 UPDF for Windows
UPDF for Windows UPDF for Mac
UPDF for Mac UPDF for iPhone/iPad
UPDF for iPhone/iPad UPDF for Android
UPDF for Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign Edit PDF
Edit PDF Annotate PDF
Annotate PDF Create PDF
Create PDF PDF Form
PDF Form Edit links
Edit links Convert PDF
Convert PDF OCR
OCR PDF to Word
PDF to Word PDF to Image
PDF to Image PDF to Excel
PDF to Excel Organize PDF
Organize PDF Merge PDF
Merge PDF Split PDF
Split PDF Crop PDF
Crop PDF Rotate PDF
Rotate PDF Protect PDF
Protect PDF Sign PDF
Sign PDF Redact PDF
Redact PDF Sanitize PDF
Sanitize PDF Remove Security
Remove Security Read PDF
Read PDF UPDF Cloud
UPDF Cloud Compress PDF
Compress PDF Print PDF
Print PDF Batch Process
Batch Process About UPDF AI
About UPDF AI UPDF AI Solutions
UPDF AI Solutions AI User Guide
AI User Guide FAQ about UPDF AI
FAQ about UPDF AI Summarize PDF
Summarize PDF Translate PDF
Translate PDF Chat with PDF
Chat with PDF Chat with AI
Chat with AI Chat with image
Chat with image PDF to Mind Map
PDF to Mind Map Explain PDF
Explain PDF PDF AI Tools
PDF AI Tools Image AI Tools
Image AI Tools AI Chat Tools
AI Chat Tools AI Writing Tools
AI Writing Tools AI Study Tools
AI Study Tools AI Working Tools
AI Working Tools Other AI Tools
Other AI Tools AI Bookmark Generation
AI Bookmark Generation AI Bookmark Summary
AI Bookmark Summary AI Watermark Generation
AI Watermark Generation AI Background Generation
AI Background Generation AI Sticker Generation
AI Sticker Generation AI Stamp Generation
AI Stamp Generation AI Editing Suite
AI Editing Suite UPDF Copilot
UPDF Copilot AI Page Management
AI Page Management AI Semantic Search
AI Semantic Search PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF to PowerPoint
PDF to PowerPoint User Guide
User Guide UPDF Tricks
UPDF Tricks FAQs
FAQs UPDF Reviews
UPDF Reviews Download Center
Download Center Blog
Blog Newsroom
Newsroom Tech Spec
Tech Spec Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Many industries and organizations heavily rely on OCR technology to make scanned PDFs accessible. Tech-based departments usually need this technology to extract useful information with Python. Notably, Python has a rich ecosystem of libraries like the Tesseract and PyMuPDF that allow users to convert these scanned PDFs into editable text.
Anyhow, this article will provide you with the best OCR PDF Python that can help you convert important scanned PDFs into searchable and editable text. Moreover, it will look at a more comprehensive approach to converting scanned PDFs into editable text with UPDF.
Part 1. How to OCR PDF Using Python?
As discussed before, Python contains a wide variety of libraries that cater to different actions and provide you with an editable file. To ease the selection, this part has listed some of the best Python OCR PDFs with easy-to-follow steps:
1. Use pdf2image + pytesseract to OCR PDF
The pdf2image Python library is mostly used for converting PDF pages into a sequence of images, which can later be processed by the pytesseract tool for Python. The assorted open-source OCR Engine, Tesseract, has the ability to support more than 100 languages, while turning text into alphabetical symbols and characters. We have outlined the steps of OCR PDF to text Python using these two utilities as follows:
Step 1. Install Tesseract on your device and open the "Command Prompt" to run the following command: pip install pdf2image pytesseract. Once the installation of required libraries is completed, you can proceed with the PDF data extraction with ease.

Step 2. Now, convert the PDF pages into images using the following commands with pdf2image:

Step 3. After that, extract all the necessary text from the PDF image using pytesseract's ability to successfully perform OCR on the PDF.

