 UPDF for Windows
UPDF for Windows UPDF for Mac
UPDF for Mac UPDF for iPhone/iPad
UPDF for iPhone/iPad UPDF for Android
UPDF for Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign Edit PDF
Edit PDF Annotate PDF
Annotate PDF Create PDF
Create PDF PDF Form
PDF Form Edit links
Edit links Convert PDF
Convert PDF OCR
OCR PDF to Word
PDF to Word PDF to Image
PDF to Image PDF to Excel
PDF to Excel Organize PDF
Organize PDF Merge PDF
Merge PDF Split PDF
Split PDF Crop PDF
Crop PDF Rotate PDF
Rotate PDF Protect PDF
Protect PDF Sign PDF
Sign PDF Redact PDF
Redact PDF Sanitize PDF
Sanitize PDF Remove Security
Remove Security Read PDF
Read PDF UPDF Cloud
UPDF Cloud Compress PDF
Compress PDF Print PDF
Print PDF Batch Process
Batch Process About UPDF AI
About UPDF AI UPDF AI Solutions
UPDF AI Solutions AI User Guide
AI User Guide FAQ about UPDF AI
FAQ about UPDF AI Summarize PDF
Summarize PDF Translate PDF
Translate PDF Chat with PDF
Chat with PDF Chat with AI
Chat with AI Chat with image
Chat with image PDF to Mind Map
PDF to Mind Map Explain PDF
Explain PDF PDF AI Tools
PDF AI Tools Image AI Tools
Image AI Tools AI Chat Tools
AI Chat Tools AI Writing Tools
AI Writing Tools AI Study Tools
AI Study Tools AI Working Tools
AI Working Tools Other AI Tools
Other AI Tools AI Bookmark Generation
AI Bookmark Generation AI Bookmark Summary
AI Bookmark Summary AI Watermark Generation
AI Watermark Generation AI Background Generation
AI Background Generation AI Sticker Generation
