 UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Das PDF-Format hat sich zum meistgenutzten Format für Unternehmen entwickelt. Da die meisten wichtigen Daten von Unternehmen in PDF-Dateien gespeichert werden, ist es oft erforderlich, Text aus der PDF-Datei zu extrahieren. Dies kann jedoch schwierig sein, da das Kopieren, Extrahieren und Bearbeiten von Texten in PDFs ohne die richtigen Methoden und Werkzeuge nicht möglich ist, insbesondere wenn Ihre PDF-Dateien gescannt oder mit Bildern erstellt wurden.
Einige von Ihnen wissen vielleicht, dass Sie mit OCR Text aus PDF-Dateien extrahieren können. Aber wann sollte man OCR verwenden und wann nicht? In diesem Artikel finden Sie Lösungen für die Extraktion von Texten aus PDF-Dateien mit und ohne OCR-Funktion. Lesen Sie weiter.
Weg 1. Wie extrahiert man Text aus PDF mit OCR?
Wenn PDF-Dateien mit Scannern oder Bildern erstellt wurden, besteht die übliche Methode zur Extraktion von Text aus PDF-Dateien darin, einen PDF-Editor mit einem OCR-Tool zu verwenden. Hier zeigen wir Ihnen anhand von UPDF, wie Sie Text aus gescannten oder bildbasierten PDFs extrahieren können.

UPDF ist ein innovativer PDF-Editor, der eine Komplettlösung für PDF-Dateien bietet, die sowohl den Anforderungen großer Unternehmen als auch denen von Einzelpersonen, die in kleinem Rahmen arbeiten, gerecht wird. Es bietet alle Funktionen, die Sie benötigen, wie z. B. die Bearbeitung, Konvertierung, Zusammenführung und Kommentierung Ihrer PDF-Dateien.
Wenn Sie Text aus gescannten PDFs extrahieren möchten, können Sie UPDF verwenden, da es eine spezielle OCR-Funktion bietet, mit der Sie gescannte PDF-Dokumente in bearbeitbaren und extrahierbaren Text umwandeln können. Folgen Sie den unten beschriebenen Schritten:
Schritt 1. UPDF herunterladen und installieren
Laden Sie UPDF herunter und folgen Sie der unten stehenden Anleitung, um zu erfahren, wie Sie Text aus gescannten PDF-Dateien extrahieren können.
Windows • macOS • iOS • Android 100% sicher
Schritt 2: Zugriff auf die OCR-Funktion
Öffnen Sie die PDF-Datei in UPDF und klicken Sie auf die Schaltfläche „Text mit OCR erkennen“ auf der rechten Seite.
Im Pop-up-Fenster wählen Sie „Suchbares PDF“, dann müssen Sie das Layout in den „Layout“-Einstellungen festlegen. Wählen Sie „Nur Text und Bilder“, „Text über dem Seitenbild“ oder „Text unter dem Seitenbild“, und wenn es erweiterte Layout-Optionen gibt, wählen Sie das „Zahnrad“-Symbol und bearbeiten Sie die Optionen, falls erforderlich.
