 Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF Nomostar
Nomostar UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
iOSでPDFに OCRする
iPhoneでスキャンしたPDFファイルを扱うのは、テキストが画像に埋もれてしまうことが多いため、非常に面倒です。
しかし、iOS版UPDFは、強力なOCR PDF機能を搭載しており、スキャンした文書からテキストや画像を抽出またはコピーできます。
さらに、元のレイアウトを維持したまま、編集・検索可能なPDFファイルを作成することもできます。
iOS版UPDFは、画像やスキャンしたPDFからテキストを抽出できます。複数の言語とその変種に対応しており、正確なOCR処理が可能です。つまり、iPhoneでスキャンした文書をより簡単に、より柔軟に扱うことができます。
UPDF 2.0を今すぐダウンロードしましょう。App Storeから入手するか、下のボタンをクリックして始めましょう。
Windows • macOS • iOS • Android 100%安全
iPhoneでPDFをOCRする方法は?
iOS版UPDFは、スキャンした文書のOCR処理を、クリック操作だけで素早く実行できるアプローチを提供します。iPhoneでPDFのOCR処理を実行するには、以下の手順に従ってください。
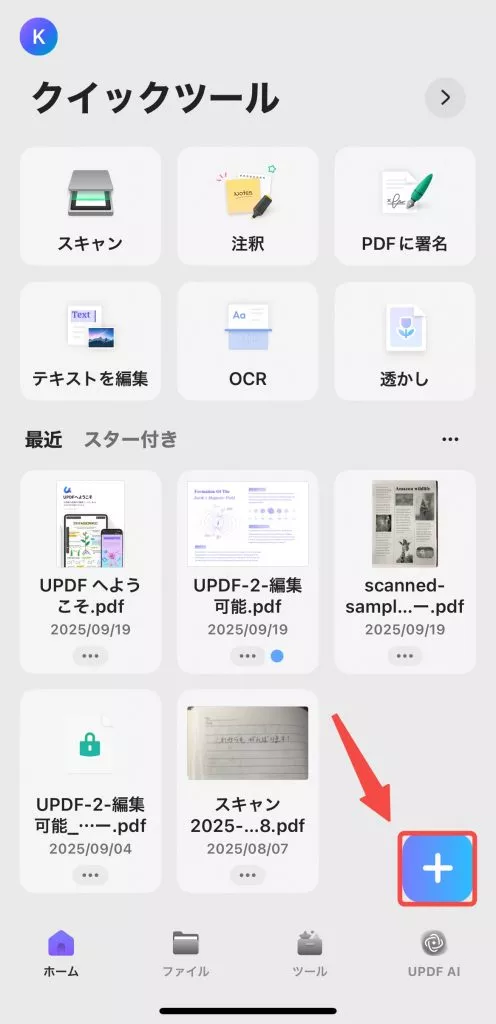
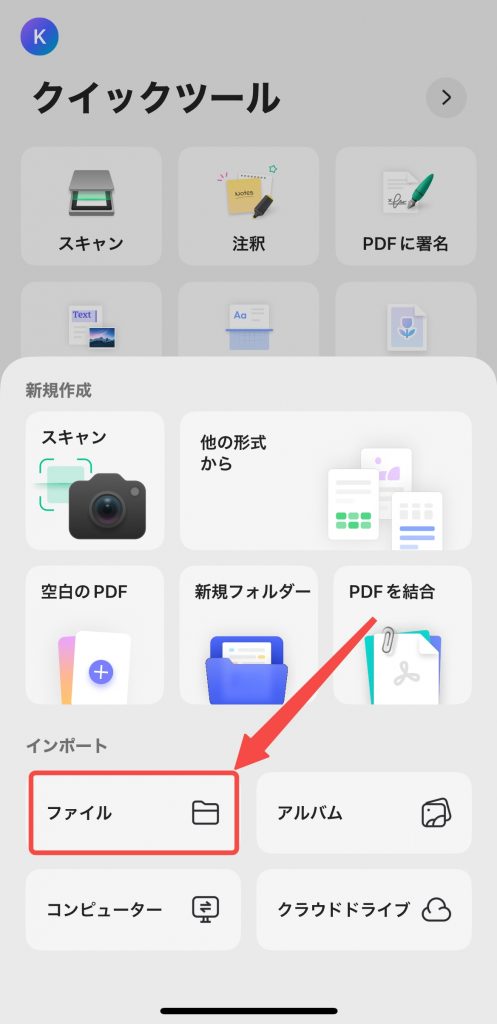
ステップ1. iPhoneでUPDFアプリを開きます。右下の「+」アイコンをクリックし、 「ファイル」をタップしてスキャンしたPDFを選択します。
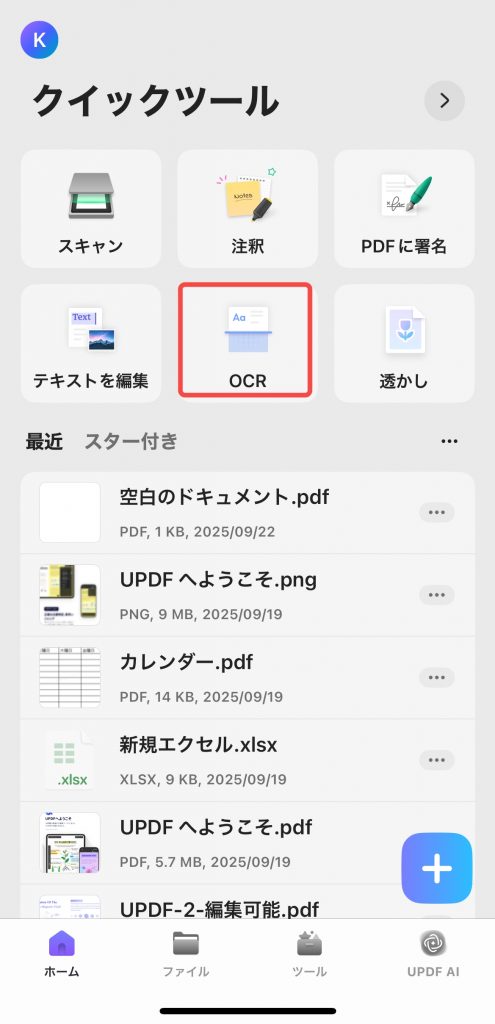
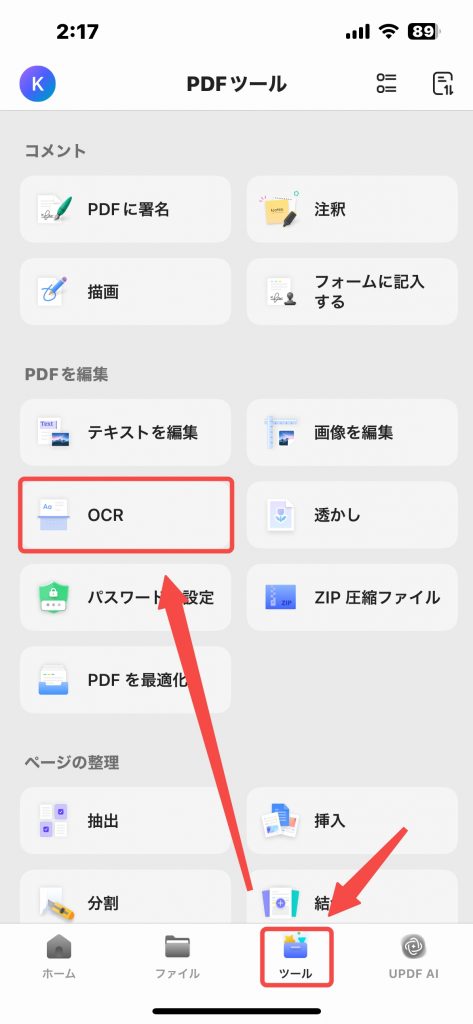
ステップ 2. 「クイック ツール」から「OCR」をクリックするか、 「ツール > OCR」をタップします。
ステップ 3.スキャンした PDF ファイルを選択します。
