 UPDF for Windows
UPDF for Windows UPDF for Mac
UPDF for Mac UPDF for iPhone/iPad
UPDF for iPhone/iPad UPDF for Android
UPDF for Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Edit PDF
Edit PDF Annotate PDF
Annotate PDF Create PDF
Create PDF PDF Form
PDF Form Edit links
Edit links Convert PDF
Convert PDF OCR
OCR PDF to Word
PDF to Word PDF to Image
PDF to Image PDF to Excel
PDF to Excel Organize PDF
Organize PDF Merge PDF
Merge PDF Split PDF
Split PDF Crop PDF
Crop PDF Rotate PDF
Rotate PDF Protect PDF
Protect PDF Sign PDF
Sign PDF Redact PDF
Redact PDF Sanitize PDF
Sanitize PDF Remove Security
Remove Security Read PDF
Read PDF UPDF Cloud
UPDF Cloud Compress PDF
Compress PDF Print PDF
Print PDF Batch Process
Batch Process About UPDF AI
About UPDF AI UPDF AI Solutions
UPDF AI Solutions AI User Guide
AI User Guide FAQ about UPDF AI
FAQ about UPDF AI Summarize PDF
Summarize PDF Translate PDF
Translate PDF Chat with PDF
Chat with PDF Chat with AI
Chat with AI Chat with image
Chat with image PDF to Mind Map
PDF to Mind Map Explain PDF
Explain PDF PDF AI Tools
PDF AI Tools Image AI Tools
Image AI Tools AI Chat Tools
AI Chat Tools AI Writing Tools
AI Writing Tools AI Study Tools
AI Study Tools AI Working Tools
AI Working Tools Other AI Tools
Other AI Tools AI Bookmark Generation
AI Bookmark Generation AI Bookmark Summary
AI Bookmark Summary AI Watermark Generation
AI Watermark Generation AI Background Generation
AI Background Generation AI Sticker Generation
AI Sticker Generation AI Stamp Generation
AI Stamp Generation AI Editing Suite
AI Editing Suite UPDF Copilot
UPDF Copilot AI Page Management
AI Page Management AI Semantic Search
AI Semantic Search PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF to PowerPoint
PDF to PowerPoint User Guide
User Guide UPDF Tricks
UPDF Tricks FAQs
FAQs UPDF Reviews
UPDF Reviews Download Center
Download Center Blog
Blog Newsroom
Newsroom Tech Spec
Tech Spec Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Manually retyping text from a locked PDF is a massive waste of time, yet it is a frustration that happens every day in busy offices. Academic researchers frequently run into historical scans where unique fonts turn into unreadable typos, corporate teams lose hours trying to pull financial metrics from flattened legal agreements, and engineers face formatting headaches when trying to scrape unmapped data from legacy documents.
Whether you are dealing with a flat image snapshot or a secure document with strict copy-paste protections, you shouldn't have to waste your day on manual data entry. Depending on your specific file type, there is a much smarter, dual-track approach to get the job done—either rebuilding the text layer with precision character recognition or using semantic AI to pull information instantly without changing the file. In this guide, we will show you exactly how UPDF helps you eliminate these bottlenecks and make pdf editable to keep your workflow moving.
Windows • macOS • iOS • Android 100% secure
Track 1: Extract Text from Scanned PDFs with OCR
When a PDF is just images, basic viewers cannot perform accurate PDF text extraction from those pages. You need dedicated, high-grade OCR tools to rebuild a clean, editable text layer from pixel-only scans.
Many people still need fast, precise PDF text extraction from scanned pages, receipts, and tricky layouts. This is where UPDF gives you focused OCR tools across desktop and mobile for daily workflows. Its AI-backed OCR recognizes text in 38 languages, including mixed multilingual pages, without breaking characters.
You can scan or import documents on Windows, Mac, and mobile phones and convert them into editable files. UPDF's OCR engine is tuned for up to 99% accuracy, keeping your converted documents reliable and usable.
