 UPDF pour Windows
UPDF pour Windows UPDF pour Mac
UPDF pour Mac UPDF pour iPhone/iPad
UPDF pour iPhone/iPad updf android
updf android UPDF AI en ligne
UPDF AI en ligne UPDF Sign
UPDF Sign Modifier le PDF
Modifier le PDF Annoter le PDF
Annoter le PDF Créer un PDF
Créer un PDF Formulaire PDF
Formulaire PDF Modifier les liens
Modifier les liens Convertir le PDF
Convertir le PDF OCR
OCR PDF en Word
PDF en Word PDF en Image
PDF en Image PDF en Excel
PDF en Excel Organiser les pages PDF
Organiser les pages PDF Fusionner les PDF
Fusionner les PDF Diviser le PDF
Diviser le PDF Rogner le PDF
Rogner le PDF Pivoter le PDF
Pivoter le PDF Protéger le PDF
Protéger le PDF Signer le PDF
Signer le PDF Rédiger le PDF
Rédiger le PDF Biffer le PDF
Biffer le PDF Supprimer la sécurité
Supprimer la sécurité Lire le PDF
Lire le PDF UPDF Cloud
UPDF Cloud Compresser le PDF
Compresser le PDF Imprimer le PDF
Imprimer le PDF Traiter par lots
Traiter par lots À propos de UPDF AI
À propos de UPDF AI Solutions de UPDF AI
Solutions de UPDF AI Mode d'emploi d'IA
Mode d'emploi d'IA FAQ sur UPDF AI
FAQ sur UPDF AI Résumer le PDF
Résumer le PDF Traduire le PDF
Traduire le PDF Analyser le PDF
Analyser le PDF Discuter avec IA
Discuter avec IA Analyser les informations de l'image
Analyser les informations de l'image PDF vers carte mentale
PDF vers carte mentale Expliquer le PDF
Expliquer le PDF Recherche académique
Recherche académique Recherche d'article
Recherche d'article Correcteur IA
Correcteur IA Rédacteur IA
Rédacteur IA Assistant aux devoirs IA
Assistant aux devoirs IA Générateur de quiz IA
Générateur de quiz IA Résolveur de maths IA
Résolveur de maths IA PDF en Word
PDF en Word PDF en Excel
PDF en Excel PDF en PowerPoint
PDF en PowerPoint Mode d'emploi
Mode d'emploi Astuces UPDF
Astuces UPDF FAQs
FAQs Avis sur UPDF
Avis sur UPDF Centre de téléchargement
Centre de téléchargement Blog
Blog Actualités
Actualités Spécifications techniques
Spécifications techniques Mises à jour
Mises à jour UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Comment convertir un PDF scanné en Word pour le rendre modifiable dans le logiciel de Microsoft? Ce processus ne peut être réalisé sans l'opération spéciale appelée OCR. Il existe plusieurs façons de procéder, dans cet article, nous allons vous présenter les méthodes les plus efficaces et les plus pratiques pour convertir des PDF numérisés en Word sur Windows et Mac.
Le meilleur convertisseur de PDF numérisé en Word
Avec la prise en charge de plus de 38 langues d'OCR, UPDF est certainement l'un des outils de conversion de PDF numérisés en Word les plus polyvalents et les plus puissants que vous pourrez trouver pour Windows et Mac. N'oubliez pas que la conversion d'un document numérisé avec OCR exige une grande précision et qu'UPDF utilise un puissant moteur d'OCR pour ses conversions. Le résultat final sera un document Word avec la même mise en page et le même formatage que le document original.

En fait, c'est un éditeur de PDF offrant les solutions tout-en-un. UPDF vous permet de modifier des documents PDF, de les commenter, de les protéger, OCR, etc.
Voici le bouton de téléchargement gratuit ci-dessous. Téléchargez-le dans votre logiciel et on voit ensemble les étapes suivante pour convertir un PDF scanné en Word avec UPDF.