AI Sticker Generation AI Stamp Generation
AI Stamp Generation AI Editing Suite
AI Editing Suite UPDF Copilot
UPDF Copilot AI Page Management
AI Page Management AI Semantic Search
AI Semantic Search PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF to PowerPoint
PDF to PowerPoint User Guide
User Guide UPDF Tricks
UPDF Tricks FAQs
FAQs UPDF Reviews
UPDF Reviews Download Center
Download Center Blog
Blog Newsroom
Newsroom Tech Spec
Tech Spec Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
OCR PDFs with UPDF on Windows
The OCR feature by UPDF allows you to convert the scanned text of a PDF document into searchable and editable content. Text on images can also be edited after using this feature which makes the document interactive for users. Click the below button and follow the below text guide or video guide to OCR PDFs.
Windows • macOS • iOS • Android 100% secure
1. How to Download and Install OCR
As you open the respective document, navigate to the "Recognize Text Using OCR" button on the right.
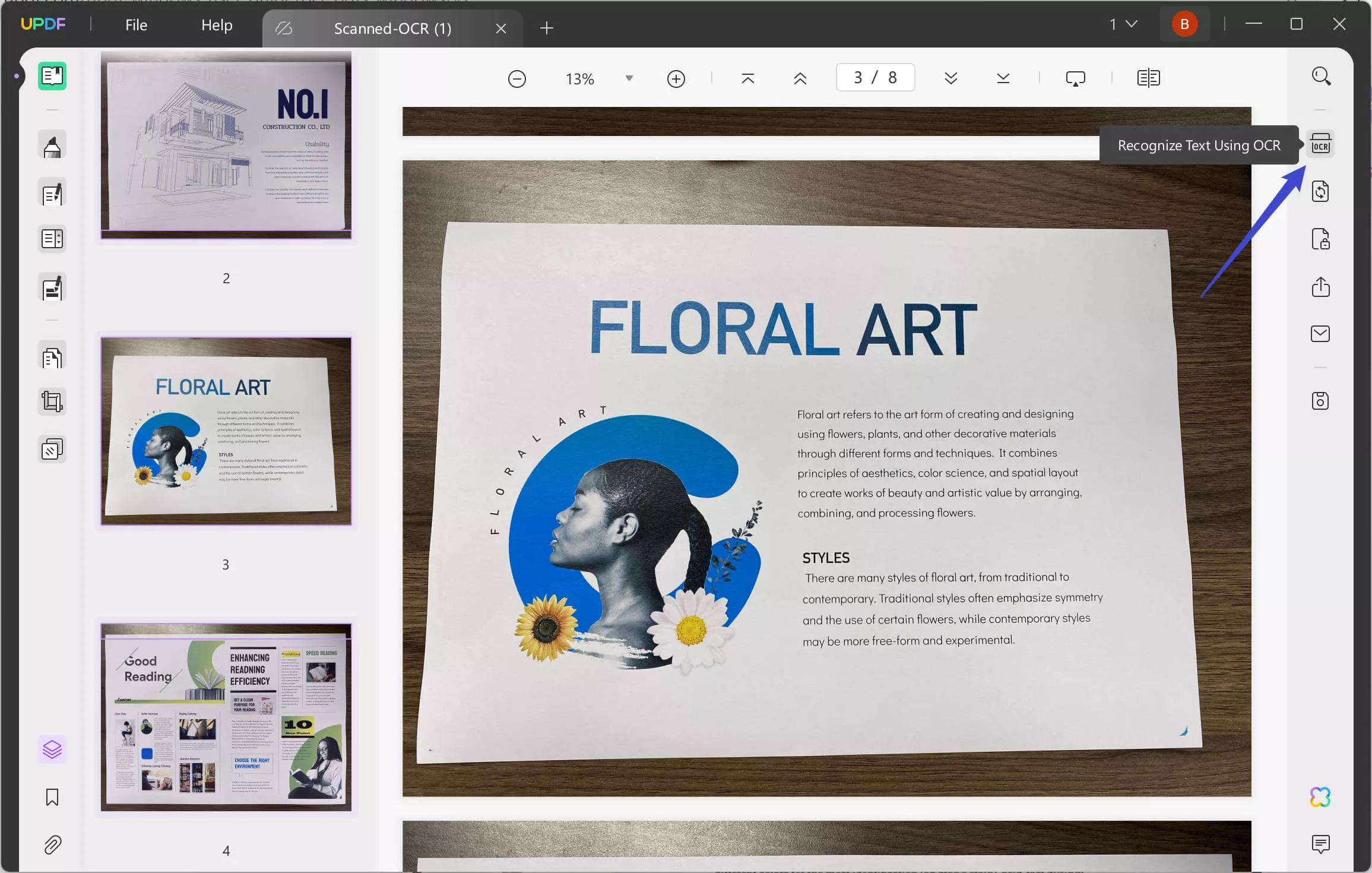
If you are using this feature for the first time, you will have to download it as a plugin across UPDF. Continue with the process by clicking on the "Download" button across the pop-up window.
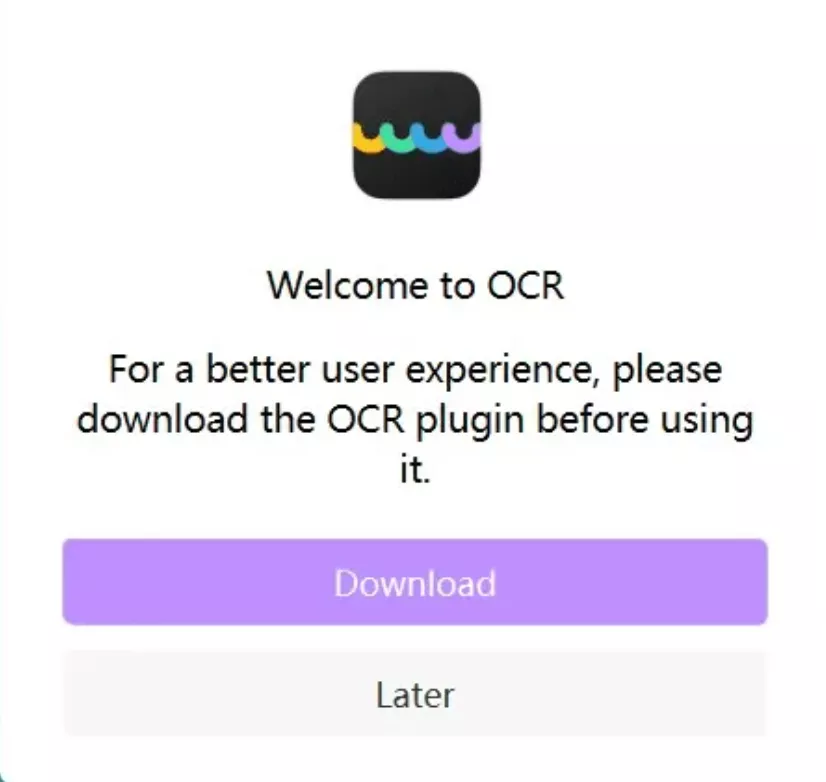
You will be automatically redirected to the next window, where the progress of the installation of the feature will be displayed. Let the feature install successfully across your Windows device before using it.
