 Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
Mac版UPDF でPDFをOCRする方法
UPDF for MacのOCR機能を使用すると、スキャンしたPDFや画像のみのPDF文書を検索・編集可能な文書に変換できます。さらに、検索・編集可能なPDFを画像のみのPDFに変換することも可能です。下のボタンをクリックしてMac版UPDFをダウンロードし、以下の手順に従って使い方をご確認ください。
ここで、 MacでUPDFOCR 機能を使用する手順を説明します。または以下の動画をご覧ください。
Windows • macOS • iOS • Android 100%安全
ステップ1. OCRをダウンロードしてインストールする(新規ユーザーのみ)
このツールを初めて使用する場合は、UPDFのOCRプラグインをダウンロードする必要があります。ダウンロードするには、左上の「ツール」オプションに移動し、 「PDF編集」セクションの「OCR」オプションを選択してください。
- ポップアップ ウィンドウの 「インストール」ボタンをクリックしてプロセスを続行します。
- 次のウィンドウに自動的にリダイレクトされ、機能のインストールの進行状況が表示されます。ご利用になる前に、Macデバイスに機能が正常にインストールされるのをお待ちください。
ステップ2. Mac用UPDFでPDFをOCR処理する
インストール後、ウィンドウを閉じ、同じツールオプションに移動して、メニューからOCRオプションを押します。
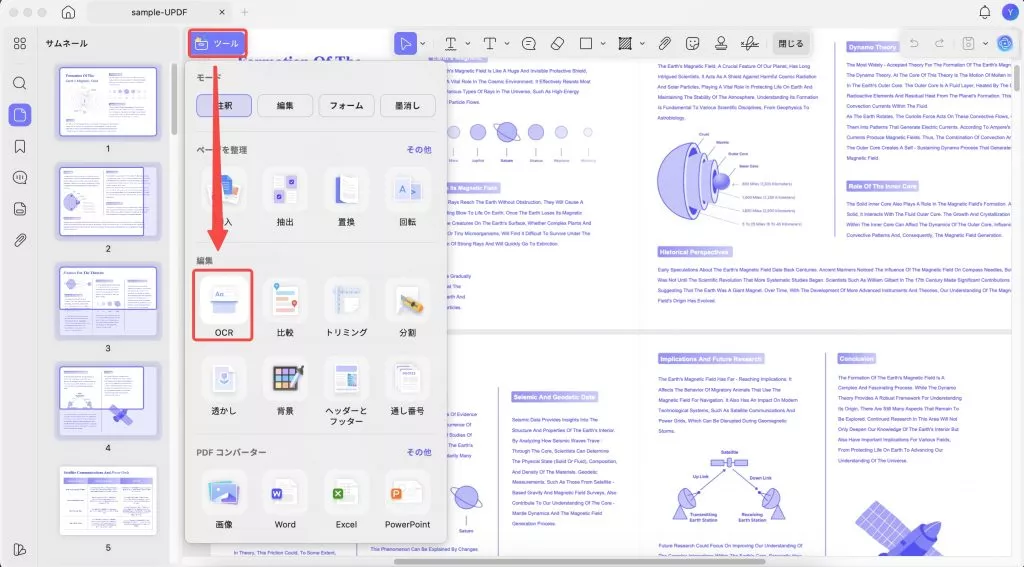
その後、新しいウィンドウが開き、ドキュメント タイプに関する 3 つのオプションが表示されます。
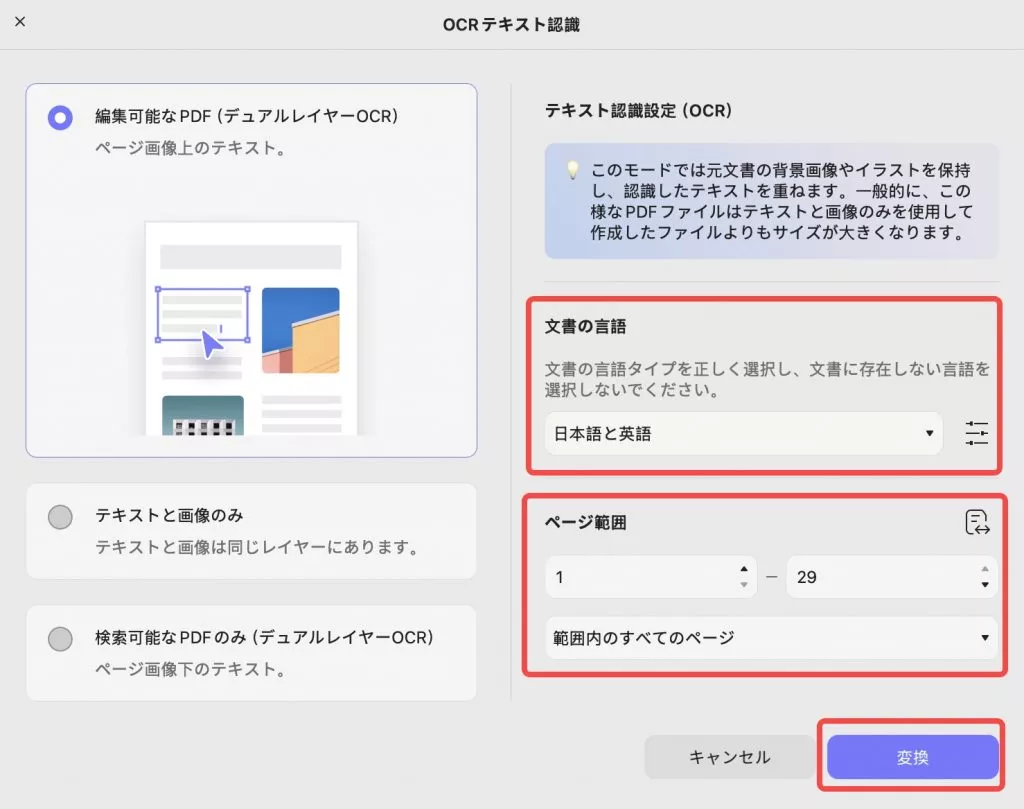
1. 編集可能なPDF(二層OCR)
OCRでこのモードを選択すると、認識されたテキストと画像が保存されますが、元の文書とは若干異なります。ただし、OCRを実行する前に、図に示すようにプロパティを設定できます。
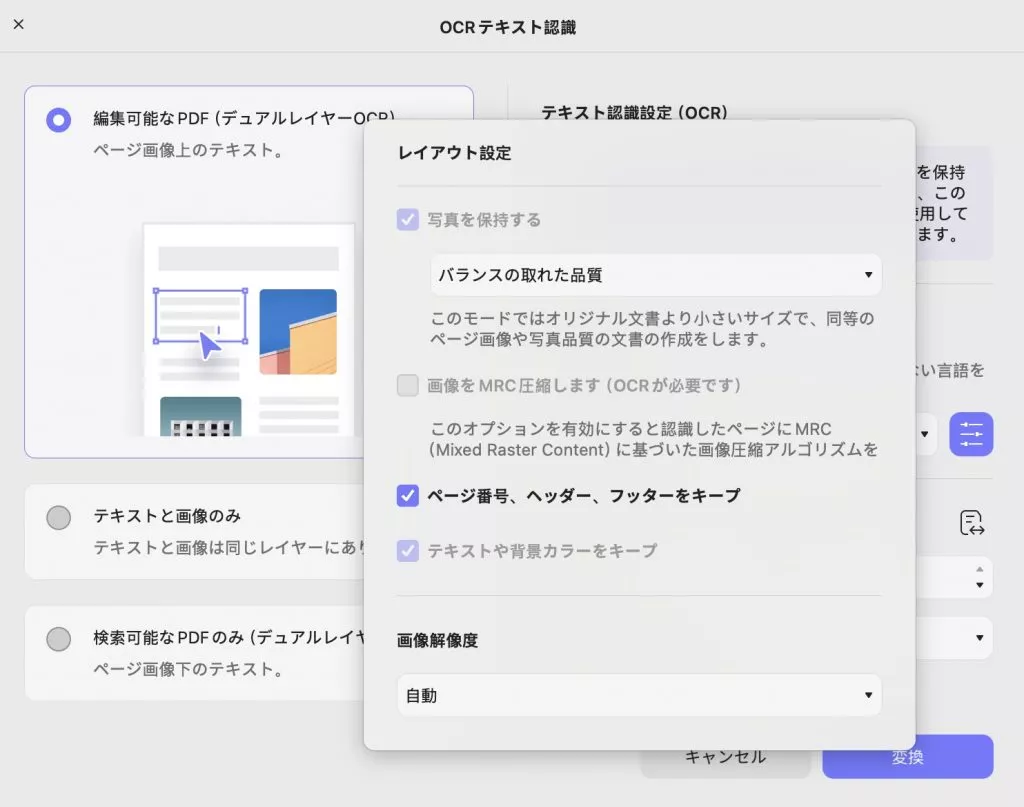
