 UPDF for Windows
UPDF for Windows UPDF for Mac
UPDF for Mac UPDF for iPhone/iPad
UPDF for iPhone/iPad UPDF for Android
UPDF for Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign Edit PDF
Edit PDF Annotate PDF
Annotate PDF Create PDF
Create PDF PDF Form
PDF Form Edit links
Edit links Convert PDF
Convert PDF OCR
OCR PDF to Word
PDF to Word PDF to Image
PDF to Image PDF to Excel
PDF to Excel Organize PDF
Organize PDF Merge PDF
Merge PDF Split PDF
Split PDF Crop PDF
Crop PDF Rotate PDF
Rotate PDF Protect PDF
Protect PDF Sign PDF
Sign PDF Redact PDF
Redact PDF Sanitize PDF
Sanitize PDF Remove Security
Remove Security Read PDF
Read PDF UPDF Cloud
UPDF Cloud Compress PDF
Compress PDF Print PDF
Print PDF Batch Process
Batch Process About UPDF AI
About UPDF AI UPDF AI Solutions
UPDF AI Solutions AI User Guide
AI User Guide FAQ about UPDF AI
FAQ about UPDF AI Summarize PDF
Summarize PDF Translate PDF
Translate PDF Chat with PDF
Chat with PDF Chat with AI
Chat with AI Chat with image
Chat with image PDF to Mind Map
PDF to Mind Map Explain PDF
Explain PDF PDF AI Tools
PDF AI Tools Image AI Tools
Image AI Tools AI Chat Tools
AI Chat Tools AI Writing Tools
AI Writing Tools AI Study Tools
AI Study Tools AI Working Tools
AI Working Tools Other AI Tools
Other AI Tools PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF to PowerPoint
PDF to PowerPoint User Guide
User Guide UPDF Tricks
UPDF Tricks FAQs
FAQs UPDF Reviews
UPDF Reviews Download Center
Download Center Blog
Blog Newsroom
Newsroom Tech Spec
Tech Spec Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
When it comes to data processing and document analysis, text extraction from PDF files through code is a common task. Although this task is widely used for document sharing, getting content from a code is not simple. Python is a coding language that provides several libraries to simplify text extraction from a PDF document.
To help you understand the significance and processing of extracting text from PDF Python, this article highlights important information on the subject. Therefore, read this article to learn about the details of Python and discover a convenient alternative to it.
Part 1. Can I Extract Text from PDF Using Python?
To briefly answer the question, yes, you can extract text from a PDF document using Python. This language provides several powerful libraries for text extraction, like PyPDF2. Despite the expressive syntax and extensive library, this language has several downsides that negatively impact the user experience.
- This language works slower than most programming languages, which could be problematic while working on large projects.
- Python's Global Interpreter Lock allows just one thread execution, limiting usage for applications that require multi-threading.
- If you need to extract text from PDF in Python, it requires a Python setup and configuration, which might be complex for beginners.
- With limited hardware, you might get slower outputs while extracting text from large PDF files.
- Many users complain that special characters in their PDF documents fail to be extracted using Python.
Users need a better alternative after knowing the complexities of Python for text extraction. UPDF replaces Python, providing simplified processing and numerous PDF-related tools. This platform converts your PDF documents into Word or TXT files and extracts text from the converted files. To enjoy the extensive functionality of this platform, download UPDF using the button below. If you want to know more, follow Part 3 for detailed instructions on using UPDF.
Windows • macOS • iOS • Android 100% secure
Part 2. How to Extract Text from PDF Using Python?
Now that we know about the details of using this programming language, it is important to know how it works for text extraction. Follow the guide below to learn how to use Python to extract PDF text in simple steps.
Method 1. Extracting Text from PDF Using Python's pypdf Library
Step 1. To start extracting text, open the Python terminal and run the "pip install pypdf" code. As an example, let's consider the following input sample for a better understanding.
