 UPDF for Windows
UPDF for Windows UPDF for Mac
UPDF for Mac UPDF for iPhone/iPad
UPDF for iPhone/iPad UPDF for Android
UPDF for Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Edit PDF
Edit PDF Annotate PDF
Annotate PDF Create PDF
Create PDF PDF Form
PDF Form Edit links
Edit links Convert PDF
Convert PDF OCR
OCR PDF to Word
PDF to Word PDF to Image
PDF to Image PDF to Excel
PDF to Excel Organize PDF
Organize PDF Merge PDF
Merge PDF Split PDF
Split PDF Crop PDF
Crop PDF Rotate PDF
Rotate PDF Protect PDF
Protect PDF Sign PDF
Sign PDF Redact PDF
Redact PDF Sanitize PDF
Sanitize PDF Remove Security
Remove Security Read PDF
Read PDF UPDF Cloud
UPDF Cloud Compress PDF
Compress PDF Print PDF
Print PDF Batch Process
Batch Process About UPDF AI
About UPDF AI UPDF AI Solutions
UPDF AI Solutions AI User Guide
AI User Guide FAQ about UPDF AI
FAQ about UPDF AI Summarize PDF
Summarize PDF Translate PDF
Translate PDF Chat with PDF
Chat with PDF Chat with AI
Chat with AI Chat with image
Chat with image PDF to Mind Map
PDF to Mind Map Explain PDF
Explain PDF PDF AI Tools
PDF AI Tools Image AI Tools
Image AI Tools AI Chat Tools
AI Chat Tools AI Writing Tools
AI Writing Tools AI Study Tools
AI Study Tools AI Working Tools
AI Working Tools Other AI Tools
Other AI Tools AI Bookmark Generation
AI Bookmark Generation AI Bookmark Summary
AI Bookmark Summary AI Watermark Generation
AI Watermark Generation AI Background Generation
AI Background Generation AI Sticker Generation
AI Sticker Generation AI Stamp Generation
AI Stamp Generation AI Editing Suite
AI Editing Suite UPDF Copilot
UPDF Copilot AI Page Management
AI Page Management AI Semantic Search
AI Semantic Search PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF to PowerPoint
PDF to PowerPoint User Guide
User Guide UPDF Tricks
UPDF Tricks FAQs
FAQs UPDF Reviews
UPDF Reviews Download Center
Download Center Blog
Blog Newsroom
Newsroom Tech Spec
Tech Spec Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
How do you convert a scanned PDF to Word format to make it editable in Microsoft software? Converting a scanned or non-editable PDF file requires a special process called OCR or optical character recognition. Once you've processed your document using OCR, you can proceed to convert the PDF into a Word file. There are a few different ways to do this, but in this article, we'll show you the most effective and convenient ways to convert scanned PDFs to Word.
How to Convert One Scanned PDF to Editable Word on Windows, Mac, Android, and iOS
With support for over 38 OCR languages, UPDF is definitely one of the most versatile and powerful scanned PDF to Word conversion tools you'll find for Windows, Mac, Android, and iOS.
Remember: converting a scanned document with OCR requires a great deal of accuracy, and UPDF uses a powerful OCR feature for its conversions. The final output will be a PDF document with the same layout and formatting as the original document. Download it now to begin. In addition, you can select specific pages in a scanned PDF and convert them to a Word file.

In summary, converting a scanned PDF to a Word file is a quick and straightforward process with UPDF, requiring just a few simple steps. Follow the instructions below:
On Desktop
- Just download UPDF via the button below to your computer.
Windows • macOS • iOS • Android 100% secure
- Open the scanned PDF by dragging and dropping it to the UPDF home interface.
- Click on the "Tools" and choose "Word" in the "PDF Converter" section.
