Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
スキャンしたPDFをワード(Word)に変換して、Microsoftソフトウェアで編集できるようにする方法は何ですか。
スキャンしたPDF、または編集不可能なPDFをワードに変換するには、OCRまたは光学式文字認識と呼ばれる特別なプロセスが必要です。
OCRを使用してドキュメントを処理したら、PDFをWordファイルに変換できます。
この記事では、WindowsおよびMacでスキャンしたPDFをワードに変換する最も効果的で便利な方法を紹介します。
スキャンしたPDFとは何ですか?
紙のドキュメントをスキャンして電子版にすることで、PDFは作成できます。これは、紙のドキュメントの画像をキャプチャして、スキャナーで電子PDFファイルとして保存することで実行される手段の一つです。
スキャナーがこのスキャン画像を作成するとき、すべての単語の各文字が複製されるわけではありません。それは、紙のドキュメントの「スナップショット」のみを取得するのです。
次に、このスキャン画像はスキャナーに付属のソフトウェアにPDFドキュメントとして変換されます。その結果、「スキャンされた」PDFドキュメントが生成されます。
そのようなPDFのコンテンツは、検索または変更できません。OCRにより、そのコンテンツを認識し、スキャンしたPDFを検索または編集するために使用可能な形式に変換する必要があります。基本的には、画像からテキストを認識して抽出することができます。
最高のPDFをスキャンしてwordに変換するソフト
38種類言語を超えてをサポートするUPDFは、WindowsおよびMacで最も強力な変換ツールの1つです。
スキャンした文書をOCRで変換するには、非常に高い精度が必要なのです。
それに対して、UPDFはその変換に強力なOCR機能を使用します。最終的な出力は、元のドキュメントと同じレイアウトとフォーマットを持つPDFドキュメントになります。
以下のボタンをクリックして、UPDFをダウンロードしましょう!
Windows • macOS • iOS • Android 100%安全
UPDFの主な機能と使い方を見てみましょう。
変換機能
- ワード、Excel、PPT、画像形式、HTML、XML、テキスト、RTFなど、多くの一般的な出力形式をサポートする専用のPDF変換ツール。
- スキャンしたPDFを編集可能なワード形式に変換するOCR機能。
