 UPDF für Windows
UPDF für Windows UPDF für Mac
UPDF für Mac UPDF für iPhone/iPad
UPDF für iPhone/iPad UPDF für Android
UPDF für Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign PDF bearbeiten
PDF bearbeiten PDF kommentieren
PDF kommentieren PDF erstellen
PDF erstellen PDF-Formular
PDF-Formular Links bearbeiten
Links bearbeiten PDF konvertieren
PDF konvertieren OCR
OCR PDF in Word
PDF in Word PDF in Bild
PDF in Bild PDF in Excel
PDF in Excel PDF organisieren
PDF organisieren PDFs zusammenführen
PDFs zusammenführen PDF teilen
PDF teilen PDF zuschneiden
PDF zuschneiden PDF drehen
PDF drehen PDF schützen
PDF schützen PDF signieren
PDF signieren PDF schwärzen
PDF schwärzen PDF bereinigen
PDF bereinigen Sicherheit entfernen
Sicherheit entfernen PDF lesen
PDF lesen UPDF Cloud
UPDF Cloud PDF komprimieren
PDF komprimieren PDF drucken
PDF drucken Stapelverarbeitung
Stapelverarbeitung Über UPDF AI
Über UPDF AI UPDF AI Lösungen
UPDF AI Lösungen KI-Benutzerhandbuch
KI-Benutzerhandbuch FAQ zu UPDF AI
FAQ zu UPDF AI PDF zusammenfassen
PDF zusammenfassen PDF übersetzen
PDF übersetzen Chatten mit PDF
Chatten mit PDF Chatten mit AI
Chatten mit AI Chatten mit Bild
Chatten mit Bild PDF zu Mindmap
PDF zu Mindmap PDF erklären
PDF erklären PDF-KI-Tools
PDF-KI-Tools Bild-KI-Tools
Bild-KI-Tools KI-Chat-Tools
KI-Chat-Tools KI-Schreibtools
KI-Schreibtools KI-Lerntools
KI-Lerntools KI-Arbeitstools
KI-Arbeitstools Weitere KI-Tools
Weitere KI-Tools PDF in Word
PDF in Word PDF in Excel
PDF in Excel PDF in PowerPoint
PDF in PowerPoint Tutorials
Tutorials UPDF Tipps
UPDF Tipps FAQs
FAQs UPDF Bewertungen
UPDF Bewertungen Downloadcenter
Downloadcenter Blog
Blog Newsroom
Newsroom Technische Daten
Technische Daten Updates
Updates UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Wollten Sie schon einmal Text aus einem gescannten Dokument kopieren? Oder möchten Sie Text aus einer PDF-Datei mit Screenshots oder handschriftlichen Notizen extrahieren? Wenn ja, dann sind Sie hier richtig, um eine Lösung zu finden.
Mit der Texterkennung aus Scans oder Bildern können Sie wichtige Details extrahieren, ohne alles manuell neu abtippen zu müssen. Sie können den Text einfach extrahieren oder bearbeiten und bei Bedarf nach bestimmten Abschnitten suchen.
Aber wie erkennt man Text in einer PDF-Datei? Dieser Artikel ist Ihr Leitfaden. Wir zeigen Ihnen, wie Sie Text aus gescannten PDFs und handschriftlichen Notizen erkennen können.
Es gibt zwar mehrere Lösungen, aber wir empfehlen UPDF. Mit seinem leistungsstarken OCR-Tool können Sie Text in etwa 38 Sprachen erkennen. Dabei bleibt die Struktur des Textes intakt!
Sie können auch direkt in UPDF nach Text suchen und ihn bearbeiten, ohne zu einer anderen Plattform wechseln zu müssen. Und wenn Sie Handschrift in PDFs genau extrahieren möchten, macht UPDF dies mit seinem leistungsstarken KI-Assistenten möglich!
Warum probieren Sie es nicht selbst aus? Laden Sie UPDF jetzt herunter! Dann folgen Sie der Anleitung unten, um mühelos Text aus jeder PDF-Datei zu extrahieren!
Windows • macOS • iOS • Android 100% sicher
Teil 1. Text in gescannten PDF-Dokumenten erkennen
Wenn Sie PDF-Text in Bildern oder gescannten PDFs erkennen möchten, bietet das OCR-Tool von UPDF eine einfache Lösung. Es analysiert schnell den Text in Ihrem Dokument und konvertiert ihn mit bemerkenswerter Genauigkeit in ein bearbeitbares und durchsuchbares PDF.
