 UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools KI-Lesezeichen-Generierung
KI-Lesezeichen-Generierung KI-Lesezeichen-Zusammenfassung
KI-Lesezeichen-Zusammenfassung KI-Wasserzeichen-Generierung
KI-Wasserzeichen-Generierung KI-Hintergrund-Generierung
KI-Hintergrund-Generierung KI-Sticker-Generierung
KI-Sticker-Generierung KI-Stempel-Generierung
KI-Stempel-Generierung KI-Schreibtools
KI-Schreibtools UPDF Copilot
UPDF Copilot KI-Seitenverwaltung
KI-Seitenverwaltung KI-Semantische Suche
KI-Semantische Suche PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Wie wandelst du eine gescannte PDF-Datei in Word-Format um, damit sie mit Microsoft-Software bearbeitet werden kann? Die Umwandlung einer nicht bearbeitbaren PDF-Datei erfordert ein spezielles Verfahren namens OCR oder optische Zeichenerkennung. Sobald du dein Dokument mit OCR verarbeitet hast, kannst du gescannte PDF in Word umwandeln. Hierfür gibt es verschiedene Möglichkeiten, doch in diesem Artikel stellen wir auf die effektivsten und praktischsten Wege vor, um gescannte PDF-Datei auf Windows und Mac in Word umzuwandeln.
Teil 1: Was ist eine gescannte PDF-Datei?
Ein PDF-Dokument kann durch das Einscannen eines Papierdokuments in eine elektronische Version erstellt werden. Dazu nimmst du einen Scanner oder ein ähnliches Gerät, das ein Bild eines Papierdokuments erfassen und es als elektronische PDF-Datei speichern kann. Wenn ein Scanner dieses gescannte Bild erstellt, bildet er jedoch nicht jedes Zeichen eines jeden Wortes ab. Er macht lediglich einen „Schnappschuss“ des Papierdokuments. Die mit dem Scanner gelieferte Software wandelt das Foto dann in ein PDF-Dokument um - sprich in ein „gescanntes“ PDF-Dokument.
Der Inhalt eines gescannten PDFs kann leider nicht durchsucht oder verändert werden. Um jedes Zeichen auf einer PDF-Seite elektronisch zu erkennen und es dann in ein bearbeitbares Format umzuwandeln, ist eine sogenannte OCR-Software notwendig. Ganz kurz und knapp gefasst erkennt und extrahiert diese OCR-Software den Text aus dem Bild-PDF.
Teil 2: PDFs in Word umwandeln - Der beste Konverter
UPDF unterstützt über 38 Sprachen, ist definitiv eine der vielseitigsten und leistungsstärksten OCR-Softwares für Windows und Mac. Denke daran: Die Umwandlung eines gescannten Dokuments mit OCR erfordert ein hohes Maß an Genauigkeit. UPDF hat eine leistungsstarke OCR-Funktion, um Bild zu scannen, wonach das resultierende PDF-Dokument dasselbe Layout und dieselbe Formatierung des Originaldokuments aufweist.
Windows • macOS • iOS • Android 100% sicher
Sehen wir uns kurz einige der wichtigsten Funktionen von UPDF an und wie du dieses umfassende PDF-Konvertierungstool von Superace nutzen kannst.
Funktionen für die Umwandlung
- Spezielles PDF-Umwandlungs-Tool, das viele gängige Ausgabeformate wie Word, Excel, PPT, Bildformate, HTML, XML, Text und RTF unterstützt.
- OCR-Funktion, um gescannte PDFs in ein bearbeitbares Word-Format umzuwandeln.
- Das Format wird bei der Konvertierung konsistent gehalten - es sind nur minimale manuelle Korrekturen erforderlich.