- 変換中にフォーマットの一貫性が保たれます。手作業による修正は最小限で済みます。
その他の機能
- PDFの編集、PDFにコメントをかける、PDFドキュメントの保護なども可能なので、UPDFはオールインワンソリューションです。
OCR機能でスキャンしたPDFをワードに変換する方法
スキャンしたPDFをワードに変換して、必要な場所で使用できるようとしますか?
テキストを入力する代わりに、UPDFが提供するOCRを使用すれば、PDFをワードに簡単に変換できます。
これによって、UPDFでスキャンしたPDFをワードに変換し、ドキュメントのテキストデータを取得することは優れたオプションようですね。
その手順を知るには、以下の内容を見てください。
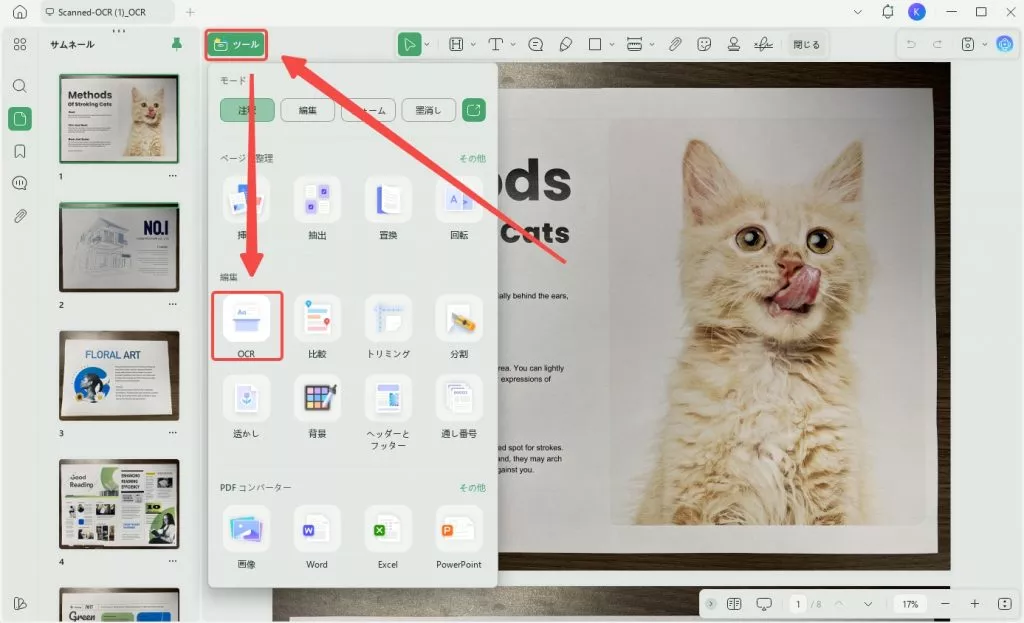
ステップ1:OCRドキュメント・タイプの定義
PDFを開いた後、左上隅にある「OCR」ボタンをクリックします。
そして、ポップアップウィンドウで「検索可能なPDF」を選択し、プロセスを続行します。
ステップ2:レイアウトを設定する
OCRツールのパラメータの設定からはじめ、このプロセスの「レイアウト」設定をセットアップする必要があります。
そのために、以下に説明する3つの異なるレイアウト設定が提供されます。
- テキストと写真のみ:このレイアウト設定では、すべてのテキストと画像がPDFドキュメントに保存されます。作成されるファイルには、元のファイルよりもサイズが小さく、特定の書式設定がありません。
- ページ画像上のテキスト:この特定のモードには、OCRプロセス中に設定されたデフォルトですが、元のファイルに応じた画像とイラストが含まれています。そのサイズが大きいですが、元のPDFドキュメントとそれほどの違いがありません。
- ページ画像の下のテキスト:この特定のモードでは、元のPDFドキュメントの完全な画像構造が保持されます。そのテキストはドキュメントの画像レイヤーの下にあるため、編集できませんが、検索可能です。
完了したら、「ドキュメントの言語」セクションに進み、検出する特定の言語を選択する必要があります。メニューで利用可能な38の言語から適切な言語を選択できます。
ステップ3:スキャンしたPDFを編集可能なWordに変換する
次に、機能を実行したいページ範囲を指定し、「OCR」をクリックします。編集可能なPDFに変換できるように、変換されたドキュメントの適切な場所を設定します。