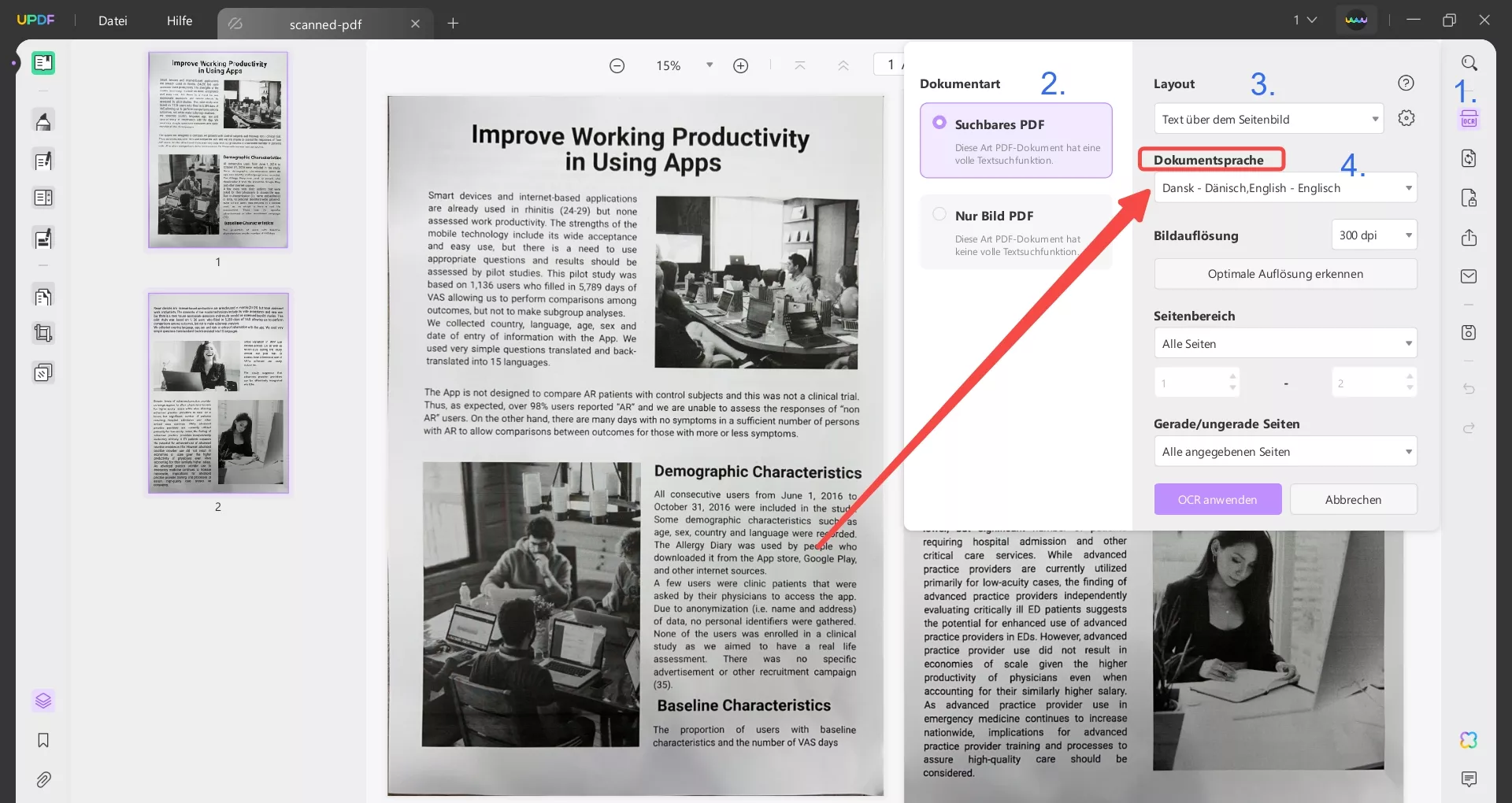
Wählen Sie die Dokumentsprache aus der Liste der 38 verschiedenen verfügbaren Sprachen aus. Anschließend nehmen Sie die Einstellungen für die „Bildauflösung“ vor und legen einen bestimmten Wert aus der Liste fest. Wenn Sie unsicher sind, klicken Sie auf die Schaltfläche „Optimale Auflösung erkennen“ und fahren Sie fort.
Schritt 3: OCR erfolgreich anwenden
Wählen Sie den Seitenbereich aus, auf dem Sie das OCR-Tool ausführen möchten. Wählen Sie anschließend die Schaltfläche „OCR anwenden“, wählen Sie den Speicherort für das OCR-Dokument und lassen Sie den Vorgang ausführen. Anschließend wird UPDF geöffnet, wo Sie den Text aus der PDF-Datei extrahieren können.
