UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools KI-Lesezeichen-Generierung
KI-Lesezeichen-Generierung KI-Lesezeichen-Zusammenfassung
KI-Lesezeichen-Zusammenfassung KI-Wasserzeichen-Generierung
KI-Wasserzeichen-Generierung KI-Hintergrund-Generierung
KI-Hintergrund-Generierung KI-Sticker-Generierung
KI-Sticker-Generierung KI-Stempel-Generierung
KI-Stempel-Generierung KI-Schreibtools
KI-Schreibtools UPDF Copilot
UPDF Copilot KI-Seitenverwaltung
KI-Seitenverwaltung KI-Semantische Suche
KI-Semantische Suche PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Stellen Sie sich vor, Sie möchten einen Artikel aus einer Zeitschrift digitalisieren. Das erneute Abtippen und anschließende Korrigieren kann jedoch viel Zeit in Anspruch nehmen. Alternativ können Sie alle benötigten Inhalte mithilfe eines Scanners (oder einer elektronischen Kamera) und einer OCR-Software in kurzer Zeit digitalisieren.
Jetzt fragen Sie sich vielleicht: Was ist OCR? In diesem Artikel erfahren Sie alles Wichtige über OCR, seine Vorteile und wie Sie den größtmöglichen Nutzen daraus ziehen können. Außerdem stellen wir Ihnen eine leistungsstarke OCR-Software vor, mit der Sie bildbasierte PDFs in durchsuchbare und bearbeitbare Dokumente umwandeln können. Klicken Sie auf die Schaltfläche unten und testen Sie es selbst, um OCR besser zu verstehen.
Windows • macOS • iOS • Android 100% sicher
Teil 1: Was ist OCR?
Die erste Frage, die sich hier stellt, ist: Wofür steht OCR? OCR steht für „Optical Character Recognition“ (Optische Zeichenerkennung). Es handelt sich um ein Verfahren zur Erkennung und Analyse von Text auf Seiten sowie zur Umwandlung der Zeichen in Code, der zur Datenverarbeitung genutzt werden kann. Einfach gesagt: Es ist eine Technik, um Text in gescannten Dokumenten und Bildern zu erkennen.
OCR-Systeme bestehen aus Software- und Hardwarelösungen, die physische Dokumente in maschinenlesbaren Text (eine elektronische Version) umwandeln.
Darüber hinaus können Nutzer nach der Speicherung im OCR-PDF-Format Stil, Design und Inhalte der Dokumente bearbeiten und analysieren – ähnlich wie bei einem Textverarbeitungsprogramm.
Ein Beispiel: Wenn Sie ein Foto oder Dokument mit einem Drucker scannen, erstellt der Drucker eine digitale Bilddatei. Diese Datei kann im PDF-, JPG- oder TIFF-Format vorliegen, bleibt jedoch zunächst nur ein Abbild des Originals. Laden Sie dieses gescannte Dokument in eine OCR-Software, erkennt diese den enthaltenen Text und wandelt das Dokument in eine bearbeitbare Textdatei um.
Diese digitalen Textversionen sind besonders hilfreich, etwa für Kinder oder auch für Erwachsene mit Leseschwierigkeiten. Deshalb können digitale Texte von verschiedenen Softwareanwendungen genutzt werden, um das Verständnis zu erleichtern.
Tauchen wir nun tiefer in das Thema ein und sehen uns an, wie OCR funktioniert.
Teil 2: Welches Tool ist das beste für OCR?
Haben Sie wichtige digitale Dokumente in gescannter oder bildbasierter Form und möchten diese in bearbeitbare PDF-Dokumente umwandeln? Es ist üblich, physische Dokumente durch Scannen mit anderen zu teilen. Solche Dateien lassen sich jedoch nicht direkt bearbeiten. Die optische Zeichenerkennung (OCR) ermöglicht es, diese Dokumente in bearbeitbare und durchsuchbare PDFs umzuwandeln, indem Text aus gescannten Dokumenten und Bildern erkannt und extrahiert wird. Heute stellen wir Ihnen eines der besten Tools auf dem Markt für OCR bei gescannten Dokumenten und Bildern vor.
Es gibt viele Tools für die Anwendung von OCR auf gescannte Dokumente und Bilder. UPDF ist eine ideale Wahl, da es schnelle, umfassende und präzise Ergebnisse liefert. Sie können OCR sogar auf iPhone- und Android-Geräten mit UPDF durchführen, was das Tool besonders flexibel und zugänglich macht. Zudem bietet es verschiedene Optionen, um die neu erstellten Dokumente individuell an Ihre Bedürfnisse anzupassen.
Die spannendste Funktion ist, dass UPDF inzwischen mit KI integriert ist, wodurch Sie Text direkt aus Bildern extrahieren können. Mit dieser Funktion lassen sich Texte aus gescannten PDFs oder Bildern besonders präzise erfassen.
Falls Sie mit der klassischen OCR-Funktion kein genaues Ergebnis erzielen, können Sie alternativ diese KI-Funktion nutzen – ein äußerst leistungsstarkes Tool.
