you can either manually choose the page range or access options for All Pages, Even and Odd Pages.
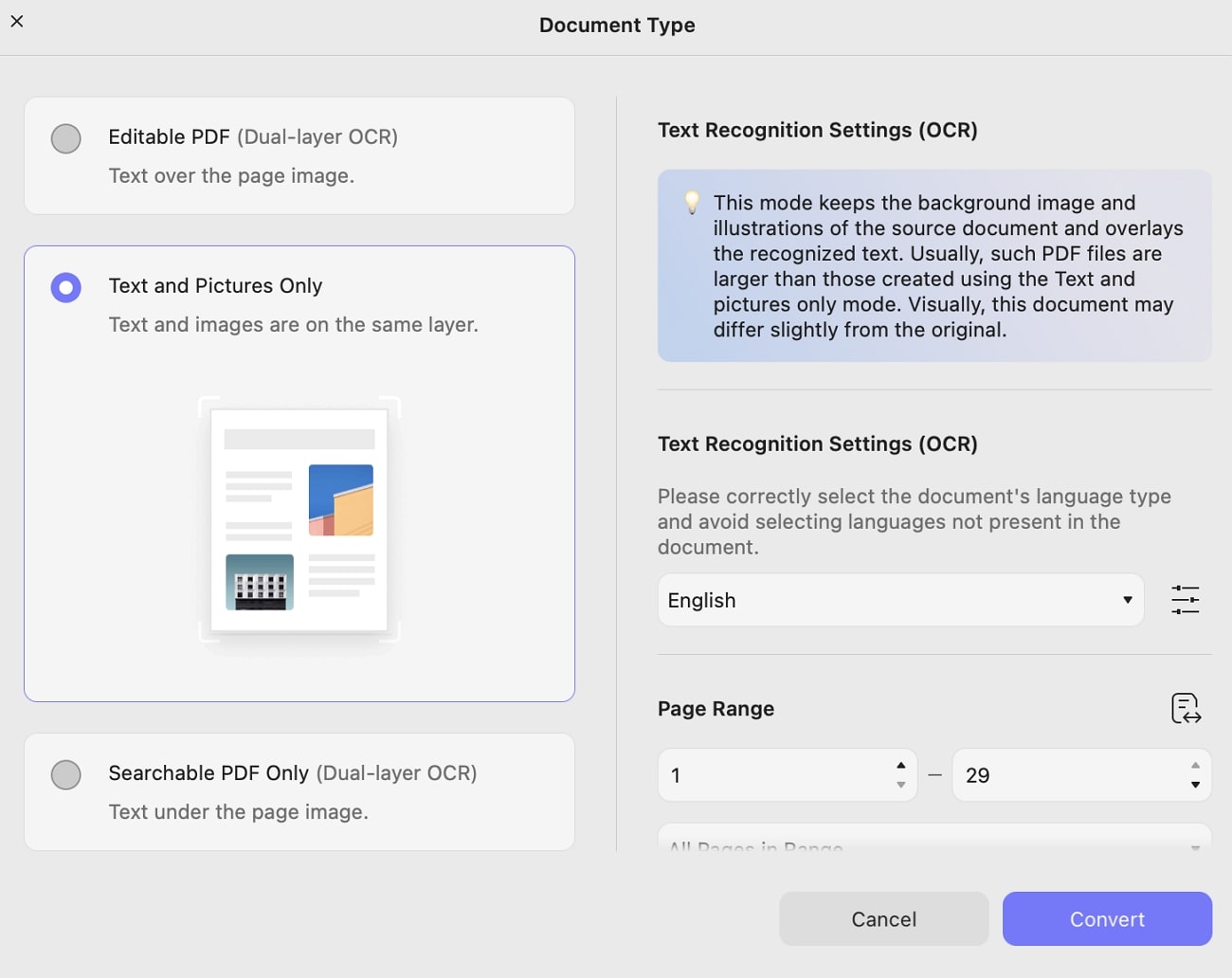
2. Text and Picture Only
This mode stores your document’s background image and illustrations of the source document and overlays the recognized text. To set properties before OCR, you need to review the screenshot below. However, it offers similar document settings to those discussed for Editable PDF.