Method 1: Multi-Lingual Desktop OCR Processing (Windows/Mac)
When your document is a flat scan, UPDF desktop OCR gives tighter control than simple viewing tools. It lets you carefully choose document types and languages, so you accurately recognize text in PDF. So, follow the steps below to convert complex scanned pages into precise, fully editable documents:
Step 1. Once you import a PDF into UPDF, press the "Tools" option and choose the "OCR" tool to access it.
Step 2. After that, choose the "Editable PDF" OCR mode and select the accurate languages used in the document. Next, click the "Convert" button and choose a location for the new PDF to begin OCR.

Step 3. Once OCR is finished, UPDF will automatically open the editable PDF. Next, access the "Edit" feature and change text directly on the PDF page.
Method 2: Rapid Touchscreen Mobile OCR Conversion (iOS/Android)
Clients often send urgent image‑only PDFs, and you must extract text from PDF directly on mobile. UPDF's app lets you open those scans, trigger OCR, and quickly copy clean text into chats. Go through the steps below to convert incoming phone documents into usable, shareable digital text instantly:
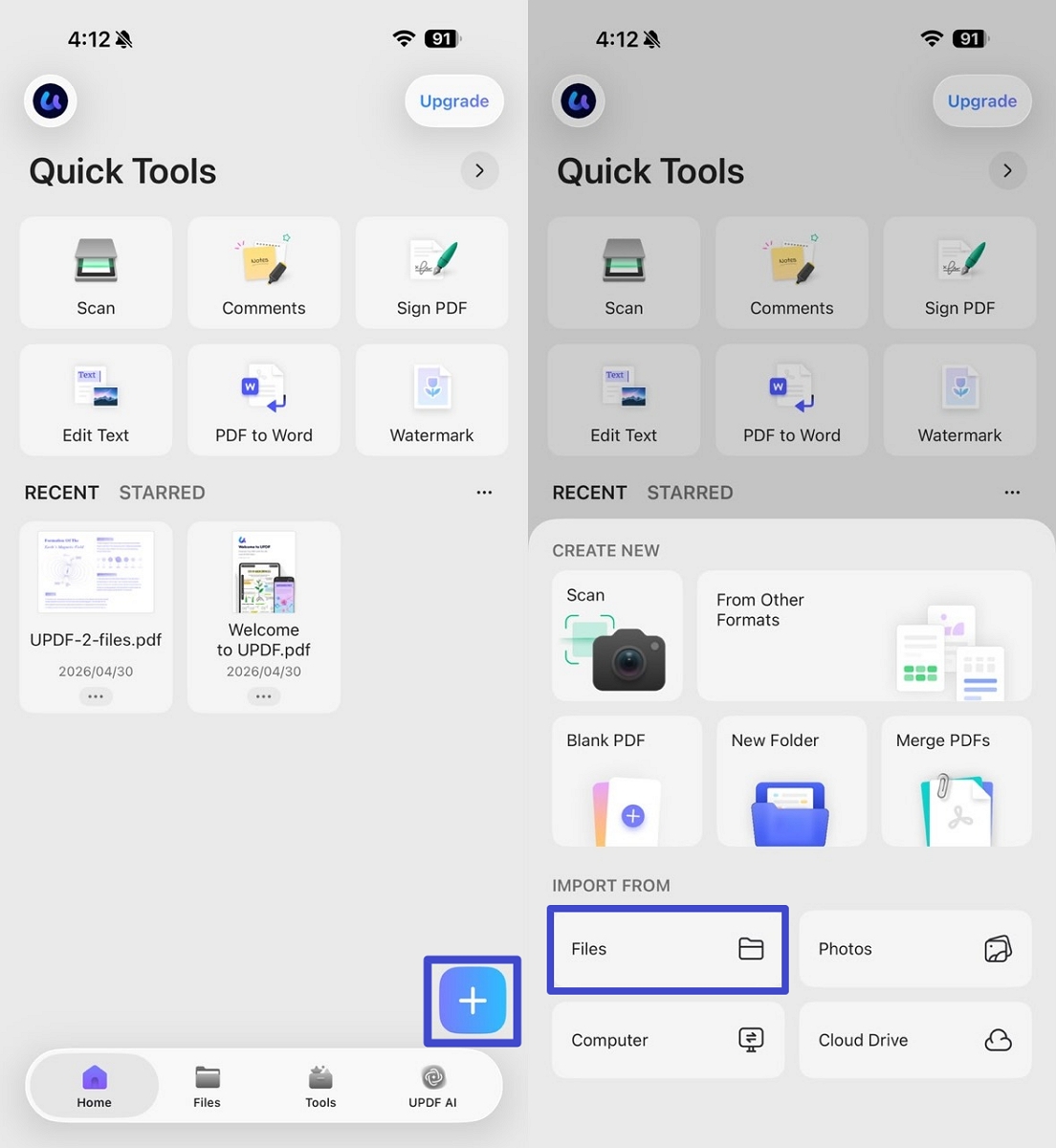
Step 1. Once you open the UPDF app on your Android or iOS phone, tap on the "+" icon and press the "File" option to import the scanned or image-based PDF. You can also directly import the image before performing OCR.
Windows • macOS • iOS • Android 100% secure
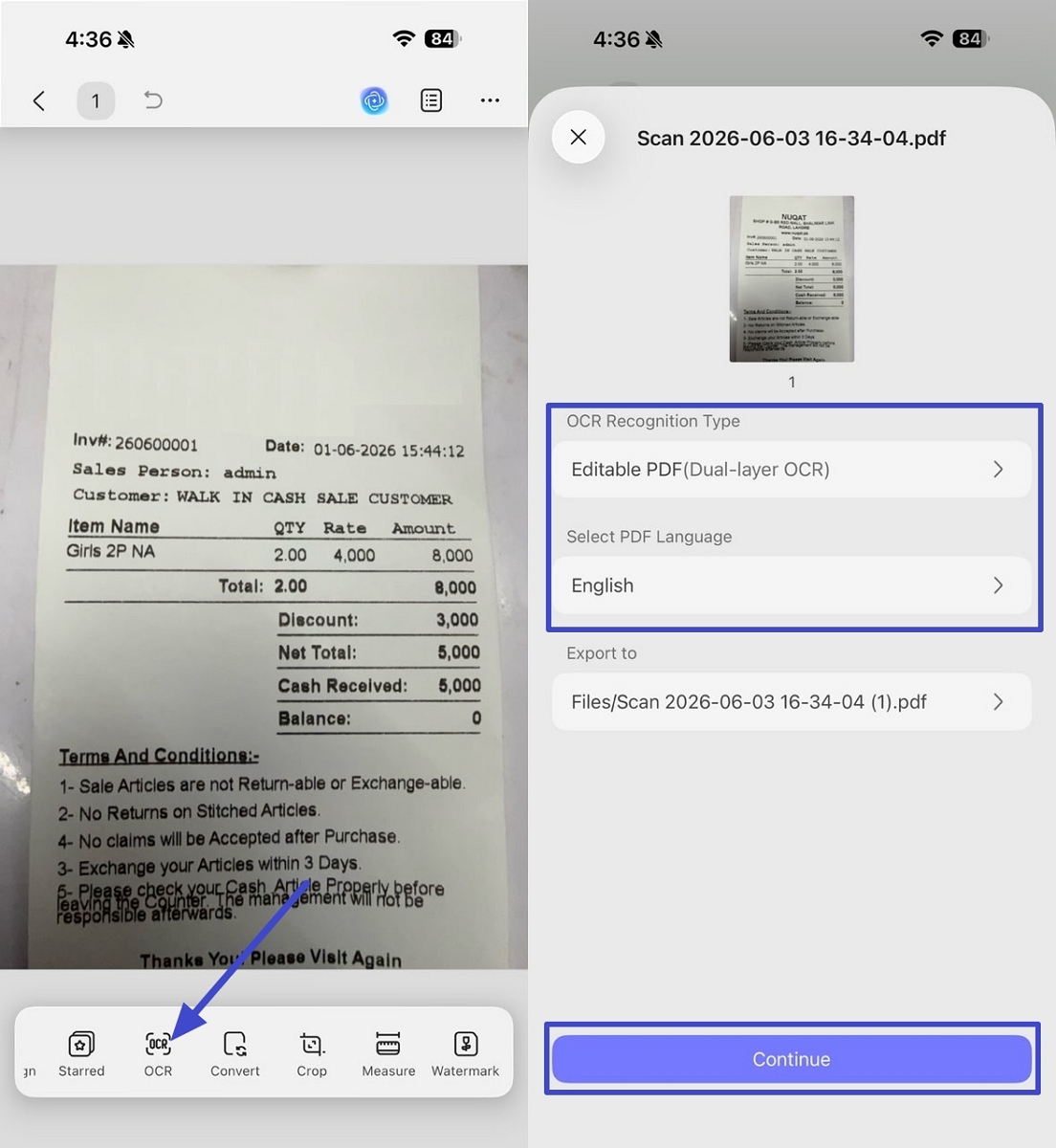