Windows • macOS • iOS • Android 100% sécurisé
Comment convertir un PDF scanné en Word modifiable avec OCR
Vous souhaitez convertir un document PDF numérisé en texte afin de pouvoir l'utiliser partout où cela est nécessaire? Plutôt que de taper le texte, vous pouvez facilement le convertir en Word éditable à l'aide de l'outil OCR fourni par UPDF. Voici les étapes à suivre :
Étape 1: Définissez le type de document pour l'OCR
D'abord, ouvrez le fichier que vous souhaitez convertir avec UPDF, et puis cliquez sur le bouton "OCR" dans le panneau de droite. Dans la section "Type de Document", sélectionnez "PDF Consultable" et poursuivez le processus.
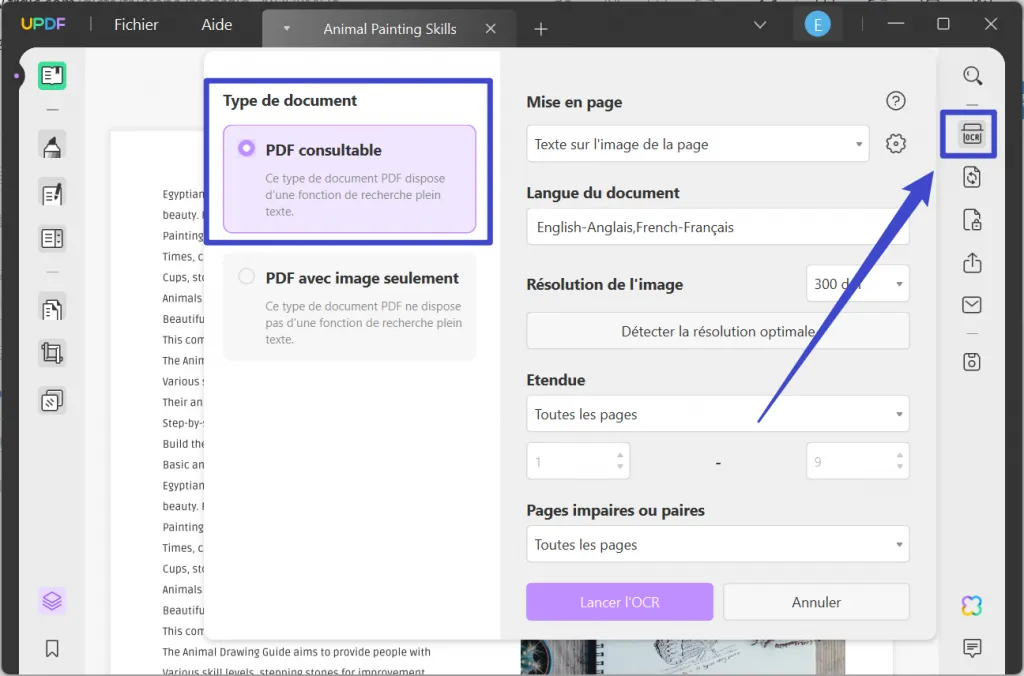
Étape 2: Définissez les paramètres de mise en page