Schritt 4. Text aus der PDF-Datei extrahieren oder kopieren
Jetzt können Sie den Text, den Sie aus der PDF-Datei kopieren oder extrahieren möchten, durch Anklicken auswählen und dann an den gewünschten Ort kopieren und einfügen.
Weg 2. Text aus PDF in Word/Excel/anderes Format extrahieren
Die obige Methode ist gut, wenn Sie den Text eines Teils der PDF-Datei kopieren müssen. Wenn Sie den gesamten Text aus der PDF-Datei extrahieren müssen, wird es sehr lange dauern. Es gibt eine schnelle Möglichkeit, UPDF zu verwenden. Hier erfahren Sie, wie es geht.
Schritt 1. PDF öffnen und zur Option „PDF-Datei exportieren“ gehen
Starten Sie UPDF auf Ihrem Computer, klicken Sie auf „Datei öffnen“ und wählen Sie die PDF-Datei auf Ihrem Computer aus, um sie zu öffnen.
Navigieren Sie zu „PDF-Datei exportieren“ im Menü auf der rechten Seite und klicken Sie darauf. Wählen Sie das gewünschte Format, das Sie benötigen. Wählen Sie zum Beispiel „Word“.

(Hinweis: Wenn es sich bei Ihrem PDF-Dokument um ein gescanntes Dokument handelt, müssen Sie zuerst die Anweisungen in Weg 1 befolgen, um die OCR durchzuführen. Das mit OCR bearbeitete Dokument wird automatisch in UPDF geöffnet).
Schritt 2. PDF in Excel/Word/beliebiges Format konvertieren
Nach der Auswahl des Formats können Sie in dem neuen Fenster bei Bedarf den Seitenbereich festlegen. Klicken Sie abschließend auf die Schaltfläche „Exportieren“ und wählen Sie den Speicherort für die konvertierten Dateien aus.
Sobald der Vorgang abgeschlossen ist, können Sie den gesamten Text aus der gescannten PDF-Datei in Excel, Word oder ein anderes Format extrahieren, das Sie benötigen. Sie können die bearbeitbare Datei auf Ihrem Computer öffnen und beliebige Operationen durchführen.
Weg 3. Stapelweise Textextraktion aus PDF
Das Extrahieren von Text aus einer einzelnen Datei kann mit UPDF in mehreren Schritten durchgeführt werden. Aber wie können Sie Text aus mehreren PDF-Dateien extrahieren? Keine Sorge, wir werden Ihnen auch hier weiterhelfen.
Schritt 1. UPDF starten
Doppelklicken Sie auf das UPDF-Symbol auf Ihrem Desktop, um es zu starten. Auf dem Startbildschirm finden Sie einige Optionen. Klicken Sie auf das Symbol „Batch“.
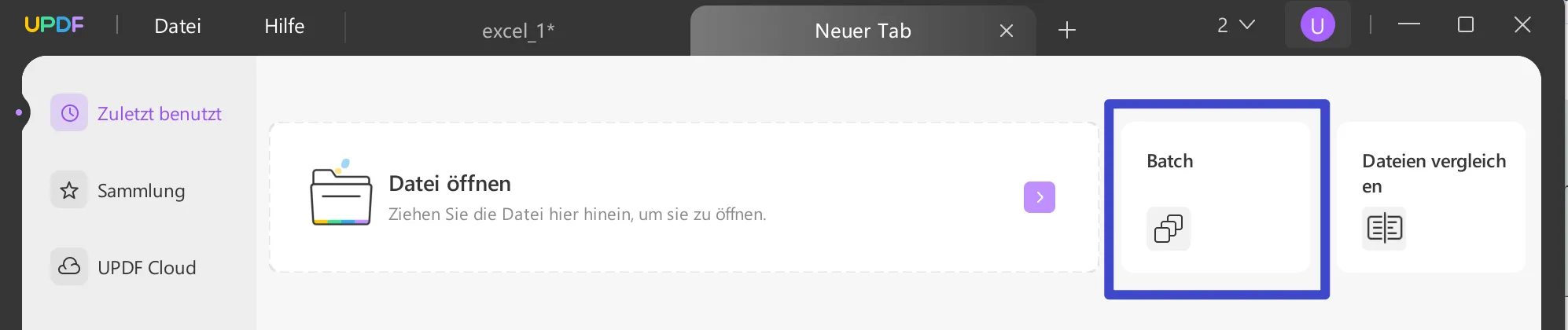
Sie werden dann mehrere Optionen finden. Wählen Sie die Option „Umwandeln“.

