 UPDF pour Windows
UPDF pour Windows UPDF pour Mac
UPDF pour Mac UPDF pour iPhone/iPad
UPDF pour iPhone/iPad updf android
updf android Nomostar
Nomostar UPDF AI en ligne
UPDF AI en ligne UPDF Sign
UPDF Sign IvyCraft
IvyCraft Modifier le PDF
Modifier le PDF Annoter le PDF
Annoter le PDF Créer un PDF
Créer un PDF Formulaire PDF
Formulaire PDF Modifier les liens
Modifier les liens Convertir le PDF
Convertir le PDF OCR
OCR PDF en Word
PDF en Word PDF en Image
PDF en Image PDF en Excel
PDF en Excel Organiser les pages PDF
Organiser les pages PDF Fusionner les PDF
Fusionner les PDF Diviser le PDF
Diviser le PDF Rogner le PDF
Rogner le PDF Pivoter le PDF
Pivoter le PDF Protéger le PDF
Protéger le PDF Signer le PDF
Signer le PDF Rédiger le PDF
Rédiger le PDF Biffer le PDF
Biffer le PDF Supprimer la sécurité
Supprimer la sécurité Lire le PDF
Lire le PDF UPDF Cloud
UPDF Cloud Compresser le PDF
Compresser le PDF Imprimer le PDF
Imprimer le PDF Traiter par lots
Traiter par lots À propos de UPDF AI
À propos de UPDF AI Solutions de UPDF AI
Solutions de UPDF AI Mode d'emploi d'IA
Mode d'emploi d'IA FAQ sur UPDF AI
FAQ sur UPDF AI Résumer le PDF
Résumer le PDF Traduire le PDF
Traduire le PDF Analyser le PDF
Analyser le PDF Discuter avec IA
Discuter avec IA Analyser l'image
Analyser l'image PDF vers carte mentale
PDF vers carte mentale Expliquer le PDF
Expliquer le PDF Outils IA PDF
Outils IA PDF Outils IA Image
Outils IA Image Outils de Chat IA
Outils de Chat IA Outils de Rédaction IA
Outils de Rédaction IA Outils d’Étude IA
Outils d’Étude IA Outils Professionnels IA
Outils Professionnels IA Autres Outils IA
Autres Outils IA Génération de signets IA
Génération de signets IA Résumé de signets IA
Résumé de signets IA Génération de filigranes IA
Génération de filigranes IA Génération d’arrière-plans IA
Génération d’arrière-plans IA Génération d’autocollants IA
Génération d’autocollants IA Génération de tampons IA
Génération de tampons IA Suite de rédaction IA
Suite de rédaction IA UPDF Copilot
UPDF Copilot Gestion des pages IA
Gestion des pages IA Recherche sémantique IA
Recherche sémantique IA PDF en Word
PDF en Word PDF en Excel
PDF en Excel PDF en PowerPoint
PDF en PowerPoint Mode d'emploi
Mode d'emploi Astuces UPDF
Astuces UPDF FAQ
FAQ Avis sur UPDF
Avis sur UPDF Centre de téléchargement
Centre de téléchargement Blog
Blog Actualités
Actualités Spécifications techniques
Spécifications techniques Mises à jour
Mises à jour UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
La reconnaissance optique de caractères (OCR) est une technologie très utile pour convertir des documents scannés/imprimés et des images en données modifiables et recherchables. L’OCR permet notamment d’analyser des documents numérisés, de modifier du texte existant, d’extraire des données pour la saisie d’informations, et bien plus encore.
Mistral OCR est une API récemment lancée par Mistral AI, offrant aux développeurs un outil avancé capable d’extraire du texte à partir de documents et d’images avec une grande précision. Dans ce guide complet, nous allons analyser Mistral OCR en détail : fonctionnalités, utilisation, avantages, inconvénients et performances.
Cependant, si vous recherchez une alternative plus simple à utiliser, sans codage, alors UPDF OCR constitue une excellente alternative à Mistral OCR. Installez UPDF pour tester son OCR en quelques clics, ou poursuivez votre lecture pour découvrir tout ce qu’il faut savoir sur Mistral OCR.
Windows • macOS • iOS • Android 100% sécurisé
Partie 1. Qu’est-ce que Mistral OCR ?
