 UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools KI-Lesezeichen-Generierung
KI-Lesezeichen-Generierung KI-Lesezeichen-Zusammenfassung
KI-Lesezeichen-Zusammenfassung KI-Wasserzeichen-Generierung
KI-Wasserzeichen-Generierung KI-Hintergrund-Generierung
KI-Hintergrund-Generierung KI-Sticker-Generierung
KI-Sticker-Generierung KI-Stempel-Generierung
KI-Stempel-Generierung KI-Schreibtools
KI-Schreibtools UPDF Copilot
UPDF Copilot KI-Seitenverwaltung
KI-Seitenverwaltung KI-Semantische Suche
KI-Semantische Suche PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Kurze Antwort
Wichtig ist die Dateityp-Frage: Eine digital erstellte PDF enthält bereits eine Textebene. Eine gescannte PDF besteht dagegen nur aus Bildern. In deutschen Büros betrifft das oft eingescannte Verträge, Rechnungen, Behördenformulare, Studienunterlagen oder alte Archivdokumente. Für sensible Unterlagen ist eine lokale Desktop-Lösung meist die bessere Wahl, weil die Datei nicht unnötig in ein beliebiges Online-Tool hochgeladen wird.
Windows • macOS • iOS • Android 100% sicher
Welche Methode passt zu Ihrer PDF?
Prüfen Sie zuerst, ob der Text in der PDF markierbar ist. Wenn Sie einzelne Wörter markieren können, reicht meist Kopieren oder Exportieren. Wenn sich nur ein Rahmen um die Seite ziehen lässt, brauchen Sie OCR.
| Situation | Empfohlene Methode | Geeignet für | Grenze |
|---|---|---|---|
| Text ist bereits markierbar | Direkt kopieren oder in ein anderes Format konvertieren | Berichte, E-Books, digital erstellte Verträge | Formatierung kann beim Kopieren verloren gehen |
| PDF ist ein Scan oder Foto | UPDF OCR auf dem Desktop | Rechnungen, Akten, Formulare, mehrseitige Scans | OCR-Ergebnis sollte bei Zahlen und Namen geprüft werden |
| Scan liegt auf dem Smartphone | UPDF Mobile OCR | Belege, unterwegs fotografierte Dokumente | Sehr lange Dateien sind am Desktop komfortabler |
| Sie brauchen nur eine Aussage, Zusammenfassung oder Tabelle | UPDF AI | Studien, Verträge, technische Dokumentation | KI liefert nutzbaren Inhalt, aber keine dauerhaft eingebettete Textebene |
| PDF enthält vertrauliche Daten | Lokale OCR mit UPDF Desktop | HR-Unterlagen, Verträge, Steuer- und Finanzdokumente | Installation erforderlich |
Methode 1: Text aus gescannten PDFs mit OCR extrahieren
Wenn eine PDF nur aus gescannten Seiten besteht, kann ein normaler PDF-Reader keinen echten Text kopieren. Die OCR-Funktion von UPDF erkennt den Text im Bild und erstellt daraus eine neue, durchsuchbare oder bearbeitbare PDF. UPDF unterstützt 38 Sprachen, was bei deutsch-englischen Verträgen, mehrsprachigen Handbüchern oder internationalen Rechnungen praktisch ist.
Schritt 1. Öffnen Sie UPDF und klicken Sie auf Datei öffnen, um die gescannte PDF zu importieren. Wenn UPDF noch nicht installiert ist, laden Sie UPDF kostenlos herunter und testen Sie OCR mit einer eigenen Datei.