Klicken Sie unten auf die Schaltfläche, um die OCR- und KI-Funktionen von UPDF direkt auszuprobieren.
Windows • macOS • iOS • Android 100% sicher

Hauptfunktionen
- Die hochpräzise OCR-Funktion ermöglicht es Ihnen, Text aus Bildern zu extrahieren und gescannte PDFs sowie Bilder in durchsuchbare Dokumente umzuwandeln. Unterstützt werden Formate wie Microsoft Office und TXT. Dabei können Sie Layoutoptionen, Auflösung und Formatierungen ganz einfach anpassen und beibehalten.
- Die Software erkennt mehr als 38 Sprachen, darunter Englisch, Französisch, Deutsch und Italienisch. Damit ist sie eine praktische Lösung für Nutzer weltweit.
- UPDF unterstützt die Texterkennung in Dokumenten mit mehreren Sprachen gleichzeitig.
- Sie können OCR und Formatkonvertierung in einem einzigen Schritt durchführen.
- Mit der Stapelverarbeitungs- und OCR-Funktion können Sie mehrere gescannte PDFs gleichzeitig erkennen oder in bearbeitbare Formate umwandeln.
- Die OCR-Funktion von UPDF ist auf Windows, Mac, Android und iOS verfügbar – so können Sie sie jederzeit und überall nutzen.
Teil 3: OCR für Dokumente in UPDF durchführen
Möchten Sie wissen, wie Sie die Texterkennung (OCR) auf Ihr gescanntes Dokument anwenden? Befolgen Sie diese Schritte, um Ihre gescannten Dokumente in UPDF per OCR zu verarbeiten:
Auf dem Desktop:
Für eine gescannte Datei:
Schritt 1. Laden Sie UPDF herunter und starten Sie es.
Windows • macOS • iOS • Android 100% sicher
Schritt 2. Ziehen Sie die gewünschten Dateien von Ihrem Gerät per Drag & Drop in das Feld oder klicken Sie auf „Datei öffnen“, um sie in durchsuchbare PDF-Formate zu konvertieren.
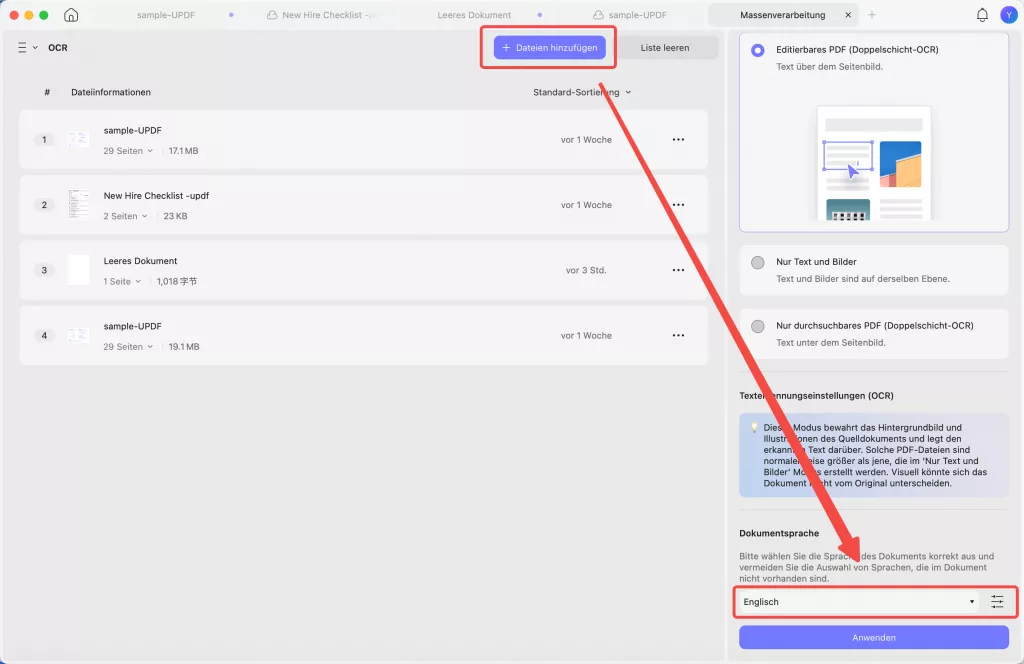
Schritt 3. Klicken Sie auf „Werkzeuge“ > „OCR“. UPDF OCR bietet Ihnen 3 verschiedene Optionen für die OCR-Texterkennung: Editierbares PDF, Nur Text und Bild sowie Nur durchsuchbares PDF.