If you find the process of using pdf2image and pytesseract too complex, try UPDF, which offers a simpler way to perform OCR on PDFs. With an intuitive interface, UPDF eliminates the need for coding and allows you to extract and copy text from scanned PDFs and images in just a few clicks. It's a faster and more effective way to perform OCR without relying on Python tools.
Windows • macOS • iOS • Android 100% secure
2. Use PyMuPDF + EasyOCR to OCR PDF
Another brilliant set of Python libraries includes PyMuPDF, which is capable of extraction, analysis, and conversion functionalities. Whereas EasyOCR is an open-source library that supports multiple languages, is pre-trained to recognize text, and is embedded with different identification models. It efficiently detects text in images and provides you with an editable PDF file. You can learn to use these OCR PDF Pythons by following the given steps:
Step 1. First, install the required Python packages of PyMuPDF and EasyOCR using the following command:

Step 2. Once the installation is completed, you can begin the conversion of PDF pages into PNGs with the help of the PyMuPDF.

Step 3. Upon doing so, the OCR function can be performed by the EasyOCR to convert the converted pages into editable text.

3. Use OCRmyPDF + PDFPlumber to OCR PDF
Users can find other Python libraries that can preserve the original layout and add an OCR layer over the PDFs, like OCRmyPDF. Furthermore, with the help of the PDFPlumber library, users can extract text from these PDFs and utilize them for their needs. This is a straightforward process that you can learn by following these steps and seamlessly using these OCR PDF Python libraries:
Step 1. Start by installing the OCRmyPDF library and run the command pip install ocrmypdf --quiet to generate the modified PDF. You can easily search your PDF output on the command and begin the extraction.


Step 2. Run the following command to install the PDFPlumber library and extract the desired pages from the scanned PDF file into editable text:


Part 2. How to OCR PDF More Easily Without Python?
While Python can make the conversion process smoother, it is not a piece of cake for beginners and users with no technical skills. While searching for an easier alternative, you should head towards UPDF, which is an AI-powered PDF editor tool designed to cater to your basic needs. With advanced OCR technology, it can recognize up to 38 languages and convert any scanned PDF, document, and image into editable and searchable text.
Moreover, it your PDF contains more than 2 different languages, it also supports for recognizing. Besides, after turning the scanned PDF or image to text, you can utilize its editing tools to make the edits you want.

