 UPDF pour Windows
UPDF pour Windows UPDF pour Mac
UPDF pour Mac UPDF pour iPhone/iPad
UPDF pour iPhone/iPad updf android
updf android Nomostar
Nomostar UPDF AI en ligne
UPDF AI en ligne UPDF Sign
UPDF Sign IvyCraft
IvyCraft Modifier le PDF
Modifier le PDF Annoter le PDF
Annoter le PDF Créer un PDF
Créer un PDF Formulaire PDF
Formulaire PDF Modifier les liens
Modifier les liens Convertir le PDF
Convertir le PDF OCR
OCR PDF en Word
PDF en Word PDF en Image
PDF en Image PDF en Excel
PDF en Excel Organiser les pages PDF
Organiser les pages PDF Fusionner les PDF
Fusionner les PDF Diviser le PDF
Diviser le PDF Rogner le PDF
Rogner le PDF Pivoter le PDF
Pivoter le PDF Protéger le PDF
Protéger le PDF Signer le PDF
Signer le PDF Rédiger le PDF
Rédiger le PDF Biffer le PDF
Biffer le PDF Supprimer la sécurité
Supprimer la sécurité Lire le PDF
Lire le PDF UPDF Cloud
UPDF Cloud Compresser le PDF
Compresser le PDF Imprimer le PDF
Imprimer le PDF Traiter par lots
Traiter par lots À propos de UPDF AI
À propos de UPDF AI Solutions de UPDF AI
Solutions de UPDF AI Mode d'emploi d'IA
Mode d'emploi d'IA FAQ sur UPDF AI
FAQ sur UPDF AI Résumer le PDF
Résumer le PDF Traduire le PDF
Traduire le PDF Analyser le PDF
Analyser le PDF Discuter avec IA
Discuter avec IA Analyser l'image
Analyser l'image PDF vers carte mentale
PDF vers carte mentale Expliquer le PDF
Expliquer le PDF Outils IA PDF
Outils IA PDF Outils IA Image
Outils IA Image Outils de Chat IA
Outils de Chat IA Outils de Rédaction IA
Outils de Rédaction IA Outils d’Étude IA
Outils d’Étude IA Outils Professionnels IA
Outils Professionnels IA Autres Outils IA
Autres Outils IA Génération de signets IA
Génération de signets IA Résumé de signets IA
Résumé de signets IA Génération de filigranes IA
Génération de filigranes IA Génération d’arrière-plans IA
Génération d’arrière-plans IA Génération d’autocollants IA
Génération d’autocollants IA Génération de tampons IA
Génération de tampons IA Suite de rédaction IA
Suite de rédaction IA UPDF Copilot
UPDF Copilot Gestion des pages IA
Gestion des pages IA Recherche sémantique IA
Recherche sémantique IA PDF en Word
PDF en Word PDF en Excel
PDF en Excel PDF en PowerPoint
PDF en PowerPoint Mode d'emploi
Mode d'emploi Astuces UPDF
Astuces UPDF FAQ
FAQ Avis sur UPDF
Avis sur UPDF Centre de téléchargement
Centre de téléchargement Blog
Blog Actualités
Actualités Spécifications techniques
Spécifications techniques Mises à jour
Mises à jour UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Le format PDF est devenu le format le plus adopté par les entreprises. Comme la plupart des données importantes des entreprises sont enregistrées dans des fichiers PDF, il est souvent nécessaire d'extraire du texte du PDF.
Cependant, il se peut que vous ayez du mal à le faire car la copie, l'extraction et l'édition de textes sur les PDF ne sont pas possibles sans les méthodes et les outils appropriés, en particulier si vos fichiers PDF sont numérisés ou créés à partir d'images.
Certains d'entre vous savent peut-être qu'il est possible d'extraire du texte d'un fichier PDF à l'aide de l'OCR. Mais qu'en est-il si vous ne souhaitez pas utiliser l'OCR? Existe-t-il des méthodes? Certainement oui!
Pour vous faciliter la tâche, cet article vous fournira des solutions pour récupérer des textes de fichiers PDF avec et sans l'utilisation de l'OCR. Poursuivre la lecture.
Extraction du texte d'un PDF avec OCR (3 façons)
Si les fichiers PDF sont créés par OCR, la méthode couramment utilisée pour extraire du texte d'un PDF consiste à utiliser un éditeur de PDF avec l'outil OCR. Ici, nous utiliserons UPDF pour vous montrer comment extraire du texte à partir de PDF numérisés ou d'images.