Mistral OCR est une API de reconnaissance optique de caractères récemment développée par Mistral AI. Elle utilise l’intelligence artificielle pour comprendre les documents et les images, puis extraire le texte avec une précision remarquable.
Mistral OCR est capable de reconnaître des mises en page complexes, de différencier les titres du contenu principal et d’interpréter avec précision les tableaux ainsi que les structures multi-colonnes. L’outil comprend l’ensemble des éléments d’un document, notamment le texte, les médias, les équations, les tableaux et bien plus encore. De plus, il préserve la mise en page et le formatage d’origine tout en transformant le fichier en document éditable.

The key capabilities of Mistral OCR include:
- Interprétation précise des documents complexes : l’outil excelle dans l’analyse d’éléments complexes tels que les images intégrées, les tableaux, les formules mathématiques, les mises en page LaTeX et bien plus encore.
- Préservation de la mise en page et du formatage : grâce à ses modèles IA avancés, Mistral OCR extrait intelligemment le texte tout en conservant la structure et la présentation du document.
- Traitement rapide : il peut traiter environ 2 000 pages par minute sur un seul nœud.
- Prise en charge multilingue : l’outil peut effectuer l’OCR sur des documents rédigés dans différentes langues et jeux de caractères.
- Option d’auto-hébergement : il propose une solution self-hosted permettant de conserver les informations sensibles ou confidentielles au sein de votre propre infrastructure.
- Intégration simplifiée : des bibliothèques clientes intégrées sont disponibles pour Python, TypeScript ainsi que des appels API directs via curl.
- Compatibilité avec divers formats : Mistral OCR fonctionne avec les PDF, les images et d’autres types de documents.
- Scalabilité : il est particulièrement adapté aux traitements massifs de documents à grande échelle.
Toutes ces fonctionnalités font de Mistral OCR une solution de nouvelle génération dédiée à l’intelligence documentaire, bien au-delà d’un simple outil OCR traditionnel.
Cas d’utilisation
Mistral OCR est utile dans de nombreux scénarios, notamment lorsqu’il est nécessaire d’effectuer un OCR de haute qualité afin d’extraire des données spécifiques. Parmi les cas d’utilisation les plus courants :
- Numérisation d’articles scientifiques : des instituts de recherche utilisent Mistral OCR pour digitaliser des articles et revues scientifiques et les rendre exploitables par l’IA.
- Préservation du patrimoine historique et culturel : des organisations et associations utilisent l’outil pour numériser des documents historiques et des archives culturelles.
- Création et structuration de documentation : des entreprises convertissent des documents techniques, notes de cours, plans d’ingénierie et autres contenus en formats exploitables pour la recherche et les réponses automatisées.
- Extraction et saisie de données : les entreprises utilisent Mistral OCR pour extraire des données structurées depuis des factures et autres documents afin d’automatiser la saisie d’informations.
En résumé, les cas d’utilisation de Mistral OCR sont pratiquement illimités pour les organisations de nombreux secteurs.stral OCR for organizations across industries.
Partie 2. Avantages et inconvénients de Mistral OCR
Mistral OCR semble être une solution OCR particulièrement performante pour le traitement de documents et d’images, mais examinons concrètement son fonctionnement et ses capacités.
Étape 1. Configuration de l’API Mistral OCR
La première étape consiste à configurer la clé API. Pour cela, rendez-vous sur la page des clés API de Mistral AI puis cliquez sur « Create new key ». Vous devrez attribuer un nom à la clé ainsi qu’une date d’expiration.