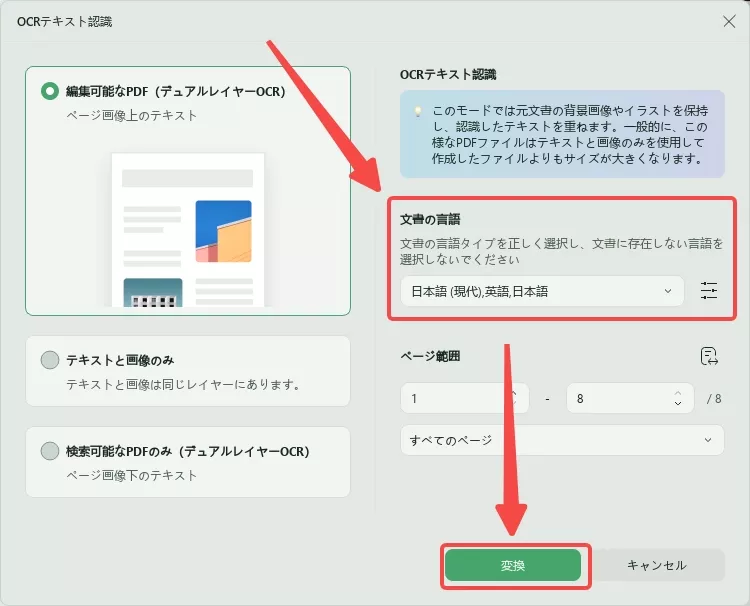
これで、PDFを編集できます。ただし、ワード形式に変換する場合は、UPDFの「PDFコンバーター」機能を使用して、PDFをワードに変換できます。PDFをワードに変換する手順は次のとおりです。
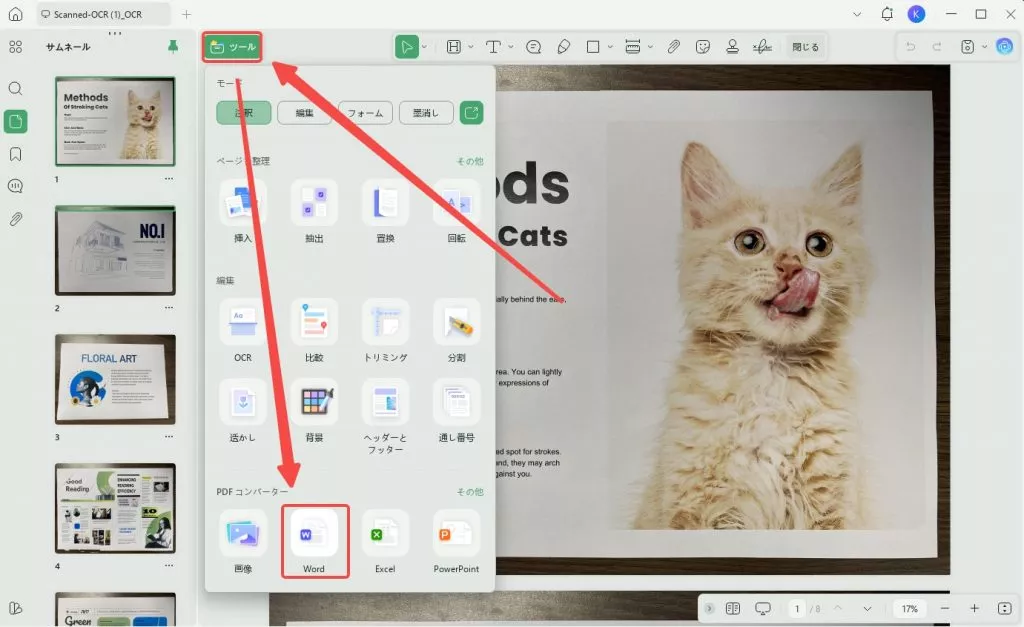
- UPDFでPDFファイルを開き、左上隅にある「ツール」で「PDFコンバーター」へ移動します。
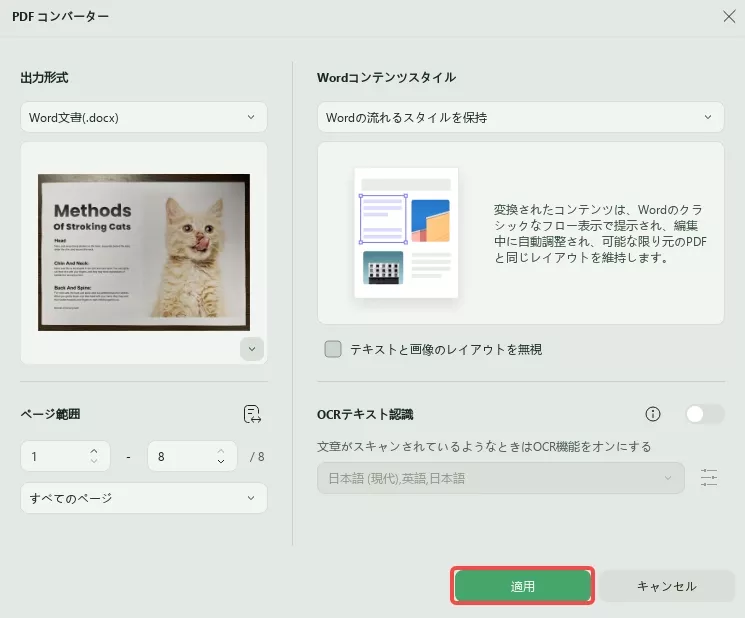
- 「Word」アイコンをタブし、ポップアップウィンドウで「適用」をクリックします。
- ファイルに名前を付けて、デバイスのフォルダーに保存します。
特にスキャンしたファイルに手書きが含まれている場合、一部のフォントは正確に変換されない場合がありますが、コンテンツは可能な限りスキャンしたコピーに近くなります。
スキャンしたPDFをワードに変換する方法に関するビデオチュートリアル
以下のボタンをクリックして、UPDFをダウンロードしましょう!
Windows • macOS • iOS • Android 100%安全
スキャンしたPDFファイルをワードへの変換で一般的な問題
ほとんどの場合には、OCR機能がスキャンしたPDFファイルを変換できます。
ただし、すべてのファイルが同じ効果となるわけではありません。
何よりもまず、プログラムでOCR機能が有効になっていることを確認してください。
スキャンしたファイルを開いてWordに変換する前に、OCR設定に移動し、OCRを使用して変換を選択します。
ファイルが変換されなければ、多分ドキュメント内の文字間のギャップが近すぎて、OCRが各文字を検出できない可能性もあります。
また、OCRの結果を損なうのは、スキャンされたドキュメントの画質が悪い、フォントの組み合わせ、イタリック体と下線付きの書体が明瞭さと形状を曖昧にする可能性があります。
その結果、OCRソフトウェアによって「認識された」文字がスキャンされた紙の文字に対応することを確認することは、はるかに困難となります。
しかし、UPDFのOCR機能を使用すると、完璧な結果と精度が得られるため、これらの問題を心配しなく大丈夫です!。
以下のボタンをクリックして、UPDFのOCR機能を試してみてください。
Windows • macOS • iOS • Android 100%安全
よくある質問
Q1.OCR(光学式文字認識)とは?
