 UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools KI-Lesezeichen-Generierung
KI-Lesezeichen-Generierung KI-Lesezeichen-Zusammenfassung
KI-Lesezeichen-Zusammenfassung KI-Wasserzeichen-Generierung
KI-Wasserzeichen-Generierung KI-Hintergrund-Generierung
KI-Hintergrund-Generierung KI-Sticker-Generierung
KI-Sticker-Generierung KI-Stempel-Generierung
KI-Stempel-Generierung KI-Schreibtools
KI-Schreibtools UPDF Copilot
UPDF Copilot KI-Seitenverwaltung
KI-Seitenverwaltung KI-Semantische Suche
KI-Semantische Suche PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
OCR-PDF mit UPDF auf dem Mac
Mit der OCR-Funktion von UPDF für Mac können Sie gescannte oder reine Bild-PDF-Dokumente in durchsuchbare und bearbeitbare Dokumente konvertieren. Darüber hinaus können Sie Ihre durchsuchbaren und bearbeitbaren PDF-Dateien in reine Bilddateien umwandeln. Klicken Sie auf die Schaltfläche unten, um UPDF auf Ihren Mac herunterzuladen. Folgen Sie den unten stehenden Schritten, um die Anwendung zu erlernen.
Videoanleitung
Jetzt führen wir Sie durch die Verwendung der UPDF OCR-Funktion auf dem Mac.
Windows • macOS • iOS • Android 100% sicher
Schritt 1. OCR herunterladen und installieren (nur für neue Benutzer)
Wenn Sie dieses Tool zum ersten Mal verwenden, müssen Sie das OCR-Plugin in UPDF herunterladen. Navigieren Sie dazu oben links zur Option „Werkzeuge“ und wählen Sie im Bereich „PDF bearbeiten“ die Option „OCR“.
- Setzen Sie den Vorgang fort, indem Sie im Popup-Fenster auf die Schaltfläche „Installieren“ klicken.
- Sie werden automatisch zum nächsten Fenster weitergeleitet, in dem der Installationsfortschritt der Funktion angezeigt wird. Warten Sie, bis die Funktion erfolgreich auf Ihrem Mac-Gerät installiert ist, bevor Sie sie verwenden.
Schritt 2. PDF mit UPDF für Mac OCR
Schließen Sie nach der Installation das Fenster, navigieren Sie zur gleichen Option „Werkzeuge“ und drücken Sie im Menü die Option „OCR“.