Step 2. After the file is imported, tap on the "OCR" option in the toolbar below. Next, select the "Editable PDF" mode, select the correct language, and tap on the "Continue" option. This process works the same on both Android and iOS devices.
Step 3. Now, open the OCRed file in UPDF. Select and copy some text from the PDF to see if it is searchable.

Track 2: How to Extract Text from PDF Without OCR via AI Semantic Retrieval
When you are stuck on a guest device, a browser fallback like free OCR software online can handle quick scans. Teams working with giant PDFs need tools that understand layouts once and then answer precise questions instantly.
Extract Text From PDFs Without OCR Scans
For huge PDFs, running full OCR every time is slow and often completely unnecessary. Instead, the built-in UPDF AI chat reads the document directly and pulls answers without OCR. You can ask for text from chosen sections and get clean, focused passages in seconds. It also creates tight summaries of long reports, highlighting key metrics for quick desktop review.
Direct Text Retrieval via UPDF AI (All Platforms)
UPDF AI helps analysts extract text from PDF without OCR by responding directly to precise questions. Now, follow the steps below to target specific pages or summaries without heavy file conversions:
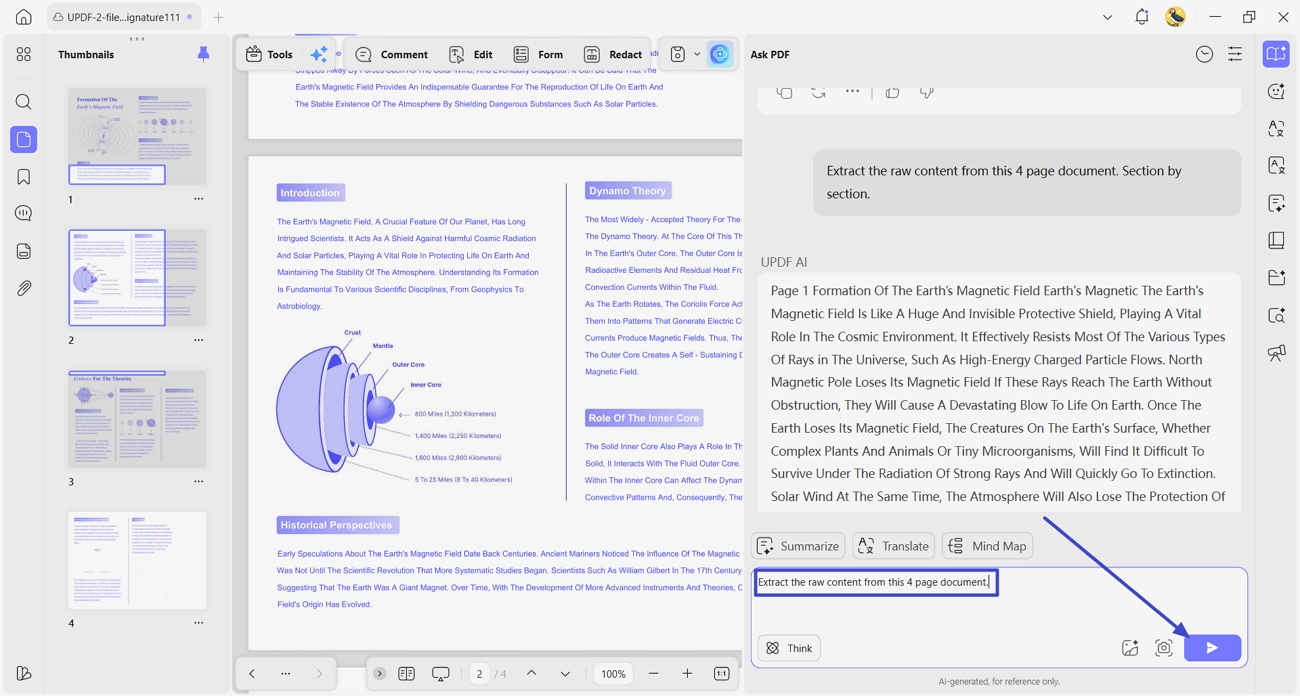
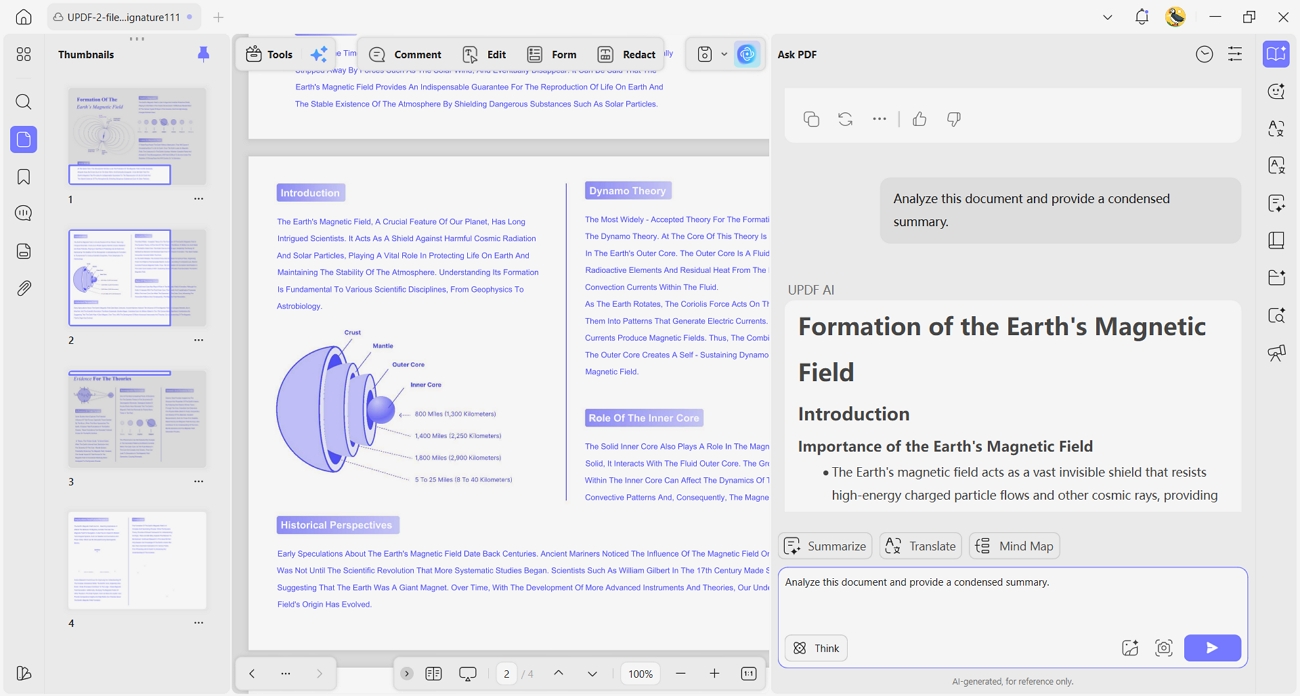
Step 1. After opening a PDF on UPDF desktop or mobile, click the "UPDF AI" icon and access the "Ask PDF" feature. Next, click the "Chat With PDF" button.
