 UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools KI-Lesezeichen-Generierung
KI-Lesezeichen-Generierung KI-Lesezeichen-Zusammenfassung
KI-Lesezeichen-Zusammenfassung KI-Wasserzeichen-Generierung
KI-Wasserzeichen-Generierung KI-Hintergrund-Generierung
KI-Hintergrund-Generierung KI-Sticker-Generierung
KI-Sticker-Generierung KI-Stempel-Generierung
KI-Stempel-Generierung KI-Schreibtools
KI-Schreibtools UPDF Copilot
UPDF Copilot KI-Seitenverwaltung
KI-Seitenverwaltung KI-Semantische Suche
KI-Semantische Suche PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Mit der zunehmenden Nutzung digitaler Inhalte steigt auch der Bedarf an optischer Zeichenerkennung (OCR), um Text aus Bildern oder gescannten Dokumenten zu extrahieren. Eine beliebte Suche im Internet ist die Frage, wie Sie einen OCR-Scan in Bengali durchführen können. In diesem Sinne haben wir diesen exklusiven Leitfaden erstellt, um Ihnen die vier besten Bengali OCR-Softwarelösungen vorzustellen und die Schritte zu erläutern, um sie zu nutzen.
Teil 1. Vergleich der 4 besten Bengali OCR-Tools
Es gibt viele Online-Tools für die Bengali OCR auf dem Markt, aber nicht alle gewährleisten eine genaue Textextraktion. Wir haben also einige Nachforschungen angestellt und die vier besten Tools in die engere Wahl gezogen, die diese Aufgabe zufriedenstellend erfüllen.
Werfen Sie einen Blick auf die Vergleichstabelle unten, um sich einen schnellen Überblick über ihre Fähigkeiten zu verschaffen:
| Funktionen | UPDFs Online AI-Assistent | Bengali Scan | i2OCR | Google Drive |
| AI-Integration | GPT-5 | |||
| Genauigkeit | Höchste (99%) | Hoch | Niedrig | Niedrig |
| Geschwindigkeit | Ultraschnell | Schnell | Schnell | Moderat |
| Unterstützte Dateiformate | Bild, PDF | Bild | Bild, PDF | Bild, PDF, Word, Excel, PPT, usw. |
| Größenbeschränkung | Bilder mit unbegrenzter Größe | Unbegrenzt | Unbegrenzt | Unbegrenzt |
| Sonstige nützliche Funktionen (Übersetzung, Chat mit Dokumenten usw.) | Übersetzung, chat mit Bildern | Text nach Scans bearbeiten | Übersetzen, Text nach Scans bearbeiten | Integration mit Google Docs, direkte Bearbeitung von Dokumenten |
Teil 2. Die 4 besten Bengali-OCR-Tools zum Extrahieren von Text
Eine gute Bengali-OCR-Software muss Text präzise extrahieren können. Sehen wir uns nun die vier besten Bengali-OCR-Tools für 2026 genauer an:
1. UPDFs Online KI-Assistent
UPDFs Online AI-Assistent ist ein AI-gestütztes Bengali-OCR-Tool, das mühelos OCR auf Bildern und gescannten Dokumenten durchführen kann. Es bietet die höchste Genauigkeit bei der Textextraktion, da es durch GPT-5 unterstützt wird. Sie müssen lediglich das Bild oder die gescannte PDF-Datei hochladen und dann die AI bitten, den Text zu extrahieren.