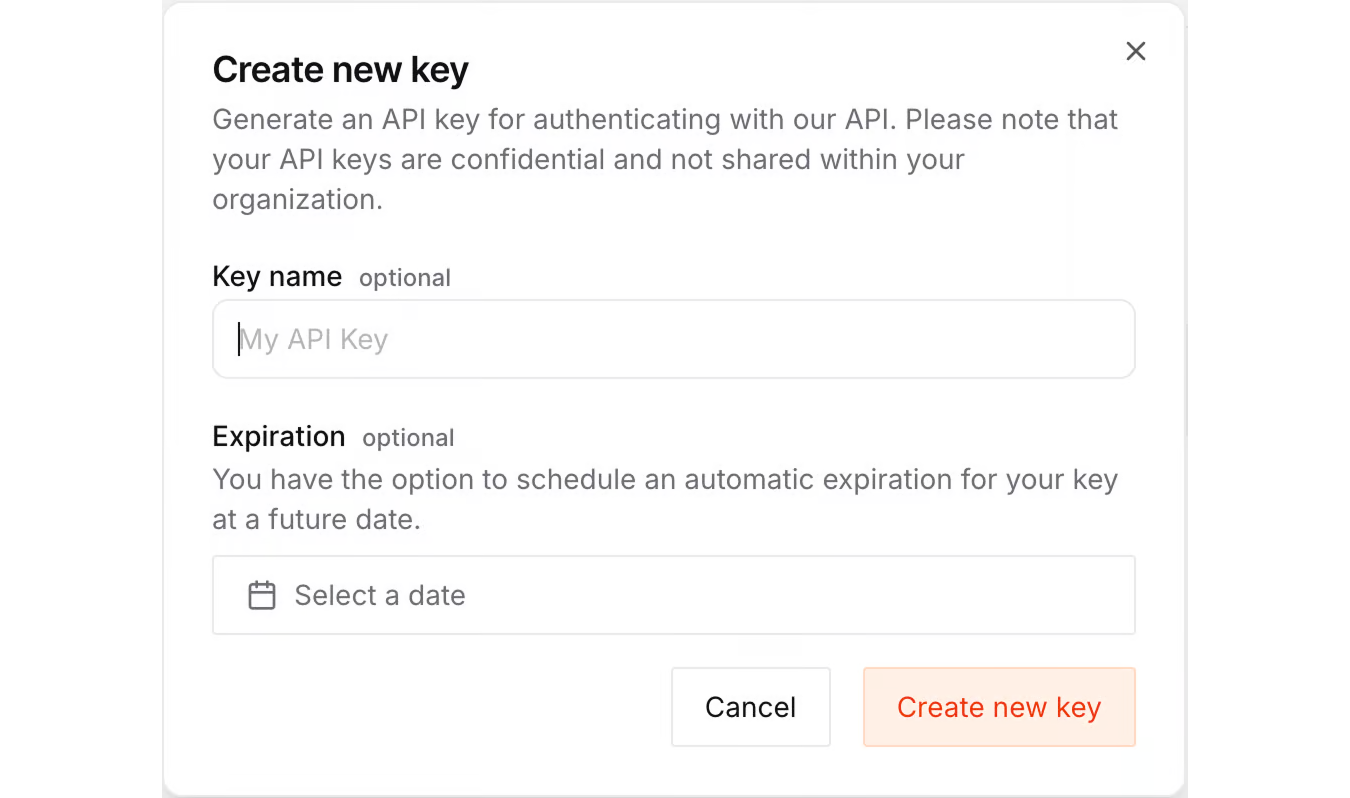
Après la création de la clé, copiez-la puis créez un fichier « .env » dans le même répertoire que votre script.
Le format doit ressembler à ceci :
MISTRAL_API_KEY=<your_api_key_here>
Étape 2. Configuration de l’environnement Python
Ensuite, vous devez installer les packages suivants pour utiliser l’API Mistral OCR avec Python :
- mistralai : client officiel permettant de communiquer avec l’API Mistral
- python-dotenv : charge les variables d’environnement depuis le fichier .env
- datauri : aide au traitement des images et à leur conversion dans un format compatible
Utilisez la commande suivante pour installer toutes les dépendances nécessaires :
pip install mistralai python-dotenv datauri
Une fois l’environnement configuré et la clé API ajoutée, vous êtes prêt à utiliser Mistral OCR.
Étape 3. Effectuer un OCR à partir d’une URL de document
Le code ci-dessous permet d’effectuer un OCR sur un document récupéré depuis une URL. Il commence par envoyer l’URL du document au moteur OCR.
import os
from mistralai import Mistral
class SimpleOCRAgent:
def __init__(self, api_key):
self.client = Mistral(api_key=api_key)
def process_document(self, document_url):
response = self.client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": document_url
},
include_image_base64=True
)
return response
if __name__ == "__main__":
api_key = os.environ.get("MISTRAL_API_KEY")
if not api_key:
raise ValueError("Please set the MISTRAL_API_KEY environment variable.")
agent = SimpleOCRAgent(api_key=api_key)
document_url = "https://arxiv.org/pdf/2201.04234" # Change as needed
result = agent.process_document(document_url)
print("OCR Result:")
print(result)Explication du fonctionnement
- Initialisation : le programme charge la clé API afin d’authentifier les requêtes auprès des services Mistral OCR.