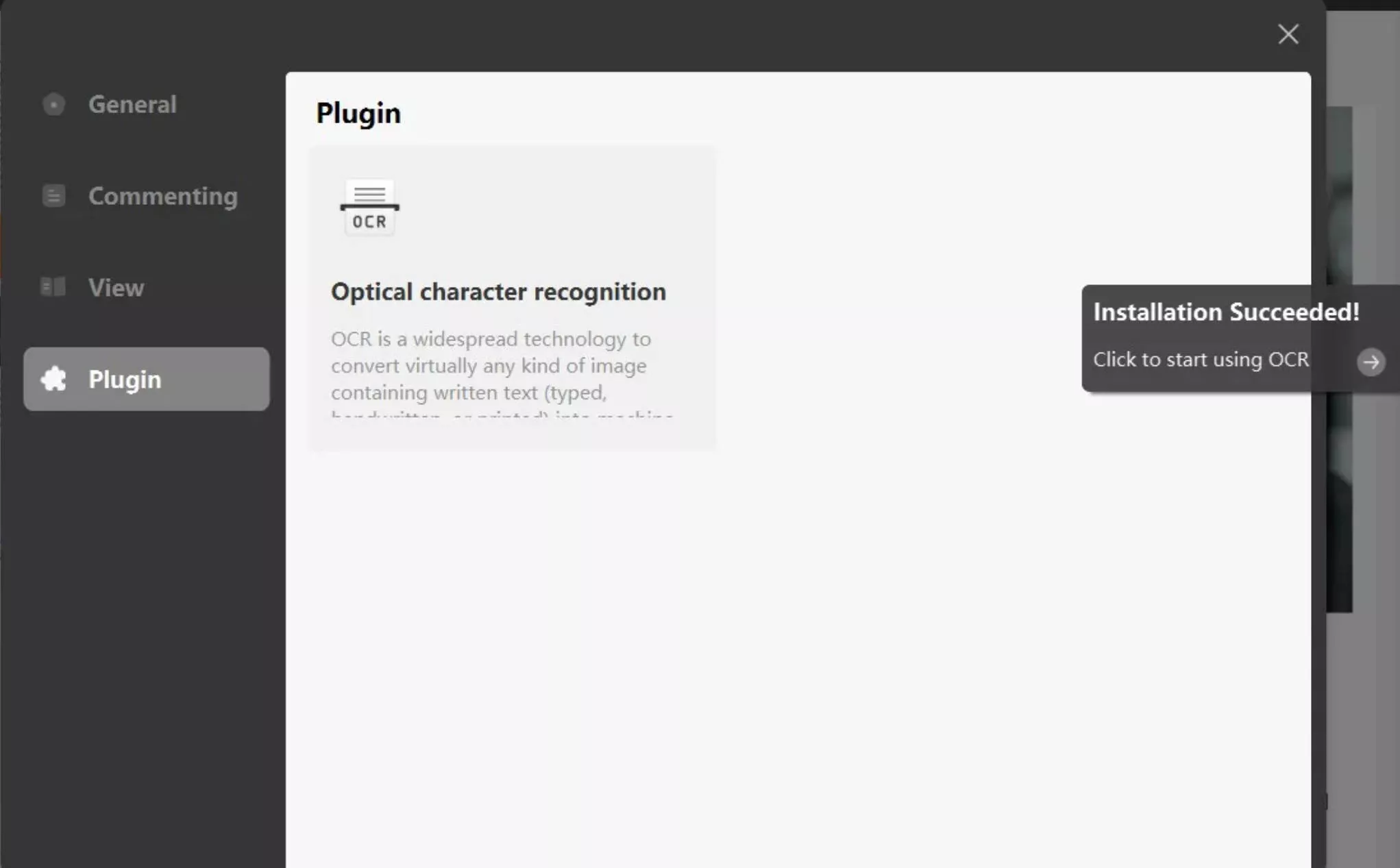
2. How to OCR PDFs
Once installed, close the window and navigate to the same button for accessing the OCR tool across UPDF. As it opens up, it will provide you with two different options of Document Type, which include "Searchable PDF" and "Image-only PDF."
- Searchable PDF: By selecting this option, it will convert scanned PDF documents into searchable and editable documents.
- Image-only PDF: By selecting this option, it will convert your searchable and editable documents into an image-based PDF document which is neither searchable nor editable.
2.1 Document Type: Searchable PDF
If you go for "Searchable PDF," it will convert your scanned PDF documents into editable and searchable documents.
Layout:
To set this up, you must first decide on a proper "Layout" with the options available in the drop-down menu.