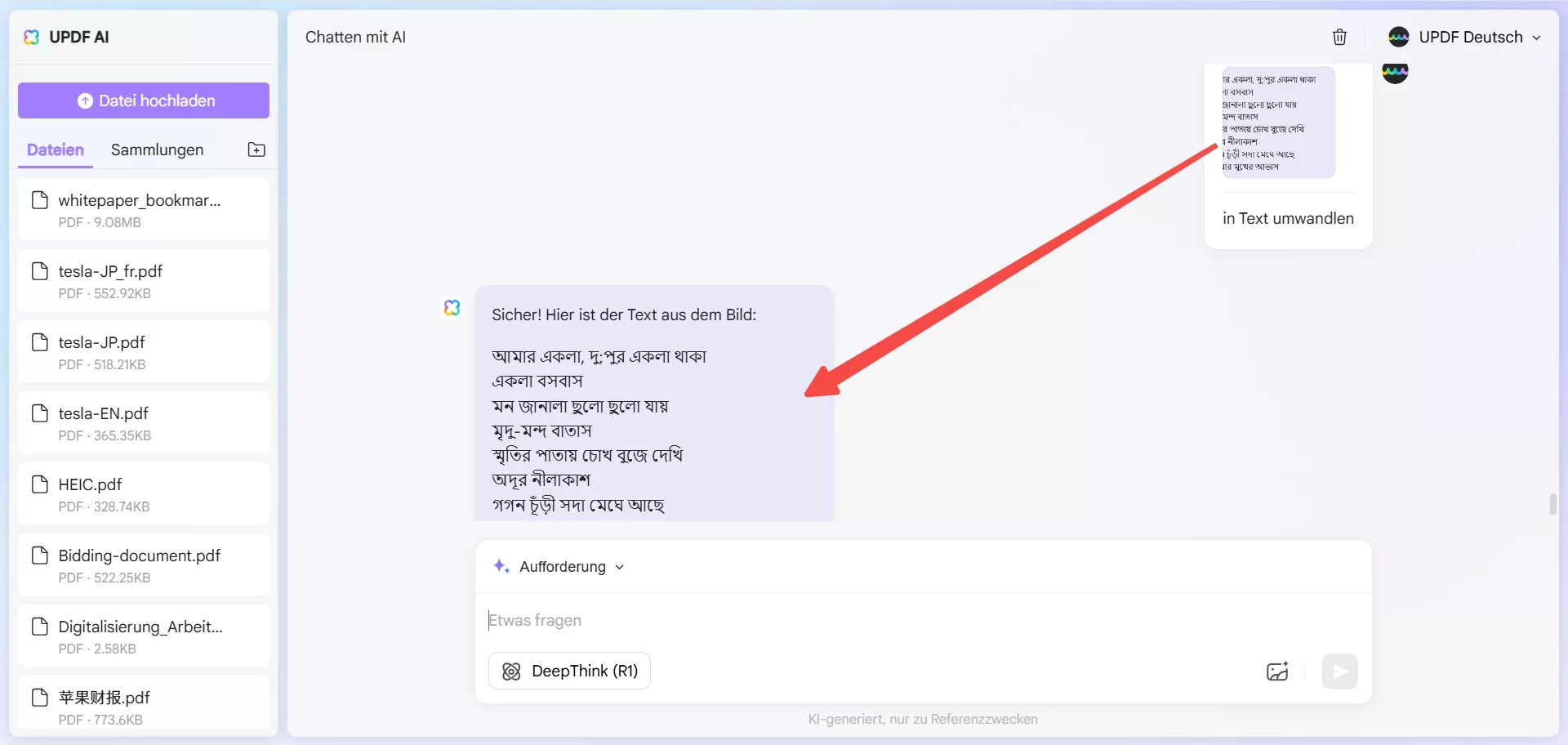
Ein großer Vorteil von UPDF ist, dass sein AI-Assistent viel mehr kann als nur OCR. Sie können ihn beispielsweise auch verwenden, um den extrahierten Text zu übersetzen, die Formulierung zu verbessern/neu zu schreiben oder über alles Mögliche zu chatten. Betrachten Sie ihn als Ihren virtuellen Assistenten, der OCR durchführen und Sie bei anderen dokumentbezogenen Aktivitäten unterstützen kann.
Zu den wichtigsten Funktionen des Online-AI-Assistenten von UPDF gehören:
- OCR von Bildern und gescannten Dokumenten mit hoher Genauigkeit
- Extrahieren von Text in Bengali oder einer anderen Sprache.
- Benutzerfreundliche Oberfläche
- Übersetzen von Bildern und gescannten Dokumenten in Bengali in jede andere Sprache
- Chatten mit Bildern, z. B. zum Erklären von Bildern, zum Generieren von Anzeigeninhalten und vieles mehr.
- AI-Unterstützung beim Umschreiben, Korrekturlesen, Zusammenfassen, Beantworten von Fragen und vieles mehr.
In short, UPDF is the go-to assistant that lets you perform OCR on und gescannten Dokumenten durchführen und andere benötigte Unterstützung erhalten können.