UPDF est un éditeur de PDF innovant qui offre une solution tout-en-un pour les fichiers PDF. Outre l'extraction de texte à partir de PDF, UPDF dispose de nombreuses autres fonctionnalités telles que l'édition, la conversion, la fusion, l'annotation, etc.
De plus, UPDF est disponible sur Mac, Windows, iOS et Android et supporte une licence unique pour toutes les plateformes, ce qui en fait une solution idéale pour les utilisateurs de différents systèmes d'exploitation. Voici l'accès à UPDF et on voit ensemble comment extraire du texte d'un PDF avec la fonction d'OCR d'UPDF.
Windows • macOS • iOS • Android 100% sécurisé

Méthode 1: Comment extraire du texte d'un PDF numérisé ou d'une image
Si vous souhaitez extraire du texte à partir d'images ou de PDF numérisés, vous pouvez utiliser UPDF car il dispose de la fonction OCR dédiée qui peut vous aider à transformer des documents PDF numérisés en texte éditable et extractible. Vous pouvez suivre les étapes indiquées ci-dessous:
Étape 1: Traitez la mise en page d'OCR
Vous pouvez commencer par ouvrir le PDF sur UPDF et cliquer sur le bouton "OCR" sur la droite.
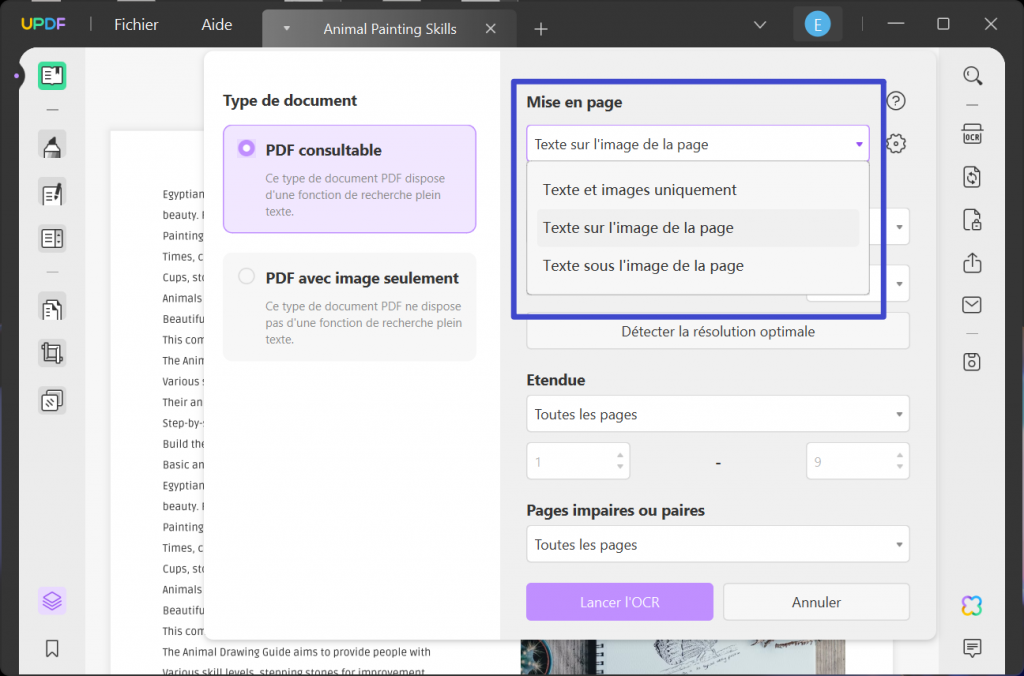
Dans la fenêtre qui s'ouvre, sélectionnez "PDF Consultable", puis spécifiez la mise en page dans les paramètres "Mise en Page". Sélectionnez "Texte et images uniquement", "Textes sur l'image de la page" ou "Textes sous l'image de la page" et sélectionnez l'icône "Étendue" et modifiez les options, si nécessaire.