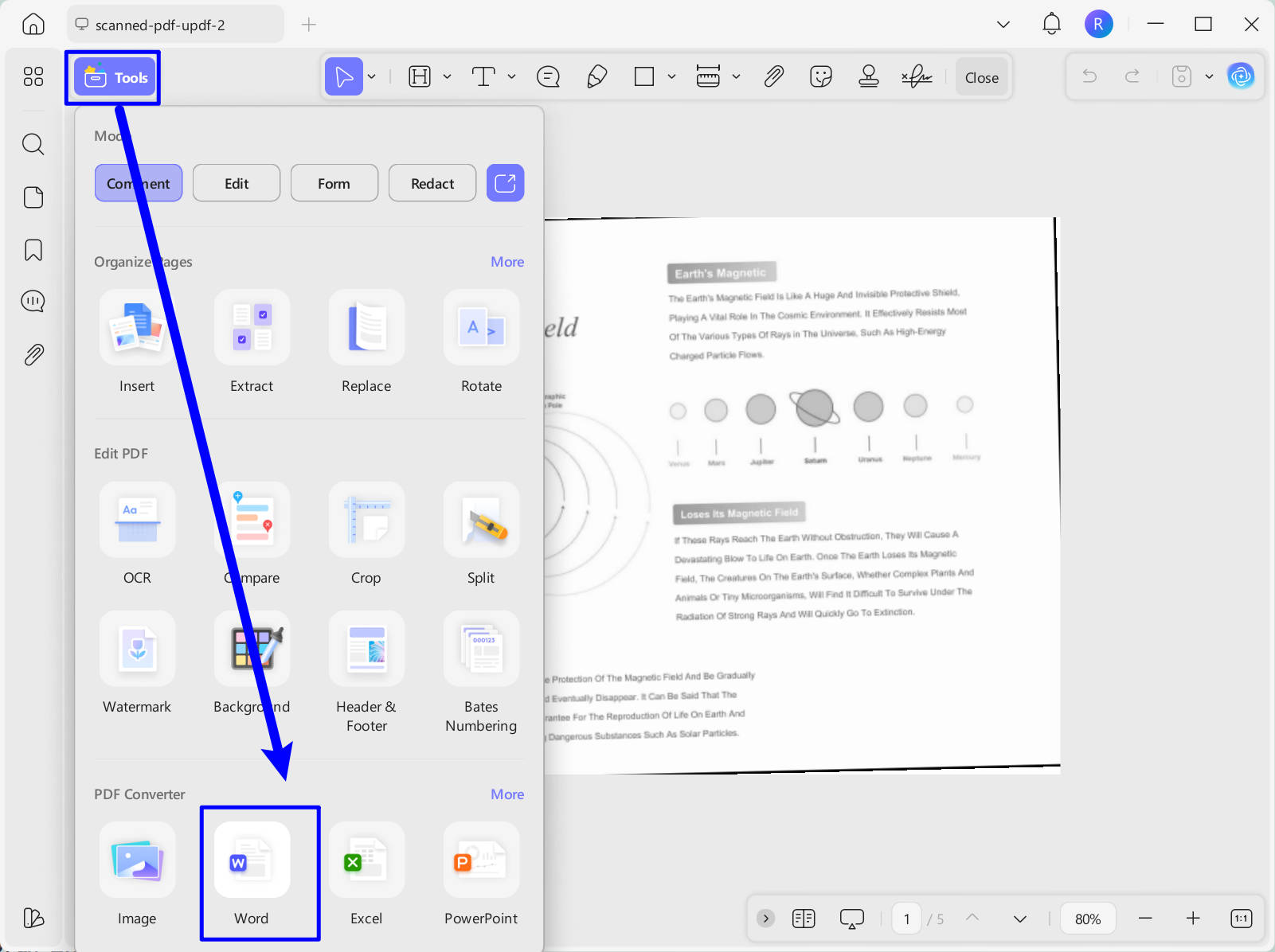
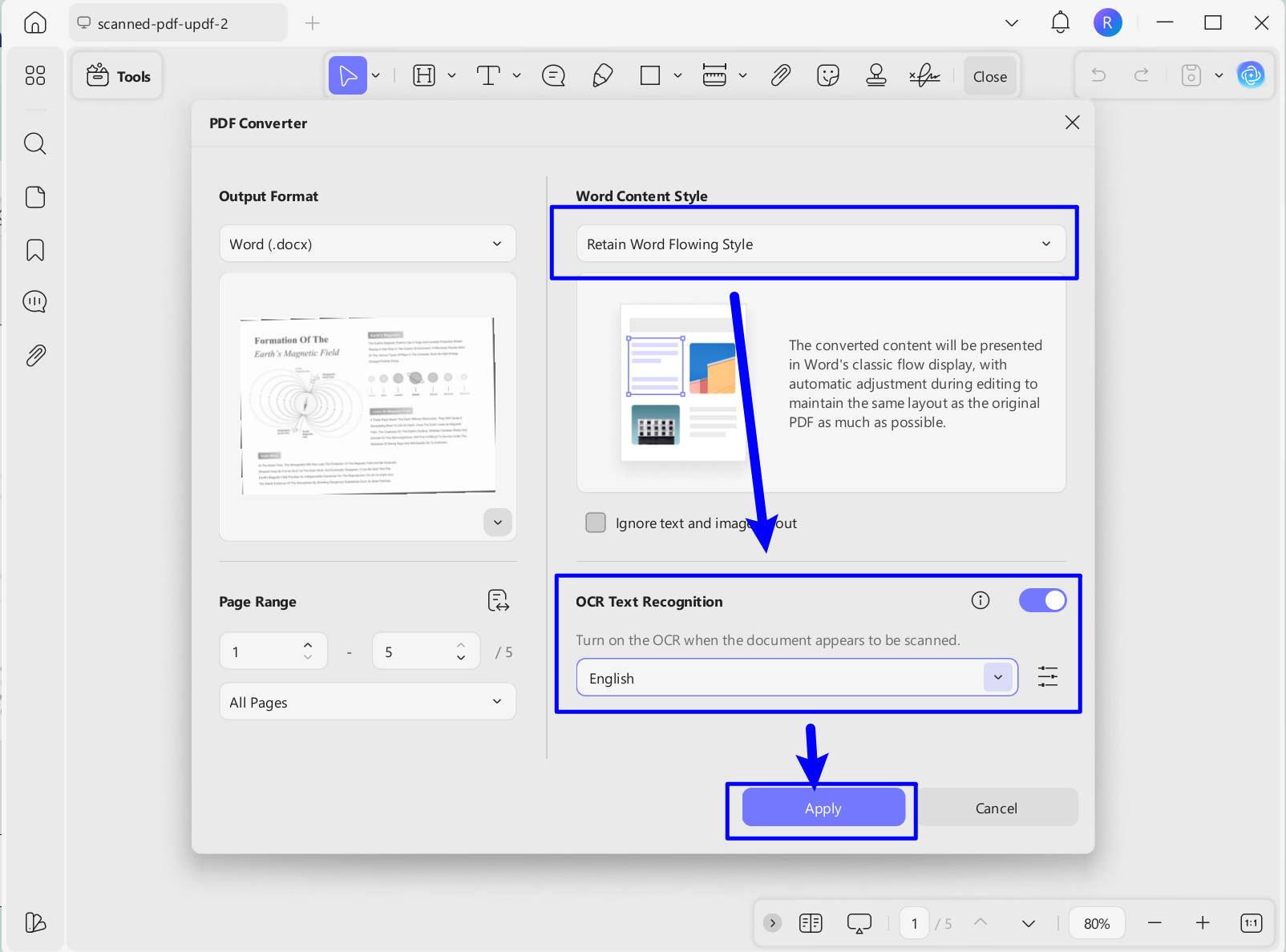
- Choose the Word Content Style you need, enable the OCR, choose the document language you need, and click on the "Apply" to convert the scanned PDF to editable Word.