Step 2. Next, in the chat box, enter the prompt "Extract the raw content from this x page document." and click the "Send" button. This way, UPDF AI will extract all the text written in the PDF.
Step 3. If you want a short summary of your lengthy document, simply enter the prompt "Analyze this document and provide a condensed summary." in the chat box. You'll get a concise summary of your PDF.
Beyond Extraction: Contextual UPDF Features
Once you extract text from PDF files, you still need ways to actually use that cleaned content. Some people paste results into other tools, but switching apps repeatedly slows every simple document task. Now, let's explore other built-in options that help you finish everything inside one UPDF workspace.
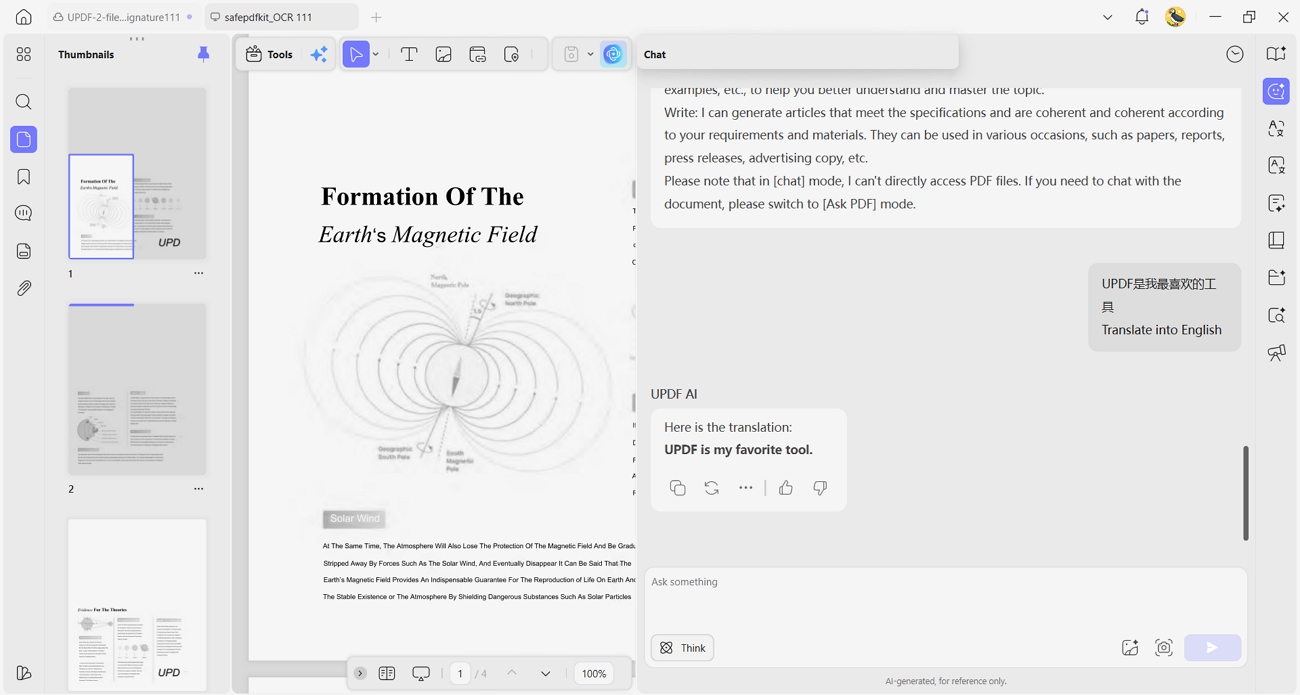
- UPDF AI Translate: After extraction, users paste foreign text into chat and instantly request translation in any language.