En commençant par définir les paramètres de l'outil d'OCR, vous devrez définir les paramètres de "Mise en Page" de ce processus. Pour ce faire, vous disposerez de trois paramètres de mise en page différents, qui sont expliqués ci-dessous:
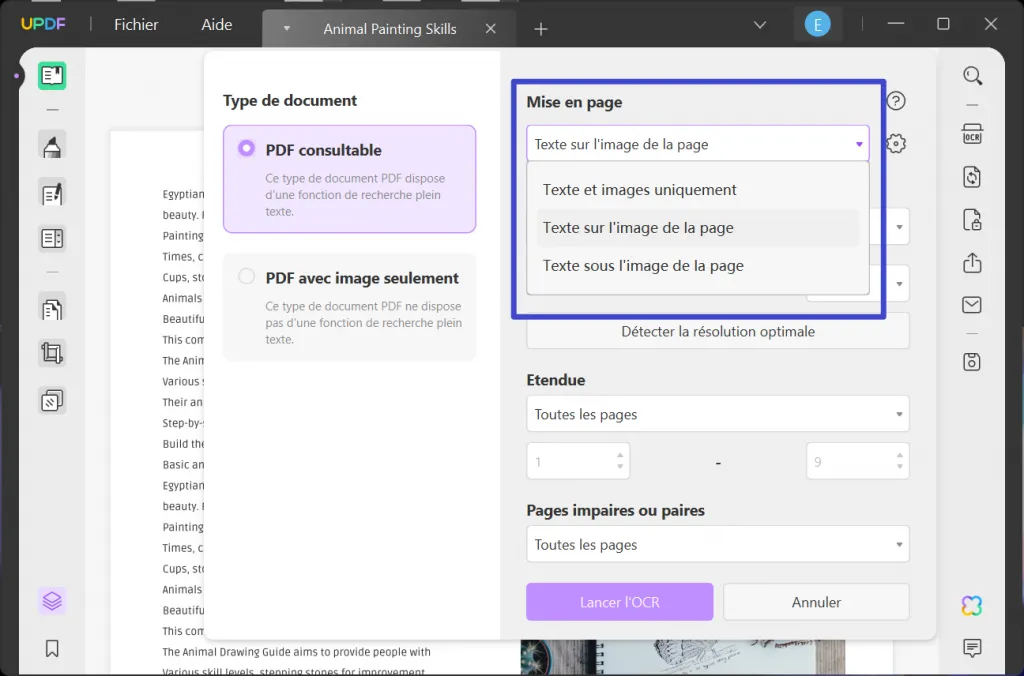
- Texte et images uniquement: Ce paramètre de mise en page enregistre l'ensemble du texte et des images dans un document PDF. Le fichier converti est plus petit que l'original et n'a pas de formatage spécifique.
- Textes sur l'image de la page: Il s'agisse de la mise en page par défaut définie au cours du processus d'OCR PDF. Ce mode particulier contient les images et les illustrations conformément au fichier original. Vu qu'elles soient de grande taille, elles ne sont pas très différentes du document PDF d'origine.
- Textes sous l'image de la page: La structure complète de l'image du document PDF original est préservée dans ce mode particulier. Le texte est présent sous la couche d'image du document, il n'est donc pas modifiable, mais il peut faire l'objet d'une recherche.