Teil 3: Wie du gescannte PDF in bearbeitbare Word-Datei umwandeln kannst
Willst du ein gescanntes PDF in Word umwandeln, damit du es überall verwenden und leicht bearbeiten kannst? Anstatt den Text mühsam abzutippen, kannst du ihn stattdessen mit dem OCR-Tool von UPDF ganz einfach in ein bearbeitbares Word-Dokument umwandeln. Das macht UPDF zu einer hervorragenden Option, um die Textdaten deines Dokuments zu erhalten. Wie das geht, erfährst du in den unten aufgeführten Schritten:
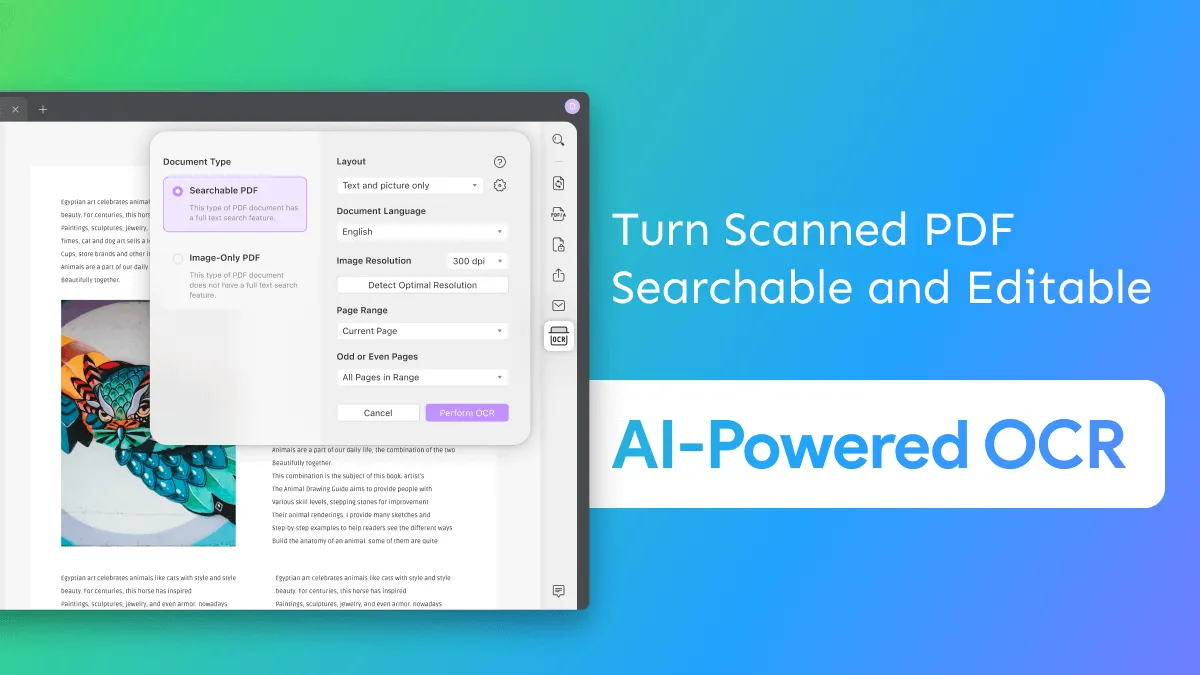
Schritt 1: OCR-Dokumententyp definieren
Gehe nach dem Öffnen der PDF-Datei auf die Schaltfläche „Text mit OCR erkennen“ auf der rechten Seite. Wähle im Abschnitt „Dokumenttyp“ die Option „Durchsuchbares PDF“ und fahre mit dem Prozess fort.
Schritt 2: Die Layout-Einstellungen festlegen
Der erste Parameter für das OCR-Tool sind die „Layout“-Einstellungen. Es stehen dir drei Stück zur Verfügung, die wie folgt lauten:
- Nur Text und Bilder: Bei dieser Layout-Einstellung werden der gesamte Text und die Bilder in einem PDF-Dokument gespeichert. Die Datei, die erstellt wird, ist kleiner als das Original und hat keine besondere Formatierung.
- Text über dem Seitenbild: Dieser Modus ist das Standardlayout, das während des OCR-PDF-Prozesses eingestellt wird, und enthält die Bilder und Illustrationen entsprechend der Originaldatei. Diese Dateien sind zwar groß, unterscheiden sich aber nicht so sehr vom ursprünglichen PDF-Dokument.
- Text unter dem Seitenbild: In diesem Modus bleibt die gesamte Bildstruktur des ursprünglichen PDF-Dokuments erhalten. Der Text befindet sich unter der Bildebene des Dokuments, kann also nicht bearbeitet werden, ist aber durchsuchbar.
Wenn du fertig bist, gehst du zum Abschnitt „Dokumentsprache“, wo du die Sprache auswählen musst, die erkannt werden soll. Du kannst eine beliebige Sprache aus den 38 Optionen im Menü auswählen.
Gehe weiter zum Abschnitt „Bildauflösung“ und stelle den gewünschten Wert ein, indem du dir einen im Menü verfügbaren Wert aussuchst. Wenn du dir nicht sicher bist, kannst du auf die Schaltfläche „Optimale Auflösung erkennen“ klicken und fortfahren.
Schritt 3: Gescannte PDFs in bearbeitbares Word umwandeln
Als Nächstes gibst du den Seitenbereich an, in dem du die Funktion ausführen möchtest, und klickst auf „OCR durchführen“. Lege den gewünschten Speicherort für das umgewandelte Dokument fest, damit es in bearbeitbaren Text umgewandelt werden kann.