Bewertung: 4,5/5 (G2)
Die OCR-Schritte:
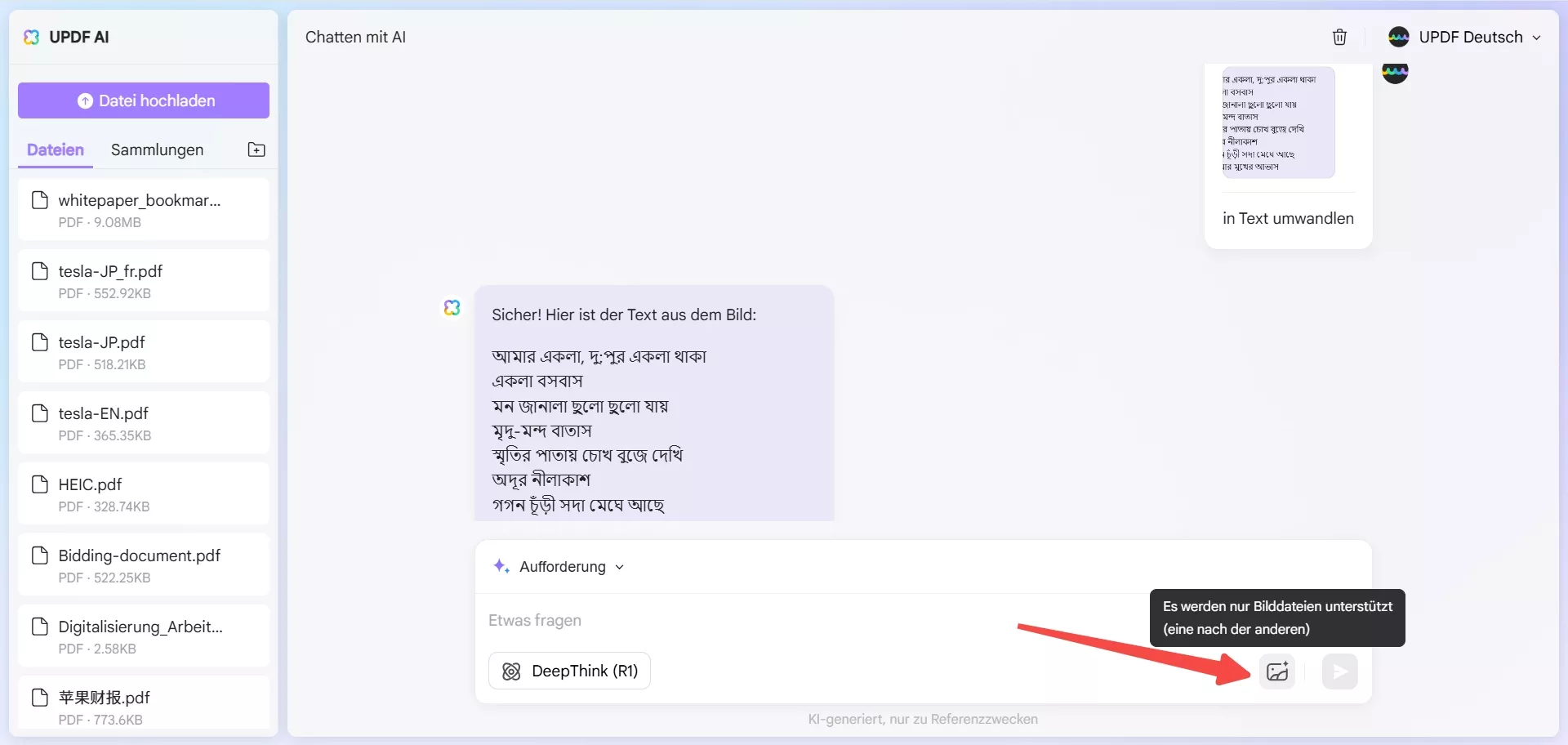
Schritt 1. Klicken Sie auf die Schaltfläche unten, um zur Website ai.UPDF.com zu gelangen, und klicken Sie auf das „Bildsymbol“, um das Bild hochzuladen.
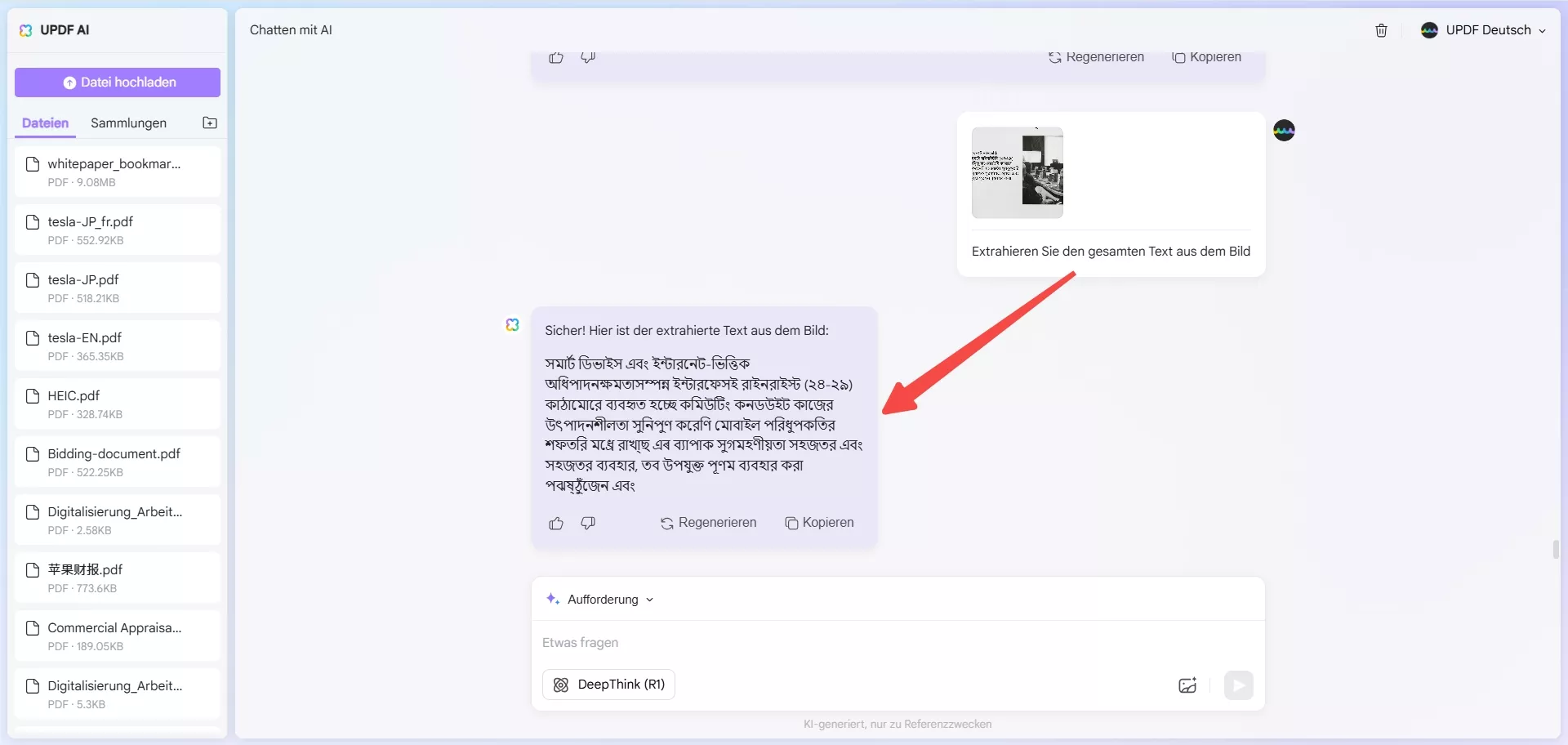
Schritt 2. Schreiben Sie in das Chat-Feld eine Eingabeaufforderung wie „Extrahieren Sie den gesamten Text aus dem Bild“. UPDF AI extrahiert den Text sofort aus dem Bild.
Schritt 3. Als Nächstes können Sie den extrahierten Text kopieren oder die AI um weitere Unterstützung bitten, z. B. „Den extrahierten Text ins Englische übersetzen“. Alternativ können Sie die AI bitten, den Bengali-Text aus dem Bild im letzten Schritt direkt zu übersetzen.
Auf diese Weise erhalten Sie mit UPDF genaue, von der AI unterstützte Bengali-OCR-Bilder. Besuchen Sie die Website von UPDF AI und erhalten Sie sofort und kostenlos einen OCR-Scan.
Hinweis: Um gescannte PDFs umzuwandeln, müssen Sie einen Screenshot des zu extrahierenden Inhalts erstellen und dann die oben genannten Schritte ausführen, um den Text zu extrahieren.
Vorteile:
- Mühelose OCR von Bildern und gescannten Dokumenten
- 99 % Genauigkeit bei der Textextraktion
- Unterstützt die Erkennung von Bildern/gescannten Dokumenten in jeder Sprache
- Webbasiert, kompatibel mit allen Betriebssystemen
- Der AI-Assistent dient auch anderen Zwecken, wie z. B. Übersetzungen, Erklärungen und mehr.
Nachteile:
- Eine direkte OCR kann nicht innerhalb von Dokumenten durchgeführt werden. Wenn Sie jedoch gescannte PDFs in Sprachen wie Englisch, Deutsch, Italienisch, Japanisch, Chinesisch, Französisch und mehr umwandeln müssen (eine vollständige Liste der über 38 unterstützten Sprachen finden Sie hier), können Sie die Desktop-Version von UPDF herunterladen. Mit der Desktop-Anwendung können Sie OCR in PDF durchführen und dabei das ursprüngliche Layout der Datei beibehalten.
Windows • macOS • iOS • Android 100% sicher

2. Bengali Scan
Wenn Sie Text aus Bildern direkt von Ihrem Android-Handy extrahieren möchten, können Sie Bengali Scan verwenden.
Bengali Scan ist eine Android-App, die eine intuitive Benutzeroberfläche zur Durchführung von OCR auf Bildern bietet. Sie können Bilder hochladen oder direkt von der Kamera scannen. Anschließend kann der Bengali oder englische Text sofort aus dem Bild extrahiert werden. Nach dem Extrahieren können Sie den Text direkt bearbeiten oder als Text- oder PDF-Datei speichern.
Bewertung: 3,8/5 (Google Play)

Die OCR-Schritte:
Schritt 1. Installieren Sie „Bild zu Text OCR Bengali Scan“ von Google Play und starten Sie die App.
Schritt 2. Laden Sie das Bild hoch oder nehmen Sie es mit Ihrer Kamera auf.
Schritt 3. Die App führt sofort eine OCR durch. Anschließend können Sie den Text direkt bearbeiten oder auf die entsprechende Option klicken, um den Text in einer TXT- oder PDF-Datei zu speichern.