Une fois que vous avez terminé, passez à la section "Langue du Document", où vous devez sélectionner la langue particulière qui doit être détectée. Vous pouvez choisir n'importe quelle langue appropriée parmi les 38 options disponibles dans le menu.
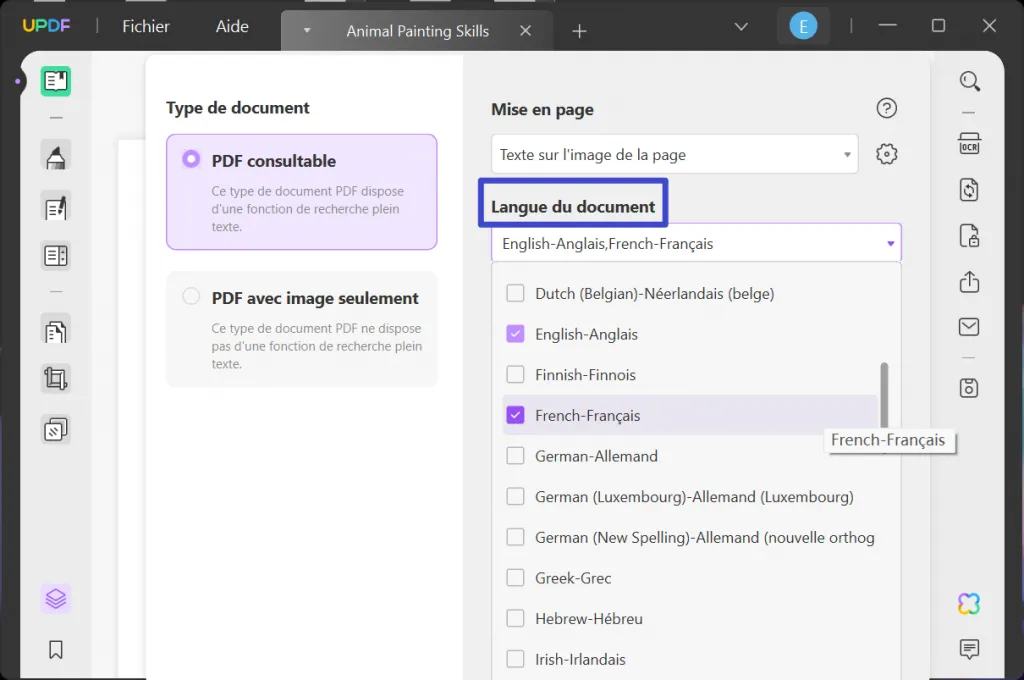
Passez à la section "Résolution de L'Image" et définissez la bonne valeur en utilisant les options disponibles dans le menu. Si vous n'êtes pas sûr, vous pouvez cliquer sur le bouton "Détecter la résolution optimale" et continuer.
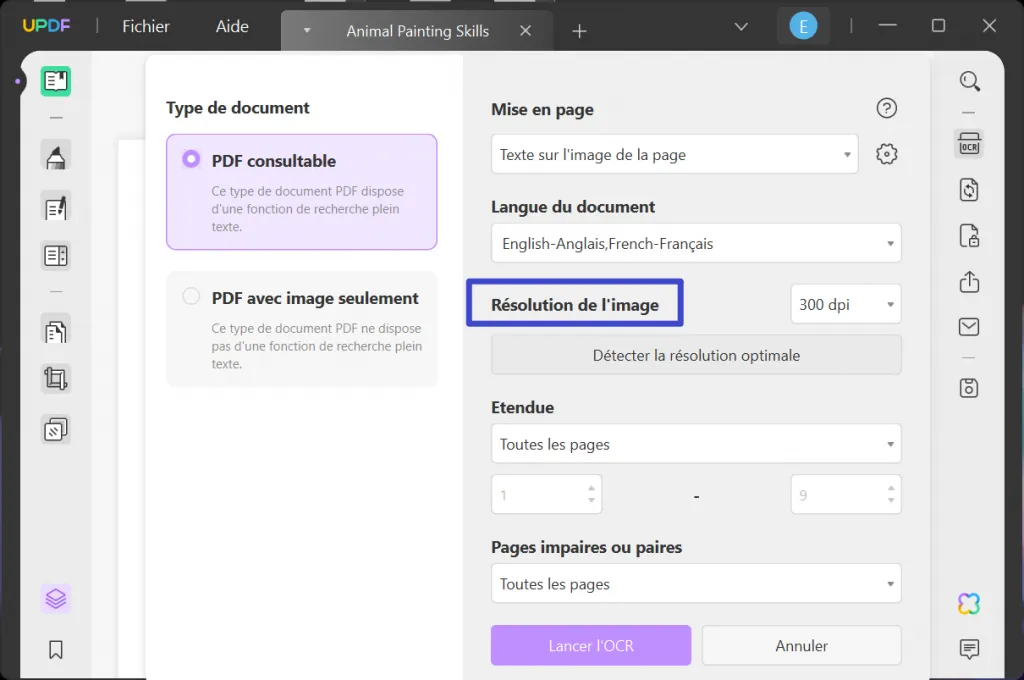
Ensuite, indiquez l'étendue où vous souhaitez exécuter la fonction et cliquez sur "Lancer L'OCR". Et puis, définissez le bon emplacement pour le document converti.