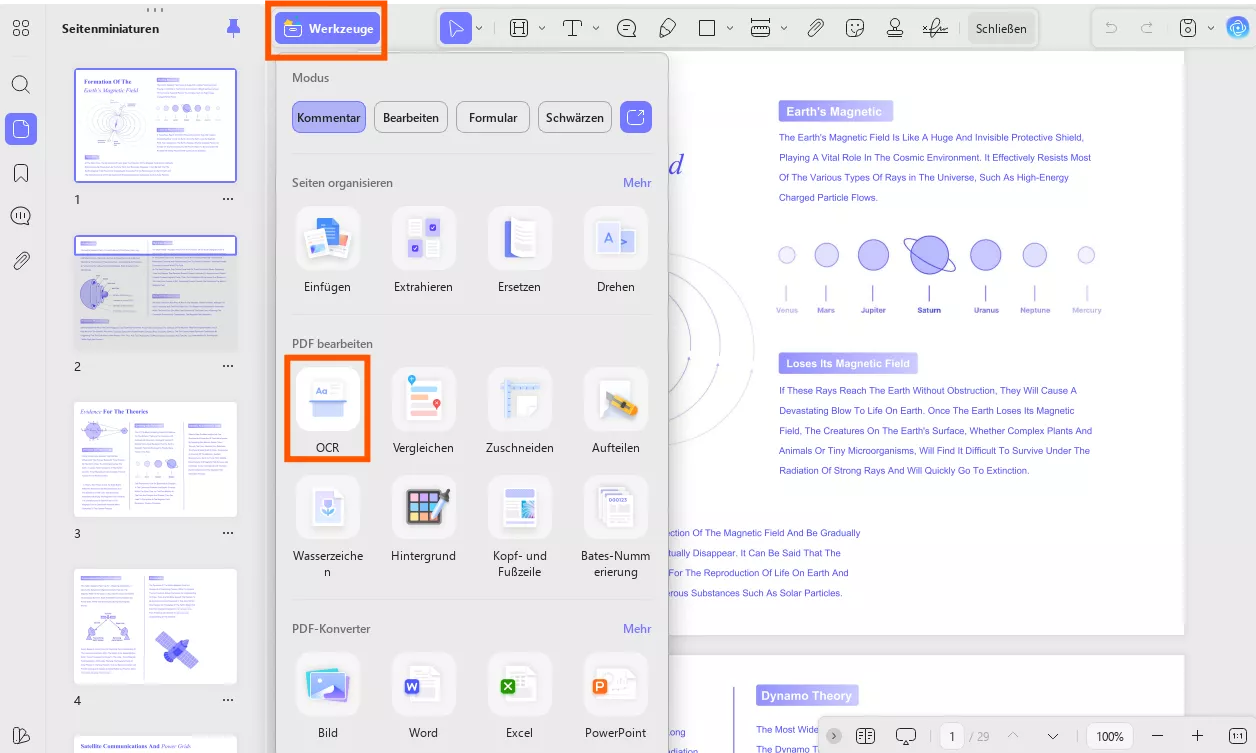
- Nur durchsuchbares PDF: In diesem Modus bleibt das Seitenbild erhalten, und der erkannte Text wird in einer unsichtbaren Ebene darunter hinzugefügt. Dadurch bleibt das Dokument optisch nahezu identisch mit dem Original.
- Editierbares PDF: In diesem Modus bleiben die Hintergrundbilder und Illustrationen des Originaldokuments erhalten, und der erkannte Text wird darübergelegt. Daher ist die Datei in der Regel größer als im Modus „Nur Text und Bilder“. Optisch kann das Ergebnis geringfügig vom Original abweichen.
- Nur Text und Bilder: In diesem Modus werden der erkannte Text und die Bilder gespeichert, wodurch eine kleinere PDF-Datei entsteht. Das Erscheinungsbild kann jedoch geringfügig vom Originaldokument abweichen.
Wählen Sie den gewünschten Modus entsprechend Ihren Bedürfnissen. Um genauere OCR-Ergebnisse zu erzielen, müssen Sie die zu erkennende Sprache, z. B. Englisch, korrekt auswählen.