- Now, go to open the editable Word with Microsoft Word.
On Mobile
- Search and download UPDF for iOS from the App Store or UPDF for Android from the Play Store.
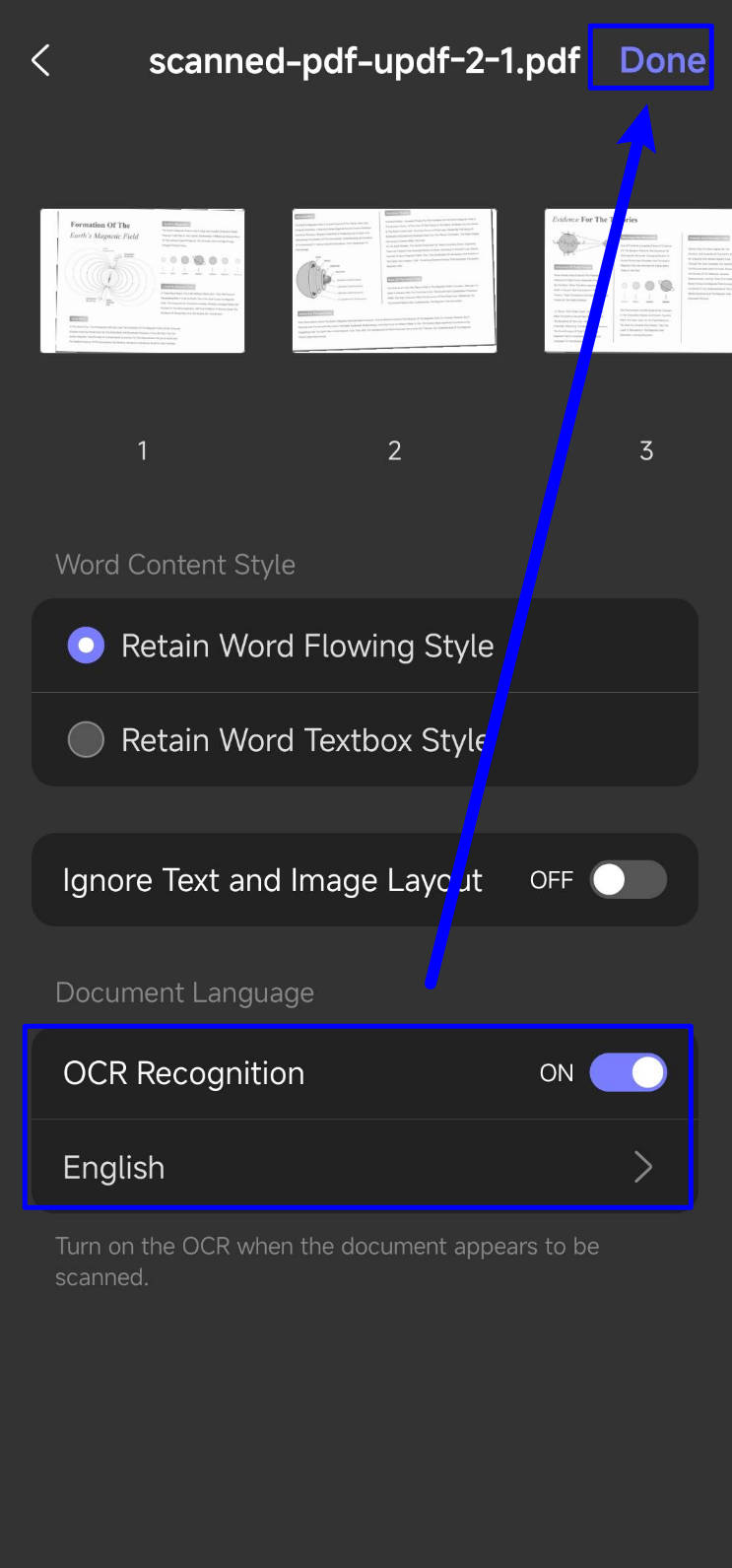
- Tap on the "Tools" > "PDF to Word".