- レイアウト設定:レイアウト設定ウィンドウでは、バランス品質、高品質、低品質などのオプションを使用して、画像を維持するための品質を調整できます。
MRC を使用して画像を圧縮する、ページ番号、ヘッダー、フッターを保持する、またはテキストと背景の色を保持するをチェックするオプションがあります。
これに加えて、画像の 解像度を自動、300、150、72 DPIから向上させることができます。
- ドキュメント言語: UPDF では、OCR の前に選択できる言語が 38 種類あります。
- ページ範囲:このオプションを使用すると、ページ範囲を手動で選択するか、すべての ページ、偶数ページ、奇数 ページのオプションにアクセスすることができます。
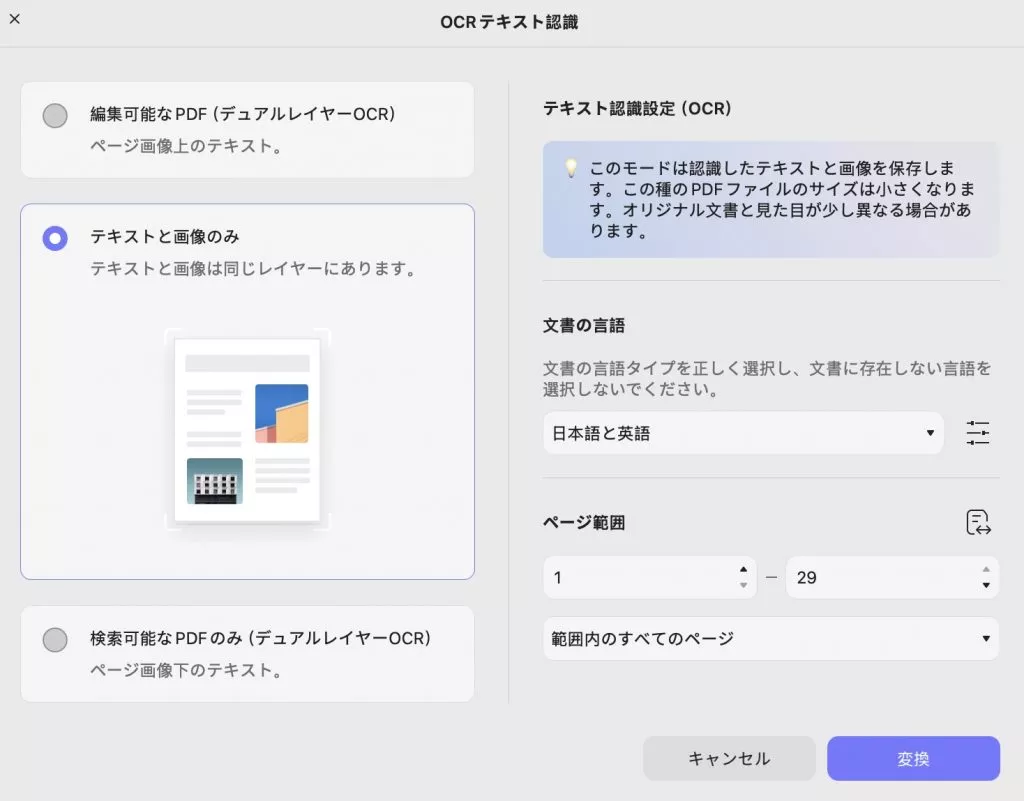
2. テキストと画像のみ
このモードでは、ドキュメントの背景画像とソースドキュメントのイラストが保存され、認識されたテキストが重ねて表示されます。OCR処理の前にプロパティを設定するには、下のスクリーンショットを確認してください。ただし、編集可能なPDFで説明したものと同様のドキュメント設定が可能です。