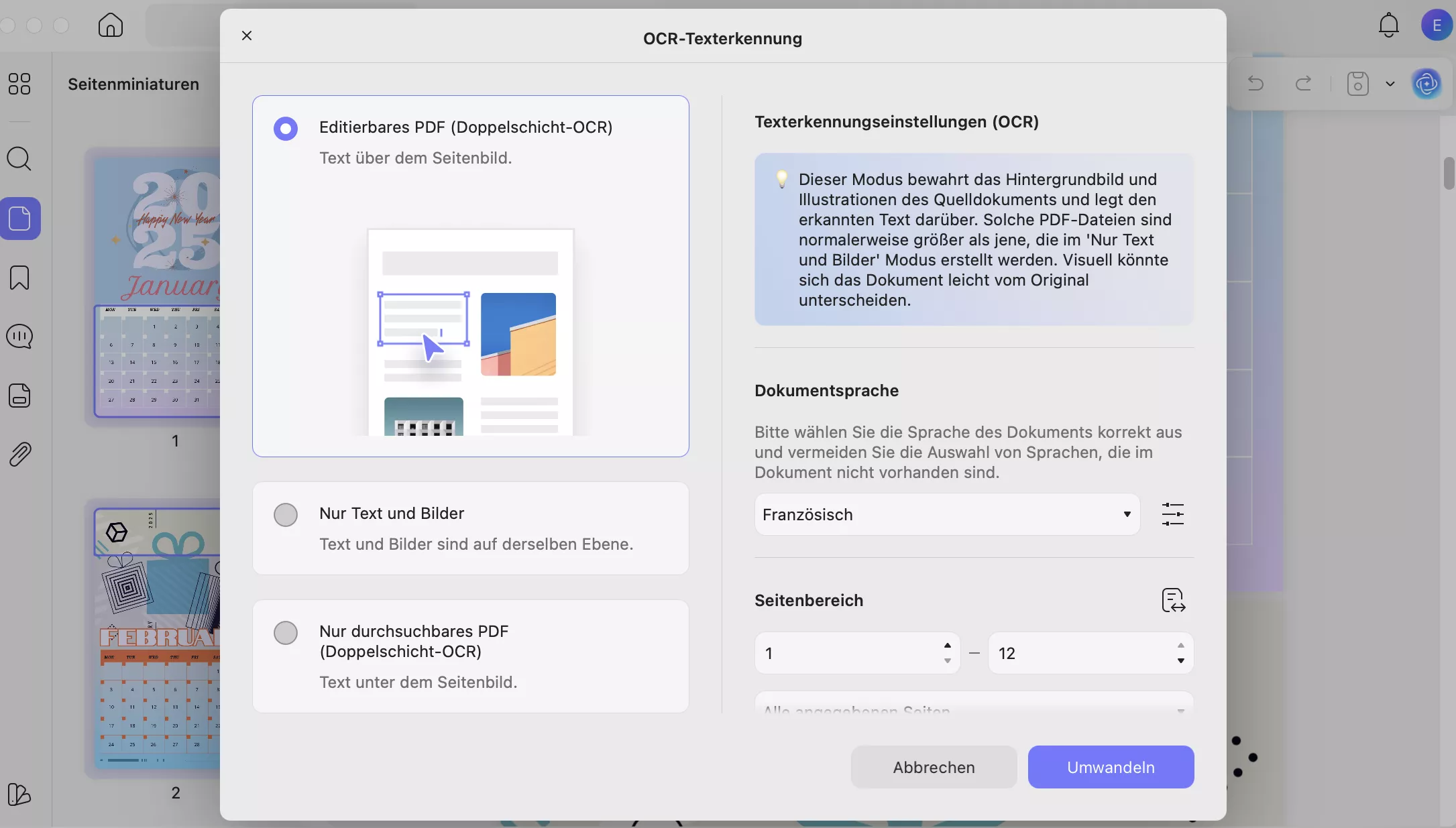
Schritt 4. Sie können auch auf die Option „Layout-Einstellungen“ neben der Sprache klicken, um auf weitere Anpassungsoptionen zuzugreifen.
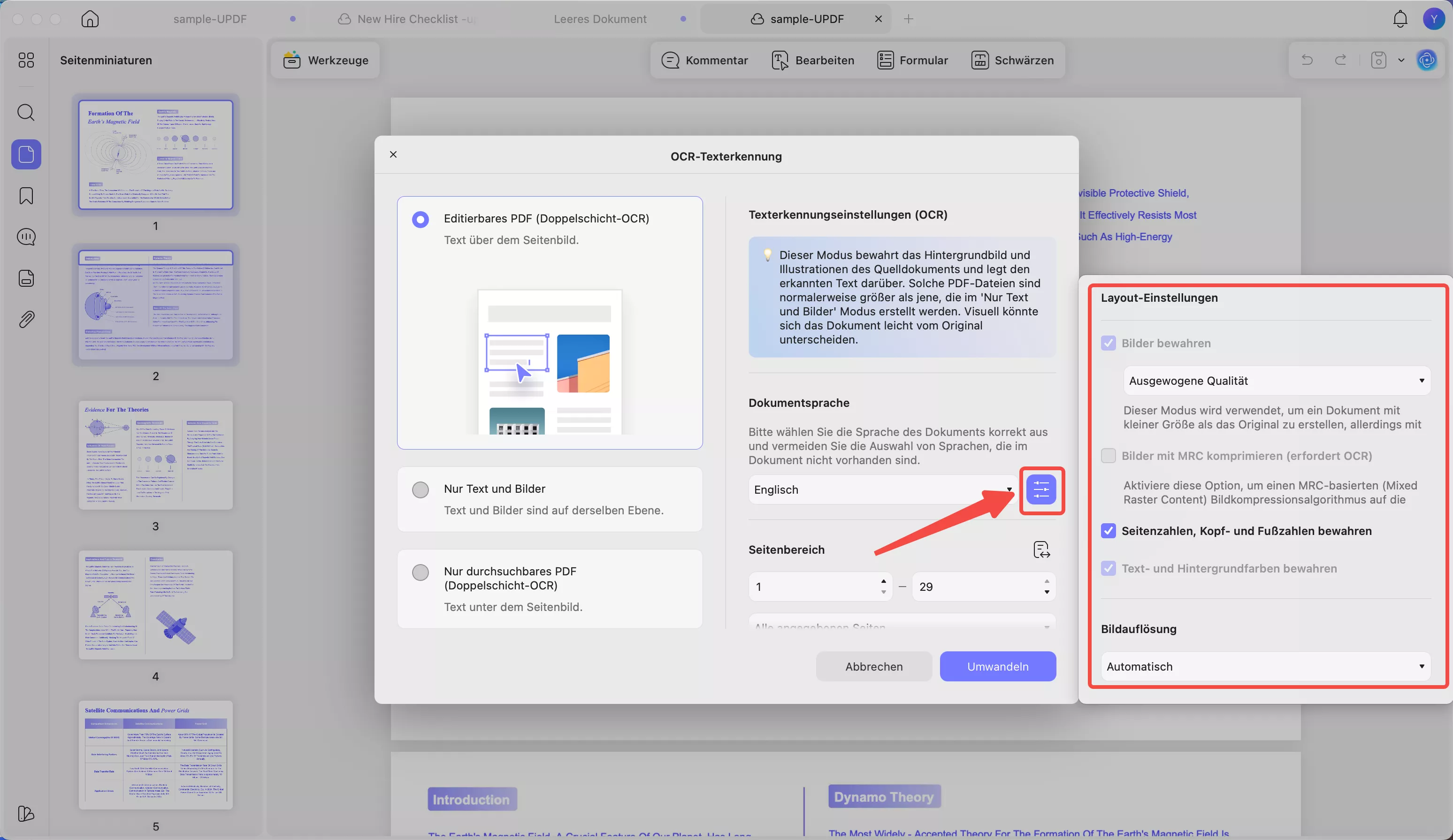
- Bilder beibehalten: Behält Bilder im Ausgabedokument bei. Es stehen die Qualitätsstufen Niedrig/Ausgewogen/Hoch zur Verfügung. Sie können die Bildqualität anpassen, um ein optimales Verhältnis zwischen Dateigröße und Schärfe zu erzielen.
- Bilder mit MRC komprimieren (erfordert OCR): Verwendet Mixed Raster Content Compression, um die Dateigröße zu reduzieren, ohne die sichtbare Qualität zu beeinträchtigen (funktioniert nur nach OCR).
- Seitenzahlen, Kopf- und Fußzeilen beibehalten: Diese Layoutelemente bleiben in der Ausgabe erhalten.
