 Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF Nomostar
Nomostar UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
スキャンしたPDFをワードに変換しようとしても、文字を選択できなかったり、Wordに変換しても画像のままで編集できなかったりすることがあります。
これは、スキャンしたPDFが通常のテキストPDFではなく、紙の書類を画像として保存したPDFであるためです。編集可能なWord文書にするには、まずOCRで文字を認識し、そのうえでWord形式に変換する必要があります。
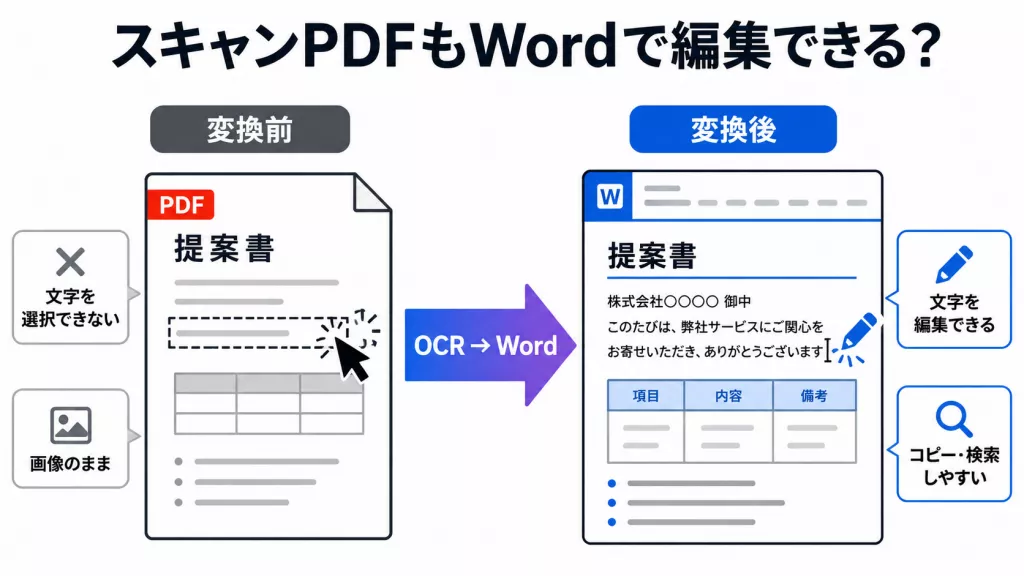
この記事では、スキャンしたPDFをワードに変換する仕組み、UPDFを使った具体的な手順、変換時によくある文字化け・レイアウト崩れの対策を解説します。
この記事でわかること
- スキャンしたPDFをワードに変換するにはなぜOCRが必要なのか
- UPDFでスキャンPDFをOCR処理し、Word形式に変換する手順
- 文字化け・レイアウト崩れ・認識ミスが起きる原因
- オンライン変換ツールとPDFソフトの使い分け
- スキャンPDFを安全にWord化するための注意点
1. 先に結論|スキャンしたPDFをワードに変換するにはOCRが必要
スキャンしたPDFをワードに変換するには、まずOCRで文字認識を行う必要があります。
通常のPDFであれば、そのままWord形式に変換できる場合があります。しかし、スキャンPDFは紙の書類を画像として保存したファイルのため、PDF内の文字をWordがテキストとして認識できないことがあります。
そのため、スキャンPDFを編集可能なWord文書にしたい場合は、「OCRで文字を読み取る」→「Word形式に変換する」という流れで作業します。
| PDFの状態 | そのままWord変換できる? | 必要な対応 |
|---|---|---|
| 文字を選択できるPDF | 変換しやすい | 通常のPDF変換で対応可能 |
| 文字を選択できないスキャンPDF | そのままでは難しい | OCRで文字認識してから変換する |
| 画像だけのPDF | 編集できないことが多い | OCR処理が必要 |
2. 変換前後の違い|スキャンPDFはWordでどこまで編集できる?