Windows • macOS • iOS • Android 100% sicher
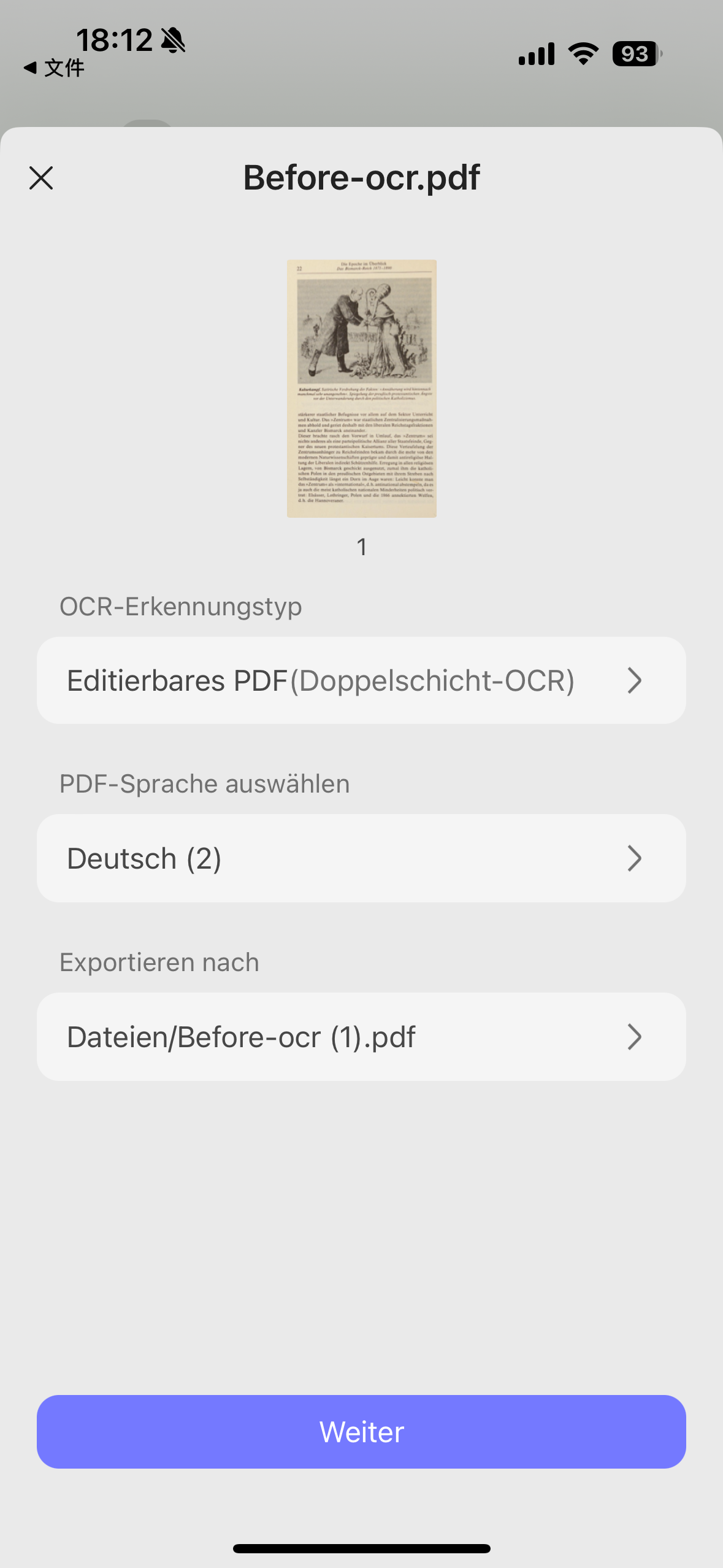
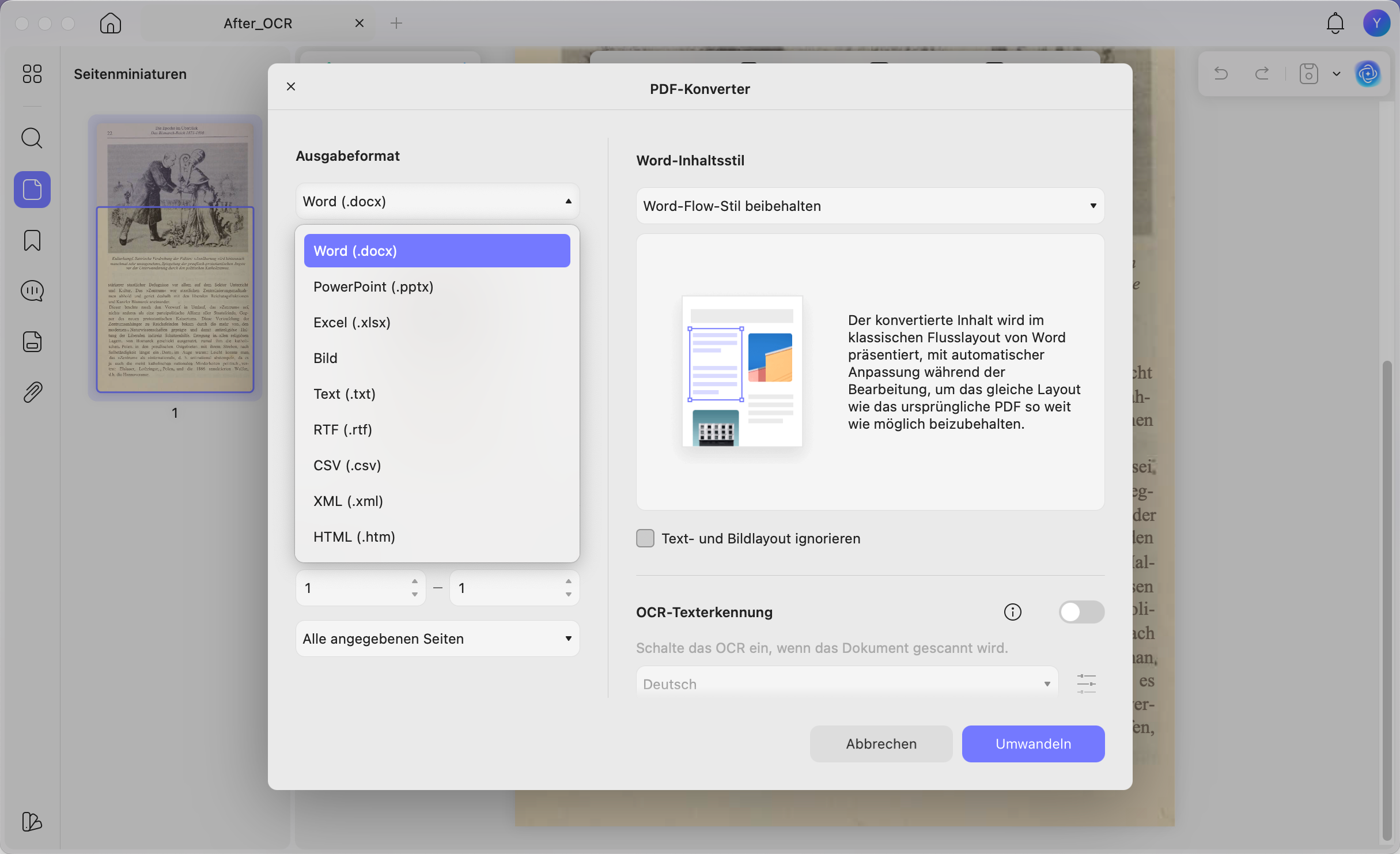
Schritt 2. Klicken Sie links auf Werkzeuge und wählen Sie OCR.