# importing required modules
from pypdf import PdfReader
# creating a pdf reader object
reader = PdfReader('example.pdf')
# printing number of pages in pdf file
print(len(reader.pages))
# getting a specific page from the pdf file
page = reader.pages[0]
# extracting text from page
text = page.extract_text()
print(text)
Step 2. For a better comprehension of how Python will process your code, let's go through the sample code in chunks. In the code "reader = PdfReader('example.pdf')," we started by creating an object of the "pdfReader" class from the "pypdf" module. We must note that the "PdfReader" class takes a mandatory positional argument of the path to the pdf file.
Step 3. The "Pages" property provides a list of "PageObjects," where you will use the built-in "len()" function to obtain the number of pages in the PDF document.
print(len(reader.pages)).
Step 4. As you access the "reader.pages," you will get a specific "Page" of the document after you tap the page index. The Python list indexing begins with 0, so "reader.pages[0]" provides us with the first page of the document.
page = reader.pages[0]
Step 5. After you have navigated to the desired page within the PDF document, you can enter the following code to extract the text from that page.
Reader.pages[0]
Method 2. Using Python's PymuPDF Library to Extract PDF Text
Step 1. Begin the process of installing the PymuPDF library on your device by entering the following code.
pip install pymupdf
pip install fitz
Step 2. After you have acquired this library, import the library by running the code below.
import fitz
Step 3. Now that the library has been imported, use the following code to open the desired PDF document. We created an object, named it "doc," and made its filename with the title Python string.
doc = fitz.open('sample.pdf')
Step 3. To extract text from the selected PDF, we ran the following code and iterated the pages within that file. Now, we used the "get_text()" code for drawing each page from that PDF document.
For page in doc:
text = page.get_text()
print(text)
Step 4. Now, run the code below to extract the entire text from the selected PDF file.
import fitz
doc = fitz.open('sample.pdf')
text = ""
For page in doc:
text+=page.get_text()
print(text)
Step 5. Once you have extracted the entire text from the selected PDF file, you will get the following output.

Part 3. How to Extract Text from a PDF Easily without Python?
From the guide above, you must have noticed the complexity while extracting text from PDF Python. It is better to use a convenient replacement, such as UPDF, to get text from a PDF file. By using UPDF, you can easily extract text from a regular or scanned PDF by converting it to editable Word or TXT. Alternatively, you can directly copy the text in PDF after opening it in UPDF.
Moreover, using this platform, you can execute various other processes besides mere text extraction. Users can avail of the PDF-editing features and polish their documents by adding or deleting text, images, and URLs from a file.
A Comprehensive Tutorial on Using UPDF to Extract Text from PDFs
From batch file upload to text extraction, this platform offers simplified functionality throughout. Follow the guide below to learn how to use UPDF for a better experience than extracting text from PDF in Python:
Step 1. Import the PDF File for Text Extraction
To initiate, download and open UPDF on your desktop and click the "Open File" button from the homepage to select the desired PDF file from your library.
Windows • macOS • iOS • Android 100% secure
Step 2. Access the File tab to Proceed
As the selected PDF file opens in the next window, navigate to the top left corner and select the "File" tab to access the menu.
Step 3. Convert the PDF File into a Word Document For Text Extraction
Using the pop-up menu, hover your mouse over the "Tools" option and select "Word (.docx)" to convert your PDF into Word format.