スキャンしたPDFをワードに変換すると、画像として保存されていた文字をOCRで認識し、Word上で編集しやすい状態にできます。
たとえば、紙の資料をスキャンしたPDFでは、変換前は文字を選択したりコピーしたりできない場合があります。OCRで文字認識を行ってからWord形式に変換すると、本文の文字を選択・修正できるようになり、文章の一部を差し替えたり、不要な行を削除したりしやすくなります。
ただし、変換結果はPDFの状態によって変わります。文字がはっきりした文書であれば比較的きれいに変換しやすい一方、表が多い資料、斜めにスキャンされた書類、手書き文字を含むPDFでは、文字化けやレイアウト崩れが起こることがあります。
| 比較項目 | 変換前のスキャンPDF | Word変換後 |
|---|---|---|
| 文字の選択 | できないことが多い | OCR後は選択できる場合がある |
| 文字の編集 | 画像扱いのため編集しにくい | Word上で修正しやすい |
| コピー・検索 | できない場合がある | テキストとして扱いやすい |
| レイアウト | 元の見た目のまま | 表や段組みは崩れる場合がある |
| 確認作業 | 不要な場合が多い | 文字化け・改行・表の位置を確認する必要がある |
そのため、スキャンPDFをワードに変換した後は、文字の認識結果、改行、表や画像の位置を必ず確認しましょう。特に契約書、請求書、申請書などの重要な文書では、変換後の内容チェックが欠かせません。
3. スキャンしたPDFとは?通常のPDFとの違い
スキャンしたPDFとは、紙の書類をスキャナーや複合機で読み取り、画像としてPDF化したファイルのことです。見た目は通常のPDFと同じように見えますが、内部では文字データではなく、ページ全体が画像として保存されている場合があります。
そのため、スキャンしたPDFでは文字を選択できない、コピーできない、検索できない、Wordに変換しても編集できないといった問題が起こることがあります。
一方、WordやExcelなどのデジタル文書から作成されたPDFには、文字データが含まれていることが多く、通常のPDF変換だけでWord形式に変換しやすいのが特徴です。
スキャンしたPDFをワードに変換して編集できる状態にするには、まずOCRで画像内の文字を認識し、テキストデータとして扱えるようにする必要があります。
4.スキャンPDFをワードに変換する方法の比較
スキャンPDFをワードに変換する方法には、OCR対応のPDFソフト、オンラインOCRツール、Googleドキュメントなどがあります。どの方法を選ぶべきかは、PDFの内容、機密性、変換後にどこまで編集したいかによって変わります。
たとえば、契約書や請求書、社内資料などを扱う場合は、オンラインツールにアップロードする前に注意が必要です。一方で、機密性の低いPDFを一度だけ変換したい場合は、オンラインOCRツールでも十分なケースがあります。
| 方法 | 向いている人 | メリット | 注意点 |
|---|---|---|---|
| OCR対応PDFソフト | 仕事用・機密性の高いPDFを扱う人 | PC上でOCR処理からWord変換まで進められる | ソフトのインストールが必要 |