Étape 3: Convertissez le PDF numérisé en mots modifiables
Vous pouvez maintenant le convertir au format Word en utilisant la fonction "Exporter". Voici la marche à suivre :
- Ouvrez le fichier PDF sur UPDF et cliquez sur "Exporter PDF" dans la barre d'outils de droite. Ensuite, sélectionnez le format "Word".
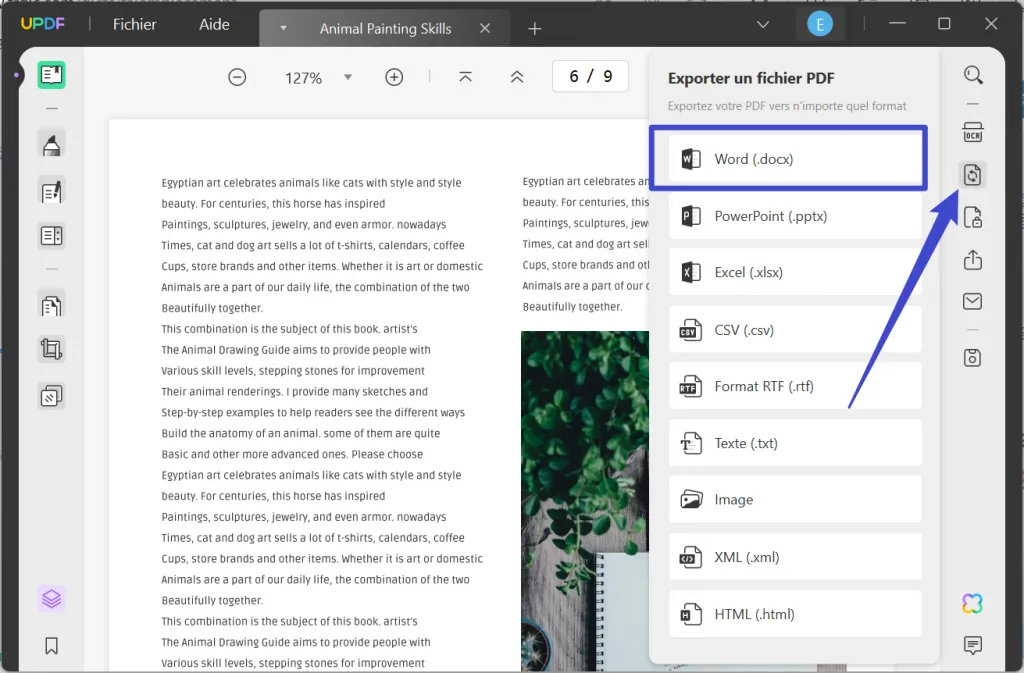
- Il apparaît par la suite une fenêtre contextuelle pour vous permettre à définir les paramètres selon vos besoins. Après, cliquez sur le bouton "Exporter" et ainsi le processus est achevé.
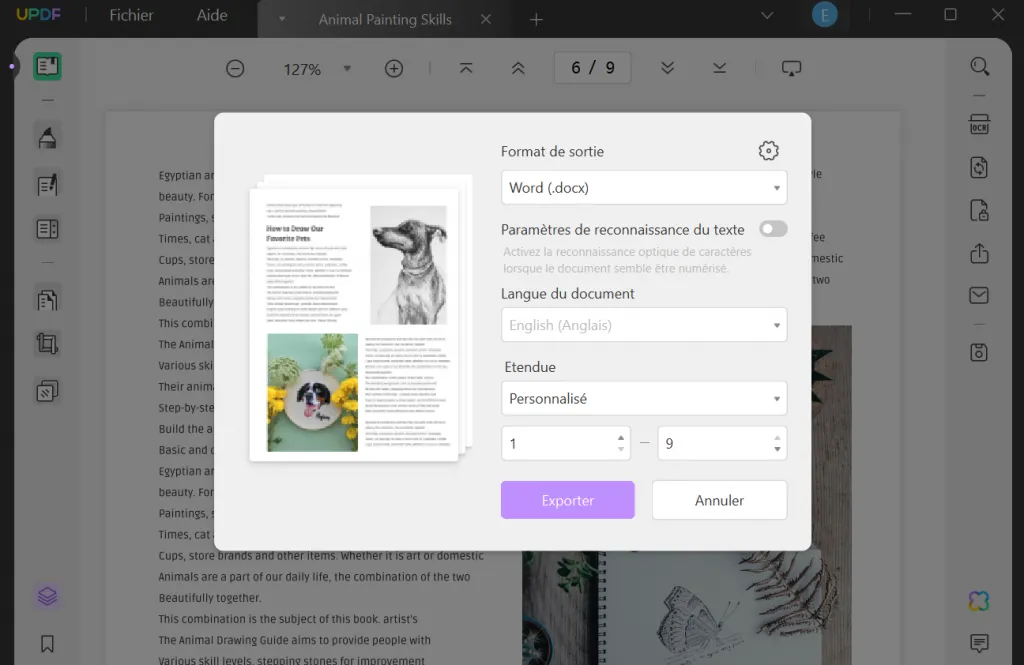
De plus, afin de rendre l'ensemble du processus plus clair pour vous, nous avons préparé une vidéo tutoriel juste en dessous. Vous pouvez d'abord cliquer sur le bouton de téléchargement ci-dessous et suivre la vidéo d'instruction.
Windows • macOS • iOS • Android 100% sécurisé
Tutoriel vidéo sur la conversion d'un PDF numérisé en Word
Quels sont les problèmes courants liés à la conversion de PDF numérisés en Word
En général, le moteur OCR peut convertir la plupart des fichiers PDF numérisés. Cependant, tous les fichiers numérisés ne sont pas égaux. Avant toute chose, si vous travaillez avec des fichiers numérisés, assurez-vous d'avoir activé l'option OCR dans le programme.
Avant d'ouvrir et de convertir un fichier numérisé, allez dans les paramètres de l'OCR et lancez-le. Si le fichier ne se convertit pas, la cause peut en être la suivante: L'espace entre les caractères trop étroit, une mauvaise qualité d'image, un mélange de polices de caractères utilisées, des caractères en italique et soulignés, qui peuvent tous brouiller la clarté et la forme des caractères individuels, sont autant de problèmes qui peuvent altérer le résultat de l'OCR.