- Traitement du document : la méthode
process_documentest utilisée pour soumettre l’URL du document au moteur OCR. - Résultat : la réponse renvoie des données OCR structurées au format Markdown, combinant le texte extrait et les métadonnées pour une lecture plus claire.
De cette manière, il est possible d’exécuter différents extraits de code afin d’utiliser Mistral OCR dans divers scénarios d’analyse documentaire.
Avantages
- Traitement rapide (environ 2 000 pages par minute)
- Gestion de formats complexes avec une excellente préservation de la mise en page
- Support multilingue
- Bonne scalabilité pour les traitements à grande échelle
Inconvénients
- Taille des documents limitée à 50 Mo, avec un maximum d’environ 1 000 pages
- Fonction OCR uniquement accessible via API
- Absence d’interface desktop native
- Nécessite une intégration technique
- Courbe d’apprentissage et compétences en programmation requises
Partie 3. Une alternative OCR plus accessible : UPDF
Mistral OCR est principalement destiné aux développeurs à l’aise avec les intégrations techniques. Cependant, si vous recherchez une solution simple, sans code et basée sur des clics, alors UPDF est une alternative idéale à Mistral OCR.
UPDF est un éditeur PDF avancé et un outil OCR qui propose une interface intuitive assistée par IA. Il permet de convertir facilement des PDF scannés, des documents papier et des images en fichiers éditables et recherchables. Quelques clics suffisent pour lancer l’OCR et extraire du texte dans plus de 38 langues.
Grâce à sa technologie avancée, UPDF garantit une précision pouvant atteindre 99 % tout en assurant un traitement rapide. Il conserve également la mise en page et le format d’origine du document.
Windows • macOS • iOS • Android 100% sécurisé

Fonctionnalités clés de l’OCR UPDF :
OCR précis
UPDF permet de traiter des documents complexes incluant graphiques, tableaux, équations et autres éléments. Le résultat est un texte éditable et recherchable tout en conservant la mise en page.
Paramètres OCR personnalisables
Vous pouvez ajuster la mise en page, la résolution, la plage de pages et bien plus encore. L’outil peut également détecter automatiquement plusieurs langues dans un même document.
Interface intuitive
UPDF propose une approche sans code, basée sur des clics. Ouvrez simplement votre document et lancez l’OCR en quelques étapes simples, sans apprentissage technique.
Compatibilité multiplateforme
L’OCR est disponible sur Windows, macOS et iOS.
Accès à de nombreuses autres fonctionnalités
UPDF ne se limite pas à l’OCR. Vous pouvez également l’utiliser pour modifier, annoter, convertir, compresser, organiser et signer vos PDF, ainsi que gérer de nombreuses autres tâches liées aux documents.
En plus, UPDF intègre un assistant IA capable d’analyser vos PDF : résumé automatique, traduction, discussion avec le document, génération de cartes mentales et bien plus encore.
Dans l’ensemble, UPDF est l’outil idéal pour réaliser un OCR de haute qualité sans effort tout en gérant efficacement l’ensemble de vos activités PDF.
Impressionné ? Découvrez ci-dessous les étapes simples pour effectuer un OCR avec UPDF :
Étape 1 : Installez et lancez UPDF sur Windows ou Mac. Glissez-déposez votre fichier PDF ou image dans l’interface principale.
Étape 2 : Ouvrez le fichier, cliquez sur « OCR » dans la section « Outils » du panneau droit. Ajustez les paramètres (mise en page, langue, résolution, etc.), puis cliquez sur « Convertir ».