Schritt 3. Wählen Sie Bearbeitbare PDF, wenn Sie den Text später ändern möchten. Wählen Sie Nur durchsuchbare PDF, wenn das Originalbild sichtbar bleiben soll und Sie nur suchen oder kopieren möchten.
Schritt 4. Legen Sie Sprache, Seitenbereich und Layout fest. Bei deutschen Dokumenten mit englischen Fachbegriffen können Sie mehrere Sprachen aktivieren, damit Umlaute, Akzente und Fachbegriffe sauberer erkannt werden.
Schritt 5. Klicken Sie auf Umwandeln. Nach der Verarbeitung öffnet UPDF die OCR-Version der Datei. Jetzt können Sie Text markieren, kopieren, suchen oder mit dem Bearbeiten-Werkzeug korrigieren.

Nach der OCR-Verarbeitung lässt sich der erkannte Text direkt in UPDF prüfen. Bei rechtlichen, finanziellen oder medizinischen Dokumenten sollten Sie Namen, Beträge, IBANs, Fristen und Aktenzeichen immer manuell kontrollieren. OCR spart Tipparbeit, ersetzt aber keine fachliche Endprüfung.

Wenn Sie regelmäßig große Mengen gescannter Unterlagen verarbeiten, lohnt sich UPDF Pro. Die kostenlose Version eignet sich zum Testen; für Export ohne Wasserzeichen, Batch-OCR und dauerhafte Nutzung auf unterstützten Plattformen können Sie die UPDF Pro-Version nutzen. Der Preis wird im Shop transparent angezeigt, unter anderem als Jahres- und Lifetime-Option: 49.99€ bzw. 79.99€.
Methode 2: Text aus PDF auf iPhone, iPad und Android extrahieren
Viele Dokumente landen zuerst auf dem Smartphone: fotografierte Belege, gescannte Bescheide, E-Mail-Anhänge oder Formulare. Mit UPDF für Mobilgeräte können Sie Text aus PDF extrahieren, ohne die Datei erst an den Computer zu senden.
Schritt 1. Öffnen Sie UPDF auf dem iPhone, iPad oder Android-Gerät und importieren Sie die PDF oder das Bild über die +-Schaltfläche.
Schritt 2. Tippen Sie auf OCR, wählen Sie die Sprache und den gewünschten Ausgabemodus aus und starten Sie die Erkennung.
Schritt 3. Öffnen Sie die erkannte Datei, wählen Sie den gewünschten Text aus und kopieren Sie den Inhalt in eine E-Mail, Notiz, Übersetzungs-App oder ein anderes Dokument.


Tipp
Methode 3: Text aus PDF ohne OCR mit UPDF AI auslesen
Nicht jede Aufgabe braucht eine vollständige OCR-Datei. Wenn Sie nur bestimmte Inhalte brauchen, etwa Kernaussagen, Tabellenwerte, Vertragsklauseln oder eine Zusammenfassung, kann UPDF AI den Inhalt semantisch auswerten. Das ist besonders praktisch bei langen Studien, technischen Handbüchern oder Verträgen, aus denen Sie nicht jedes Wort, sondern gezielte Informationen extrahieren möchten.
Schritt 1. Öffnen Sie die PDF in UPDF und klicken Sie unten rechts auf UPDF AI.