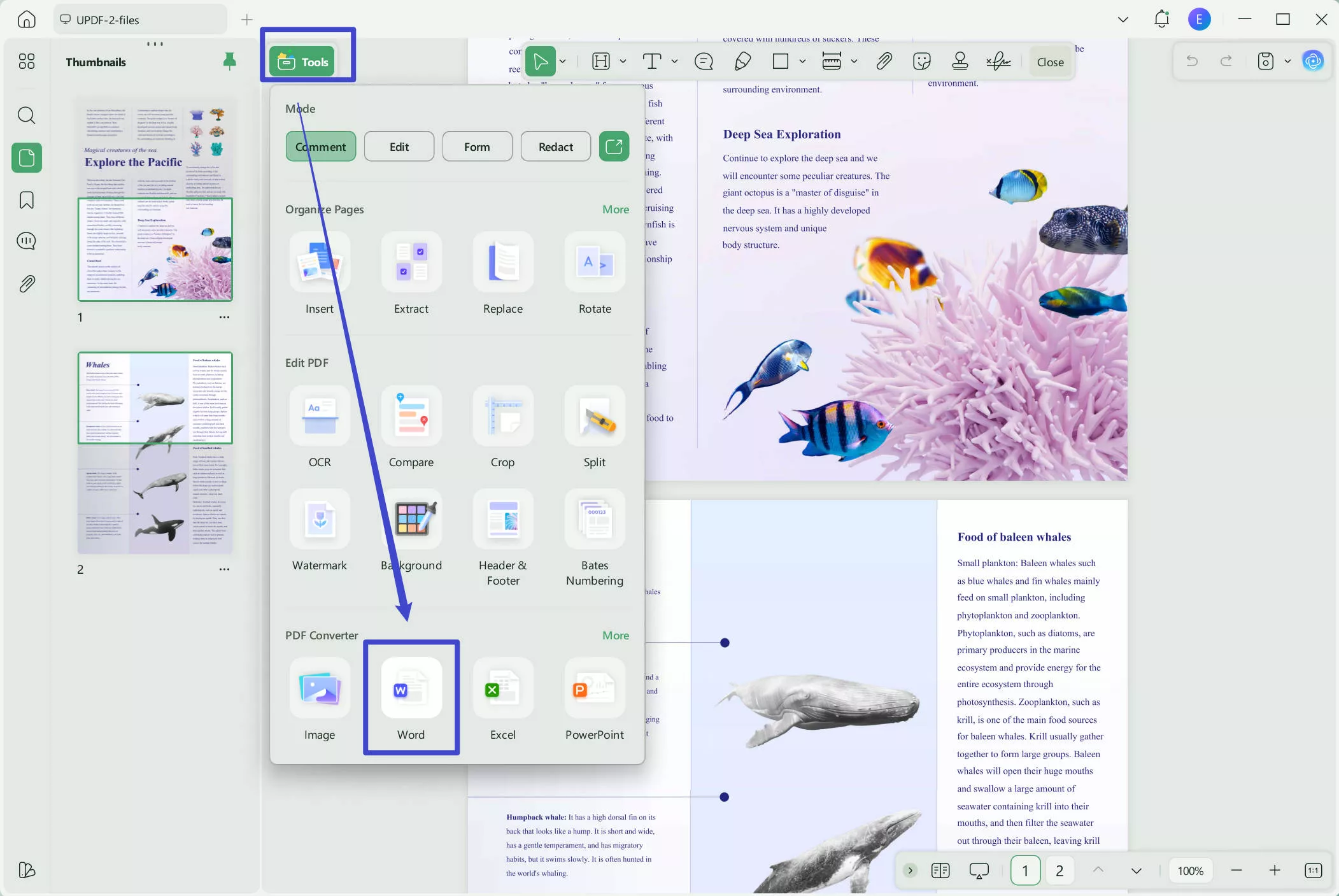
Step 4. Extract the Text by Exporting the PDF in Word Format
When the following dialogue box appears, make sure that you have selected "Word (.docx)" from the "Output Format" drop-down menu. To save the PDF in Word format, click the "Export" button at the bottom of the window, and your file will be automatically saved.