光学式文字認識(OCR)というのは、テキスト画像を認識可能のテキスト形式に変換するプロセスです。
たとえば、フォームや領収書をスキャンするときに、コンピューターはスキャンを画像ファイルとして保存します。
その画像ファイルには、テキストエディターを使用して、画像ファイル内の単語を変更、検索、またはカウントすることができません。
ただし、OCRを通じて、画像をテキストドキュメントに変換し、内容をテキストデータとして保存することはできます。
ビジネスワークフローの大部分では、印刷媒体から情報を取得する必要があります。
ビジネスプロセスには、紙のフォーム、請求書、スキャンされた法的文書、および印刷された契約書が含まれます。
これらの膨大な量の事務処理は、保管および処理にかなりの時間とスペースを必要とします。ペーパーレスのドキュメント管理が進むべき道ですが、ドキュメントをスキャンして画像にするのは実際に困難です。
この手順には手作業が必要であり、時間がかかり、非効率的である可能性があります。
さらに、この文書コンテンツをデジタル化すると、テキストを含む画像ファイルが生成されます。
イメージテキストは、テキストドキュメントと同じようにワープロソフトウェアで処理することができません。
だが、テキスト画像を他のビジネスアプリが評価できるデータに変換することで、OCRテクノロジーはそれを解決しました。その後、データを分析、運用の合理化、手順の自動化、生産性の向上に使用できます。
Q2.スキャンされたPDFとは何ですか?
PDF文書は、紙文書をスキャンして電子版にすることで作成できます。
これは、紙文書の画像をキャプチャし、電子PDFファイルとして保存するスキャナまたは同様のマシンを選択することによって実行されます。
スキャナーがすべての単語の各文字を複製せずに、紙の文書の「スナップショット」を取得することで、このスキャン画像を作成します。
そして、スキャナ付属のソフトウェアがその写真をPDF文書に変換します。その結果、「スキャンされた」PDF文書が作成されます。
Q3.ネイティブPDFファイルとは何ですか?
ネイティブPDFは、「デジタルで生まれた」文書のPDFである。それは、印刷版ではなく電子版の文書から作成されたことを意味します。
一方、ネイティブPDFは印刷ジャーナルからページをスキャンしてファイルをPDFとして保存するとき、印刷ドキュメントのスキャンされたPDFです。
Q4.スキャンしたPDFとネイティブPDFの違いは何ですか?
スキャンしたPDFとネイティブPDFの違いを知りたいですか?
スキャンPDFは、特定のドキュメントのスキャンイメージで構成されるPDFです。スキャンしたPDFは画像の集まりであるため、ユーザーはテキストを検索できないのです。
一方、ネイティブPDFは、デジタルで「生まれた」文書のPDFです。つまり、そのPDFは、Microsoft Word文書など、文書の元の電子バージョンから形成されたものです。
ProQuestデータベースの多くのコンテンツが「生まれた」デジタルであり、ネイティブPDFとして利用できます(一部の完全なテキストはASCII/HTMLでのみ利用可能ですけど)。
ちなみに、ProQuestデータベースに提供されるデジタル生まれの情報の割合は、年々増加しています。
Q5.スキャンしたPDFの種類は何ですか?
スキャンしたPDFは3つのカテゴリに分類されます。
①画像PDF - 最も一般的なPDFの種類は画像PDFです。これは、ハードコピードキュメントをスキャンしてPDFファイルにする場合に当てはまります。
②検索可能なテキストを含むスキャンしたPDF - このスキャンされたPDFドキュメントには、画像の背後に非表示のテキストが含まれている場合があります。
③コンテンツが混在するスキャンされたPDF - このPDFには、スキャンされた写真や電子的に生成されたPDF要素が含まれている場合があります。
結論
スキャンしたPDFをワードに変換する上記の紹介から、UPDFが最高のスキャンしたPDFからワードへの変換ソフトであることがわかりましたね。
手頃な価格で、専用で、幅広く用途で利用されるUPDFは、Windows、Mac、iOS、およびAndroidシステムで対応できます。さらに、PDFを他のさまざまな形式に変換して編集できます。
試してみて、日常のドキュメントワークフローに満足できるUPDFをダウンロードしましょう!
Windows • macOS • iOS • Android 100%安全