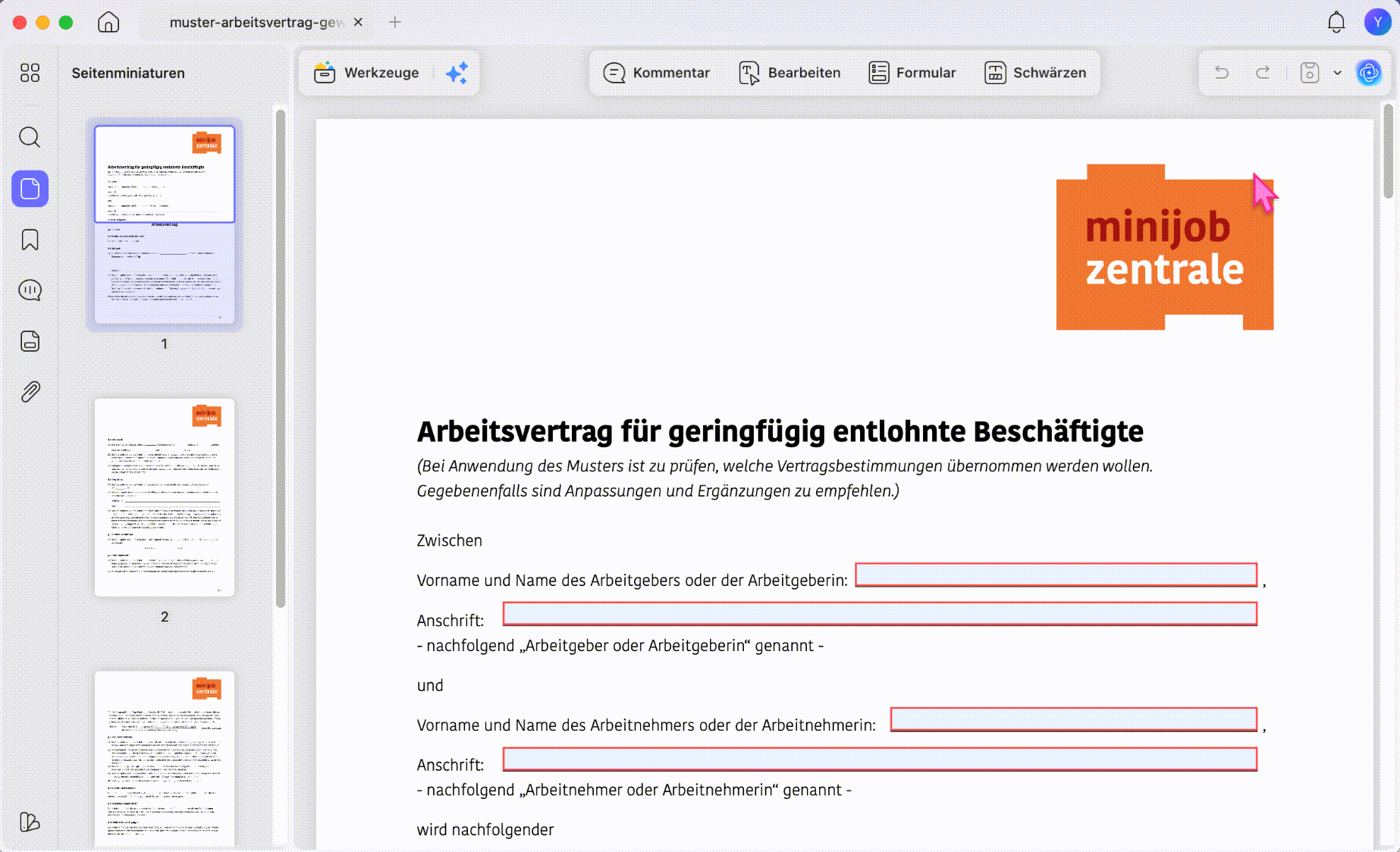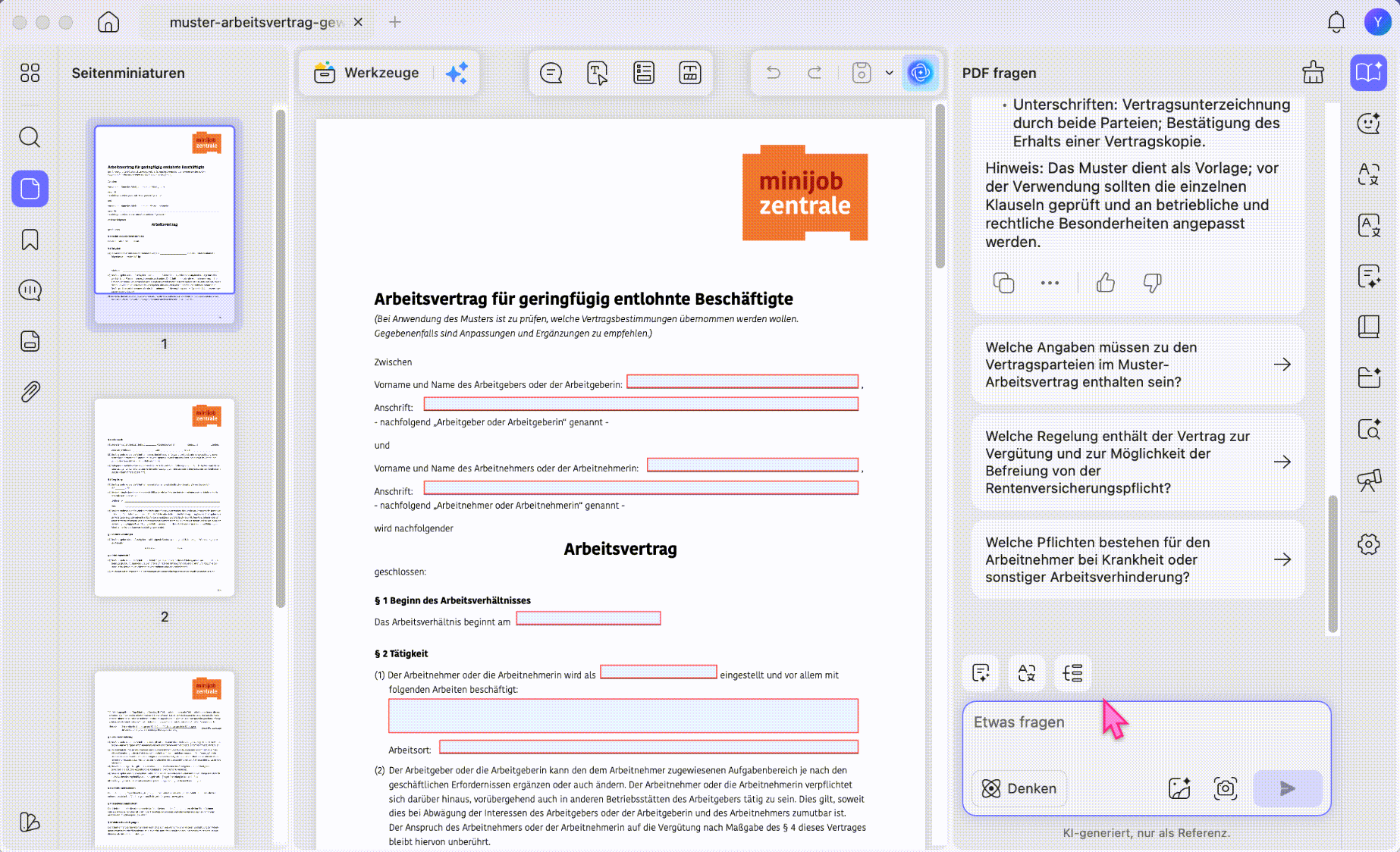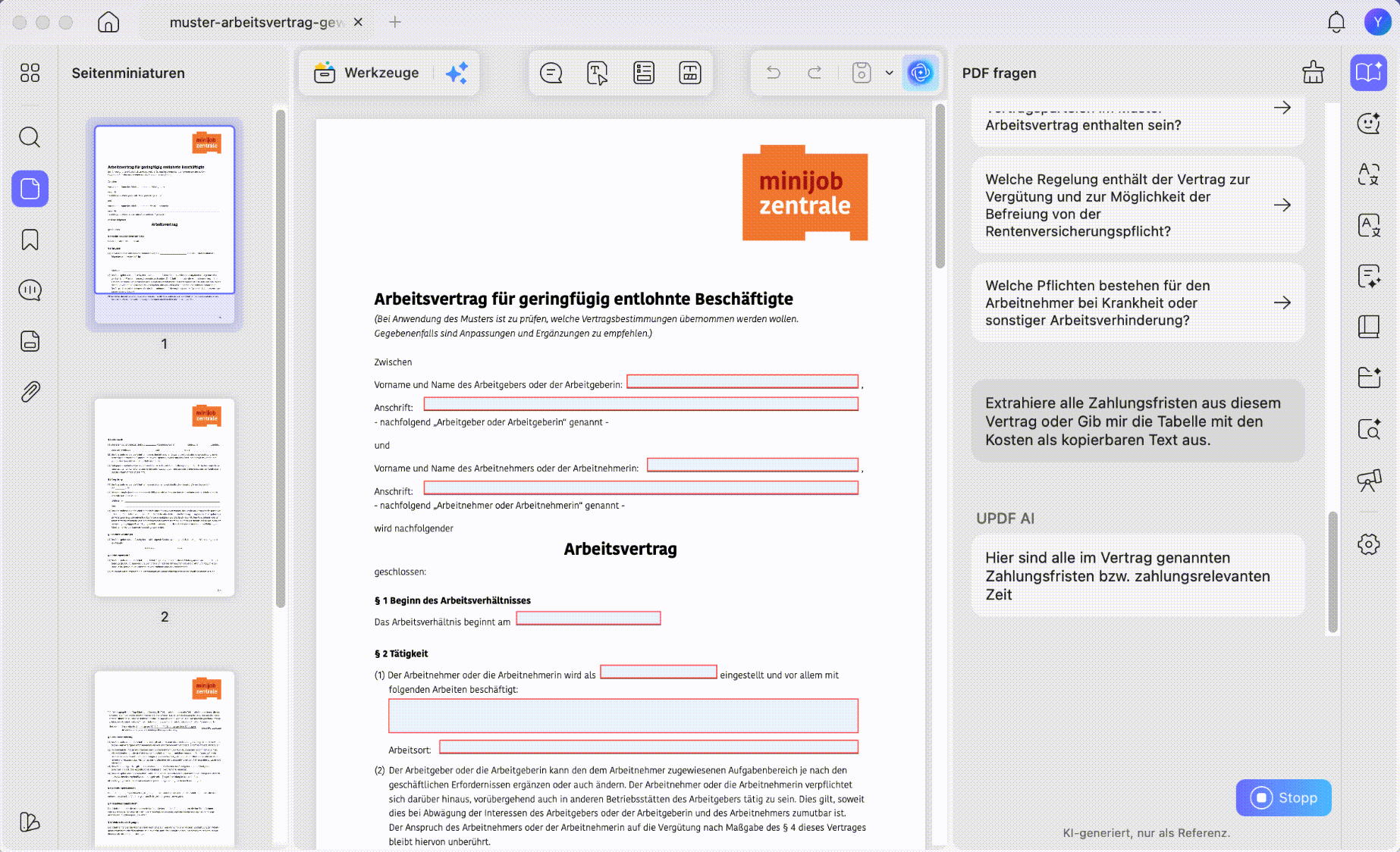