3. 検索可能なPDFのみ(二層OCR)
このモードでは、ページ画像は保持されますが、認識されたテキストは画像の下の非表示レイヤーに配置されます。また、このタイプのドキュメントは元のドキュメントとほぼ同じです。レイアウト設定やその他のプロパティについては、提供されているスクリーンショットをご覧ください。
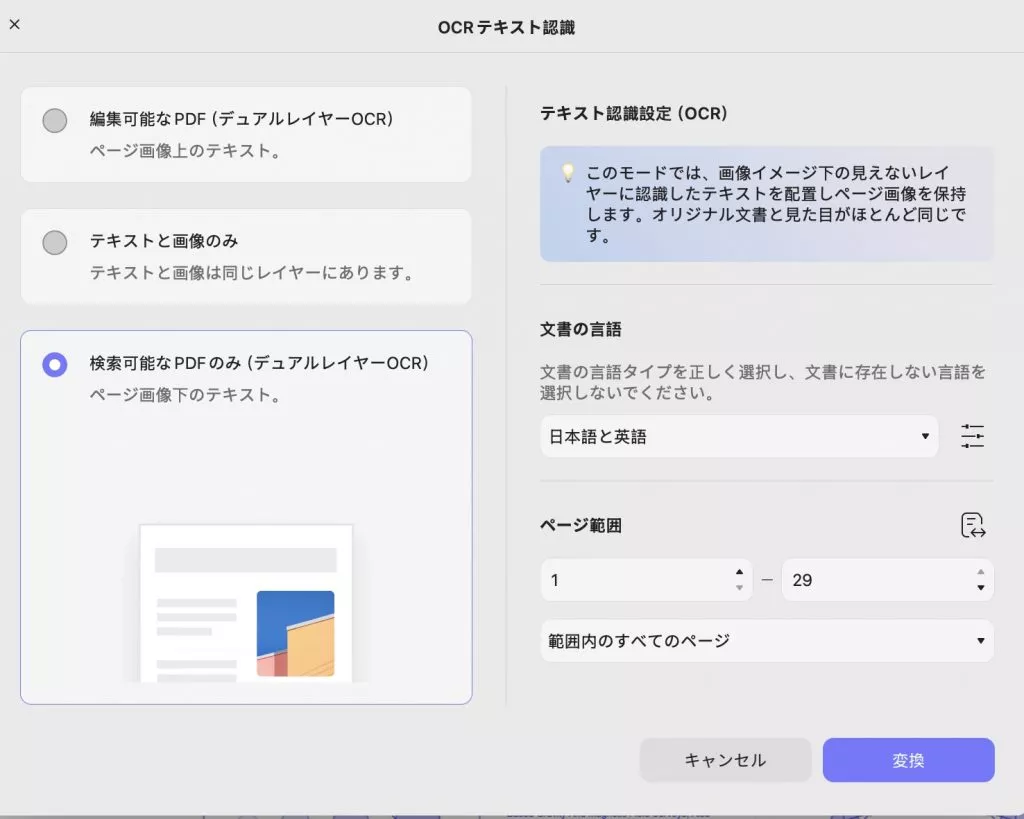
設定が完了したら、「変換」ボタンをクリックして、OCR処理されたPDFの保存先を選択してください。処理が完了すると、OCR処理されたPDFはUPDFで自動的に開きます。「PDFを編集」をクリックして変更を加えるか、「保存」アイコンをクリックして変更を加えた後、デバイスに保存してください。
無料トライアル版でOCR機能をお試しください。ご満足いただけましたら、こちらをクリックしてプロ版にアップグレードすると、大幅な割引が適用されます。