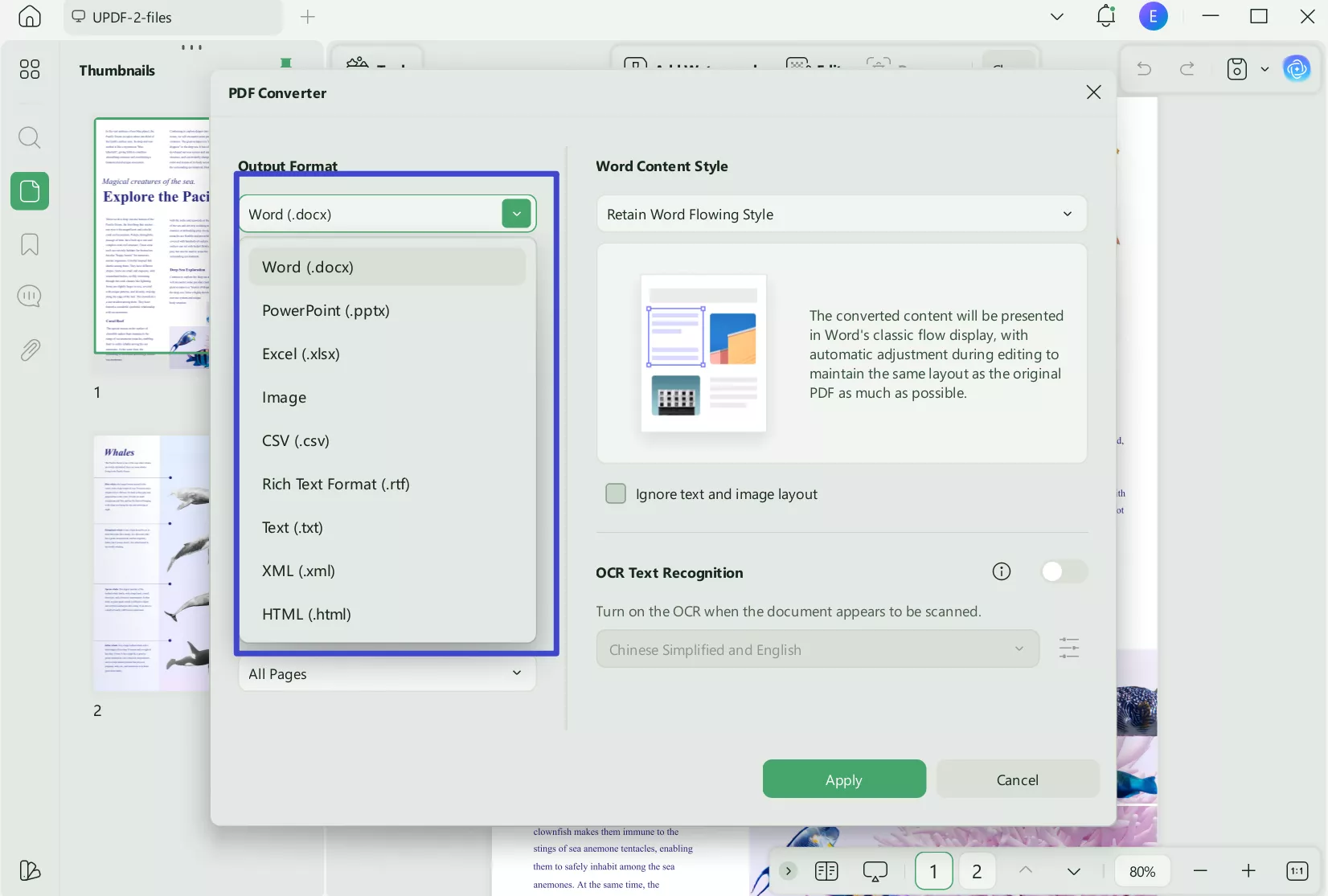
Step 5. Extract the Desired Text from the Word File
After your Word file has been saved to the device, open it and locate the text that needs to be extracted from the document. Now, use the "Ctrl+C" keys from your keyboard to successfully extract the text from this file, which you can paste anywhere needed.
Bonus Tip
If your PDF contains only a small amount of text, you can directly copy it in UPDF's Reader mode. However, if you need to extract text from multiple PDFs, you can first merge them into one using UPDF and then export it in an editable format such as Word or TXT.
Conclusion
In summary, this article was a detailed guide on how to extract text from PDF Python using various libraries. After having an in-depth overview of this method, we explored that it offers complicated functionality for beginners. Therefore, we discovered UPDF as a better alternative that provides a user-friendly interface for functionalities beyond text extraction.
Windows • macOS • iOS • Android 100% secure








 Enid Brown
Enid Brown 
 Enrica Taylor
Enrica Taylor 

 Delia Meyer
Delia Meyer 