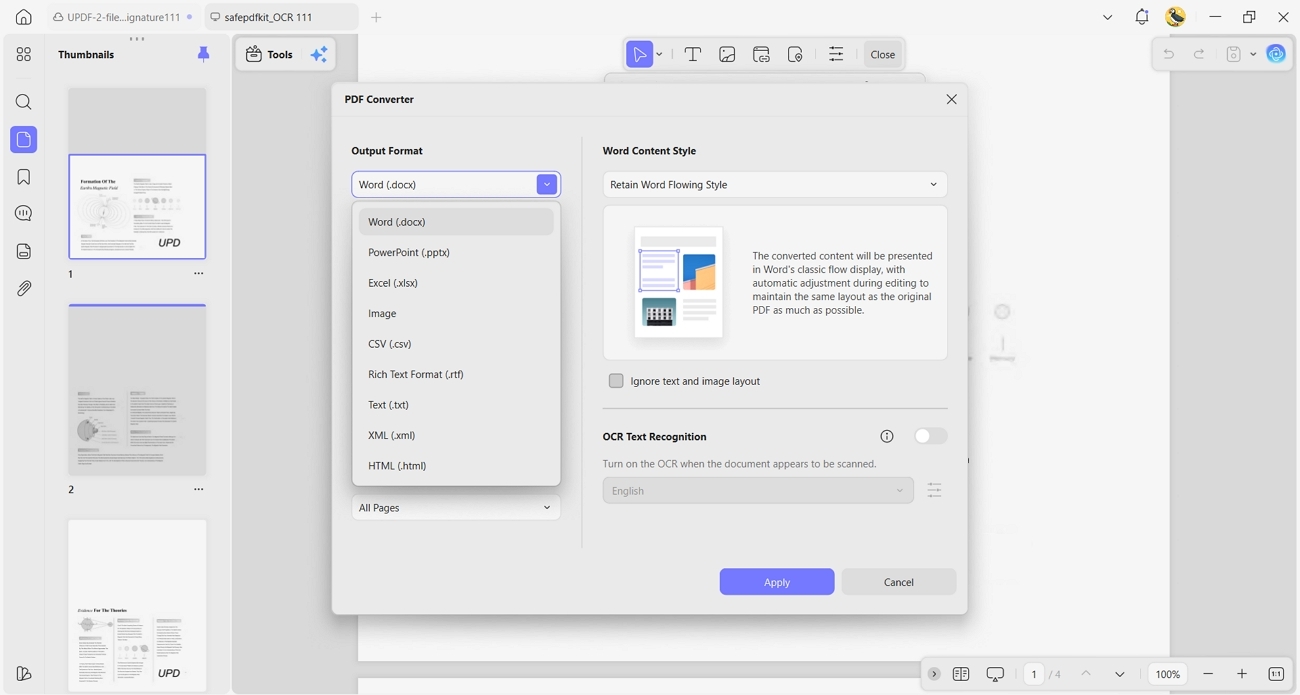
- Convert PDF: Cleaned documents can be converted into Word or Excel with tables and formatting preserved. This helps teams prepare polished reports and presentations faster when deadlines are very tight.