- Text- und Hintergrundfarben beibehalten: Die Originalfarben bleiben erhalten, um eine bessere visuelle Wiedergabetreue zu gewährleisten.
- Bildauflösung (letztes Bild): Hier können Sie die Ausgaberesolution auswählen:
- Automatisch : Die Software entscheidet.
- 300 dpi : Hohe Qualität (am besten für den Druck geeignet).
- 150 dpi : Mittlere Qualität (kleinere Datei).
- 72 dpi : Niedrige Qualität (kleinste Datei, nur für die Bildschirmdarstellung).
Für mehrere gescannte PDF-Dateien:
Schritt 1. Klicken Sie nach dem Start von UPDF auf die Schaltfläche „Werkzeuge“ und wählen Sie im Popup-Menü unter dem Bedienfeld MEHRDATEIOPERATION die Option „OCR“ aus.
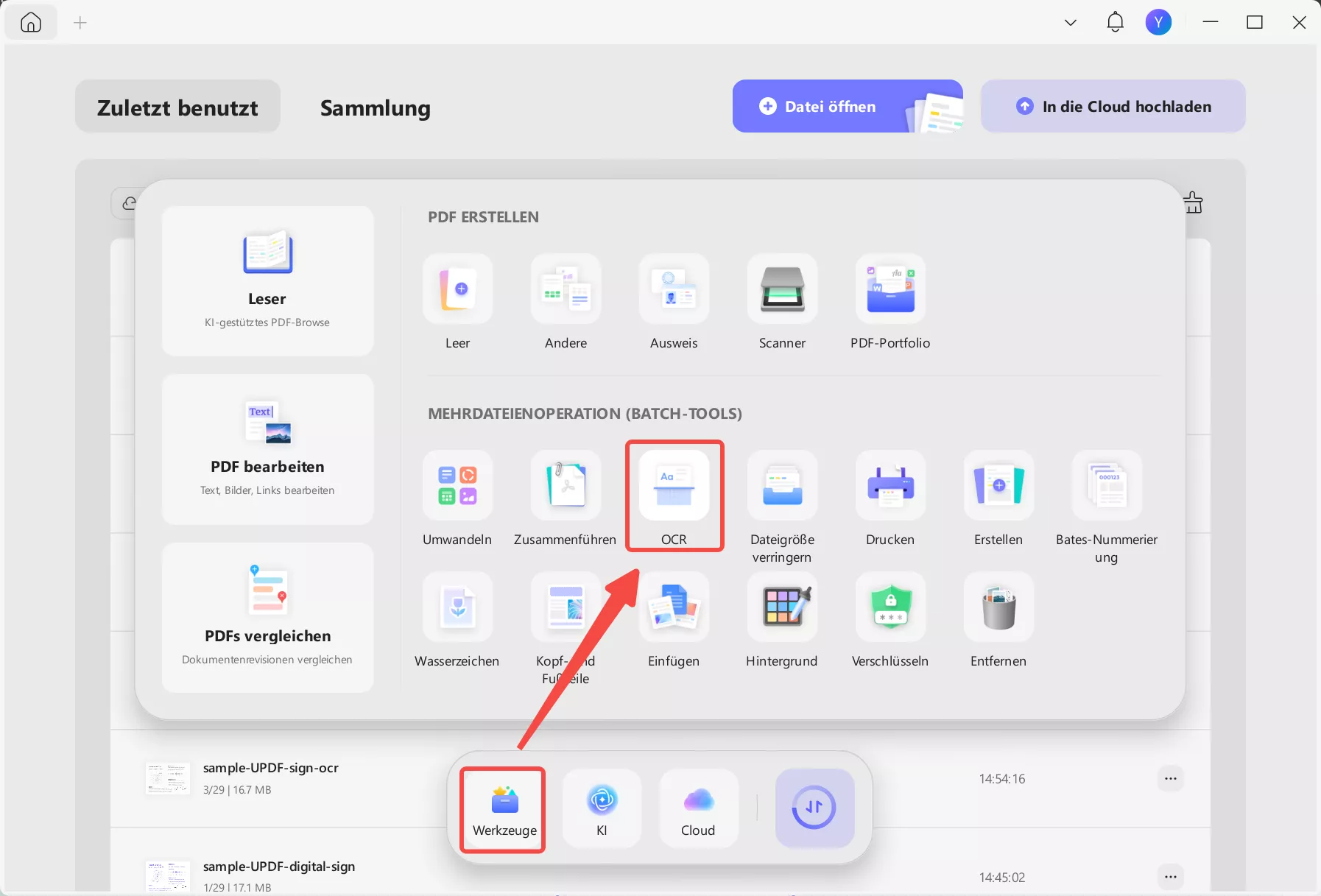