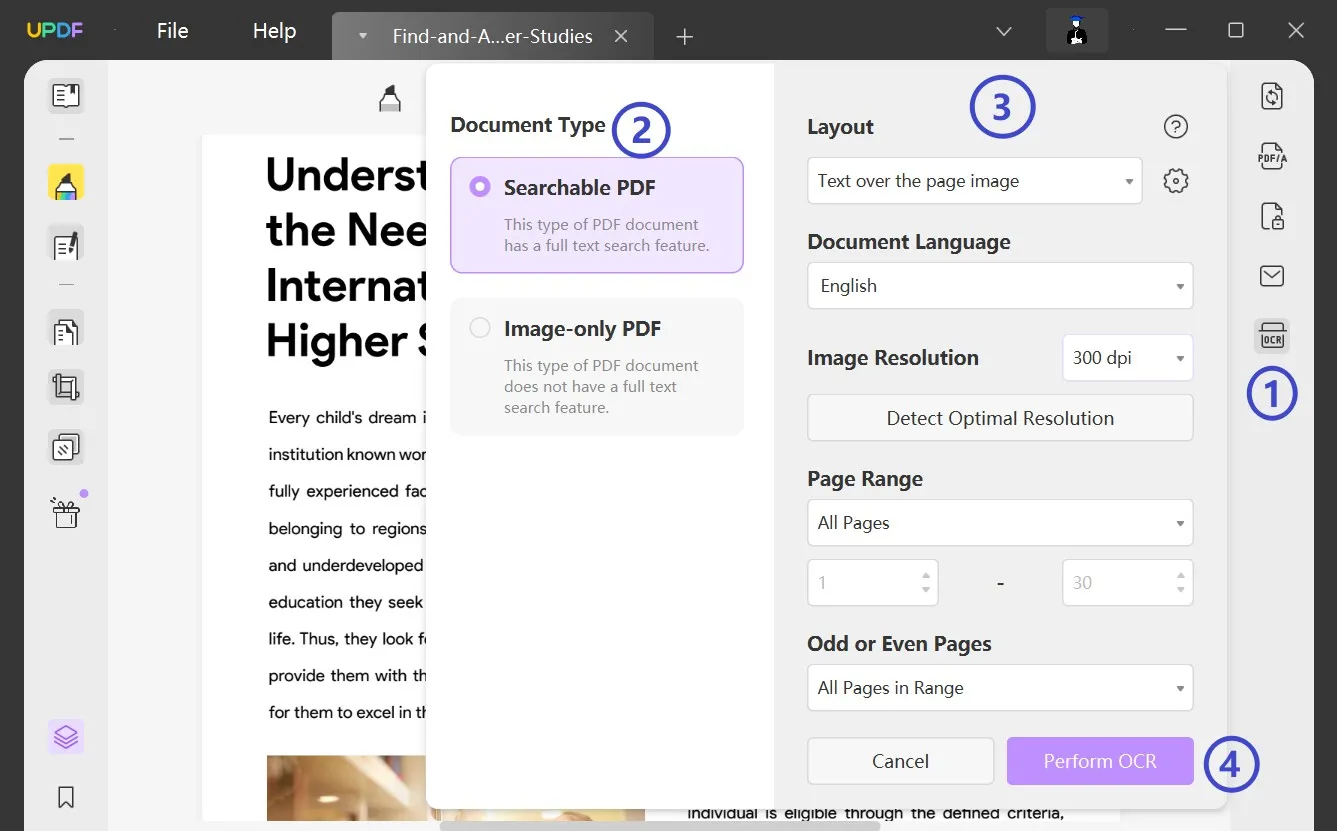
Du kannst die PDF-Datei jetzt bearbeiten. Wenn du es aber in das Word-Format umwandeln möchtest, kannst du die UPDF Export PDF-Funktion verwenden, um PDF in das Word-Format zu konvertieren. Hier sind die Schritten:
- Öffne die PDF-Datei in UPDF und klicke auf „PDF exportieren“ in der rechten Symbolleiste.
- Wähle das Format „Word“ und klicke dann im Pop-up-Fenster auf „Exportieren“.
- Benenne die Datei und speichere sie in dem Ordner auf deinen Geräten.
Einige Schriftarten werden möglicherweise nicht genau umgewandelt, vor allem wenn deine gescannte Datei Handschrift enthält, aber der Inhalt wird der gescannten Kopie so nahe wie möglich kommen.
Video-Tutorial
Fazit
Anhand der obigen Ausführungen zur Umwandlung von gescannten PDFs in Word kannst du erkennen, dass UPDF der beste Konverter ist. Er ist erschwinglich, genau, engagiert, vielseitig und darüber hinaus für Windows-, Mac-, iOS- und Android-Systeme verfügbar. Außerdem kannst du PDFs in verschiedene andere Formate umwandeln, damit die Dateien in den jeweiligen Anwendungen bearbeitet werden können. Probiere es aus, schließe dich dem UPDF-Team an und nutze ein Tool, auf das sich bereits tausende Nutzer bei ihrem täglichen Dokumenten-Workflow verlassen!
Windows • macOS • iOS • Android 100% sicher






 Enrica Taylor
Enrica Taylor 
 Delia Meyer
Delia Meyer 