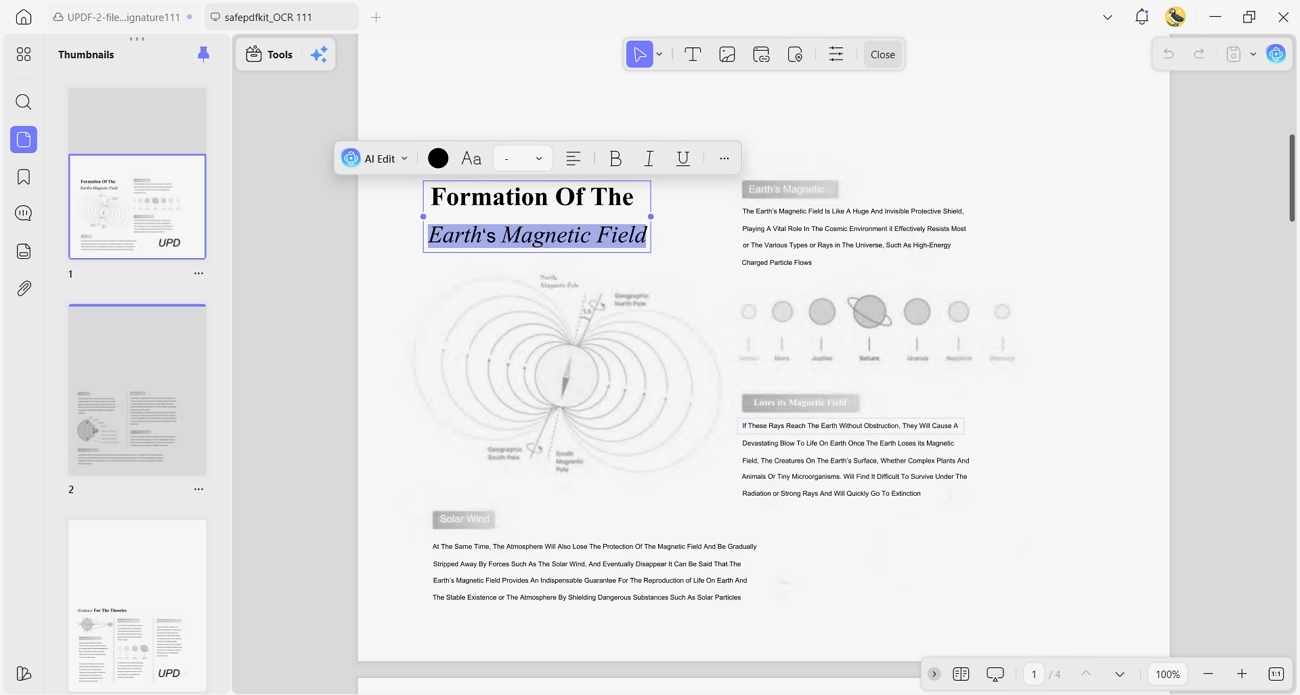
- All-in-One PDF Editor: UPDF lets you adjust text, swap images, and organize pages inside the same streamlined interface. You can install it once and handle reviewing, correcting, and finalizing documents without juggling extra tools.
So, download UPDF to start using AI Translate and convert PDFs in your documents.
Windows • macOS • iOS • Android 100% secure
Frequently Asked Questions
Can AI actually extract text from a scanned PDF image without running OCR?
Yes. Traditional PDF tools need an invisible text layer, so they cannot perform direct PDF text extraction from images. UPDF's Ask PDF mode uses large language models to interpret visual content instead of the hidden layer. The AI turns what it sees into answers in chat, avoiding slow conversions or file changes entirely.
Will UPDF's OCR turn text into unreadable characters if a page contains multiple languages?
Yes. Many free web tools guess only one language, which often breaks secondary scripts into useless symbols. UPDF's OCR engine supports 38 languages and lets you enable several options for one document. Selecting every language on the page makes OCR combine all libraries and deliver accurate, readable characters.
Conclusion
In this guide, you get two clear paths to reliably extract text from PDF using UPDF. Traditional OCR handles layout-perfect conversions, while AI reading delivers instant understanding without extra scanning work each time. One UPDF license covers Windows, Mac, iOS, and Android, so every device shares the same tools. So, try UPDF now to test text extraction on your own everyday documents.
Windows • macOS • iOS • Android 100% secure







 Enrica Taylor
Enrica Taylor 

 Enola Miller
Enola Miller 
 Engelbert White
Engelbert White