Schritt 2. Stapelweise Text aus mehreren PDF-Dateien extrahieren
Wählen Sie im neuen Fenster das Ausgabeformat, ändern Sie andere Einstellungen, klicken Sie auf „Anwenden“, wählen Sie den Speicherort und klicken Sie auf „Speichern“, um den Vorgang auszuführen. Anschließend finden Sie die bearbeitbaren Dateien im Pop-up-Speicherort.
Weg 4. Wie extrahiert man Text aus PDFs ohne OCR?
OCR ist eine hervorragende Möglichkeit, Text aus PDFs zu extrahieren. Vielleicht haben Sie jedoch eine normale PDF-Datei und möchten Text extrahieren oder Sie möchten die OCR-Funktionen einfach nicht verwenden. Was auch immer die Gründe sind, Sie suchen nach einer Möglichkeit, Text aus PDFs ohne OCR zu extrahieren. Wir kennen Ihre Szenarien und stellen Ihnen hier drei effektive Möglichkeiten vor.
Wenn Sie eine normale PDF-Datei verwenden, die nicht von Scannern oder Bildern erstellt wurde, können Sie die UPDF-Bearbeitungsfunktionen nutzen, um Text aus einer PDF-Datei zu extrahieren. Hier ist die Vorgehensweise.
Schritt 1: Navigieren Sie zum Bearbeitungsmodus
Der erste Schritt besteht darin, eine PDF-Datei in UPDF zu öffnen, aus der Sie Text extrahieren möchten. Klicken Sie dazu auf die Schaltfläche „Datei öffnen“ in der Mitte der UPDF-Oberfläche.
Nachdem Sie die PDF-Datei in UPDF importiert haben, navigieren Sie zur Symbolleiste und klicken auf die Registerkarte „PDF bearbeiten“, um den Bearbeitungsmodus auf Ihre Datei anzuwenden.
Schritt 2: Extrahieren von Wörtern aus der PDF-Datei
Markieren Sie den Text, den Sie aus einer PDF-Datei extrahieren möchten, indem Sie mit der rechten Maustaste darauf klicken und anschließend auf die Option „Kopieren“ klicken oder die Tastenkombination „Strg + C“ verwenden. Nachdem Sie den Text kopiert haben, können Sie den extrahierten Text in eine Word-Datei oder ein anderes Dateiformat einfügen.
Darüber hinaus ist UPDF auf Mac, Windows, iOS und Android-Geräten verfügbar und unterstützt eine Lizenz für alle Plattformen, was es zu einer idealen Lösung für Benutzer mit unterschiedlichen Betriebssystemen macht. Neben dem Extrahieren von Text aus PDF hat UPDF auch viele andere Funktionen. Hier sind einige der wichtigsten Funktionen:
Hauptmerkmale von UPDF Benutzerfreundlicher PDF-Editor:
UPDF bietet seinen Anwendern eine Reihe von Schlüsselfunktionen, die es zu einem Zentrum von Lösungen für alltägliche PDF-Editoren machen. Einige dieser Funktionen sind unten aufgeführt:
- Konvertieren Sie PDF in Bilder, Word, Excel, PPT und jedes andere Format, das Sie benötigen: UPDF unterstützt die Funktion der Konvertierung von PDF in ein beliebiges Dateiformat. Wenn Sie Text aus einem PDF direkt in Word, Excel oder andere Formate extrahieren möchten, können Sie dies ohne Probleme tun.