Étape 2: Paramètres de langue et d'image
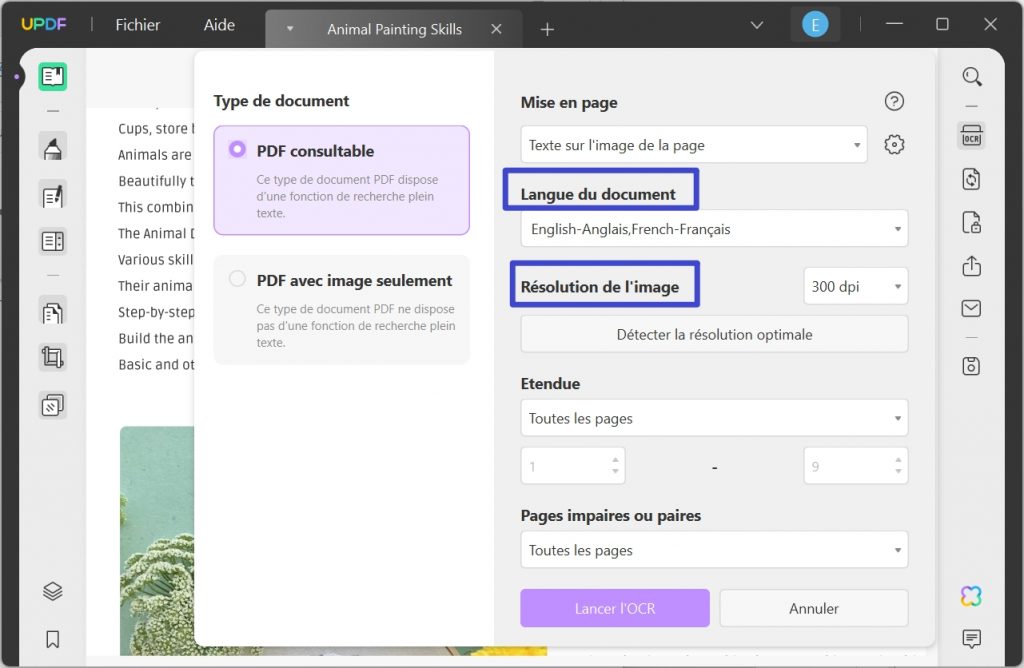
Sélectionnez la langue du document dans la liste des 38 langues disponibles. Ensuite, travaillez sur les paramètres de "Résolution de L'Image" et définissez une valeur particulière à partir de la liste fournie. En cas de doute, cliquez sur le bouton "Détecter la résolution optimale" et continuez.
Étape 3: Lancez l'OCR
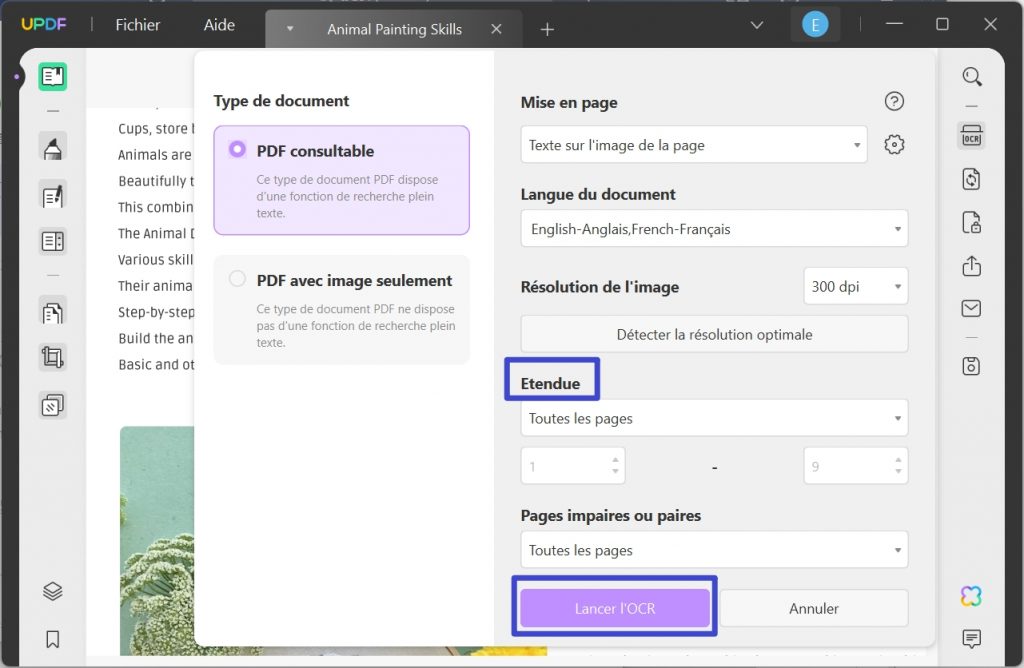
Sélectionnez l'étendue de page sur laquelle vous souhaitez exécuter l'outil d'OCR. Ensuite, sélectionnez le bouton "Lancer L'OCR". Une fois le processus terminé, quand il s'ouvre sur UPDF, où vous pouvez extraire le texte du PDF.