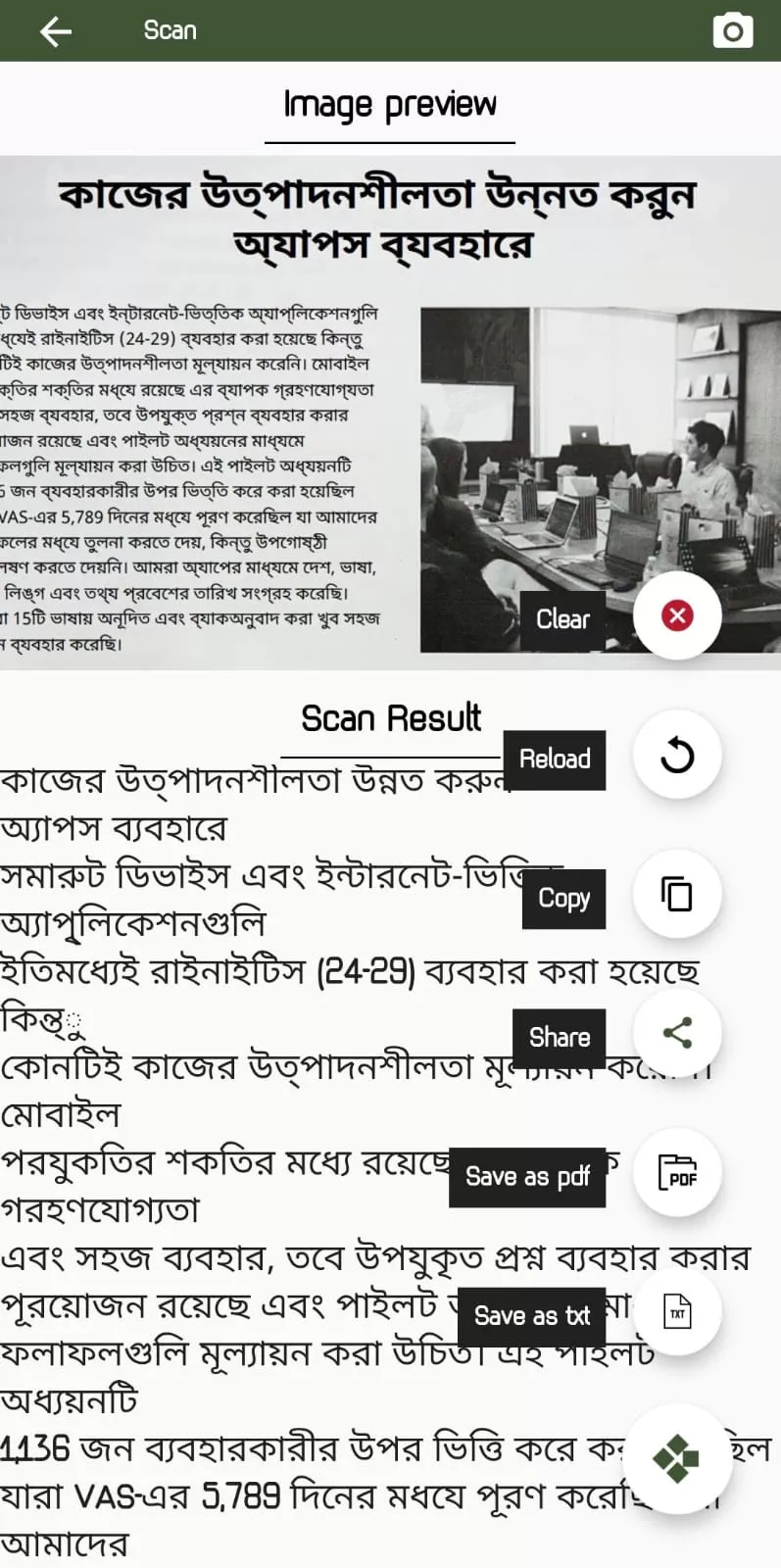
Vorteile:
- Kostenlose Android-basierte Bengali-OCR-App
- Schneller OCR-Scan
- Benutzerfreundliche Oberfläche
- Direkte Bearbeitung des Textes
Nachteile:
- Nur für Android-Geräte
- Keine Option zum Extrahieren von Text aus gescannten PDFs
- Werbeanzeigen
3. i2OCR
i2OCR ist ein Online-Tool für Bengali OCR, das Text aus Bildern und gescannten PDFs extrahieren kann. Es kann eine Bilddatei in einen durchsuchbaren und bearbeitbaren Text umwandeln und diesen dann im PDF-, Doc- oder HTML-Format herunterladen. Außerdem können Sie den extrahierten Text in andere Sprachen übersetzen.
i2OCR bietet eine webbasierte Oberfläche, auf der Sie die Datei hochladen und sofort eine Texterkennung erhalten können. Die Nutzung ist kostenlos und erfordert keine Anmeldung.