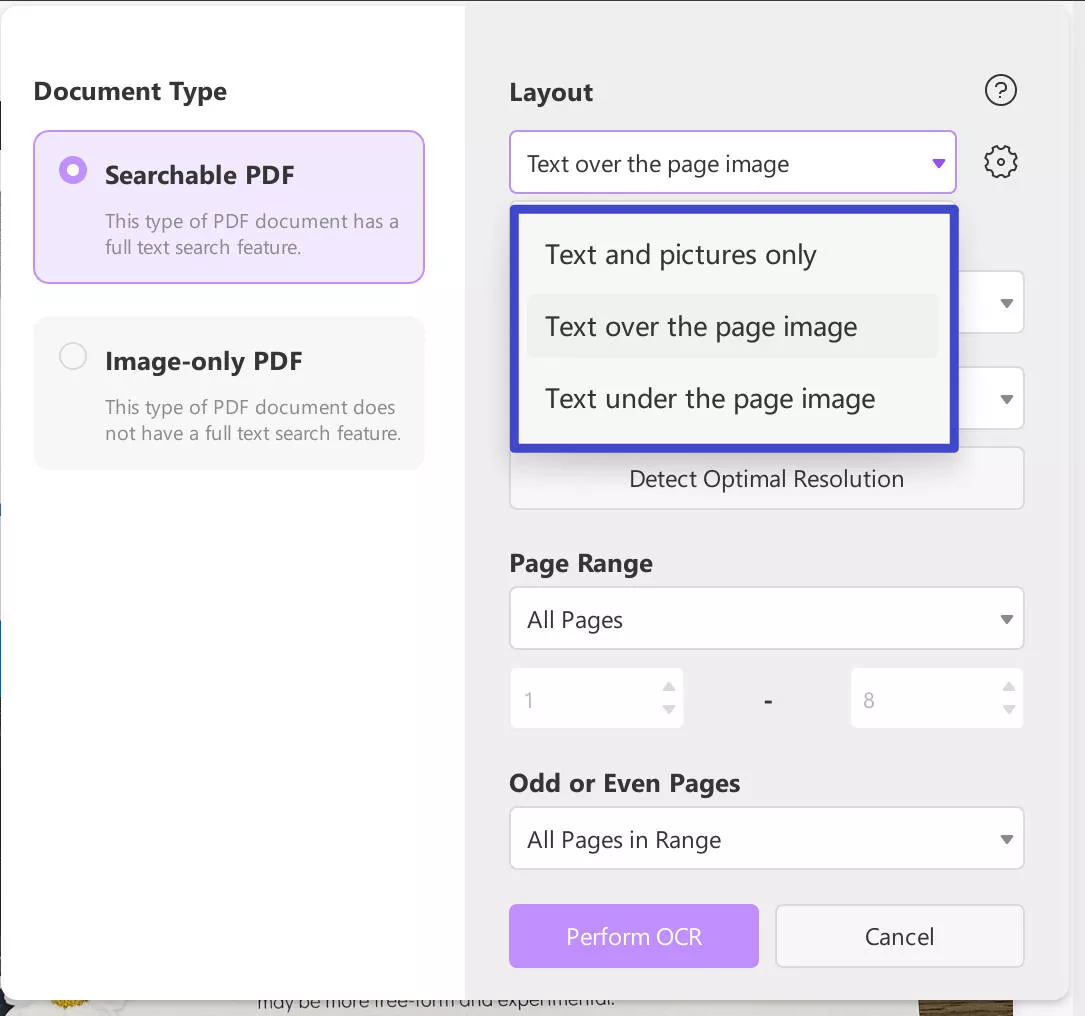
You will get three different options in setting up the layout of the process:
- Text and pictures only: The recognized text and pictures will be saved across the PDF document that will be created. The file that is created is also of a smaller size, and its visual structure may differ from the original file.

- Text over the page image: This mode is responsible for retaining the background images and illustrations present across the source document across which the OCR is being performed. These files are larger; however, they may differ visually from the original ones.

- Text under the page image: For this mode, the PDF images are retained; however, the recognized text is placed under an invisible layer beneath the images. This file type is quite identical to the original PDF file.

Click on the "Gear" icon to access more Layout Settings that you can define for your file. Here you can specify if you wish to "Keep pictures," while determining the quality between "Low," "Balanced," or "High" to save a file with a smaller size than the original with commendable image and picture quality.