Par conséquent, il est beaucoup plus difficile de confirmer que le caractère "reconnu" par le logiciel d'OCR correspond complètement au caractère présent sur le papier numérisé.
Le plus important est que vous sachiez qu'avec OCR d'UPDF, vous n'avez pas à vous soucier de ces problèmes car il vous donnera des résultats parfaits et précis. Il se peut que certaines polices ne soient pas traduites correctement, surtout si votre fichier numérisé comporte de l'écriture manuscrite, mais le contenu sera aussi proche que possible de la copie numérisée. Essayez-le maintenant.
Windows • macOS • iOS • Android 100% sécurisé
Qu'est-ce qu'un PDF numérisé
Un document PDF peut être créé en numérisant un document papier pour en faire une version électronique. Pour ce faire, on utilise un scanner ou un appareil similaire qui capture l'image d'un document papier et l'enregistre sous forme de fichier PDF électronique. Lorsqu'un scanner réalise cette image numérisée, il ne reproduit pas chaque caractère de chaque mot. Il prend seulement un "instantané" du document papier. Le logiciel fourni avec le scanner convertit ensuite la photo en un document PDF. Le résultat est un document PDF "numérisé".
Le contenu d'un PDF numérisé ne peut être ni recherché ni modifié. Dans ce cas-là, un logiciel d'OCR est nécessaire pour reconnaître électroniquement chaque caractère d'une page et le transformer en un format utilisable pour rechercher ou modifier un PDF numérisé. Essentiellement, il reconnaît et extrait le texte des images.
FAQ sur les PDF numérisés
Qu'est-ce que l'OCR (reconnaissance optique de caractères)?