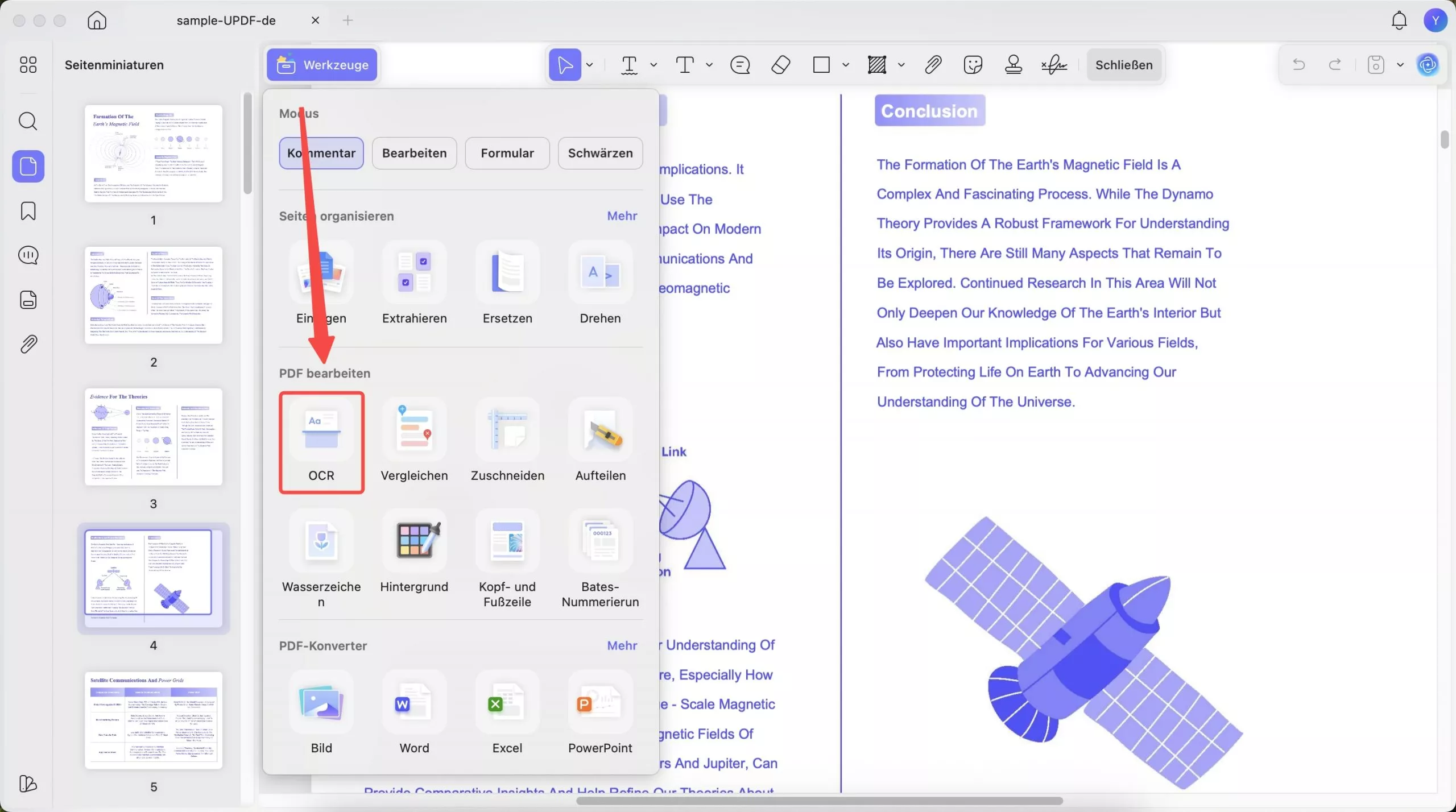
Anschließend öffnet sich ein neues Fenster, das Ihnen 3 Optionen für den Dokumenttyp bietet.
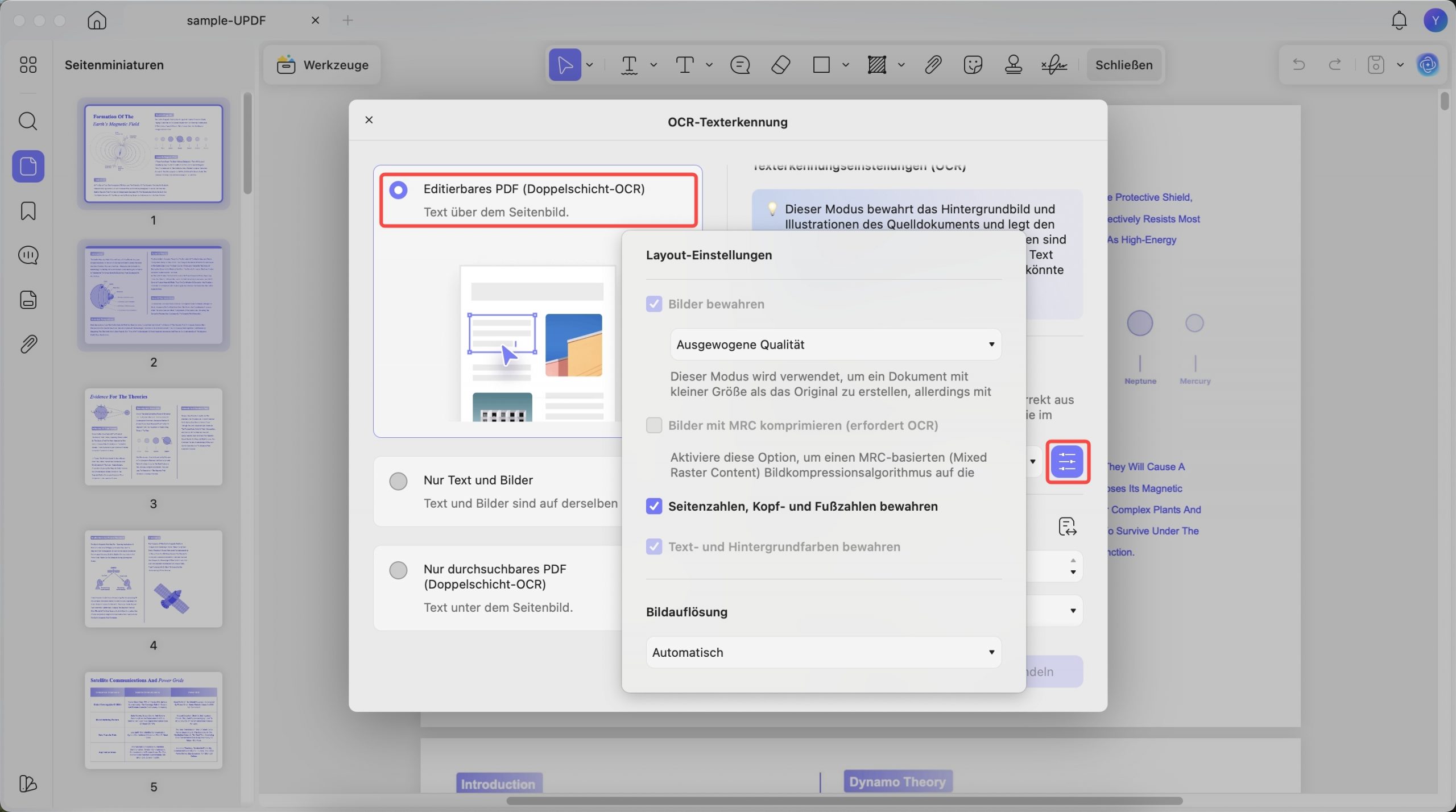
1. Editierbares PDF (Doppelschicht-OCR)
Wenn Sie diesen OCR-Modus wählen, werden die erkannten Texte und Bilder gespeichert, die sich leicht vom Originaldokument unterscheiden. Vor der OCR-Ausführung können Sie jedoch die Eigenschaften wie im Bild gezeigt und kurz erläutert festlegen.
- Layouteinstellungen: Im Fenster „Layouteinstellungen“ können Sie die Qualität mit Optionen wie „Ausgewogene Qualität“, „Hohe Qualität“ und „Niedrige Qualität“ zum Beibehalten der Bilder anpassen.
Es bietet Optionen zum Aktivieren der Optionen „Bilder mit MRC komprimieren“, „Seitenzahlen, Kopf- und Fußzeilen beibehalten“ oder „Text- und Hintergrundfarben beibehalten“.
Außerdem können Sie die Bildauflösung von Automatisch, 300, 150 und 72 DPI verbessern.