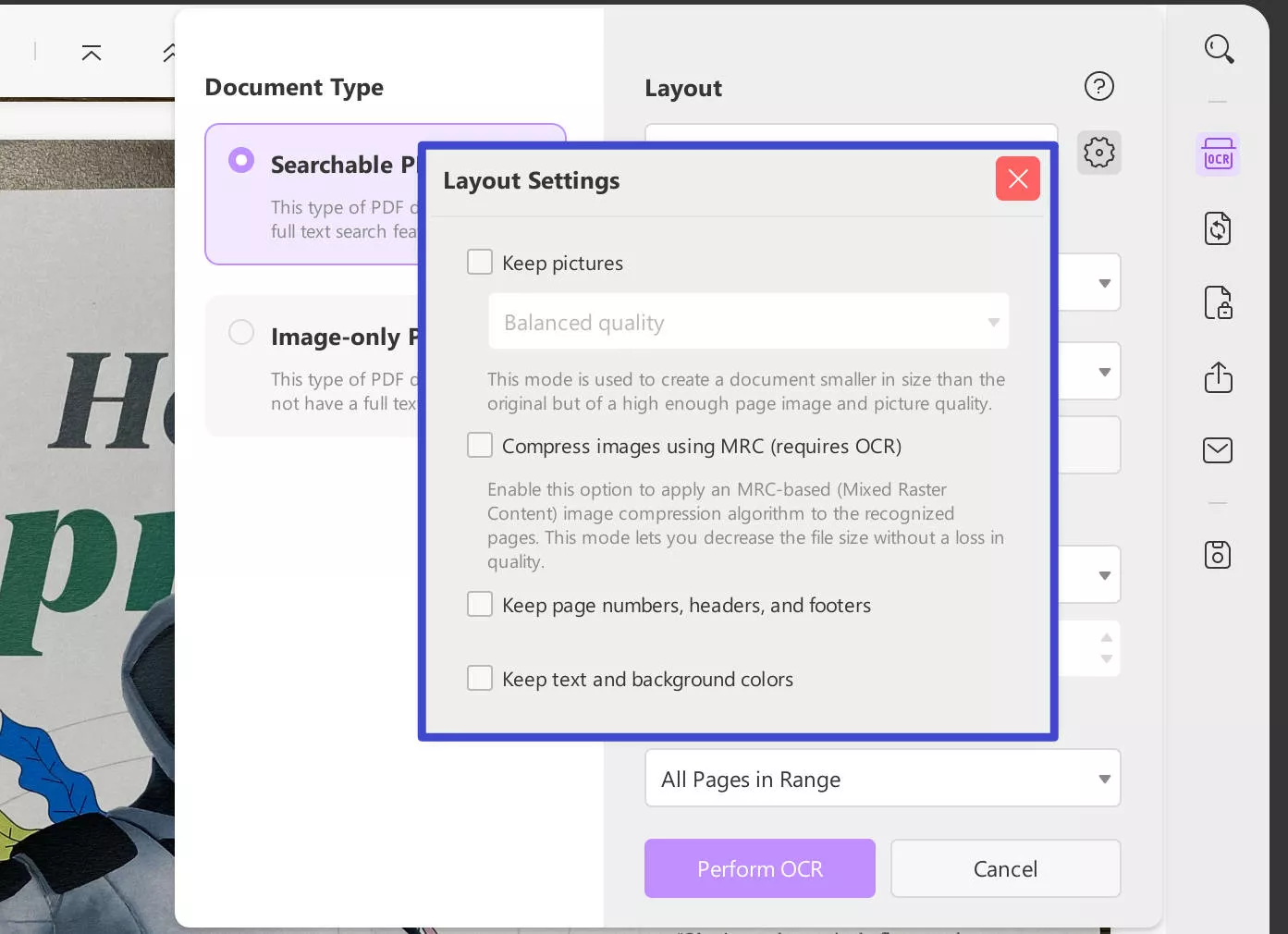
Document Language, Image Resolution, and Page Range:
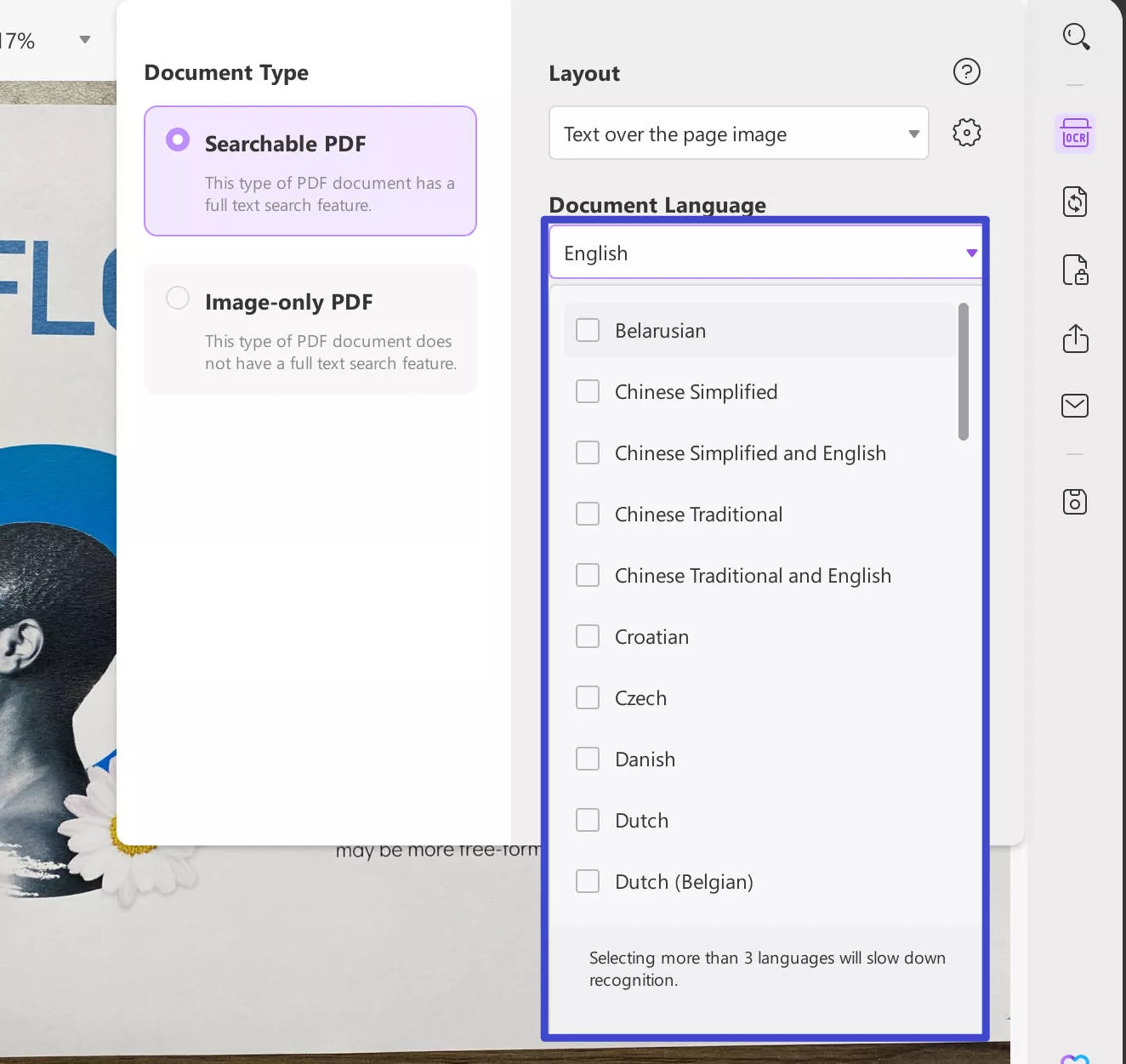
Define a proper "Document Language" with the option of 38 different languages across the drop-down menu. This provides UPDF with a better ground for recognizing text accurately across the document.