Étape 4: Extrayez ou copiez le texte du PDF
Vous pouvez maintenant cliquer et sélectionner le texte que vous souhaitez récupérer du PDF, puis le copier et le coller à la destination de votre choix. Téléchargez UPDF et essayez-le maintenant!
Windows • macOS • iOS • Android 100% sécurisé
Méthode 2: Comment extraire tout le texte d'un PDF numérisé/image vers Excel/Word/tout autre format
La méthode ci-dessus convient si vous avez besoin de copier le texte d'une partie du PDF. Cela prendra beaucoup de temps si vous avez besoin d'extraire tout le texte du PDF. Il existe un moyen rapide avec UPDF et vous trouverez ici la marche à suivre.
Étape 1: Ouvrez le PDF sur UPDF
Lancez UPDF sur votre ordinateur, cliquez sur "Ouvrir Un Fichier" et sélectionnez le PDF sur votre ordinateur pour l'ouvrir.
Étape 2: Convertissez le PDF en Excel/Word/N'importe quel format
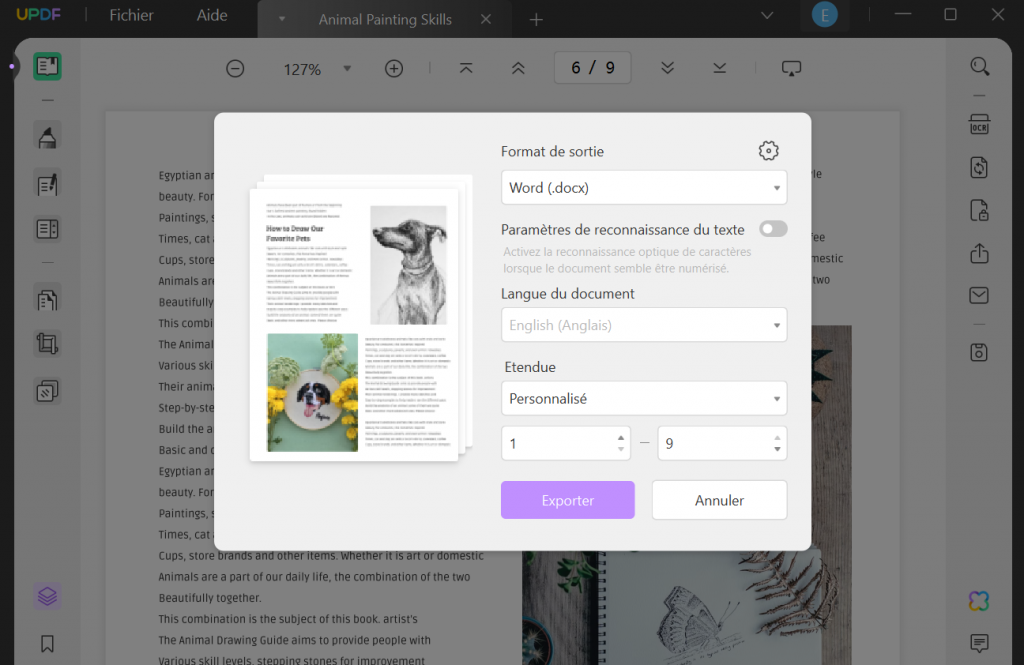
Naviguez jusqu'à "Exporter" dans le menu de droite et cliquez dessus. Sélectionnez le format souhaité. Par exemple, sélectionnez "Word", activez l'option "Paramètres de reconnaissance du texte", choisissez la langue du document et personnalisez l'étendue de pages. Lorsque tout est terminé, cliquez sur le bouton "Exporter" et sélectionnez l'emplacement où vous souhaitez enregistrer les fichiers convertis. Une fois le processus terminé, vous avez réussi à extraire tout le texte d'un PDF numérisé/imagé vers Excel, Word ou tout autre format dont vous avez besoin. Vous pouvez ouvrir le fichier modifiable sur votre ordinateur et effectuer toutes les opérations nécessaires.