Schritt 2. Ziehen Sie Ihre gescannten Dokumente per Drag & Drop in den Upload-Bereich. Die übrigen Einstellungen entsprechen denen der Einzeldateiverarbeitung. Klicken Sie auf die violette Schaltfläche
„Anwenden“ (unten rechts), um die Stapelkonvertierung zu starten.
Auf Mobilgeräten:
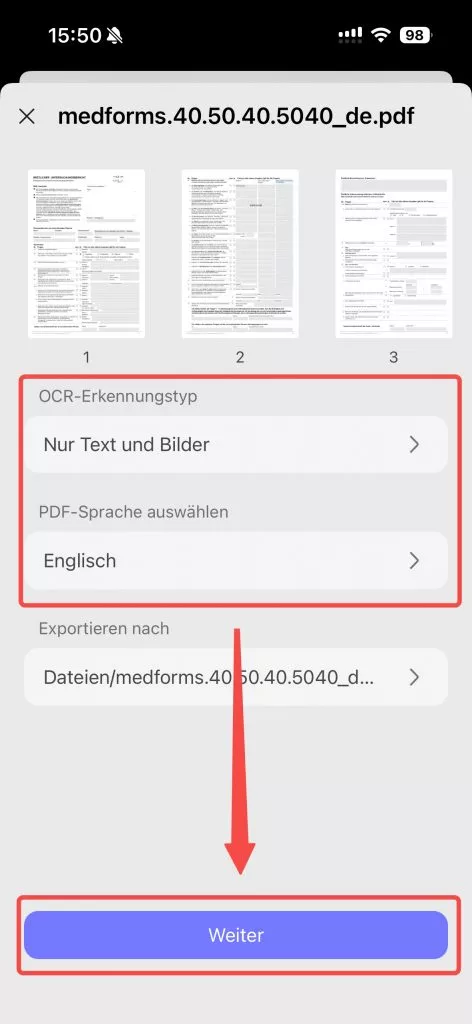
Wenn Sie ein Mobilgerät verwenden, können Sie der folgenden Anleitung folgen.
Schritte. Gehen Sie zu „Werkzeuge“ > „OCR“, laden Sie die gescannte PDF-Datei hoch, wählen Sie „Editierbares PDF“, wählen Sie die richtige Dokumentsprache und tippen Sie dann auf „Weiter“, um die gescannte PDF-Datei in eine bearbeitbare Datei zu konvertieren.
In diesem Video erfahren Sie mehr darüber, wie Sie mit UPDF PDFs per OCR bearbeiten.