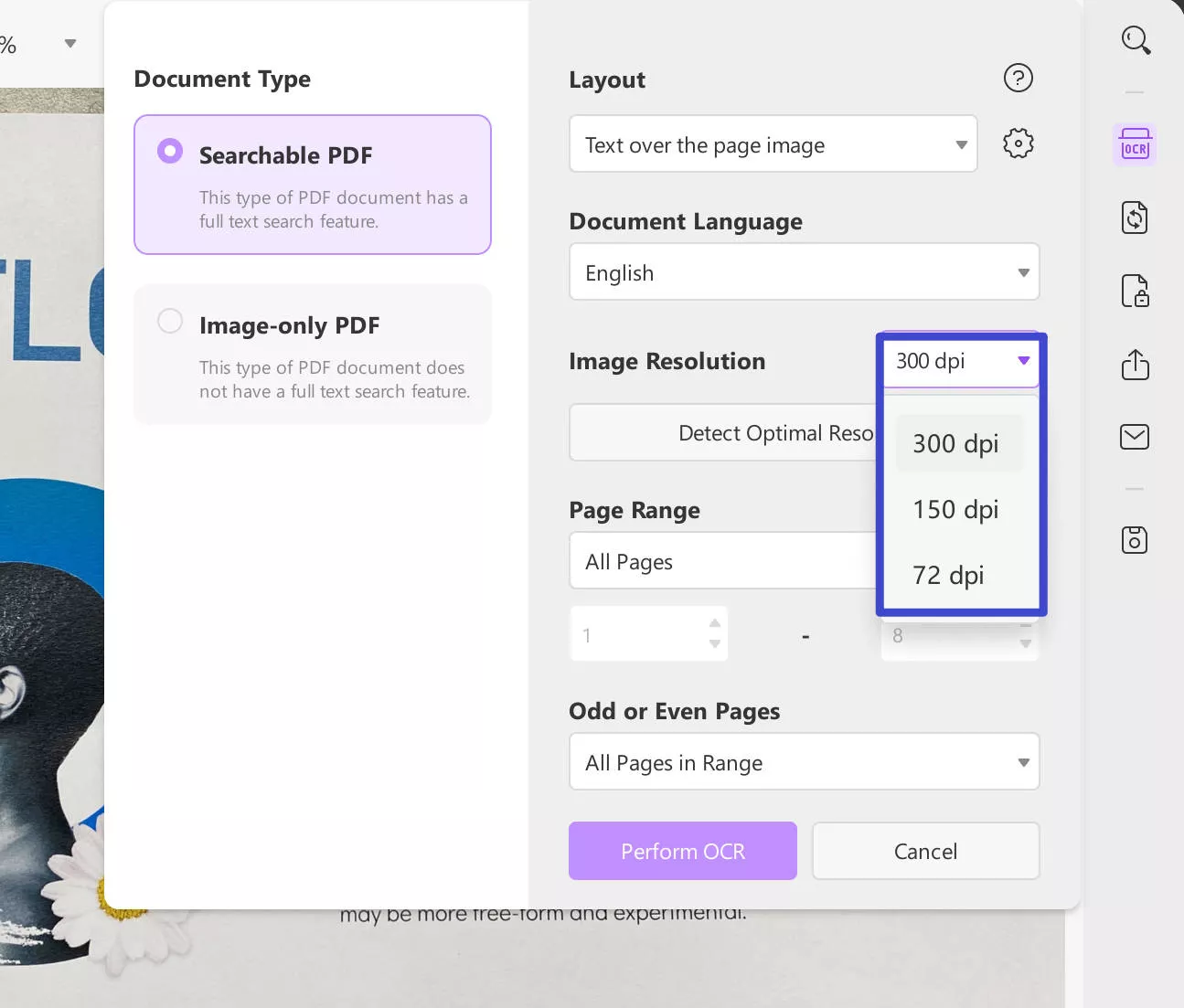
You can also specify proper resolution settings for the images with the "Image Resolution" option. Work over the "Page Range" and click "Perform OCR" to execute OCR across the file with the defined settings.