Hier sind einige herausragende Merkmale, die es bietet.
- Sie können Scans mit 3 Layouts konvertieren: nur Text und Bild, Text über dem Hintergrundbild oder Text darunter.
- Sie können die Einstellungen für das Layout, die Bildauflösung, den Seitenbereich und vieles mehr anpassen.
- Sie können Text aus einem mehrsprachigen Dokument extrahieren.
- Mit Reverse OCR können Sie ein bearbeitbares PDF in ein reines Bildformat umwandeln.
- Es werden sowohl gescannte Dokumente als auch Bilder unterstützt.
Sind Sie bereit, Text in gescannten PDF-Dokumenten zu erkennen? So funktioniert's.
Schritt 1: Starten Sie UPDF auf Ihrem Gerät. Klicken Sie dann auf „Datei öffnen“, um Ihr gescanntes PDF zu importieren. Bei Bilddateien können Sie diese in die UPDF-Startoberfläche ziehen, um sie zu öffnen.
Schritt 2: Sobald Ihre Datei geöffnet ist, klicken Sie auf „Text mit OCR erkennen“ im rechten Fenster.
Schritt 3: Ein Menü für die OCR-Einstellungen wird geöffnet. Wählen Sie unter dem Dokumentart „Suchbares PDF“.
Schritt 4: Wählen Sie das gewünschte Layout aus und passen Sie weitere Einstellungen wie Dokumentsprache, Bildauflösung, Seitenbereich usw. an.
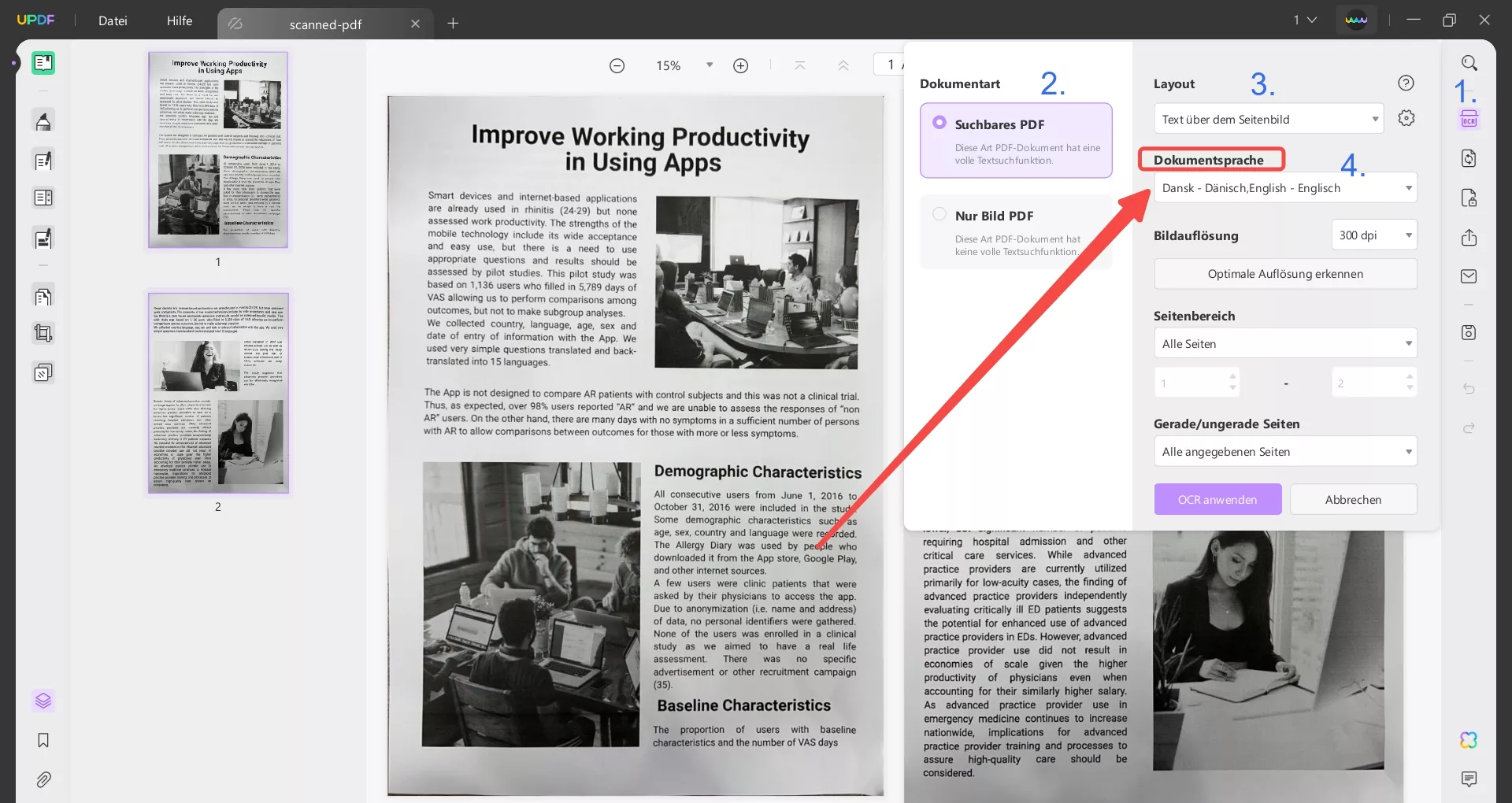
Schritt 5: Klicken Sie auf das Zahnradsymbol neben dem Dropdown-Menü Layout für erweiterte Layout-Einstellungen. Dadurch wird das Menü für die Layout-Einstellungen geöffnet. Hier können Sie Optionen wie MRC-Kompression und mehr auswählen. Klicken Sie auf „OCR anwenden“, wenn Sie mit den Einstellungen fertig sind.
Schritt 6: Sobald die OCR abgeschlossen ist, wird die konvertierte PDF-Datei in einem neuen Fenster geöffnet. Dann können Sie den Text in der PDF-Datei auswählen, suchen und bearbeiten.