Bewertung: N/A
Die OCR-Schritte:
Schritt 1. Gehen Sie zur Website von i2OCR. Wählen Sie aus, ob Sie eine Bild- oder PDF-OCR durchführen möchten.
Schritt 2. Wählen Sie die Sprache „Bengali“ und das Bildlayout aus, laden Sie das Bild hoch und klicken Sie auf „Text extrahieren“.
Schritt 3. Das Tool führt sofort eine OCR durch und generiert ein neues Dokument mit extrahiertem Text. Als Nächstes können Sie den extrahierten Text bearbeiten, übersetzen oder in Ihrem bevorzugten Format herunterladen.
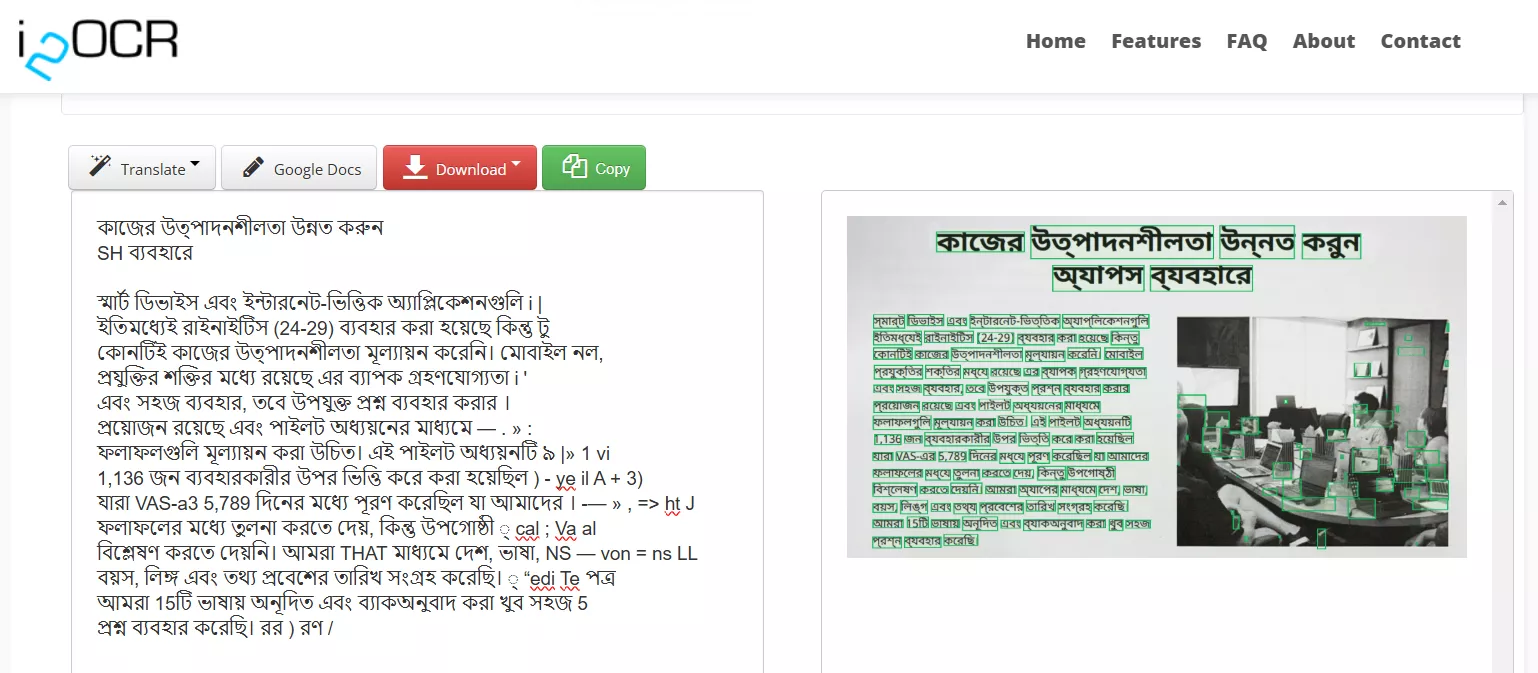
Vorteile:
- Kostenlose webbasierte OCR-Software für Bengali
- Schnelle Textextraktion
- Textübersetzung und -bearbeitung
Nachteile:
- Möglicherweise nicht immer genaue Ergebnisse
4. Google Drive
Die letzte und eine weitere effektive Möglichkeit, einen Bengali-OCR-Scan durchzuführen, ist Google Drive. Es handelt sich um eine bekannte Cloud-Speicherplattform, die aber auch OCR für Sie durchführen kann.