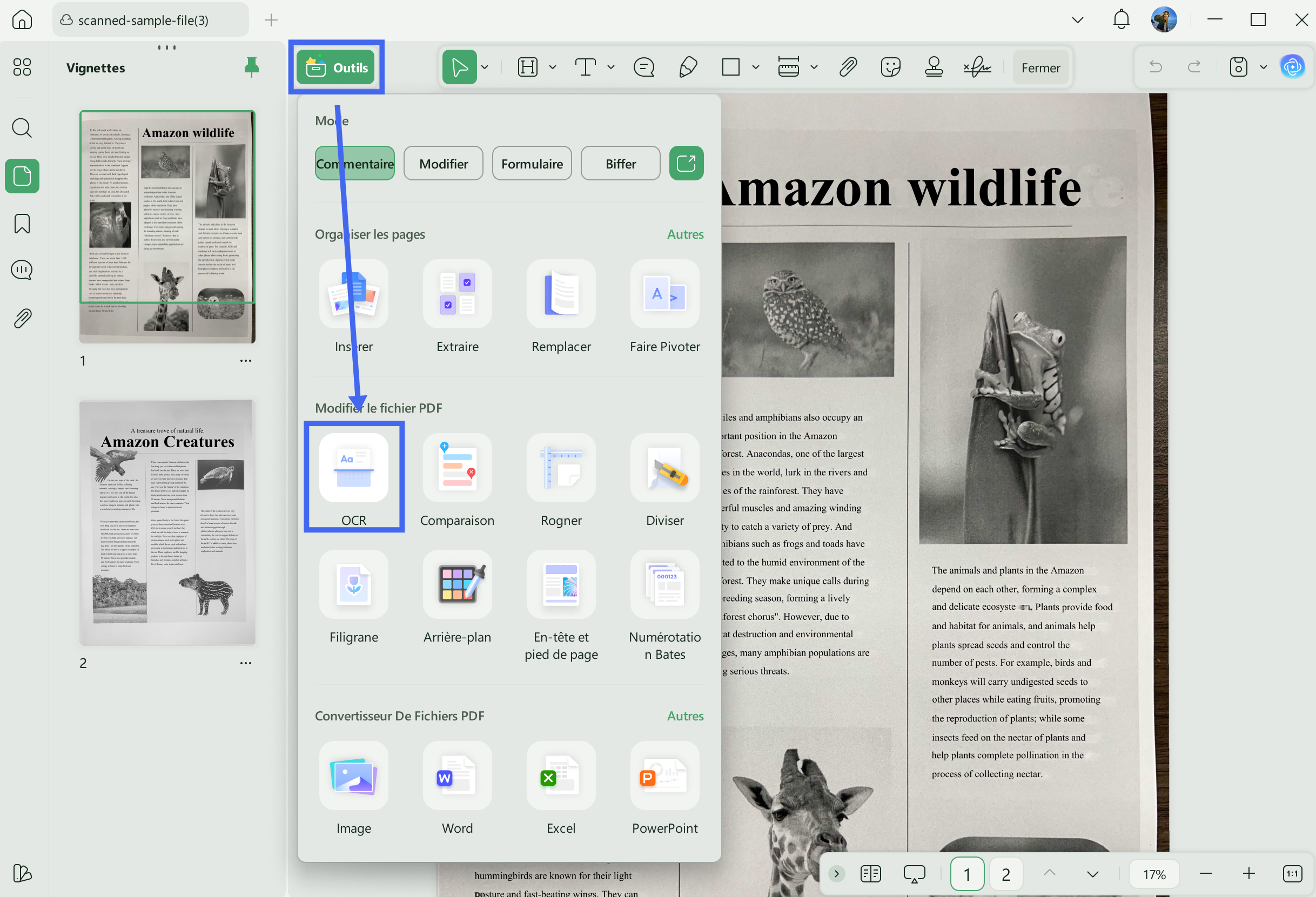
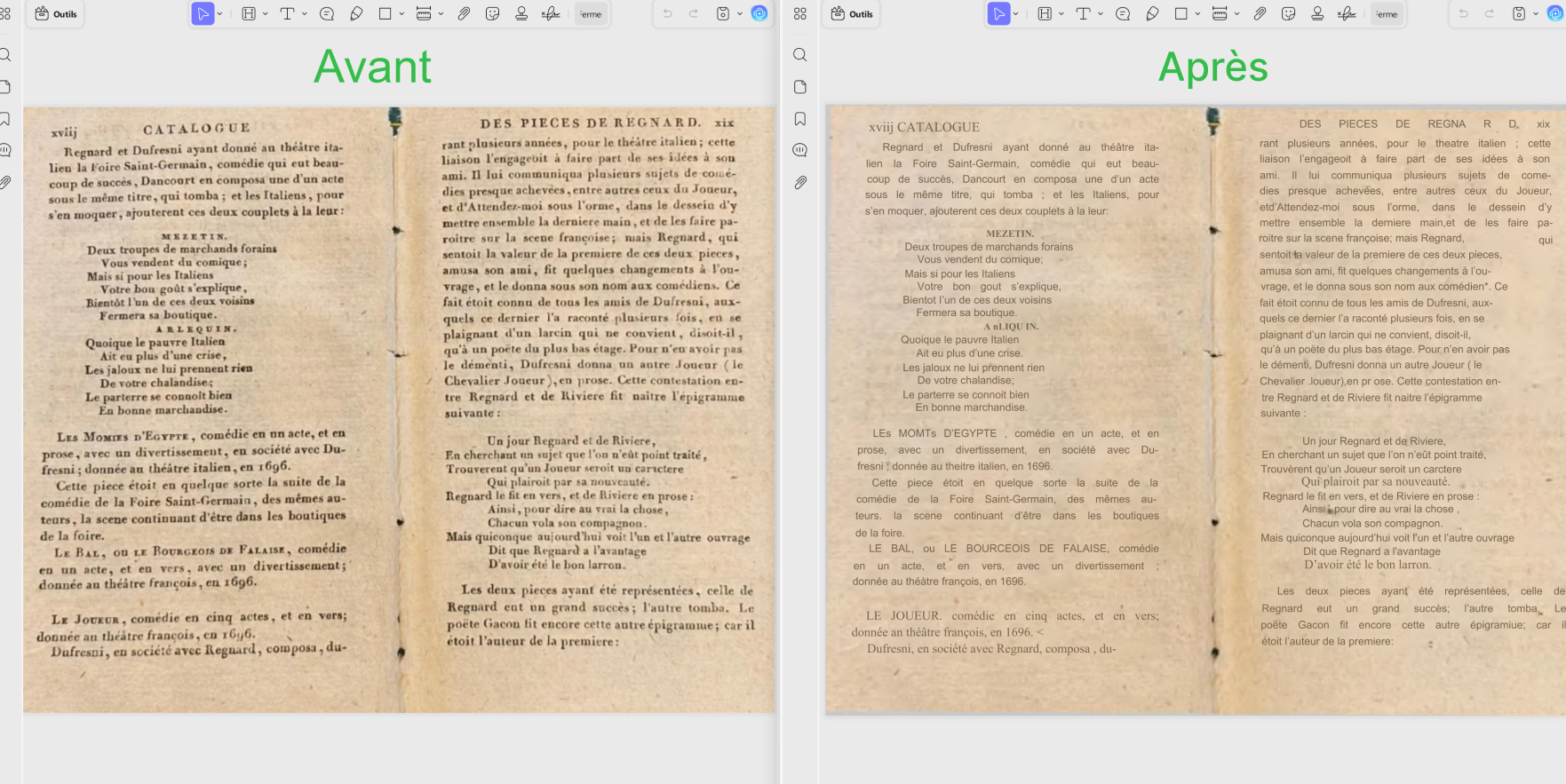
En quelques secondes, UPDF génère un nouveau fichier PDF contenant un texte éditable et recherchable, tout en conservant la mise en page d’origine.