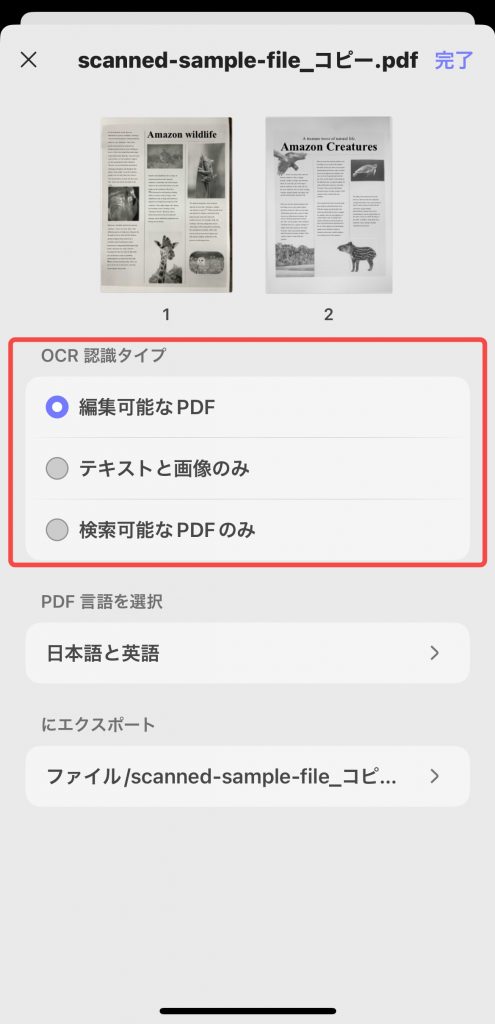
ステップ 4. 「OCR認識タイプ」で、次のいずれかのオプションを選択します。
- 編集可能なPDF:スキャン画像を完全に編集可能なPDFに変換します。テキストと画像の両方を選択、変更、移動できますが、元のレイアウトは維持されます。ページのレイアウトを維持したまま画像を置き換えることもできます。
- テキストと画像のみ:ページの書式を保持せずに、スキャンからテキストと画像のみを抽出します。シンプルなファイルからテキストや画像をコピーまたは編集したい場合に便利です。
- 検索可能なPDFのみ:スキャンしたページの画像はそのまま保持されますが、非表示のテキストレイヤーが追加されます。これにより、テキスト編集はできなくなりますが、ファイルは検索可能になります。
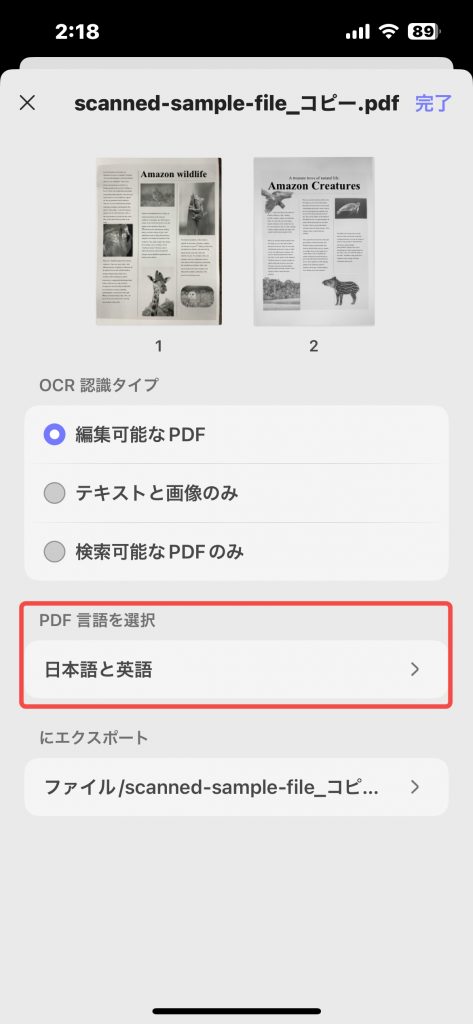
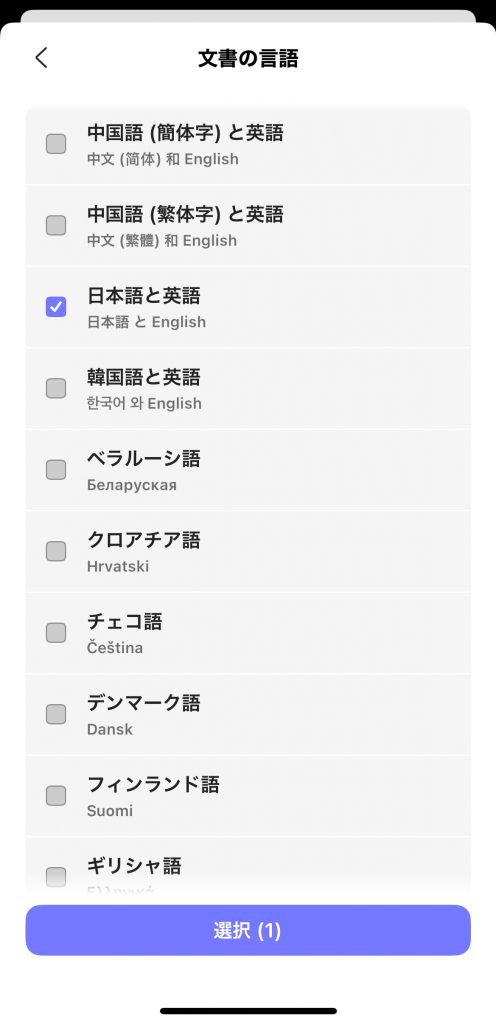