2.2. Document Type: Image-only PDF
If you proceed with "Image-only PDF," it converts your searchable and editable documents into an image-based PDF document which is neither searchable nor editable.
- Set up the image quality under the "Keep Pictures" section by selecting any of the available options of "Low, Balanced, or High".
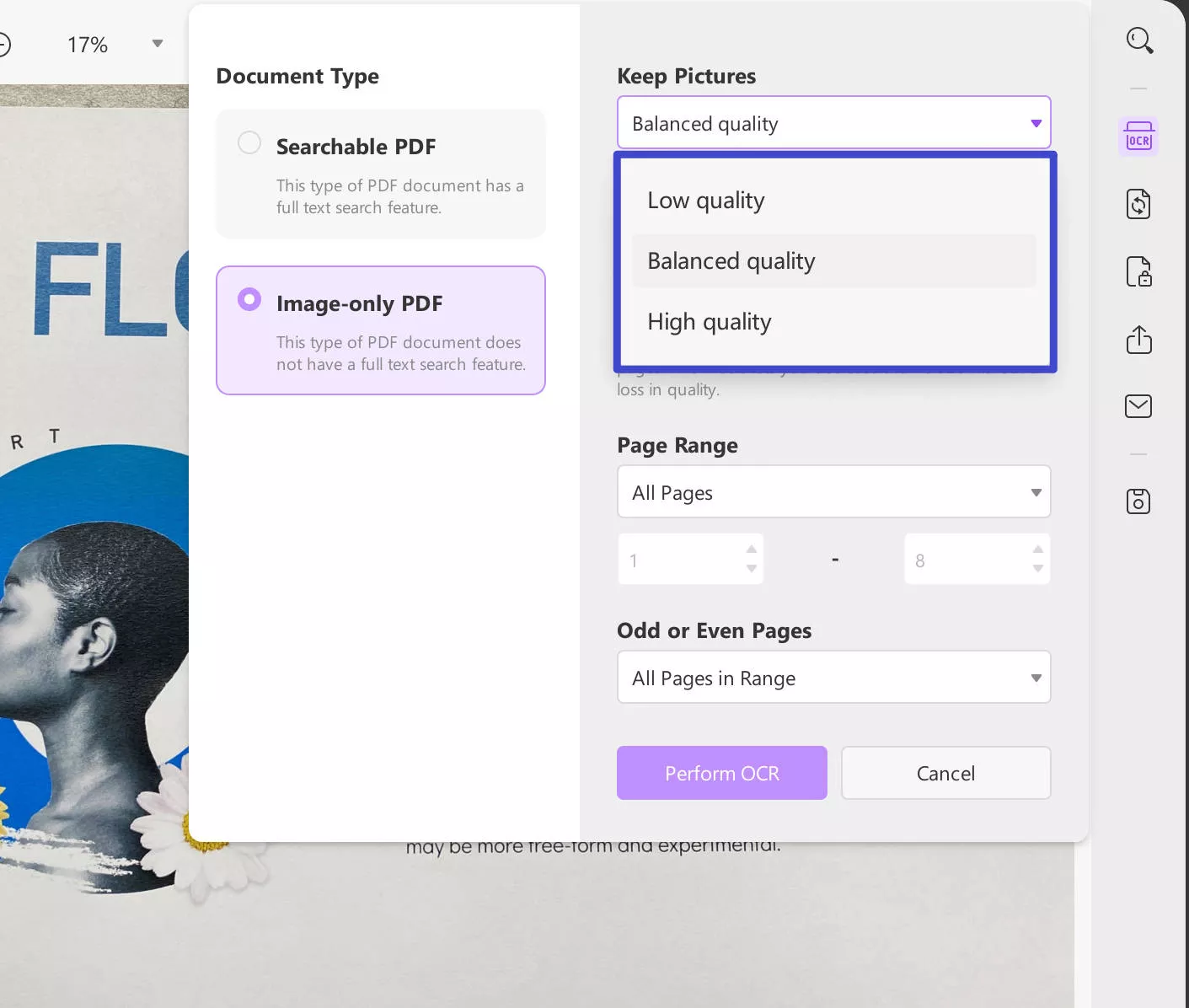
- Decide if you wish to compress your images using MRC. This mode let you decrease the file size without a loss in quality.