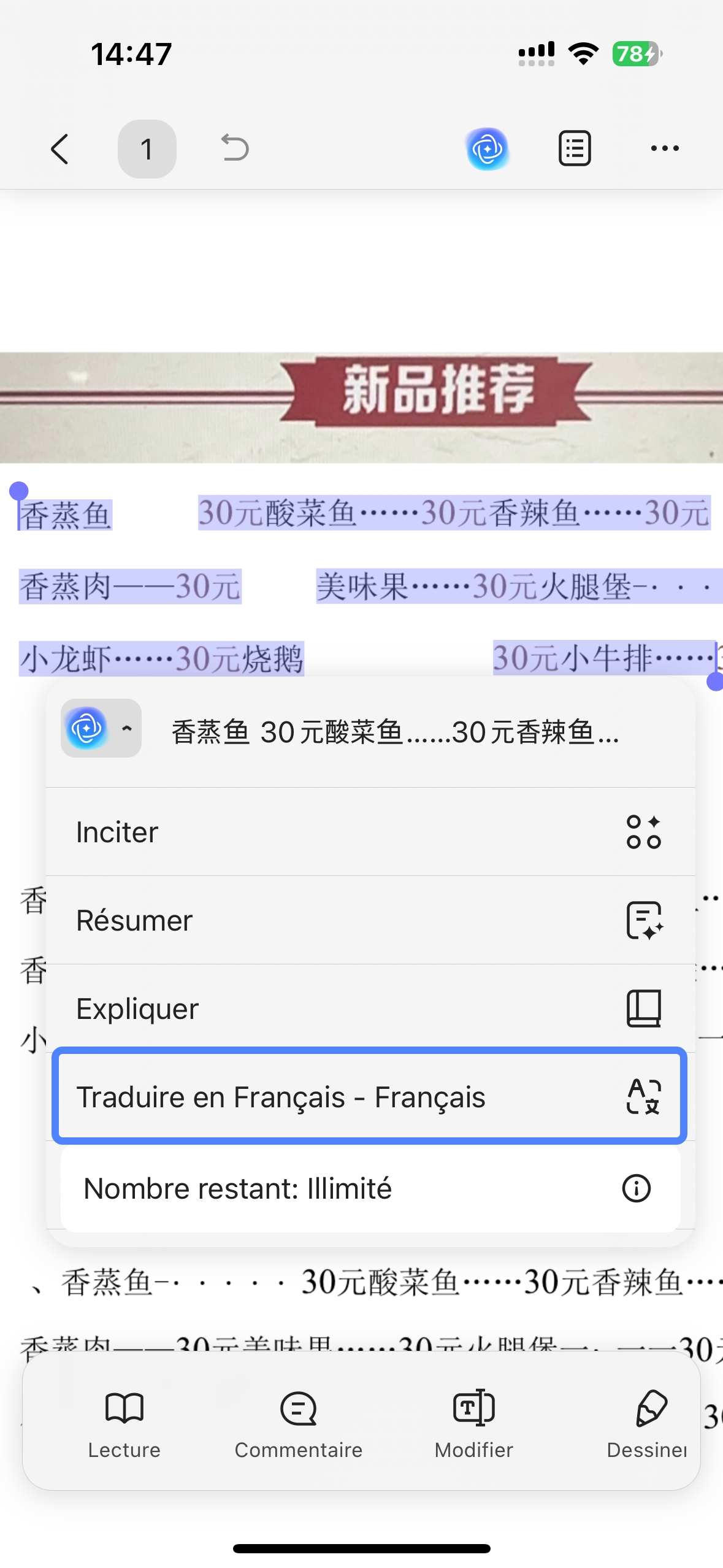
Par ailleurs, UPDF est également disponible sur iOS et Android, ce qui vous permet d’utiliser facilement la fonction OCR directement depuis votre smartphone.
C’est ainsi que vous pouvez réaliser un OCR rapidement grâce à l’approche simple et basée sur des clics d’UPDF. Cliquez sur le bouton de téléchargement ci-dessous pour essayer UPDF par vous-même.
Windows • macOS • iOS • Android 100% sécurisé
Conclusion
Mistral OCR s’impose comme une API OCR puissante capable de traiter des documents complexes. Sa rapidité et la précision de son extraction de texte ont séduit de nombreux développeurs pour divers cas d’usage. Cependant, l’absence d’interface graphique, la limitation de taille des documents et la courbe d’apprentissage élevée peuvent freiner son utilisation.
À l’inverse, UPDF offre des performances OCR similaires tout en proposant une expérience beaucoup plus intuitive. En plus, il intègre de nombreuses autres fonctionnalités liées aux PDF. Ainsi, la conclusion de cet avis sur Mistral OCR est claire : UPDF constitue une alternative plus simple et plus complète, évitant les contraintes techniques liées à l’intégration de Mistral OCR.







 Freddy Leroy
Freddy Leroy 