Das war's. Jetzt wissen Sie, wie Sie Text in einer PDF-Datei mit gescannten Bildern erkennen können! Wenn Sie eher ein visueller Lerntyp sind, sehen Sie sich das folgende Video an, das eine einfache Anleitung für das OCR-Tool von UPDF enthält.
Teil 2. Handschriftlichen Text in PDF erkennen
Manchmal müssen Sie einen handschriftlichen Text aus einer PDF-Datei extrahieren. OCR-Tools können Ihnen zwar bei der Erkennung helfen, aber sie können ungenau sein, vor allem wenn die Schrift undeutlich ist.
Aber keine Sorge. UPDF bietet mit seinem integrierten KI-Assistenten eine einfache Lösung. Geben Sie ihm einen Screenshot der Handschrift, und er extrahiert den Text innerhalb von Sekunden. Sie können ihn dann kopieren und in einen beliebigen Texteditor einfügen, um ihn manuell zu bearbeiten.
Das ist der Chat mit der Bildfunktion bei der Arbeit! Hier sehen Sie, was Sie noch alles damit machen können.
- Sie können Text mit einer einzigen Eingabeaufforderung aus Bildern und Screenshots extrahieren.
- Es werden alle Sprachen für handschriftlichen und digitalen Text unterstützt.
- Sie können detaillierte Analysen von Datentabellen und komplexen Diagrammen erstellen.
- Sie können Expertenfeedback, Vorschläge zur Designverbesserung und vieles mehr anbieten.
- Sie können auf der Grundlage der Datei Inhalte für soziale Medien erstellen.
Sind Sie also bereit, handgeschriebenen Text in PDF zu erkennen? Laden Sie das Programm herunter und installieren Sie es auf Ihrem Windows oder Mac. Verwenden Sie dann die folgende Anleitung, um handschriftlichen Text schnell und einfach zu extrahieren!
Windows • macOS • iOS • Android 100% sicher
Schritt 1: Öffnen Sie UPDF auf Ihrem Desktop. Klicken Sie auf „Datei öffnen“ und wählen Sie die PDF-Datei mit dem handschriftlichen Text aus.
Schritt 2: Sobald Ihr PDF geöffnet ist, klicken Sie unten rechts auf „UPDF AI“. Wählen Sie dann oben den „Chatten“-Modus aus.

