 Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF Nomostar
Nomostar UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
スキャンしたPDFをテキスト化することは、変換ツールに見られる光学式文字認識またはOCR機能を使用して簡単になりました。この機能により、スキャンしたPDFや画像ベースのPDFを簡単に編集可能なバージョンに変換することができます。最適なツールは、変換に使用できるOCR機能を備えたUPDFです。スキャンしたPDFをテキストに変換するOCRを使用する方法を学ぶには、この記事をお読みください。
Windows • macOS • iOS • Android 100%安全
OCR搭載ベストスキャンしたPDFテキスト化ツール
UPDFは、HTML、XML、テキスト、CSV、Excel、Word、JPEG、TIFF、BMPなど、様々な編集可能なバージョンへのハイレベルなPDF変換を提供するために作成されました。それは正確な変換と一貫性のあるフォーマットを提供します。このツールは、他の同様のツールから例外となる優れた機能を備えています。そのシンプルなインターフェイスで、数回クリックするだけで、数秒以内に変換作業を完了することができます。
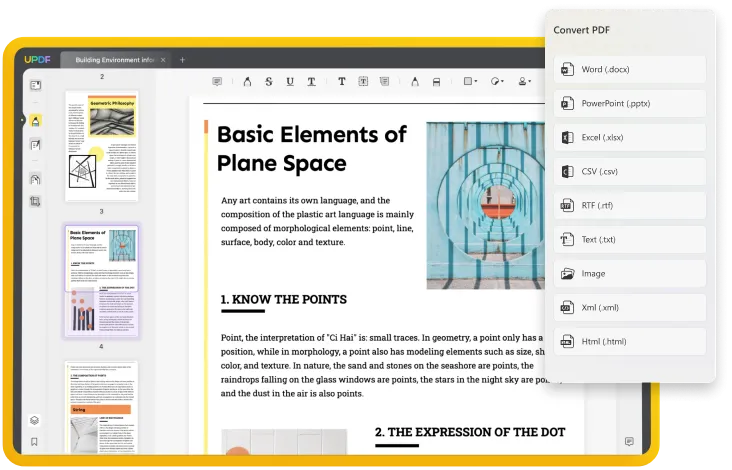
このツールは、そのOCRまたは光学式文字認識機能を持つ他の編集可能なフォーマットへの画像ベースまたはスキャンしたPDFの変換をサポートしているので、汎用性があります。また、より効率の良いPDF上のテキストや画像の変更など、PDF文書の編集をサポートしています。
主な機能
- そのフレンドリーで直感的なインターフェースは、簡単に使い方を学ぶことができます。
- もう一つの素晴らしい点は、UPDFがWindows、Mac、iOS、Androidを含む全てのプラットフォームで利用できることです(機能はバージョンによって異なります)。
- このツールはPDFエディタでもあり、テキストや画像を簡単に編集することができます。
- PDF注釈ツールでもあり、数秒以内に同時にマークアップすることができます。
- OCR機能は、30以上の言語をサポートしています。
- 変換速度は超高速で、元のファイルと同じ品質を保ちます。
- 変換されたファイルはリンク、メール、QRコードを介して他の人と共有することができます。
- PDFの順序を変更したい場合は、また、PDFの順序を変更するには、ページの整理ツールを使用することができます。ページの挿入、置換、抽出、分割、削除もできます。
- ファイルが大きすぎるは、ファイルを圧縮することもできます。
Windows • macOS • iOS • Android 100%安全
OCRでスキャンしたPDFをテキスト化する方法