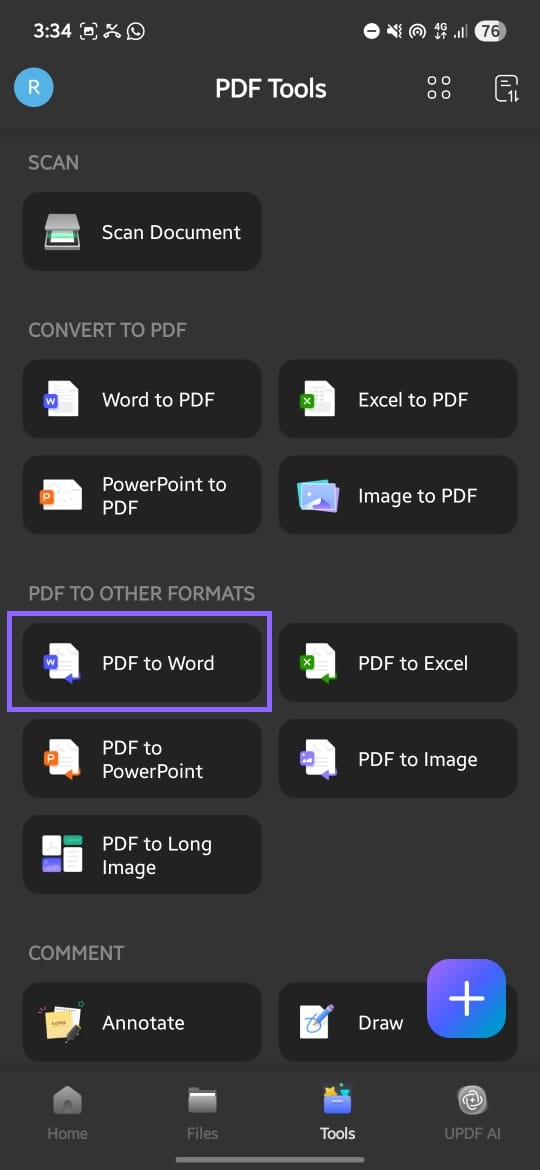
- Make sure "OCR Recognition" is enabled. Choose the output language. Here, my document is in English. I chose "English". Tap on the "Done" to start converting scanned PDF to editable Word. Tap on the "Save" to save the editable Word.
For more detailed guide, you can watch the video below.
Having mastered the conversion of scanned PDFs, let's now uncover more powerful features within UPDF.
- Dedicated PDF conversion tool that supports many common output formats such as Word, Excel, PPT, image formats, HTML, XML, Text, and RTF.
- OCR function to convert scanned PDF to editable Word format.
- The format is kept consistent during conversions - minimal manual correction is required.
- All-in-one solution. It also allows you to edit PDF documents, comment on PDF documents, protect PDF documents, etc.
- UPDF AI features to help you summarize, translate, and explain PDF documents in seconds!
Ready to take your experience to the next level? Upgrade to UPDF Pro for exclusive access to premium features. Discover the difference and revolutionize your PDF workflow. And to know more about UPDF, you can read this review article.
How to Batch Convert Scanned PDF to Word with UPDF?
The methods mentioned above are for a single scanned PDF. What if you have mass scanned PDF files and want to convert them into editable Word at once? No worry, UPDF understands you. Download UPDF via the button below now and follow the guide below to convert scanned PDF files to Word in bulk.
Windows • macOS • iOS • Android 100% secure
Step 1. Run UPDF on your computer, tap on the "Tools" > "Convert".