- Bearbeiten Sie PDF-Texte und fügen Sie Bilder, Texte und Links zu PDF hinzu: UPDF ermöglicht es Ihnen, PDF-Texte zu bearbeiten, die Schriftart, Farbe und Größe zu ändern, die Bildgröße zu ändern und beliebige Texte, Bilder und Links zu PDF hinzuzufügen.
- PDF annotieren: Fügen Sie Haftnotizen, Textkommentare, Hervorhebungen, Durchstreichen, Unterstreichen, Formen, Aufkleber und weitere Kommentarfunktionen zu Ihrem PDF hinzu.
- Verwalten und Organisieren von PDFs: UPDF unterstützt das Einfügen, Löschen, Extrahieren, Teilen von Seiten und Drehen von Seiten.
- Hinzufügen eines Kennworts zum Öffnen und Zulassen: UPDF ermöglicht es dem Benutzer auch, ein Kennwort zu den PDF-Dateien hinzuzufügen, um wichtige PDF-Dokumente und Formulare zusätzlich zu schützen.
- PDF in Diashow abspielen.
Nachdem Sie all die erstaunlichen Funktionen von UPDF kennengelernt haben, fragen Sie sich vielleicht, wo Sie diese leistungsstarke Software herunterladen können. Klicken Sie auf die Schaltfläche „Free Download“ unten und installieren Sie es jetzt!
Windows • macOS • iOS • Android 100% sicher
Wenn Sie mehr darüber erfahren möchten, wie man ein PDF ocriert, sehen Sie sich die folgende Videoanleitung an.
FAQs zum Extrahieren von Text aus PDF
1. Kann man Text aus einem PDF-Bild extrahieren?
Ja, Sie können Text aus PDF-Bildern extrahieren, indem Sie die von UPDF angebotene OCR-Funktion verwenden. Importieren Sie das PDF-Bild in UPDF und klicken Sie auf das Symbol „Erkennen von Text mit OCR“ im rechten Bereich des UPDF-Fensters. Nachdem Sie auf „Text mit OCR erkennen“ geklickt haben, wählen Sie die Option „OCR anwenden“, um den Konvertierungsprozess vom PDF-Bild in ein editierbares und durchsuchbares PDF zu starten. Sie können den Text in den OCR-PDFs extrahieren, sobald die Konvertierung abgeschlossen ist.
2. Wie kann ich Text aus einer PDF-Datei ohne Acrobat extrahieren?
Sie können Text aus einer PDF-Datei extrahieren, indem Sie UPDF anstelle von Adobe Acrobat verwenden, da dies eine kostengünstigere, schnellere und intuitivere Lösung ist. Es funktioniert für Mac, Windows, Android und iOS.
3. Kann ich Text aus einer PDF-Datei unter Linux extrahieren?
Ja, Sie können Inhalte aus PDF-Dateien unter Linux extrahieren, indem Sie verschiedene auf dem Markt erhältliche Online-Tools verwenden, wie z. B. die Google Drive-Methode oder die OCR-Funktion von PDF24 Tools auf Ihrem Linux-Betriebssystem.
Fazit
Obwohl es auf dem Markt viele Möglichkeiten gibt, Text aus PDF-Dateien mit und ohne OCR zu extrahieren, ist es die klügste und zuverlässigste Wahl, ein spezielles und renommiertes Tool für PDF-Dateien zu verwenden. In dieser Hinsicht ist UPDF die beste Wahl, denn es erledigt die Aufgabe nicht nur effizient und genau, sondern unterstützt auch die Sicherheit Ihrer Daten, die Bearbeitung von PDF, die Konvertierung von PDF und vieles mehr. Jetzt gibt es ein exklusives Angebot und Sie können jetzt auf UPDF Pro upgraden. Sie können UPDF auch noch heute auf Ihren Windows-Computer oder Ihr MacBook herunterladen und eine zufriedenstellende Benutzererfahrung genießen.
Windows • macOS • iOS • Android 100% sicher





 Delia Meyer
Delia Meyer 