Méthode 3: Comment extraire par lots du texte à partir d'un PDF numérisé ou d'une image
Nous avons expliqué tout à l'heure les méthodes de l'extraction du texte à partir d'un seul fichier. Mais comment faire si on aimerait extraire du texte à partir de plusieurs fichiers PDF? Ne vous inquiétez pas, nous allons également vous aider ici.
Étape 1: Lancez UPDF
Double-cliquez sur l'icône UPDF sur votre ordinateur pour le lancer. Si vous ne l'avez pas encore téléchargé, cliquez le bouton ci-dessous.
Windows • macOS • iOS • Android 100% sécurisé
Étape 2: Extrayez par lots le texte de plusieurs fichiers PDF
Cliquez sur l'icône "Batch" > "Convertir". Dans la nouvelle fenêtre, sélectionnez le format de sortie, basculez sur "Paramètres de Reconnaissance du Texte", modifiez d'autres paramètres, cliquez sur "Appliquer", sélectionnez l'emplacement de stockage, et cliquez sur "Enregistrer" pour exécuter le processus. Une fois le processus terminé, vous pouvez trouver les fichiers PDF modifiables dans l'emplacement de la fenêtre contextuelle.

C'est très facile, n'est-ce pas? Essayez-le maintenant!
Windows • macOS • iOS • Android 100% sécurisé
Extraction du texte d'un PDF sans OCR (3 façons)
L'OCR est un excellent moyen d'extraire du texte des PDF. Cependant, il se peut que vous ayez un PDF normal et que vous souhaitiez en extraire du texte sans utiliser la fonction de l'OCR. Ne vous inquiétez pas, voici trois méthodes efficaces pour vous.
Méthode 1: Extraire du texte d'un fichier PDF à l'aide d'UPDF
Si vous utilisez un fichier PDF normal plutôt que ceux créés par des scanners ou des images, vous pouvez utiliser les fonctionnalités d'édition UPDF pour extraire du texte du PDF. Voici comment procéder.
Étape 1: Passez en mode de modification
La première étape consiste à ouvrir un fichier PDF dans UPDF à partir duquel vous souhaitez extraire du texte. Pour ce faire, cliquez sur le bouton "Ouvrir Un Fichier" au centre de l'interface UPDF.
Après avoir importé le fichier PDF dans UPDF, accédez à la barre d'outils et cliquez sur l'onglet "Modifier" pour appliquer le mode d'édition à votre fichier.
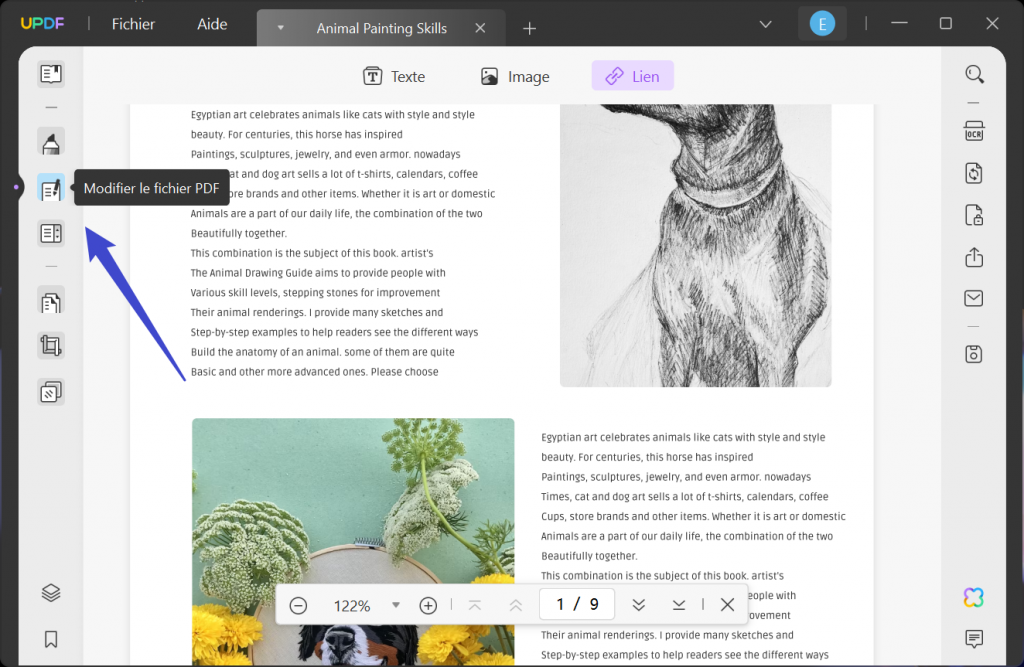
Étape 2: Extrayez les mots du PDF
Cliquez l'icône Texte du haut et sélectionnez le texte que vous souhaitez extraire d'un PDF en cliquant dessus avec le bouton droit de la souris et poursuivez en cliquant sur l'option "Copier" ou en utilisant le raccourci "Ctrl + C". Après avoir copié le texte, vous pouvez le coller dans un fichier Word ou dans d'autres formats de fichier.