ステップ5. 「PDF言語を選択」をクリックし、文書の言語を選択します。文書に複数の言語のテキストが含まれている場合は、複数の言語を選択してください。
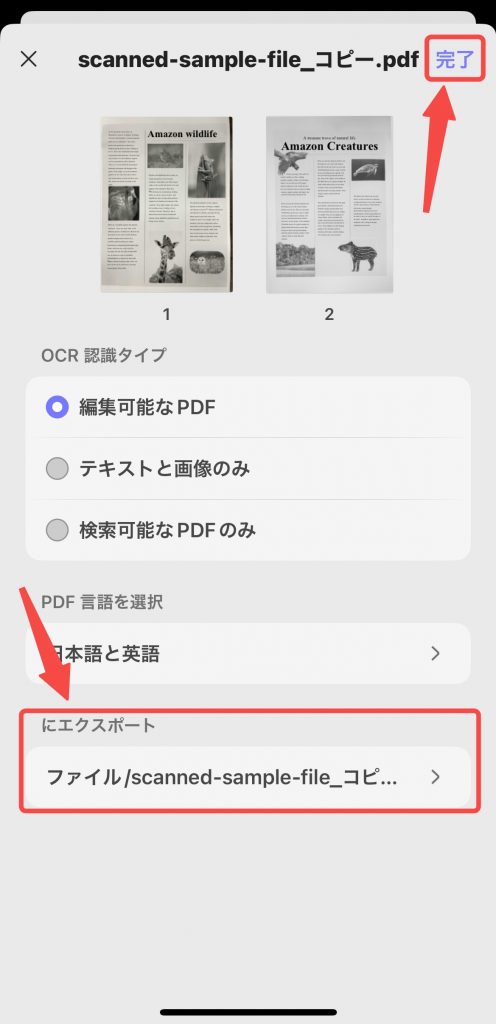
ステップ 6. エクスポート先の場所を設定して、OCR された PDF を保存する場所を指定し、 「完了」ボタンを押して OCR を開始します。
ステップ7. OCRが完了するまでお待ちください。OCRが完了したら、 「ファイル」タブに移動し、新しく生成されたOCR処理済みのPDFファイルを開きます。テキストをコピーするか、UPDFの編集機能を使用してテキストと画像を編集します。
UPDFを使えば、スキャンしたPDFファイルを素早くOCR処理し、ドキュメントを自在にコントロールできます。
今すぐiPhoneにUPDF 2.0をインストールして、iPhoneでよりスマートなPDF編集を体験してください。下のボタンをクリックしてダウンロードするか、 App Storeから入手してください。
Windows • macOS • iOS • Android 100%安全