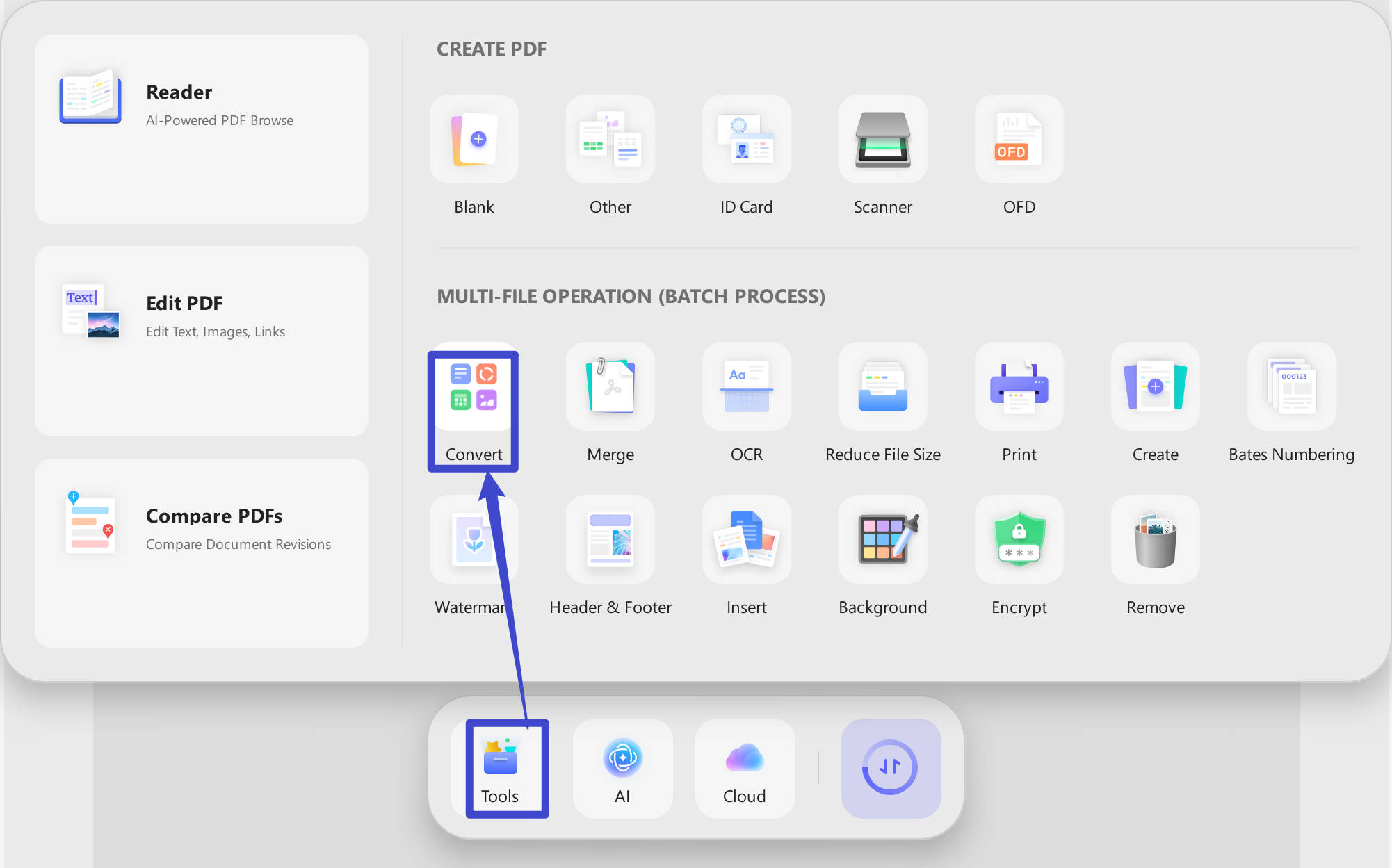
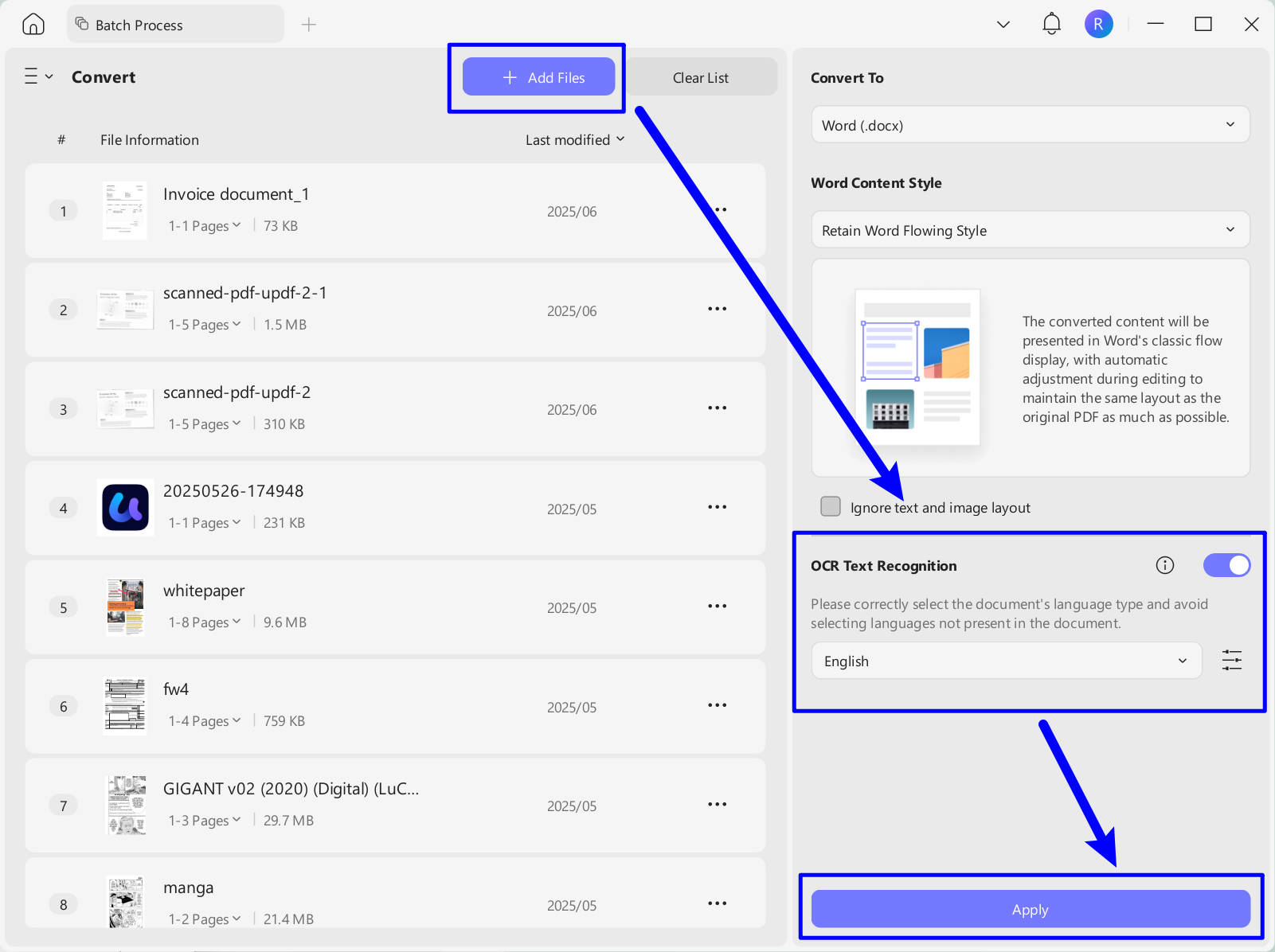
Step 2. Click on the "Add Files" to select all the scanned PDF files, enable the "OCR Text Recognition", choose the document language, and click on the "Apply" to convert scanned PDF to editable Word.