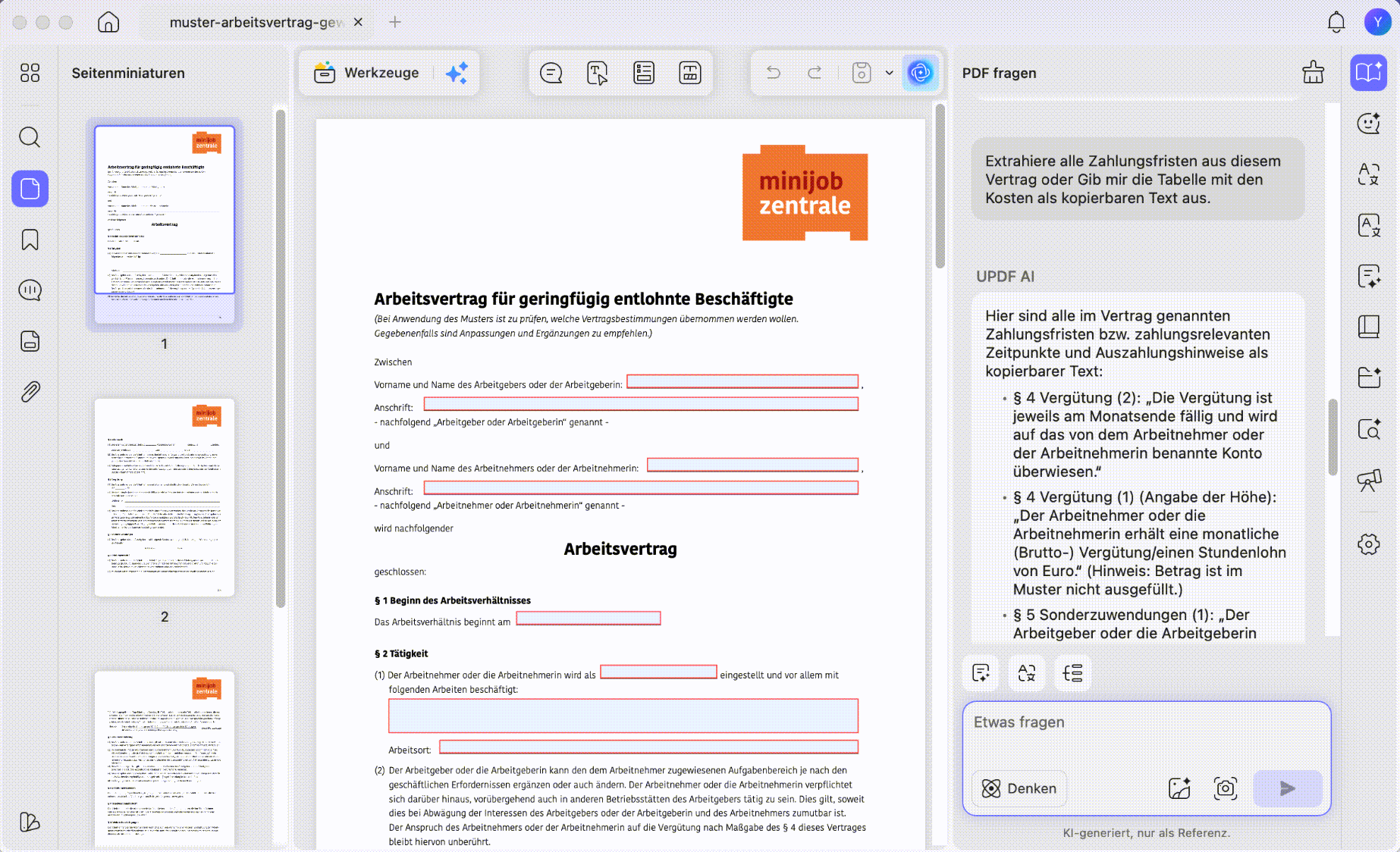
Schritt 2. Nutzen Sie den Modus PDF fragen oder Chat. Stellen Sie eine konkrete Frage, zum Beispiel: Extrahiere alle Zahlungsfristen aus diesem Vertrag oder Gib mir die Tabelle mit den Kosten als kopierbaren Text aus.