Notiz:
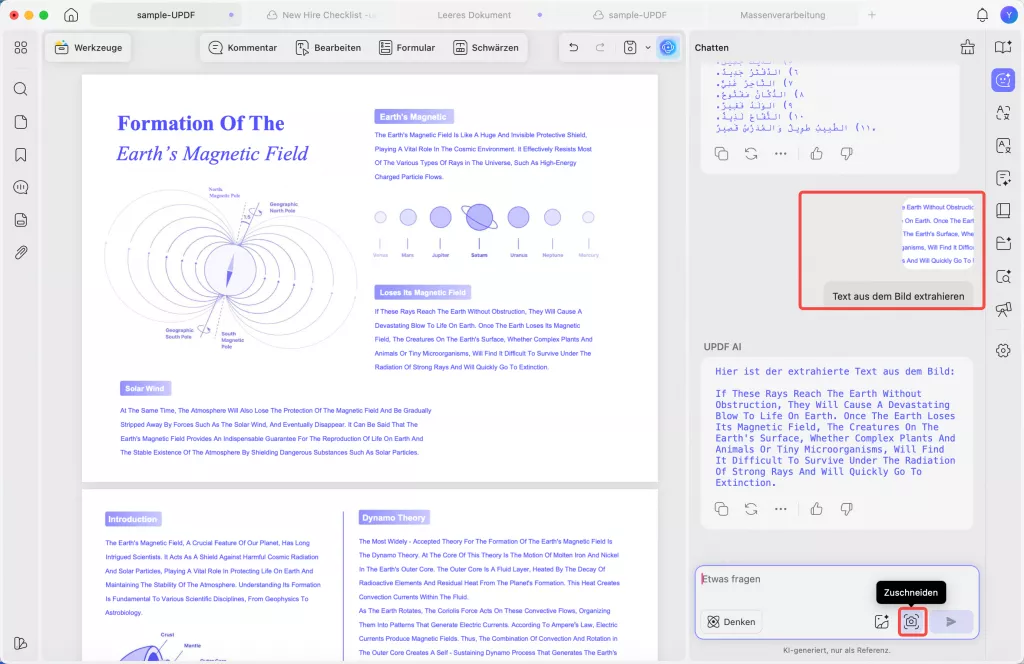
Wenn das OCR-Ergebnis nicht Ihren Anforderungen entspricht, können Sie mit UPDF AI direkt Text extrahieren, indem Sie auf „UPDF AI“ > „Chatten-Modus“ > „Bild hinzufügen“ oder „Zuschneiden“ klicken, die Eingabeaufforderung „Text aus dem Bild extrahieren“ eingeben und dann „Senden“ auswählen.
UPDF verfügt nicht nur über OCR- und KI-Funktionen. Lesen Sie diesen Testbericht oder klicken Sie auf die Schaltfläche unten, um eine kostenlose Testversion von UPDF herunterzuladen und mehr darüber zu erfahren.
Windows • macOS • iOS • Android 100% sicher
Teil 4: Wie funktioniert optische Zeichenerkennung?
Die optische Zeichenerkennung (OCR) arbeitet mit Scannern zusammen, um gedruckte Dokumente zu verarbeiten. Nach dem Kopieren aller Seiten ermöglicht eine OCR-Software wie UPDF die Umwandlung des Dokuments in eine zweifarbige oder schwarzweiße Version.
Das gescannte Bild analysierte dunkle und helle Bereiche. Die dunklen Bereiche wurden als zu identifizierende Zeichen klassifiziert, die hellen Bereiche als Hintergrund.
Diese dunklen Bereiche werden verarbeitet, um Ziffern oder Buchstaben zu identifizieren. Dies geschieht typischerweise, indem man sich gleichzeitig auf jeweils ein Wort, ein Zeichen oder einen Textblock konzentriert. Die Zeichen werden dann mit einer der beiden folgenden Methoden identifiziert:
- Mustererkennung.
- Merkmalerkennung.
Mustererkennung
Die Mustererkennung wird verwendet, wenn der OCR-Anwendung Textmuster mit verschiedenen Schriftarten und Formaten zur Verfügung gestellt werden, um die Zeichen in den Dokumenten oder Bilddateien zu identifizieren und zuzuordnen.
Merkmalerkennung
Die Merkmalserkennung erfolgt durch die Anwendung von OCR-Regeln auf die spezifischen Merkmale von Ziffern oder Buchstaben, um die in das Dokument eingescannten Zeichen zu erkennen. Merkmale lassen sich beispielsweise an der Anzahl von gekreuzten Linien, schrägen Linien und Krümmungen in den Zeichen identifizieren.
Der Buchstabe „A“ besteht beispielsweise aus zwei geraden Linien, die eine horizontale Linie in der Mitte kreuzen. Wird ein Zeichen von einem Computer erkannt, wird es in den ASCII-Code (American Standard Code for Information Interchange) umgewandelt, den Computer zur weiteren Verarbeitung verwenden.
Die OCR-Software analysiert auch die Struktur eines Bildes. Sie zerlegt die Seite in Bestandteile wie Textblöcke, Tabellen oder Bilder. Die Zeilen werden in Wörter und anschließend in Zeichen getrennt. Nach der Zeichenisolierung analysiert die Software die Zeichen anhand von Mustern. Der gefundene Text wird nach der Verarbeitung aller möglichen Übereinstimmungen angezeigt.
Teil 5: Anwendungsfälle der optischen Zeichenerkennung ( OCR )
Im Jahr 2021, in dem alles digital und technologisch fortgeschritten ist, wird die OCR-Technologie von verschiedenen Unternehmen eingesetzt, um die Effizienz der Geschäftsprozesse zu verbessern, die Zugänglichkeit zu erhöhen und die Zufriedenheit der Kunden zu steigern.