Le processus de conversion d'une image texte en un format texte lisible par une machine est connu sous le nom de reconnaissance optique de caractères (OCR). Par exemple, lorsque vous numérisez un formulaire ou un reçu, votre ordinateur enregistre la numérisation sous forme de fichier image. En utilisant un éditeur de texte, vous ne pouvez pas modifier, rechercher ou compter les mots dans le fichier image. Vous pouvez toutefois utiliser l'OCR pour transformer l'image en un document texte, dont le contenu est enregistré sous forme de données texte.
La majorité des flux de travail des entreprises impliquent l'obtention d'informations à partir de supports imprimés tels que des formulaires papier, des factures, des documents juridiques numérisés, des contrats imprimés, etc. Le stockage et la gestion de ces grandes quantités de documents exigent beaucoup de temps et d'espace. Si la gestion des documents sans papier est la voie à suivre, la numérisation d'un document en une image présente des difficultés. La procédure nécessite une intervention manuelle et peut s'avérer longue et inefficace.
En outre, la numérisation de ce contenu documentaire génère des fichiers image contenant le texte qu'ils contiennent. Le texte image ne peut pas être traité par un logiciel de traitement de texte de la même manière que les documents texte. Le problème est résolu par la technologie OCR, qui convertit les images de texte en données que d'autres applications commerciales peuvent évaluer. Les données peuvent ensuite être utilisées pour l'analyse, la rationalisation des opérations, l'automatisation des procédures et l'amélioration de la productivité.
Qu'est-ce qu'un fichier PDF natif?
Un PDF natif est un PDF d'un document qui est "né numérique", c'est-à-dire qu'il a été créé à partir d'une version électronique du document plutôt que d'une version imprimée. D'autre part, un PDF numérisé consiste à numériser les pages d'un document imprimé, puis à enregistrer le fichier au format PDF.
Quelle est la différence entre un PDF numérisé et un PDF natif?
Vous souhaitez connaître les différences entre un PDF numérisé et un PDF natif? Les PDF numérisés sont des PDF constitués d'images numérisées d'un certain document. Comme un PDF numérisé est une collection d'images, l'utilisateur est souvent incapable de faire des recherches sur le texte. Les PDF natifs, en revanche, sont des PDF de documents qui sont "nés" sous forme numérique, ce qui signifie que le PDF a été créé à partir d'une version électronique originale du document, comme un document Microsoft Word. De plus en plus de contenu dans les bases de données ProQuest est numérique à l'origine et donc disponible sous forme de PDF natif au format PDF (certains textes complets sont uniquement disponibles en ASCII/HTML). Le pourcentage d'informations numériques natives versées dans les bases de données ProQuest augmente d'année en année.
Quels sont les types de PDF numérisés?
Les PDF numérisés sont classés en trois catégories:
- PDF d'image - Le type de PDF le plus fréquent est le PDF d'image. C'est le cas lorsqu'un document papier est scanné pour être transformé en fichier PDF.
- PDF numérisés avec texte consultable - Ce document PDF numérisé peut contenir du texte caché derrière l'image.
- PDF numérisés à contenu mixte - Ce PDF peut contenir des photos numérisées et des éléments PDF générés électroniquement.
Conclusion
Et voilà qui conclut notre article sur le meilleur outil pour convertir des PDF numérisés en Word à des fins d'édition ou d'autres. D'après les présentations ci-dessus, nous pouvons savoir que UPDF est abordable, précis, dédié, polyvalent et disponible pour les systèmes Windows et Mac. En outre, vous pouvez convertir les PDF en divers autres formats afin que les fichiers puissent être édités dans leurs applications d'origine. Essayez-le et rejoignez des tonnes d'utilisateurs satisfaits qui font confiance à UPDF pour traiter leurs flux de documents quotidiens. Voici l'entrée de téléchargement ci-dessous.
Windows • macOS • iOS • Android 100% sécurisé








 Freddy Leroy
Freddy Leroy 