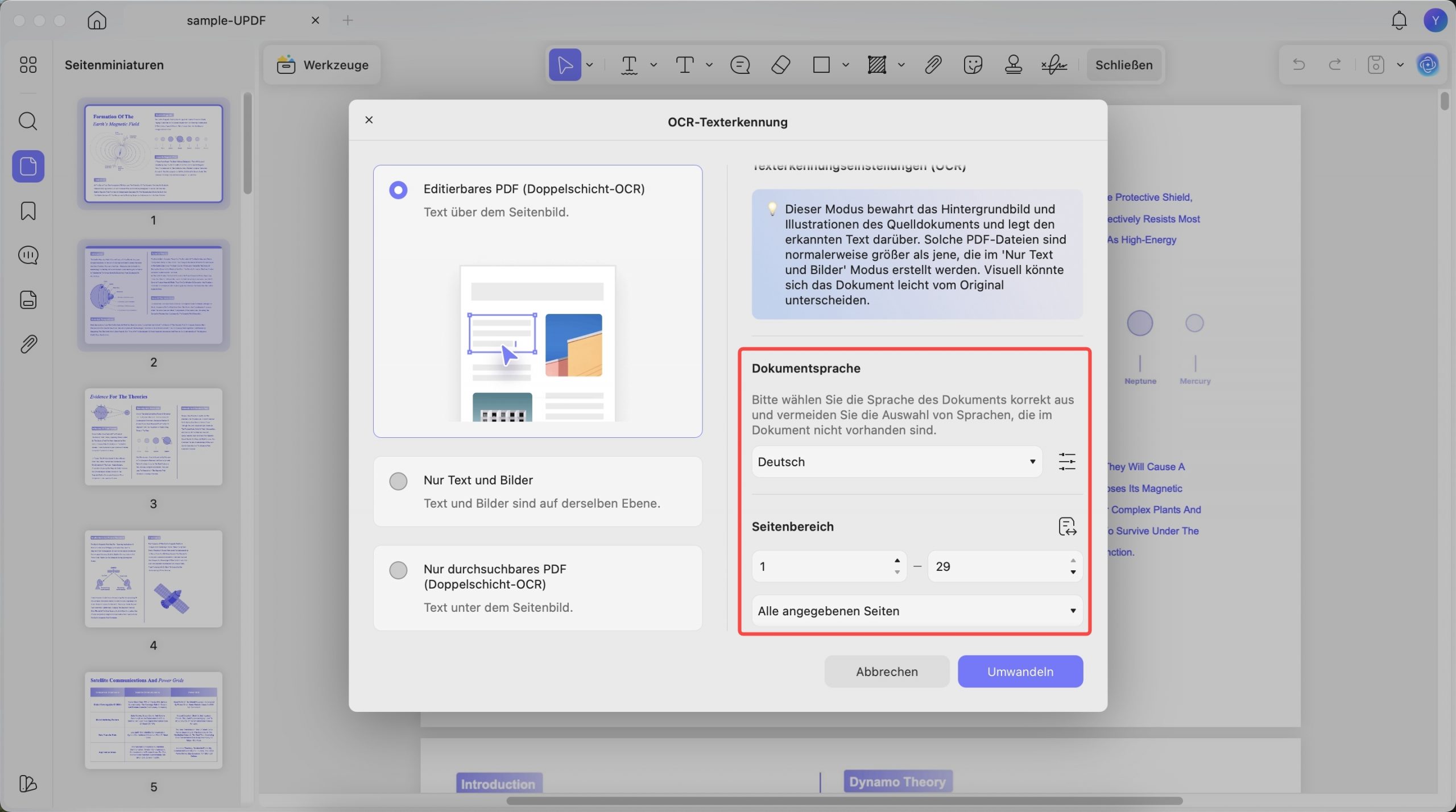
- Dokumentsprache: UPDF bietet Ihnen 38 Sprachen zur Auswahl vor der OCR.
- Seitenbereich: Mit dieser Option können Sie den Seitenbereich entweder manuell auswählen oder auf Optionen für „Alle Seiten“, „Gerade“ und „Ungerade Seiten“ zugreifen.