Im Folgenden findest du einige der bekanntesten Anwendungen von OCR in der heutigen Industrie.
OCR-Technologie im Gesundheitswesen
Die OCR-Technologie hat viele Vorteile für Fachkräfte im Gesundheitswesen. So ermöglicht sie beispielsweise, dass die Krankengeschichte der Patienten sowohl für Ärzte als auch für Patienten digital zugänglich ist.
Außerdem können die Patientenakten, wie z. B. Behandlungs-, Röntgen-, Blutuntersuchungs-, Krankenhaus- und Versicherungsunterlagen, mithilfe der OCR-Technologie durchsucht, gescannt und gespeichert werden.
Deshalb kann die optische Zeichenerkennung die Arbeitsabläufe straffen und den Arbeitsaufwand im Krankenhaus verringern, während die Krankenakten auf dem neuesten Stand bleiben.
OCR-Technologie in der Kommunikation
Die häufigste Anwendung von OCR ist die Digitalisierung von Dokumenten und Büchern, um die Kommunikation von Mensch zu Mensch effizienter zu gestalten. Ein Beispiel dafür ist die OCR-Technologie von Google Translate, mit der du jeden Text in jede Sprache übersetzen kannst.
OCR-Technologie im Bankwesen
Ein Beispiel für den Einsatz von OCR in der Bankgewerbe sind mobile Banking-Apps, mit denen Schecks elektronisch eingereicht und innerhalb weniger Tage mit OCR-basierten Scheckeinreichungsfunktionen verarbeitet werden können.
Eine weitere Anwendung von OCR im Bankensektor besteht darin, die Daten der Kunden zu verfolgen und zu analysieren, einschließlich persönlicher und sicherheitsrelevanter Daten.
Bankgeschäfte sind durch eine große Anzahl von Dateneingaben im Zusammenhang mit den Kontoauszügen gekennzeichnet. OCR-basierte Technologie kann dazu beitragen, dass der Arbeitsablauf reibungslos abläuft und die Texterkennung jedes Mal mit hoher Genauigkeit erfolgt.
Darüber hinaus kann OCR auch bei der Erfassung sensibler Informationen in Gehaltsabrechnungen und Hypothekenanträgen nützlich sein.
OCR-Technologie in Rechtsangelegenheiten
Sie ermöglicht es Anwaltskanzleien, Dokumente wie eidesstattliche Erklärungen, Akten, Urteile, Testamente und Erklärungen u.a. digitalisiert zu drucken. PDF in der Rechtsbranche ist weit verbreitet.
OCR-Technologie in der Versicherung
OCR kann auch der wachsenden Versicherungsbranche helfen. Insbesondere kann OCR die Bearbeitung von Versicherungsansprüchen automatisieren, um Transaktionen zu beschleunigen.
Teil 6: Die Vorteile der optischen Zeichenerkennung ( OCR )
OCR, oder Optical Character Recognition, bietet verschiedene Vorteile, von denen viele in diesem Artikel behandelt wurden. Aber die wichtigsten Vorteile von OCR werden im Folgenden zur Information genannt.
- Genauigkeit: Durch die softwarebasierte optische Zeichenerkennung werden menschliche Fehler vermieden, was zu einer höheren Genauigkeit führt.
- Erschwinglich: Die OCR-Technologie benötigt keine großen Ressourcen, was die Kosten für die Verarbeitung und damit auch die Gesamtkosten eines Unternehmens senkt.
- Verbesserte Kundenzufriedenheit Die Verfügbarkeit von durchsuchbaren Informationen für Kunden sorgt für ein positives Erlebnis und erhöht die Kundenzufriedenheit.
- Nicht zuletzt steigert sie die Produktivität: Die Zugänglichkeit von durchsuchbaren Daten schafft eine zugängliche, stressfreie Umgebung für die Mitarbeiter, sodass sie sich auf die Hauptziele konzentrieren können, was die Effizienz und Produktivität eines jeden Unternehmens steigert.
Da sich maschinelles Lernen ständig weiterentwickelt, geht es über die Datenerfassung hinaus und bietet zahlreiche Anwendungsmöglichkeiten in verschiedenen Branchen.
Fazit
Die Nutzung der OCR-Funktion eröffnet Nutzern zahlreiche Möglichkeiten und Vorteile im digitalen Alltag. Mit UPDF wurde der Zugriff auf diese Funktion für eine breite Nutzerbasis vereinfacht, um gescannte Dokumente zu bearbeiten oder zu durchsuchen.
Wir hoffen, dieser Artikel hat Ihnen ausreichend Informationen zum Thema OCR geliefert. Wenn Sie OCR nutzen und präzise Ergebnisse erzielen möchten, können Sie UPDF über den untenstehenden Button herunterladen. In der kostenlosen Version können Sie OCR lediglich testen. Für die volle Nutzung empfehlen wir Ihnen ein Upgrade auf die Pro-Version zum günstigen Preis (hier erhältlich).
Windows • macOS • iOS • Android 100% sicher







 Wayne Austin
Wayne Austin