Schritt 3. Kopieren Sie die Antwort von UPDF AI und verwenden Sie den Text in Ihrer E-Mail, Präsentation, Notiz oder Dokumentation weiter. Für mehrsprachige Dokumente können Sie den extrahierten Inhalt auch direkt übersetzen lassen.
Hinweis: UPDF AI ist ideal, wenn Sie Informationen aus einer PDF auslesen möchten. Wenn Sie den kompletten Text dauerhaft in der PDF auswählbar machen wollen, ist OCR die passendere Methode.
Windows • macOS • iOS • Android 100% sicher
Nach der Textextraktion: Was Sie mit dem Inhalt tun können
Textextraktion ist meist nur der erste Schritt. Danach müssen Inhalte oft weiterverarbeitet werden: in Word korrigieren, in Excel auswerten, in PowerPoint zitieren oder direkt in der PDF ersetzen. UPDF bündelt diese Anschlussaufgaben in derselben Oberfläche.
PDF konvertieren: Wenn Sie den gesamten Inhalt außerhalb der PDF weiterbearbeiten möchten, können Sie die PDF in Word, Excel, PowerPoint, TXT oder andere Formate umwandeln. Mehr dazu finden Sie im Leitfaden PDF konvertieren.
PDF direkt bearbeiten: Wenn Sie nur einzelne Wörter, Zahlen oder Bilder korrigieren möchten, können Sie die erkannte PDF direkt in UPDF bearbeiten. Das ist schneller als der Umweg über Word, besonders bei Formularen, Angeboten und kurzen Vertragsänderungen. Für gescannte Dateien hilft zusätzlich der Leitfaden PDF bearbeitbar machen.
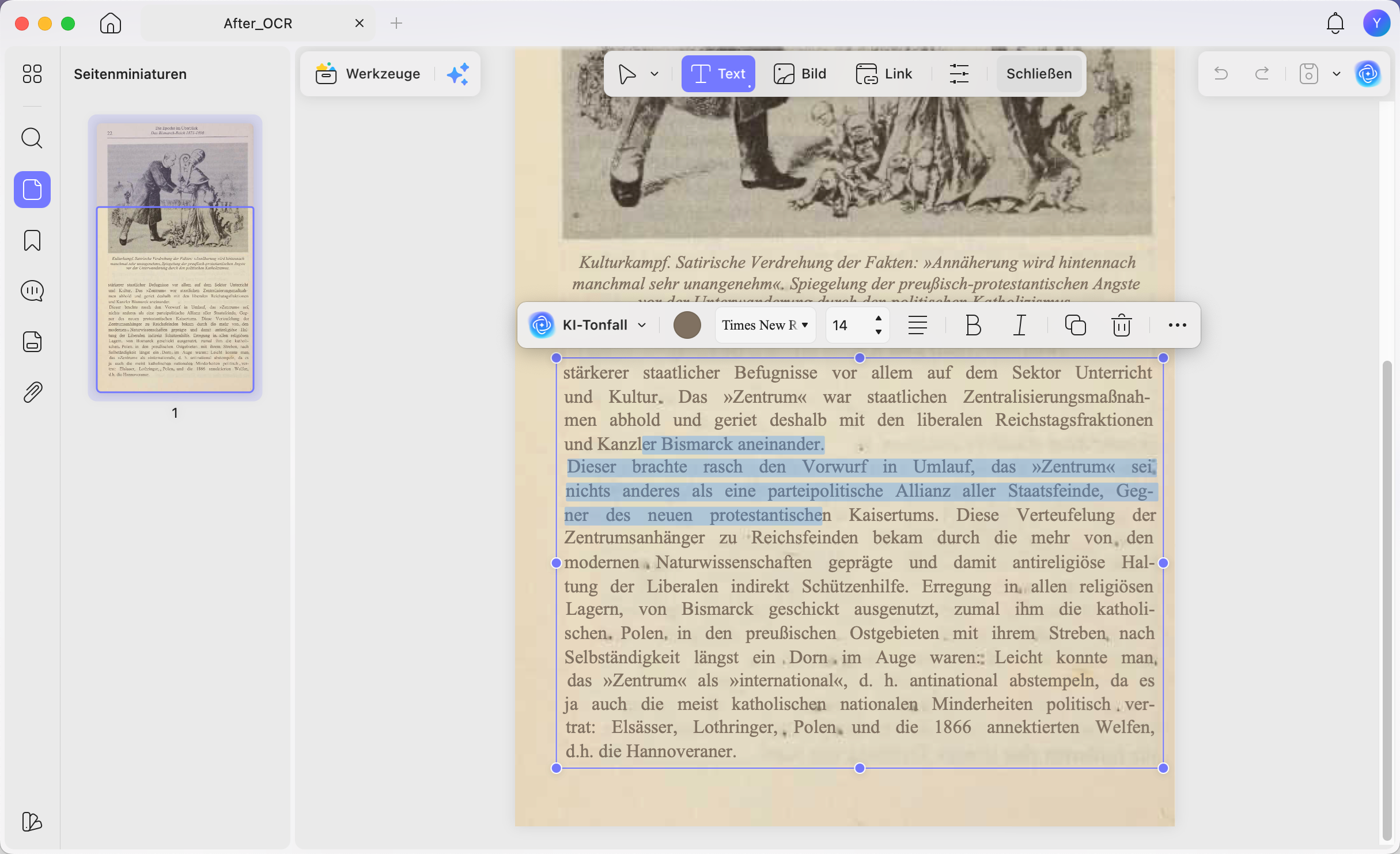
Datenschutz im DACH-Kontext: Wenn Sie Text aus PDF extrahieren, können personenbezogene Daten, Vertragsdetails oder Finanzinformationen betroffen sein. UPDF Desktop verarbeitet OCR lokal auf Ihrem Gerät. Das reduziert unnötige Uploads und passt besser zu Arbeitsumgebungen, in denen Vertraulichkeit wichtig ist. Details finden Sie in der Datenschutzerklärung von UPDF.
Wenn das Extrahieren nicht funktioniert
- Der Text lässt sich nicht markieren. Die PDF ist wahrscheinlich ein Scan. Führen Sie zuerst OCR aus und kopieren Sie den Text danach aus der erkannten Datei.
- Die kopierten Zeichen sehen falsch aus. Wählen Sie in OCR die richtige Dokumentsprache. Bei deutschsprachigen Dokumenten mit englischen Begriffen sollten beide Sprachen aktiviert werden.