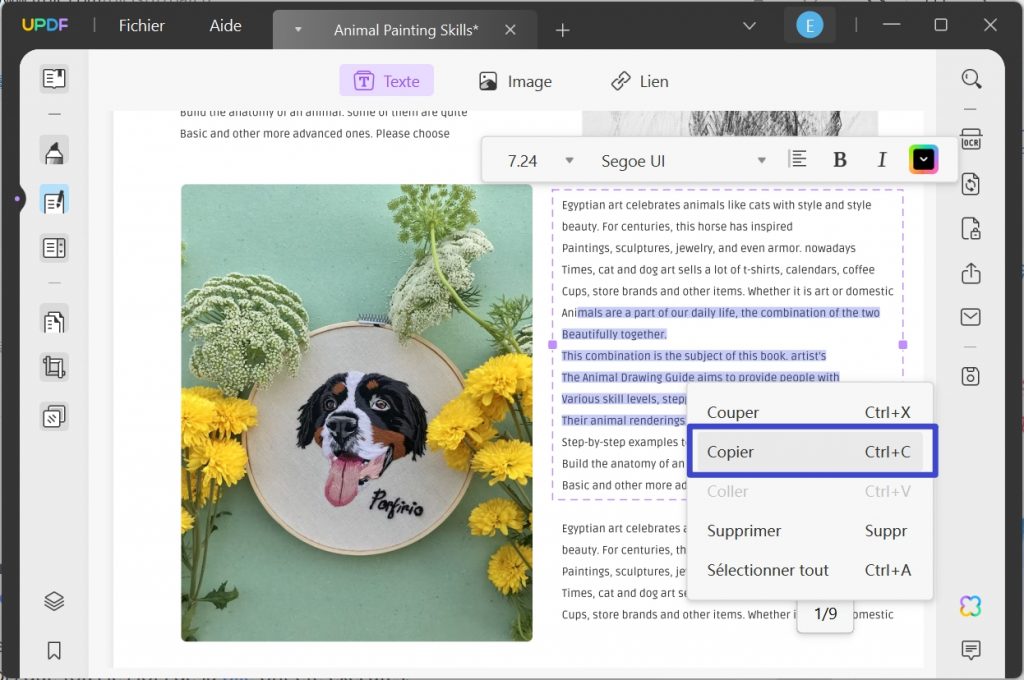
Téléchargez-le et essayez-le dès aujourd'hui!
Windows • macOS • iOS • Android 100% sécurisé
Méthode 2: Extraire du texte d'un PDF en ligne à l'aide de Google Drive
Si vous souhaitez extraire du texte d'un PDF numérisé sans OCR, vous devriez essayer Google Drive.
Les utilisateurs peuvent facilement extraire du texte et d'autres éléments d'un PDF sans télécharger ni installer de logiciel. Il s'agit d'une méthode simple, pratique et fiable par rapport à d'autres méthodes d'extraction de texte à partir de fichiers PDF. Voici les étapes à suivre pour extraire des informations d'un fichier PDF en ligne à l'aide de la méthode Google Drive:
Étape 1: Accédez à Google Drive dans votre navigateur Internet et cliquez sur l'onglet "Nouveau". Ensuite, cliquez sur "Téléchargement de fichier" dans le menu déroulant pour parcourir le fichier PDF depuis votre ordinateur et le télécharger sur Google Drive.