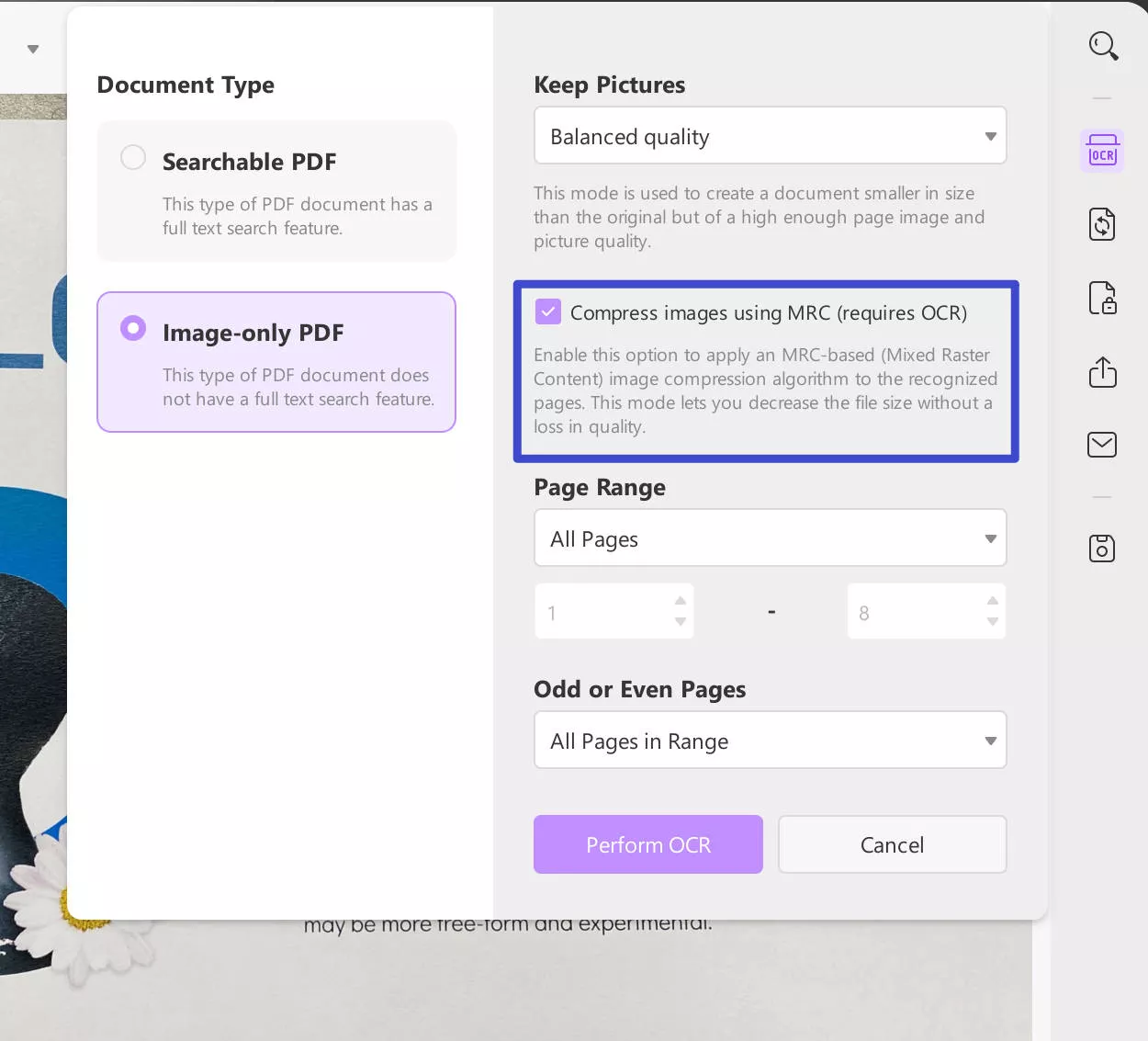
- Provide a proper "Page Range" and click on "Perform OCR" to perform the actions on the document. Select the folder and you will get a scanned PDF document immediately.
It is free to test the OCR feature in the free trial version. But you can only experience and cannot save, copy, and edit the OCRed PDF. To have all the features you need, you can upgrade to pro version.