3. Searchable PDF Only (Dual Layer OCR)
In this mode, the page image is retained, whereas the recognized text is placed into an invisible layer underneath the image. Additionally, this type of document is nearly identical to the original one. When Layout settings and other properties are concerned, draw your attention to the provided screenshot:
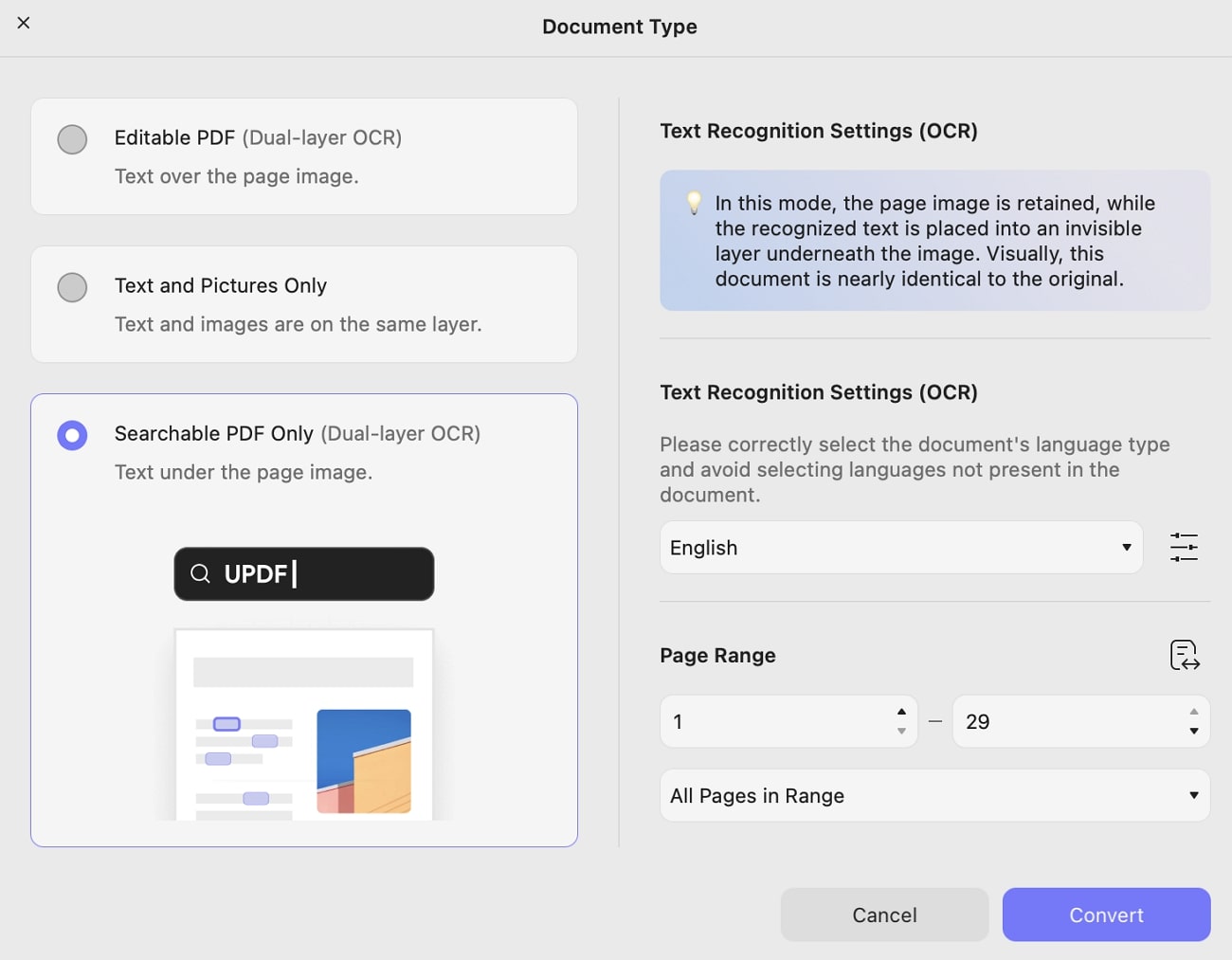
When you finished setting, you can click on the Convert button to select where you want to save the OCRed PDF. Once the process is done, the OCRed PDF will open automatically in UPDF. Now you can click on the Edit PDF to make changes or click on the Save icon to save it on your device after making changes.
You can experience the OCR in the free trial version. And if you are satisfied with it, you can upgrade to the pro version by clicking here with a big discount.