You can customize the conversion process by selecting the desired page range, language, layout, and DPI. UPDF can convert files into editable PDFs with high-quality precision and 99% accuracy. It also ensures that the PDF's formatting, layout, and structure remain intact after the OCR.
Guide on How to Perform OCR to Scanned PDFs Using UPDF
As you have found an exceptional alternative to OCR PDF to text Python, follow the given operational guide. Through it, learn how you can turn a scanned image or document into an editable file using this alternative, UPDF:
Step 1. Open UPDF and Import the Desired PDF
After downloading and installing UPDF on your computer, launch and access the main interface. Now, click the "Open File" button to import the scanned PDF from the dialogue box.
Windows • macOS • iOS • Android 100% secure
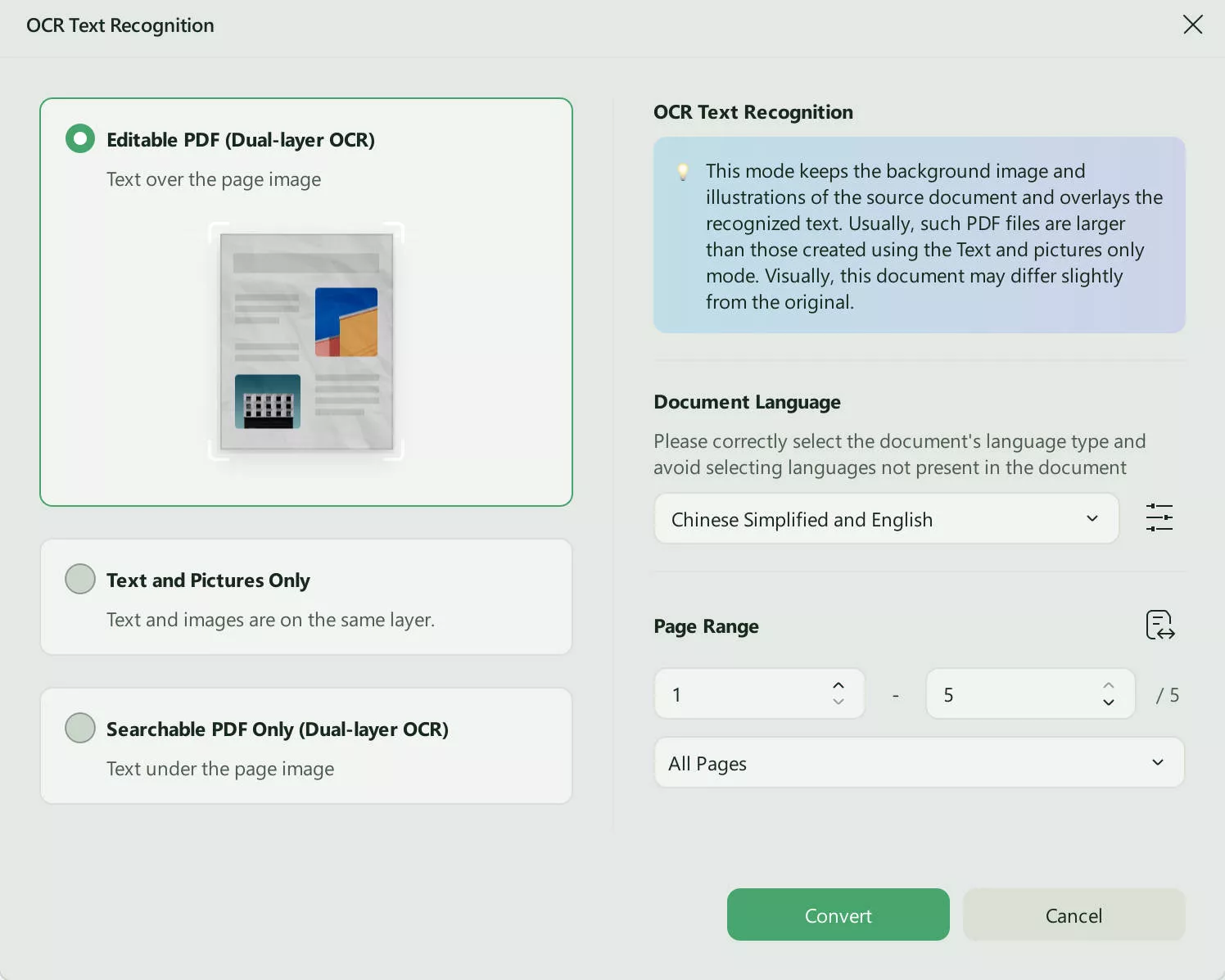
Step 2. Access and Perform OCR