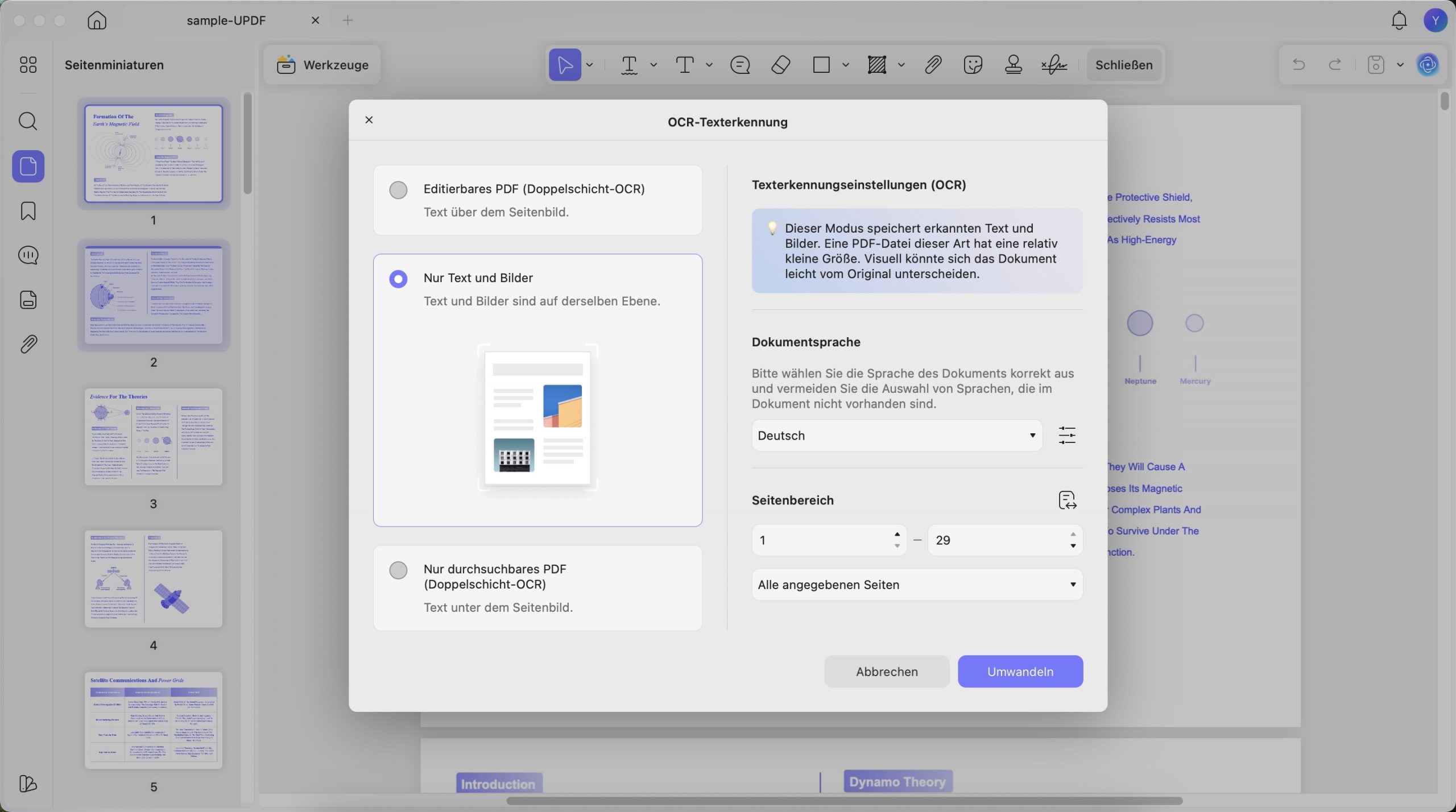
2. Nur Text und Bilder
In diesem Modus werden das Hintergrundbild und die Abbildungen des Quelldokuments gespeichert und über den erkannten Text gelegt. Um die Eigenschaften vor der OCR festzulegen, sehen Sie sich den folgenden Screenshot an. Die Dokumenteinstellungen ähneln denen für bearbeitbare PDF-Dateien.