Sie müssen zunächst das Bild oder Dokument auf Google Drive hochladen und es dann mit Google Docs öffnen. Während dieses Vorgangs führt das System eine Texterkennung durch und ermöglicht es Ihnen, den Text aus Google Docs einfach zu kopieren, zu bearbeiten oder zu speichern.
Bewertung: 4,6/5 (Gartner)
Schritte
Schritt 1. Gehen Sie zu Drive.Google.com und melden Sie sich mit Ihrem Google-Konto an.
Schritt 2. Klicken Sie auf „Neu“ > „Datei-Upload“ und laden Sie die PDF- oder Bilddatei hoch.
Schritt 3. Klicken Sie auf die „3 Punkte“ neben der Datei und wählen Sie „Öffnen mit“ > „Google Docs“ aus.
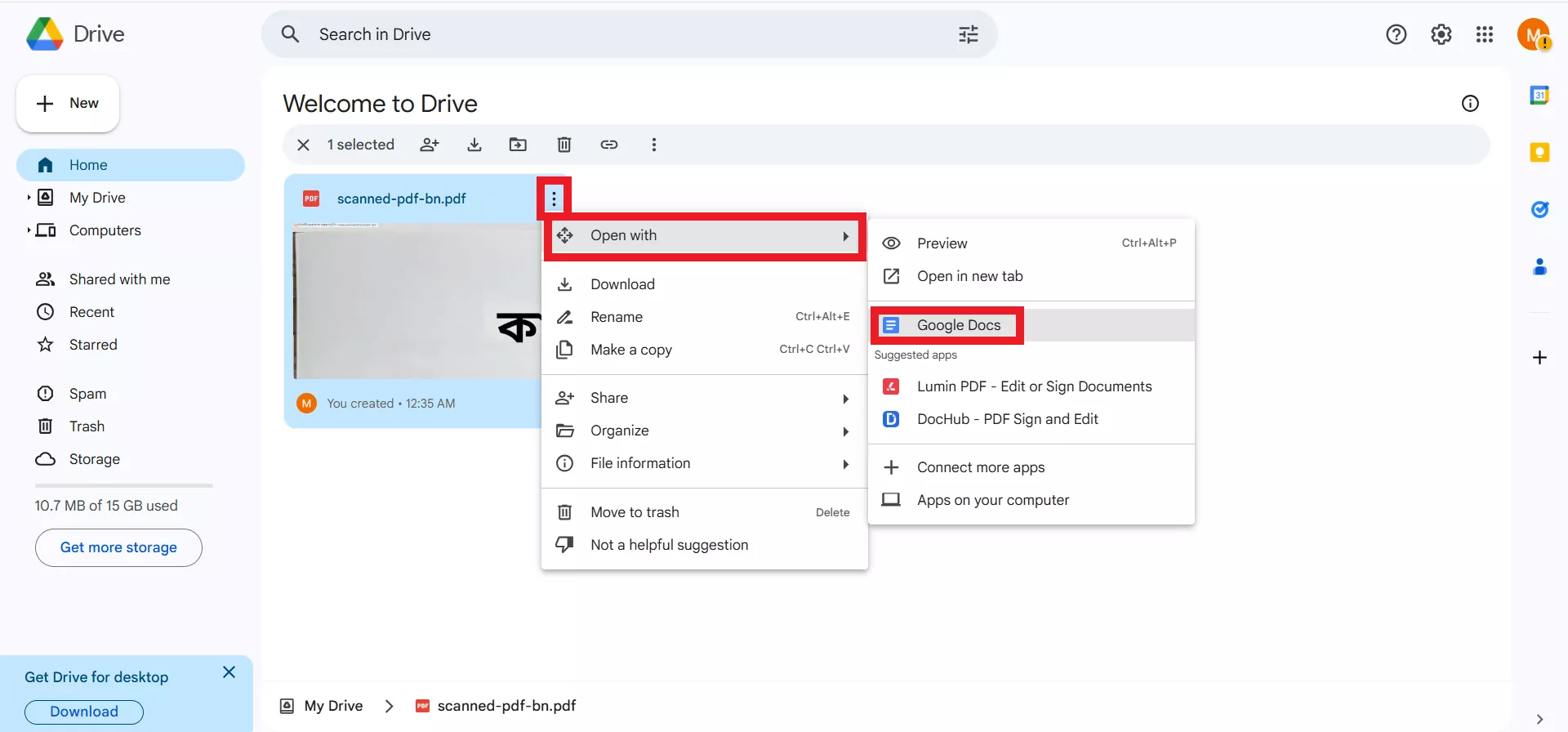
Schritt 4. Warten Sie, bis die Datei in Google Docs geöffnet wurde. Während dieses Vorgangs wird auch eine OCR durchgeführt.
Schritt 5. Sobald die Datei in Google Docs geöffnet wurde, können Sie den Text bearbeiten, kopieren oder die Datei in Ihrem gewünschten Format speichern, z. B. DOCX, PDF, TXT usw.