| オンラインOCRツール | 機密性の低いPDFを一度だけ変換したい人 | インストール不要ですぐ使える | ファイルをアップロードする必要がある |
| Googleドキュメント | まず無料でテキスト化を試したい人 | 手軽に文字抽出できる | レイアウト保持や表の再現には弱い |
| 手入力 | ページ数が少ない・重要箇所だけ直したい人 | 認識ミスを避けやすい | ページ数が多いと時間がかかる |
仕事用のPDFや、個人情報・社内情報を含むPDFを扱う場合は、PC上でOCR処理とWord変換を行えるPDFソフトを使うと安心です。次の章では、UPDFを使ってスキャンしたPDFをワードに変換する具体的な手順を紹介します。
5. UPDFでスキャンしたPDFをワードに変換する方法
スキャンしたPDFをワードに変換するには、まずOCRでPDF内の文字を認識し、その後Word形式で書き出します。
ここでは、UPDFを使ってスキャンPDFを編集可能なWord文書に変換する手順を紹介します。
手順1. UPDFでスキャンPDFを開き、OCRを選択する
まず、UPDFを起動し、ワードに変換したいスキャンPDFを開きます。紙の書類をスキャンしたPDFや、文字を選択できない画像PDFもここで読み込めます。
PDFを開いたら、画面上の「OCR」機能を選択します。OCRの設定画面が表示されたら、用途に合わせてOCRの種類を選びます。スキャンPDFを検索・コピー・変換しやすくしたい場合は、「検索可能なPDF」を選択します。
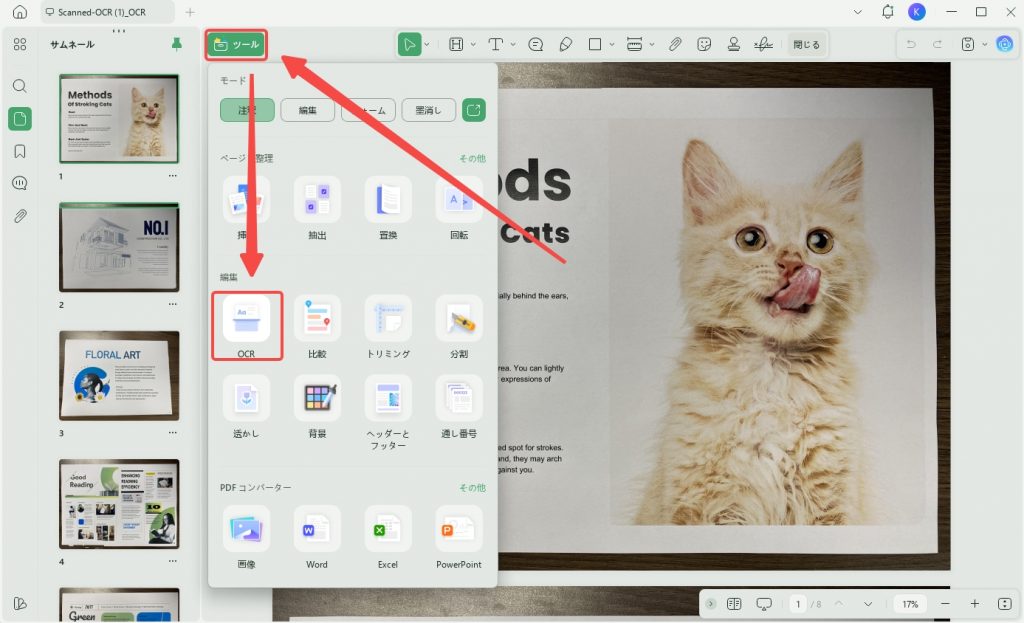
手順2. レイアウト・言語・ページ範囲を設定してOCRを実行する
次に、OCR後のレイアウト、ドキュメントの言語、ページ範囲を設定します。
| 設定項目 | 内容 | 確認ポイント |
|---|---|---|
| レイアウト | OCR後の表示形式を選択する | 編集しやすさや見た目の保持を考えて選ぶ |
| ドキュメントの言語 | 認識する言語を選択する | 日本語の書類なら「日本語」を選ぶ |
| ページ範囲 | OCRを実行するページを指定する | 必要なページだけ処理することも可能 |
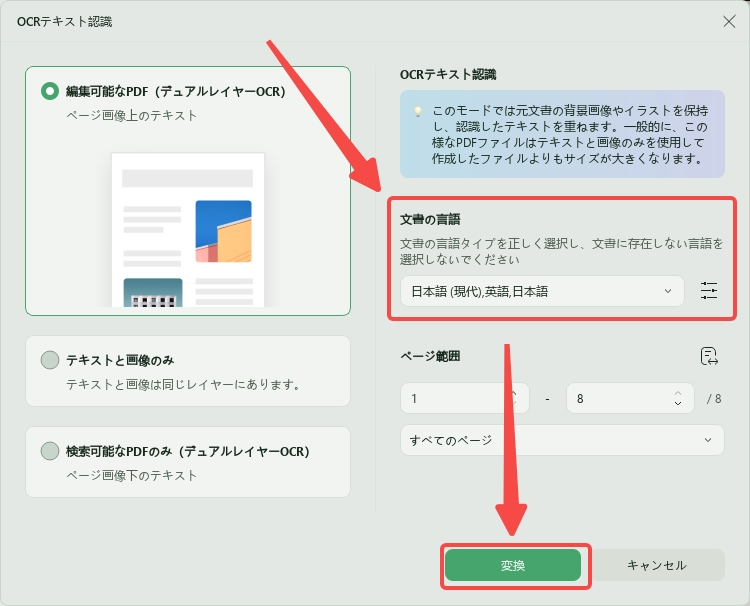
日本語の書類を変換する場合は、OCRの言語設定で「日本語」を選択しておきましょう。言語設定が合っていないと、文字化けや誤認識が起こりやすくなります。
設定が完了したら、「OCR」をクリックして文字認識を実行します。
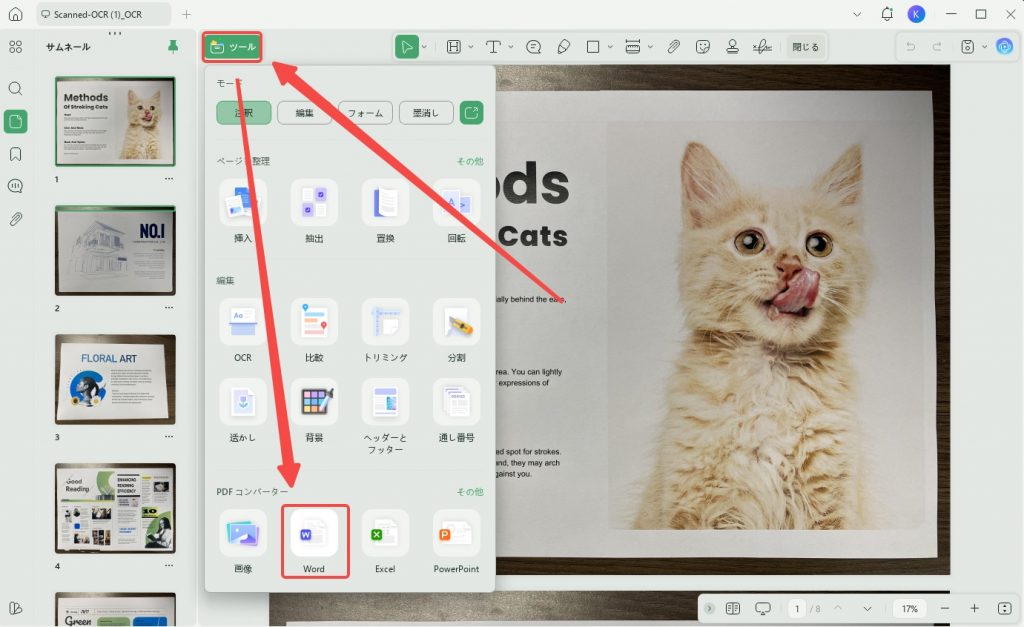
手順3. OCR後のPDFをWord形式に変換して保存する
OCR処理が完了したら、UPDFの変換機能を使ってPDFをWord形式に書き出します。
「ツール」から「PDFコンバーター」を選択し、出力形式として「Word」を選びます。その後、保存先とファイル名を指定して保存すれば、スキャンしたPDFをワード文書として開けるようになります。
変換後のWordファイルは、Microsoft Wordで開いて内容を編集できます。