Schritt 3: Navigieren Sie zur PDF-Seite mit dem handschriftlichen Text. Wählen Sie dann unten rechts das Tool „Zuschneiden“ aus.

Schritt 4: Klicken Sie auf den Bereich mit dem handschriftlichen Text und ziehen Sie den Cursor darüber. Sobald Sie ihn loslassen, wird der Screenshot zu UPDF AI hochgeladen.
Schritt 5: Schreiben Sie eine Aufforderung an UPDF AI, die Handschrift aus dem Bild zu extrahieren. Klicken Sie dann auf die Schaltfläche „Senden“. UPDF AI wird die Handschrift schnell analysieren und sie in digitaler Form extrahieren.
Aufforderung: Extrahieren Sie den handschriftlichen Text aus diesem Bild.
Und so erkennen Sie handgeschriebenen Text in PDF mit AI! UPDF AI macht es schnell und einfach. Sie brauchen keine langwierigen Schritte oder komplexe Navigation. Und was noch besser ist, es bietet 100 kostenlose Aufgaben für den Anfang.
Neben dem KI-Assistenten bietet UPDF eine ganze Reihe von produktiven PDF-Werkzeugen für Ihre Arbeitsabläufe. Lesen Sie diesen UPDF-Test, um mehr über die Funktionen zu erfahren und wie Sie davon profitieren können!
Teil 3. Warum wird mein Text in PDF nicht erkannt?
Manchmal kann es vorkommen, dass eine OCR den Text nicht erkennt, was zu einer ungenauen Konvertierung führt. Wenn Sie mit diesem Problem konfrontiert sind, geraten Sie nicht in Panik. Hier sind einige mögliche Gründe und wie Sie das Problem beheben können.
- Qualitativ schlechte Scans: Ein Scan mit verschwommenem oder falsch ausgerichtetem Text ist für die OCR schwer zu erkennen.
- Unordentliche Handschrift: OCR-Tools können schlampig geschriebenen Text nur schwer erkennen.
- Stilisierte Schriftarten: Die PDF-Datei kann dekorativen oder komplexen Text enthalten, der die OCR verwirren kann.
- Geringer Kontrast: Wenn der Kontrast zwischen Text und Hintergrund nicht ausreichend ist, kann die Unterscheidung der Zeichen schwierig sein.
- Geschütztes PDF: Die PDF-Datei enthält möglicherweise Einschränkungen für die OCR und die Bearbeitung des Textes, wodurch die Texterkennung eingeschränkt wird.
Lösungen für nicht erkannten Text in PDF
Hier erfahren Sie, wie Sie das Problem „Text in PDF nicht erkannt“ beheben können.
- Hochwertige Scans verwenden: Scannen Sie das Dokument mit einer höheren Auflösung, um klaren und lesbaren Text zu erhalten.
- Mehrsprachige OCR verwenden: Wenn Ihr PDF-Dokument mehrere Sprachen enthält, verwenden Sie ein OCR-Tool, das mehrsprachige Dokumente unterstützt.
- OCR-Einstellungen prüfen: Wählen Sie die richtige Dokumentsprache, das richtige Layout und den richtigen Ausgabetyp. Falsche Einstellungen können zu Problemen bei der Texterkennung führen.
- KI verwenden: Wenn das Ergebnis nicht Ihren Vorstellungen entspricht, versuchen Sie, die gescannte PDF-Datei in Bilder umzuwandeln oder einen Screenshot davon zu machen, und verwenden Sie dann ein AI-Tool wie UPDF AI, um Text zu extrahieren.
Fazit
Hier erfahren Sie, wie Sie Text in PDF-Dateien erkennen können. Mit den vielseitigen Texterkennungsfunktionen von UPDF ist der Prozess mühelos. Sie können das OCR-Werkzeug verwenden, um Text aus gescannten Dokumenten zu erkennen, oder den KI-Assistenten, um Text mit minimalem Aufwand zu extrahieren. Probieren Sie es aus. Laden Sie UPDF noch heute auf Ihren Desktop herunter! Sie werden einen effizienten Weg finden, Ihre gescannten PDFs und mehr zu bearbeiten!
Windows • macOS • iOS • Android 100% sicher







 Delia Meyer
Delia Meyer 