3. Nur durchsuchbare PDFs (Doppelschicht-OCR)
In diesem Modus bleibt das Seitenbild erhalten, während der erkannte Text in einer unsichtbaren Ebene darunter platziert wird. Darüber hinaus ist dieser Dokumenttyp nahezu identisch mit dem Original. Beachten Sie hinsichtlich der Layouteinstellungen und anderer Eigenschaften den folgenden Screenshot:
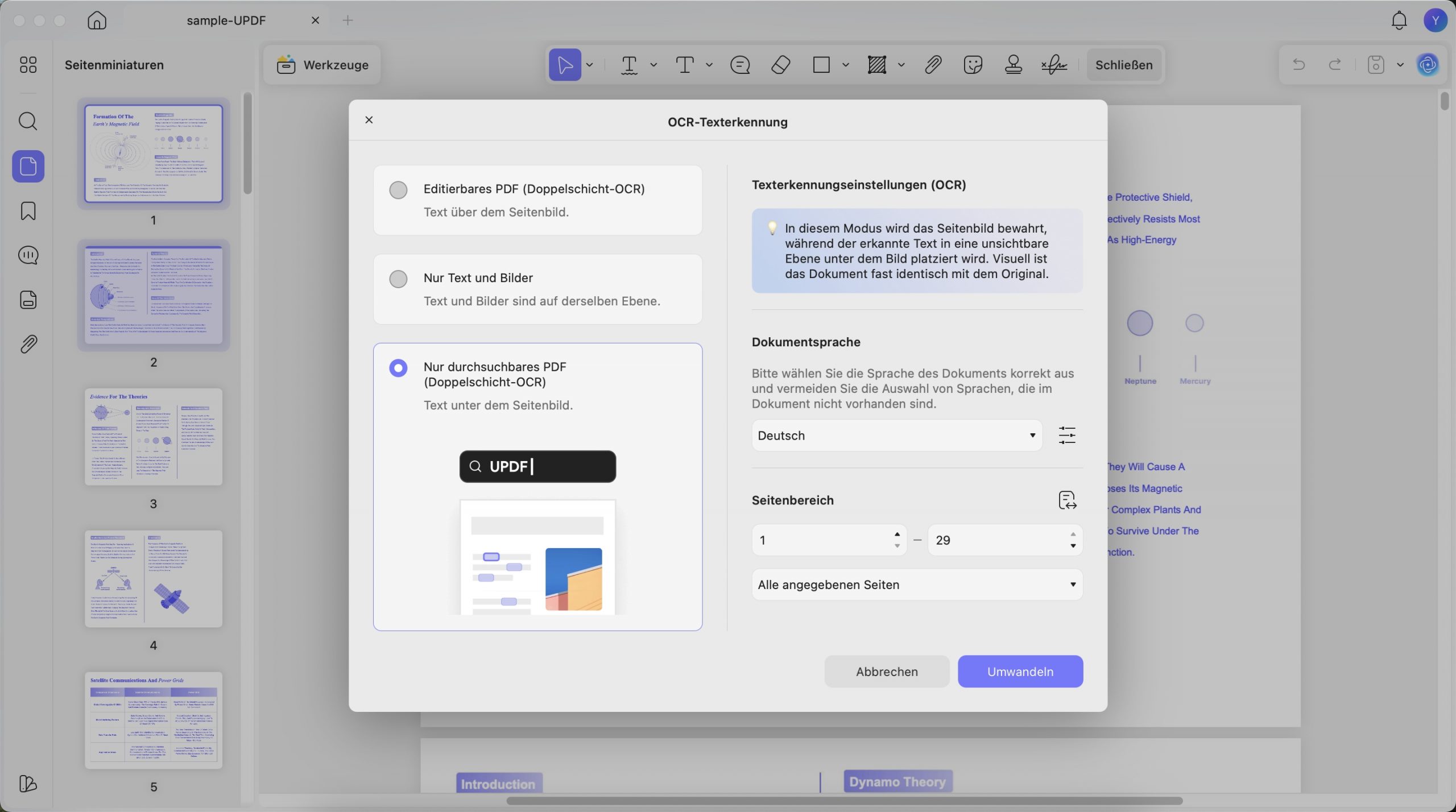
Wenn Sie mit den Einstellungen fertig sind, können Sie auf die Schaltfläche „Umwandeln“ klicken , um den Speicherort für die OCR-PDF auszuwählen. Sobald der Vorgang abgeschlossen ist, wird die OCR-PDF automatisch in UPDF geöffnet. Klicken Sie nun auf „PDF bearbeiten“, um Änderungen vorzunehmen, oder auf „Speichern“, um die Datei nach den Änderungen auf Ihrem Gerät zu speichern.
Sie können OCR in der kostenlosen Testversion ausprobieren. Wenn Sie zufrieden sind, können Sie hier auf die Pro-Version mit großem Rabatt upgraden.