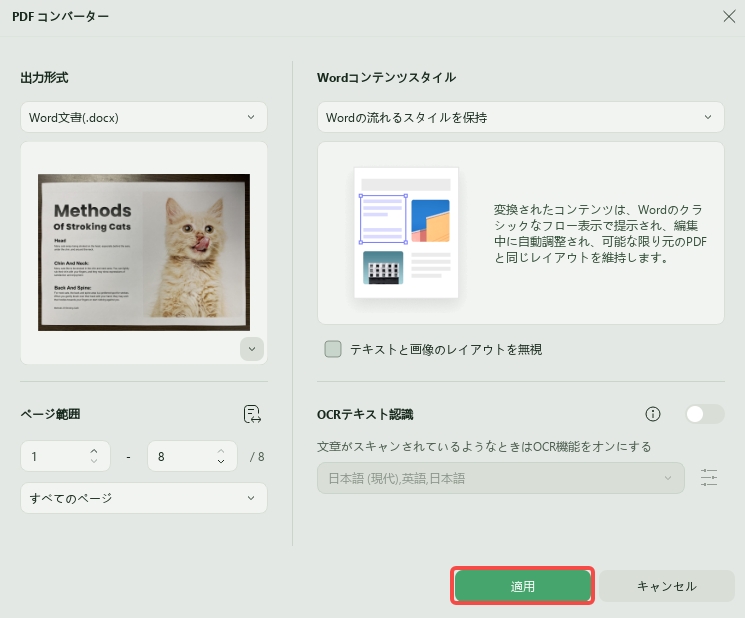
表、画像、段組みが多いPDFでは、変換後にレイアウトが一部崩れる場合があります。保存後は、文字の認識結果や改行、表の位置を確認しましょう。
スキャンしたPDFをワードに変換したい場合は、以下のボタンからUPDFをダウンロードして、OCR機能とWord変換機能を試してみてください。
Windows • macOS • iOS • Android 100%安全
6. スキャンPDFのWord変換にUPDFが向いているケース
UPDFは、スキャンPDFのOCR処理からWord形式への変換まで同じソフト内で進められるため、仕事用のPDFや編集作業が必要な文書に向いています。
特に、次のような場合に使いやすい方法です。
| ケース | UPDFが向いている理由 |
|---|---|
| 契約書や請求書をWordで修正したい | PC上でOCR処理とWord変換を進めやすい |
| 文字を選択できないPDFを編集したい | OCRで文字認識してからWord形式に変換できる |
| 複数ページの紙資料をデータ化したい | ページ範囲を指定してOCR処理できる |
| 変換後にPDFも編集したい | PDF編集、注釈、ページ整理も同じソフト内で行える |
| オンラインにアップロードしたくない | ローカル環境で作業しやすい |

スキャンPDFをWord文書として編集したい場合は、UPDFをダウンロードしてOCR機能とWord変換機能を試してみてください。
7. スキャンしたPDFをワードに変換できない・失敗する原因
スキャンしたPDFは、OCRで文字認識を行うことでWord形式に変換できます。ただし、PDFの状態によっては、文字化けが起きたり、レイアウトが崩れたり、文字を正しく認識できなかったりする場合があります。
ここでは、スキャンしたPDFをワードに変換するときによくある原因と対処法を紹介します。
OCR処理をしていない
スキャンPDFをそのままWordに変換すると、文字が画像のまま残り、Word上で編集できない場合があります。
文字を選択できないPDFや画像PDFを編集可能なWord文書にしたい場合は、変換前にOCRで文字認識を行いましょう。
スキャン画像の画質が低い
文字がぼやけている、斜めにスキャンされている、解像度が低いPDFでは、OCRの認識精度が下がることがあります。
できるだけ鮮明なPDFを使用し、必要に応じてスキャンし直すことで、変換結果が安定しやすくなります。
OCRの言語設定が合っていない
日本語の書類を変換する場合、OCRの言語設定が日本語になっていないと、文字化けや誤認識が起こることがあります。
スキャンしたPDFをワードに変換する前に、OCR設定で文書の言語を確認しておきましょう。
表やレイアウトが複雑
表、画像、段組み、注釈が多いPDFでは、Word変換後にレイアウトが完全に再現されない場合があります。
変換後は、文字の認識結果だけでなく、改行、表の位置、画像の配置も確認することが大切です。
手書き文字や特殊なフォントが含まれている
OCRは印刷文字の認識に向いていますが、手書き文字や装飾性の高いフォントは正しく認識されにくい場合があります。