When the PDF opens in the "Reader" window, head to the right-side panel and press the "OCR" icon in "Tools". You can choose "Editable PDF", "Text and Pictures Only", "Searchable PDF Only" for different needs. Adjust the settings if needed. Once satisfied, hit the "Convert" button and save the file with an OCR copy on your device.
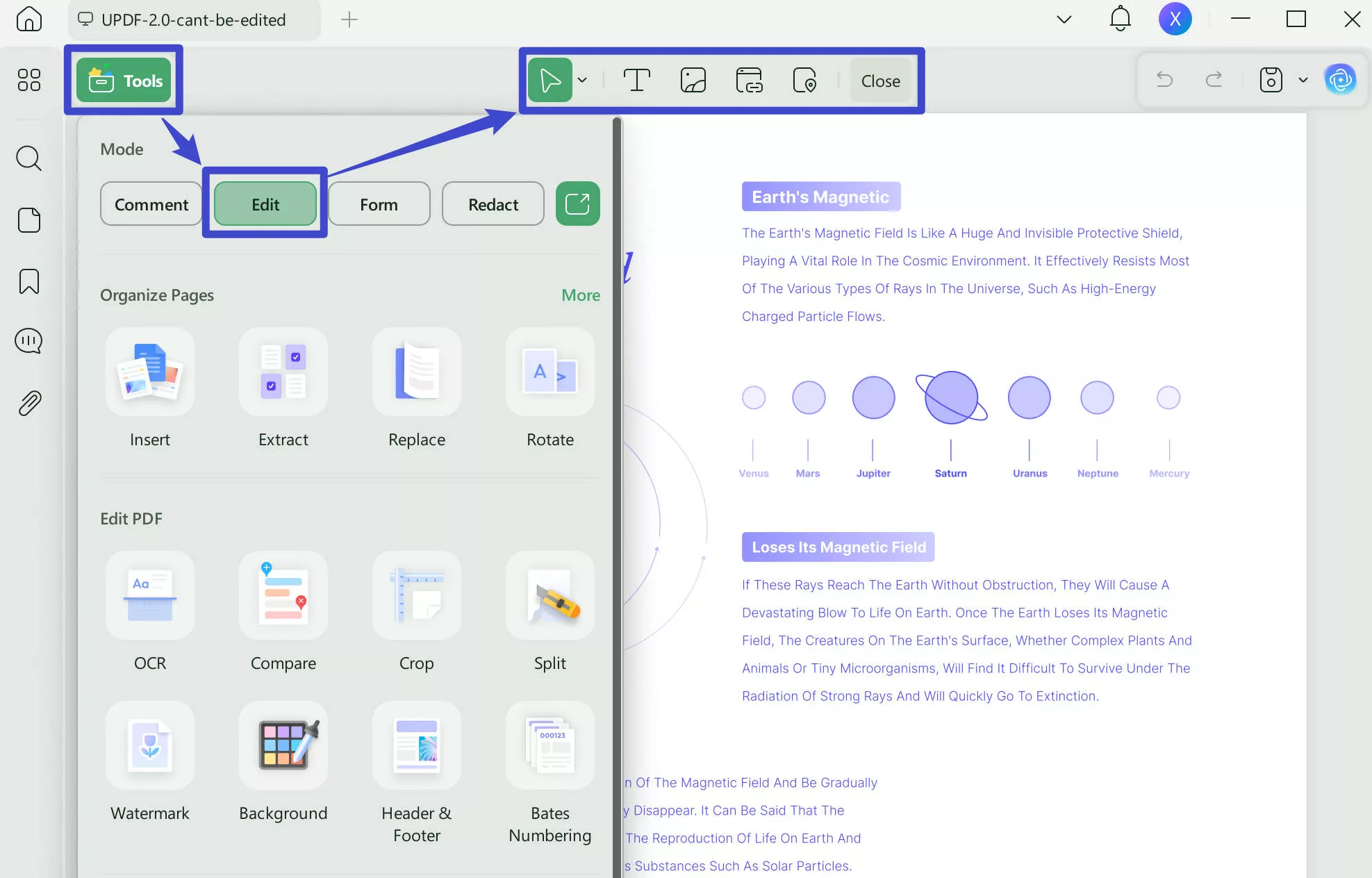
Step 3. Edit the Content of the PDF
Now, you can switch to the Edit mode in "Tools", select the text, images, or links from the document and make desirable changes. You can also copy the text in the PDF.
Conclusion
In conclusion, this article dives into understanding different OCR PDF Python libraries, such as pdf2image, EasyOCR, and more. These are responsible for turning PDF pages into images; others can turn these images into editable text.
Since this guide looked at the best 4 methods of performing OCR with comprehensive steps, it is evident that the simplest one is UPDF. This software can not only turn any PDF into an editable file but also lets you personalize, copy, extract, and export to other formats with ease.
Windows • macOS • iOS • Android 100% secure








 Engelbert White
Engelbert White 


 Delia Meyer
Delia Meyer 