Étape 2: Dès que le fichier PDF est téléchargé, il s'affiche sur My Drive. Cliquez avec le bouton droit de la souris sur le fichier PDF téléchargé, appuyez sur "Ouvrir avec", puis choisissez "Google Documents" pour ouvrir le PDF dans Google Documents.
Étape 3: Après avoir ouvert le fichier PDF dans Google Documents, le texte du fichier PDF devient automatiquement modifiable et vous pouvez facilement extraire du texte du PDF en ligne gratuitement.
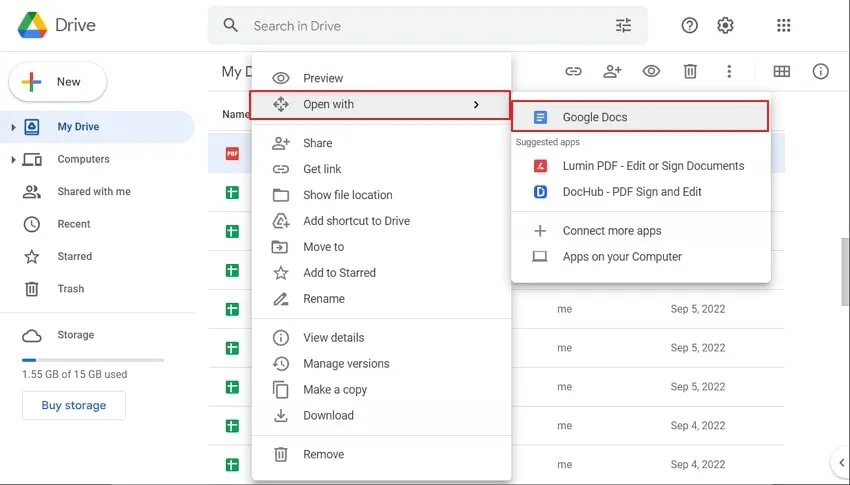
Méthode 3: Extraire du texte d'un PDF à l'aide de Python
Qui aurait pensé que Python pouvait aussi être une source pour extraire du texte d'un PDF? Si vous êtes sur votre ordinateur et que vous utilisez fréquemment Python, vous pouvez utiliser PyPDF2 pour exécuter cette tâche. Vous devez suivre le script fourni ci-dessous pour en savoir plus sur cette méthode:
from PyPDF2 import PdfReader
reader = PdfReader("example.pdf")
page = reader.pagers[0]
text = page.extract_text()
print(text)
FAQ sur l'extraction du texte d'un PDF
1. Puis-je extraire du texte d'une image PDF?
Oui, vous pouvez extraire du texte d'une image PDF en utilisant la fonction OCR offerte par UPDF. Importez l'image PDF dans UPDF et cliquez sur l'icône "OCR" dans le panneau droit de la fenêtre UPDF. Après avoir réglé tous les paramètres, sélectionnez l'option "Lancer L'OCR" pour lancer le processus de conversion de l'image PDF en PDF éditable et consultable. Vous pouvez extraire du texte dans les PDF OCR dès que la conversion est terminée.
2. Comment extraire du texte d'un PDF sans Acrobat?
Vous pouvez extraire du texte d'un PDF en utilisant UPDF au lieu d'Adobe Acrobat car il s'agit d'une solution plus fiable, plus puissante et plus compatible avec Mac, Windows, Android et iOS.
3. Puis-je extraire du texte d'un PDF sous Linux?
Oui, vous pouvez extraire le contenu d'un PDF sous Linux en utilisant différents outils en ligne disponibles sur le marché, tels que la méthode Google Drive ou la fonction OCR de PDF24 Tools sur votre système d'exploitation Linux.
Conclusion
Bien qu'il existe de nombreuses options disponibles sur le marché pour extraire du texte d'un PDF avec ou sans OCR, le choix le plus sage et le plus fiable est d'utiliser un outil dédié et réputé pour les fichiers PDF. À cet égard, UPDF est le meilleur choix car, en plus d'accomplir la tâche avec efficacité et précision, il permet de sécuriser vos données, d'éditer des PDF, de les convertir et bien plus encore. Téléchargez UPDF dès aujourd'hui et profitez d'une expérience utilisateur satisfaisante.
Windows • macOS • iOS • Android 100% sécurisé







 Freddy Leroy
Freddy Leroy 