重要な文書を変換する場合は、変換後のWordファイルを必ず確認し、必要に応じて手動で修正しましょう。
UPDFを使えば、スキャンPDFのOCR処理からWord形式への変換まで同じソフト内で進められます。文字を選択できないPDFを編集可能なWord文書にしたい場合は、以下のボタンから試してみてください。
Windows • macOS • iOS • Android 100%安全
よくある質問
Q1. スキャンしたPDFをそのままワードに変換できますか?
文字を選択できるPDFであれば、そのままWord形式に変換できる場合があります。ただし、スキャンしたPDFは画像として保存されていることが多いため、そのまま変換してもWord上で編集できない場合があります。編集可能なWord文書にするには、OCRで文字認識を行ってから変換する必要があります。
Q2. OCRとは何ですか?
OCRとは、画像として保存された文字を読み取り、検索・コピー・編集できるテキストデータに変換する技術です。スキャンPDFや画像PDFをワードに変換する場合、OCRを使うことで、画像内の文字をWordで編集しやすい形にできます。
Q3. スキャンPDFをワードに変換すると文字化けしますか?
PDFの状態によっては、文字化けや誤認識が起こることがあります。特に、画質が低いPDF、斜めにスキャンされた書類、文字が小さい書類、言語設定が合っていないPDFでは注意が必要です。日本語の書類を変換する場合は、OCRの言語設定で日本語を選択してから変換しましょう。
Q4. スキャンPDFをワードに変換するとレイアウトは崩れますか?
表、画像、段組み、注釈が多いPDFでは、Word変換後にレイアウトが一部崩れる場合があります。シンプルな文書であれば比較的きれいに変換しやすいですが、変換後は文字の認識結果、改行、表の位置、画像の配置を確認することをおすすめします。
Q5. オンラインでスキャンPDFをワードに変換しても安全ですか?
機密性の低いPDFを一度だけ変換する場合は、オンラインツールも便利です。ただし、契約書、請求書、履歴書、社内資料などを扱う場合は、PDFを外部サービスにアップロードする前に注意が必要です。重要なPDFは、PC上でOCR処理とWord変換ができるソフトを使う方が安心です。
まとめ
スキャンしたPDFをワードに変換するには、通常のPDF変換だけでなく、OCRによる文字認識が必要です。文字を選択できないPDFや画像PDFでも、OCR処理を行うことで、Wordで編集しやすい文書として活用できます。
ただし、PDFの画質やレイアウトによっては、文字化けや配置崩れが起こる場合があります。変換後は、文字の認識結果、改行、表や画像の位置を確認することが大切です。
UPDFを使えば、スキャンPDFのOCR処理からWord形式への変換まで同じソフト内で進められます。紙の資料や文字をコピーできないPDFを編集可能なWord文書にしたい場合は、以下のボタンからUPDFをダウンロードして試してみてください。
Windows • macOS • iOS • Android 100%安全










 Lizzy Lozano
Lizzy Lozano