- Tabellen verlieren beim Kopieren ihre Struktur. Nutzen Sie statt einfachem Kopieren eine Konvertierung nach Excel oder fragen Sie UPDF AI gezielt nach einer Tabelle im kopierbaren Format.
- Die PDF ist geschützt. Wenn Kopieren oder Bearbeiten blockiert ist, kann ein Berechtigungspasswort aktiv sein. Entfernen Sie den Schutz nur, wenn Sie dazu berechtigt sind.
- Das OCR-Ergebnis ist ungenau. Scannen Sie mit höherer Auflösung, richten Sie schiefe Seiten aus und vermeiden Sie Schatten. 300 DPI sind für Büro-Scans meist ein guter Ausgangspunkt.
FAQ
Kann ich Text aus einer gescannten PDF ohne OCR extrahieren?
Ja, UPDF AI kann Inhalte aus einer gescannten PDF auslesen, wenn Sie gezielte Informationen oder eine Zusammenfassung benötigen. Wenn der komplette Text dauerhaft auswählbar und durchsuchbar in der PDF bleiben soll, ist OCR jedoch die bessere Methode.
Warum werden Umlaute oder Sonderzeichen nach OCR falsch erkannt?
Umlaute und Sonderzeichen werden oft falsch erkannt, wenn die falsche OCR-Sprache ausgewählt wurde oder der Scan unscharf ist. Wählen Sie Deutsch und bei Bedarf weitere Sprachen aus, scannen Sie möglichst gerade und prüfen Sie wichtige Namen, Beträge und Nummern manuell.
Ist es sicher, vertraulichen Text aus PDF online zu extrahieren?
Für vertrauliche PDFs ist eine lokale Desktop-Lösung meist sicherer als ein beliebiges Online-Tool. Bei Verträgen, Rechnungen, Bewerbungen, Ausweisen oder Steuerunterlagen sollten Sie den Text möglichst lokal mit UPDF Desktop extrahieren und unnötige Uploads vermeiden.
Fazit
Text aus PDF extrahieren ist einfach, wenn Sie zuerst den Dateityp bestimmen. Bei normalen PDFs reicht Kopieren oder Konvertieren. Bei gescannten PDFs erstellt UPDF OCR eine echte Textebene. Wenn Sie nur einzelne Informationen brauchen, hilft UPDF AI schneller als eine vollständige OCR-Konvertierung. Laden Sie UPDF kostenlos herunter und testen Sie die Methode direkt an Ihrer eigenen PDF.
Windows • macOS • iOS • Android 100% sicher








 Wayne Austin
Wayne Austin 