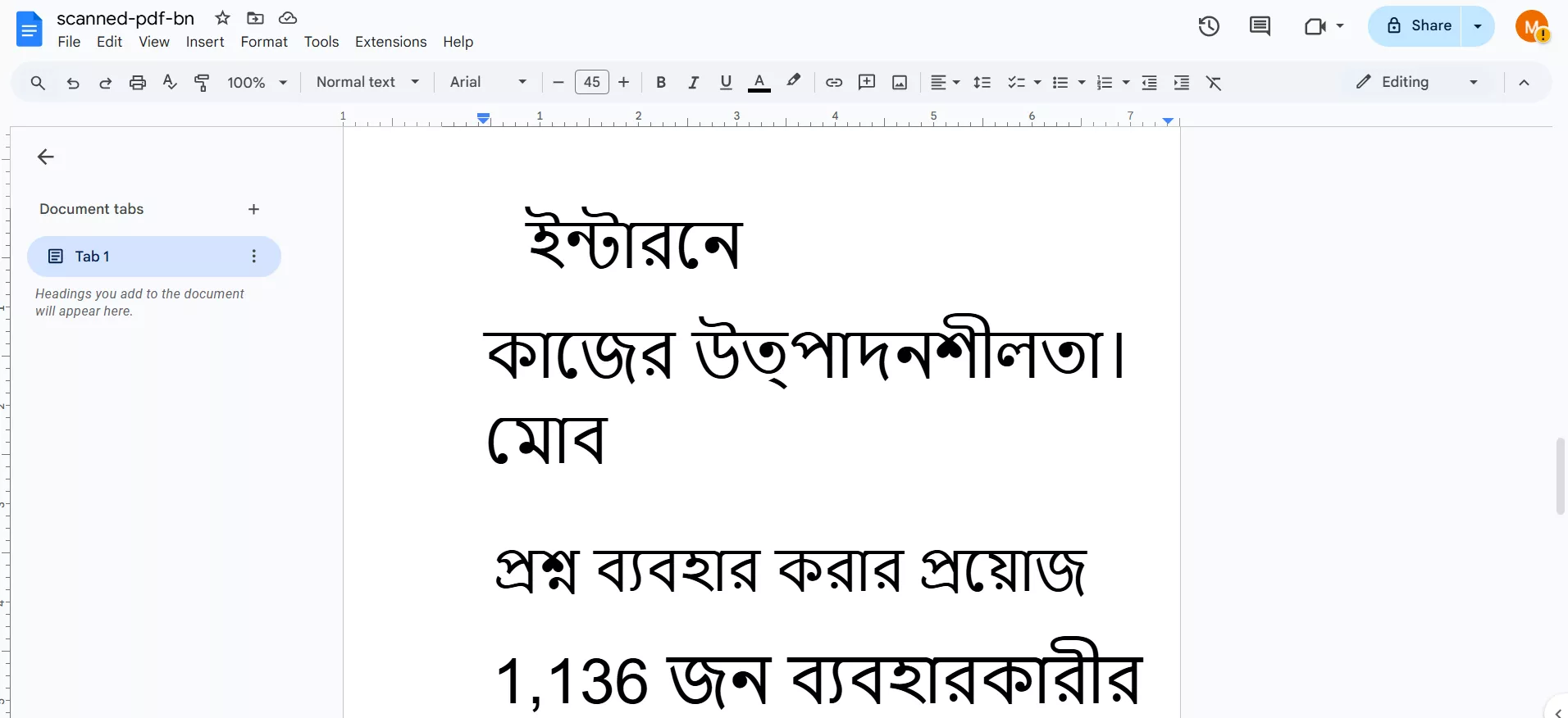
Vorteile:
- Kostenlose Möglichkeit zur Durchführung von Bengali-OCR
- Sichere Dokumentenspeicherung und Textextraktion
- Klickbasierter Prozess
Nachteile:
- Die ursprüngliche Formatierung und das Layout können nicht beibehalten werden.
- Bilder aus der gescannten PDF-Datei werden bei der OCR ignoriert.
- Möglicherweise wird die Textextraktion ignoriert.
Fazit
Es gibt viele Online-Tools für die OCR in Bengali, mit denen Sie bengalischen Text einfach aus Bildern oder anderen Dokumenten extrahieren können. Die oben genannten vier Optionen sind die besten, um mühelos Text zu extrahieren. Unter allen haben wir UPDF aufgrund seiner AI-gestützten OCR und höchsten Genauigkeit als beste Wahl befunden. Darüber hinaus können Sie den AI-Assistenten auch für andere Aufgaben nutzen und beispielsweise Dokumente übersetzen. Probieren Sie den Online-AI-Assistenten von UPDF für die Textextraktion aber am besten aus und überzeugen Sie sich selbst!










 Delia Meyer
Delia Meyer 