What Are Some Common Issues with Converting Scanned PDF Files to Word?
In general, the OCR engine can convert most scanned PDF files. However, not all scanned files are made equal. First and foremost, if you are working with scanned files, ensure that you have enabled the OCR option in the program.
Before opening and converting a scanned file, go to OCR settings and select Convert using OCR. If the file does not convert, this could be the cause: the gap between the characters in the document is too close, and the OCR cannot detect each character.
The poor image quality of the scanned document, a mix of fonts used in the scanned documents, and italicized and underlined typefaces, all of which can muddy the clarity and shape of the individual characters, are all issues that can impair the OCR result. As a result, confirming that the character "recognized" by the OCR software corresponds to the character on the scanned paper is much more challenging.
Most importantly, you should know that, with UPDF OCR, you don't need to worry about any of these issues as it will give you the perfect results and accuracy. Try it now.
Windows • macOS • iOS • Android 100% secure
FAQs about Converting Scanned PDF to Word
Q1. What is OCR (Optical Character Recognition)?
OCR, or optical character recognition, is the process of converting a text image into machine-readable text. Scanned forms and receipts are often saved as image files, limiting their utility in text editors. With OCR, these images can be transformed into editable text documents. In business workflows, dealing with printed materials like forms, invoices, and contracts can be time-consuming. Digitizing these documents often results in image files, which OCR technology converts into data usable by various business applications. This streamlined process facilitates analytics, operational efficiency, and productivity enhancement.
Q2. What is a Scanned PDF?
A PDF document can be created by scanning a paper document into an electronic version. This is performed by selecting a scanner or a similar machine that captures an image of a paper document and saves it as an electronic PDF file. When a scanner makes this scanned image, it does not replicate each character of every word. It only takes a "snapshot" of the paper document. The software provided with the scanner then converts the photo into a PDF document. As a result, a "scanned" PDF document is produced.
A scanned PDF's content cannot be searched or modified. OCR software is necessary to electronically recognize each character on a page and then transform it into a usable format to search or edit a scanned PDF. Essentially, it recognizes and extracts text from images.
Q3. What is a Native PDF File?
A native PDF is a PDF of a document that was "born digital," meaning it was made from an electronic version of the document rather than a print version. On the other hand, a scanned PDF of a print document, as when you scan pages from a print journal and save the file as a PDF.
Q4. What is the Difference Between a Scanned PDF and a Native PDF?
Scanned PDFs are images of documents, hindering text search capabilities. Native PDFs, born from electronic sources like Word documents, allow seamless text search. ProQuest's databases increasingly feature born-digital content, expanding the availability of native PDFs in PDF format. The percentage of born-digital information in ProQuest databases continues to grow annually.
Q5. What are the Types of Scanned PDFs?
Scanned PDFs are classified into three categories:
1.Image PDFs- The most frequent type of PDF is an image PDF. This is true when a hard copy document is scanned into a PDF file.
2.Scannable PDFs with searchable text - This scanned PDF document may contain hidden text behind the image.
3.Scanned PDFs with Mixed Content -This PDF may contain scanned photos and electronically generated PDF elements.
Conclusion
From the above introductions of converting scanned PDF to Word, we can know UPDF is the best scanned PDF to Word converter. It is affordable, accurate, dedicated, versatile, and available for Windows, Mac, iOS, and Android systems. In addition, you can convert PDFs to various other formats so the files can be edited in their native applications. Give it a try and join the UPDF that tons of users are satisfied to rely on for their everyday document workflow. The Beebom site even provides valuable insights into UPDF's capabilities. We encourage you to check out their review for more information.
Windows • macOS • iOS • Android 100% secure








 Enid Brown
Enid Brown 
 Enola Miller
Enola Miller 
 Enrica Taylor
Enrica Taylor 