スキャンしたPDFからテキストを編集・検索することはできません。OCRを使ってテキストに変換することができます。UPDFはWindowsとMacの両方でOCR機能をサポートすることができます。OCRでスキャンしたPDFをテキストに変換する手順では以下の通りです:
ステップ1: スキャンしたPDFを追加する
OCRでスキャンしたPDFからテキストへの変換を開始するプログラムを起動します。ドラッグして、インターフェイスにストレージデバイスから変換したいPDFファイルをドロップします。PDFを開く ためのもう一つのオプションは、ツールにファイルをアップロードする「ファイルを開く」ボタンをクリックしています。
ステップ2: OCRの設定
まずPDFを開き、右側の「OCRを使用してテキストを認識する」ボタンを押します。メニューが開くので、「ドキュメントの種類」タブをクリックし、「検索可能なPDF」を選択します。
次に「レイアウト」設定でレイアウトを指定します。「テキストと画像のみ」または「ページ画像にテキストを重ねる」を選択し、注意すべき高度なレイアウトオプションがある場合は、「歯車」アイコンを選択し、オプションを操作します。
その下で、文書言語を定義することができます。また、「画像解像度 」の設定もできます。どの設定が最適か分からない場合は、「最適解像度を検出」ボタンをタップして進みます。
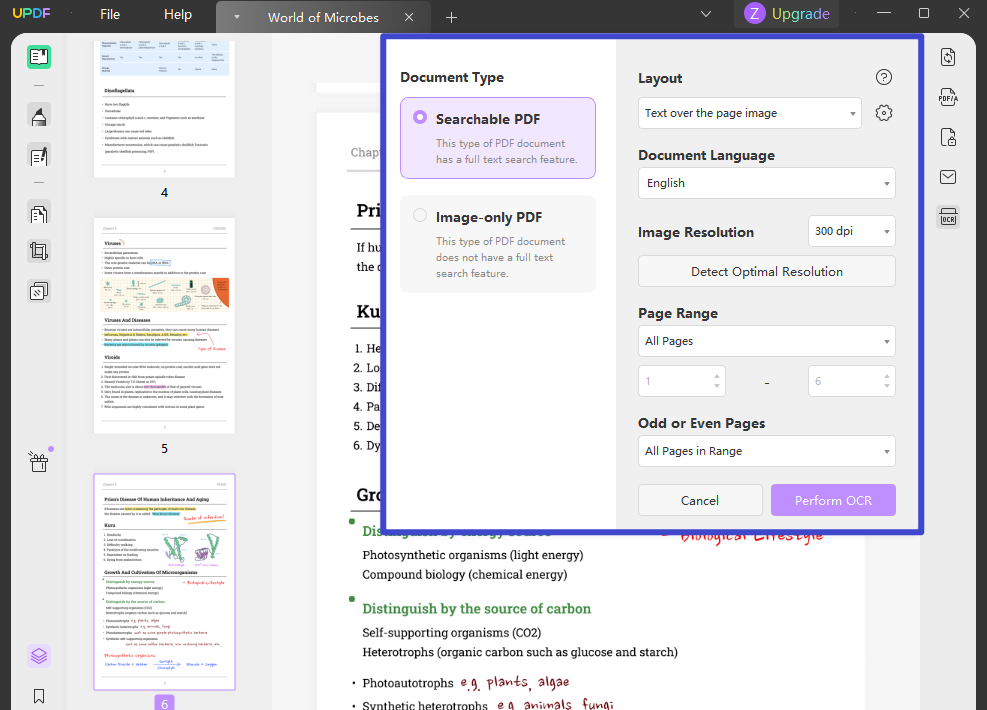
ステップ3: テキスト化するためのPDFをスキャンする
OCRツールを実行したいページ範囲で作業します。続いて「OCRを実行」ボタンを選択し、保存されたOCRドキュメントの場所を定義して、処理を実行させます。実行が完了すると、UPDFが開き、UPDF内でテキストを直接編集することができます。
ステップ4: スキャンしたPDFをテキスト化
スキャンしたPDFがUPDFにインポートされたら、右上にある「PDFをエクスポート」オプションをクリックします。「PDFをエクスポート」オプションをクリックするとすぐに小さなウィンドウが画面に表示されます。メニューオプションからテキストとして出力形式を選択します。「エクスポート」ボタンをクリックすると、すぐに変換が開始されます。ファイルは変換されると、選択したフォルダに保存され、画面上に表示されます。デフォルトのテキストエディタで開くには、ダブルクリックしてください。
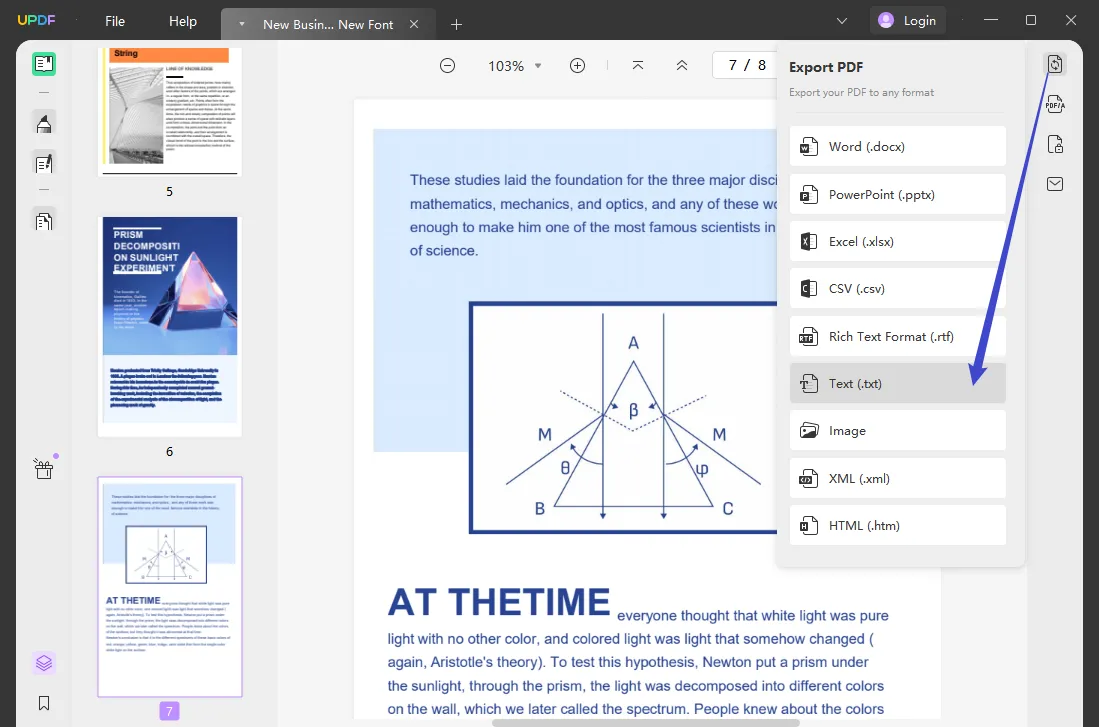
まとめ
UPDFはOCRオプションでスキャンしたPDFを簡単にテキストに変換することができます。このツールを使用して、スキャンしたPDFファイルからテキストや文字を他の形式に抽出することができます。このツールは、30以上の言語をサポートするOCRを備えています。オールインワンPDFエディタとして、PDFページの読み込み、編集、注釈、保護、整理をするために使用することができます。逃したら後悔すること間違いなしの最高のツールです。今すぐダウンロードして無料でお試しください!
Windows • macOS • iOS • Android 100%安全










