 UPDF pour Windows
UPDF pour Windows UPDF pour Mac
UPDF pour Mac UPDF pour iPhone/iPad
UPDF pour iPhone/iPad updf android
updf android Nomostar
Nomostar UPDF AI en ligne
UPDF AI en ligne UPDF Sign
UPDF Sign IvyCraft
IvyCraft Modifier le PDF
Modifier le PDF Annoter le PDF
Annoter le PDF Créer un PDF
Créer un PDF Formulaire PDF
Formulaire PDF Modifier les liens
Modifier les liens Convertir le PDF
Convertir le PDF OCR
OCR PDF en Word
PDF en Word PDF en Image
PDF en Image PDF en Excel
PDF en Excel Organiser les pages PDF
Organiser les pages PDF Fusionner les PDF
Fusionner les PDF Diviser le PDF
Diviser le PDF Rogner le PDF
Rogner le PDF Pivoter le PDF
Pivoter le PDF Protéger le PDF
Protéger le PDF Signer le PDF
Signer le PDF Rédiger le PDF
Rédiger le PDF Biffer le PDF
Biffer le PDF Supprimer la sécurité
Supprimer la sécurité Lire le PDF
Lire le PDF UPDF Cloud
UPDF Cloud Compresser le PDF
Compresser le PDF Imprimer le PDF
Imprimer le PDF Traiter par lots
Traiter par lots À propos de UPDF AI
À propos de UPDF AI Solutions de UPDF AI
Solutions de UPDF AI Mode d'emploi d'IA
Mode d'emploi d'IA FAQ sur UPDF AI
FAQ sur UPDF AI Résumer le PDF
Résumer le PDF Traduire le PDF
Traduire le PDF Analyser le PDF
Analyser le PDF Discuter avec IA
Discuter avec IA Analyser l'image
Analyser l'image PDF vers carte mentale
PDF vers carte mentale Expliquer le PDF
Expliquer le PDF Outils IA PDF
Outils IA PDF Outils IA Image
Outils IA Image Outils de Chat IA
Outils de Chat IA Outils de Rédaction IA
Outils de Rédaction IA Outils d’Étude IA
Outils d’Étude IA Outils Professionnels IA
Outils Professionnels IA Autres Outils IA
Autres Outils IA Génération de signets IA
Génération de signets IA Résumé de signets IA
Résumé de signets IA Génération de filigranes IA
Génération de filigranes IA Génération d’arrière-plans IA
Génération d’arrière-plans IA Génération d’autocollants IA
Génération d’autocollants IA Génération de tampons IA
Génération de tampons IA Suite de rédaction IA
Suite de rédaction IA UPDF Copilot
UPDF Copilot Gestion des pages IA
Gestion des pages IA Recherche sémantique IA
Recherche sémantique IA PDF en Word
PDF en Word PDF en Excel
PDF en Excel PDF en PowerPoint
PDF en PowerPoint Mode d'emploi
Mode d'emploi Astuces UPDF
Astuces UPDF FAQ
FAQ Avis sur UPDF
Avis sur UPDF Centre de téléchargement
Centre de téléchargement Blog
Blog Actualités
Actualités Spécifications techniques
Spécifications techniques Mises à jour
Mises à jour UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Vous ne savez pas comment rechercher dans un PDF numérisé qui affiche « Cette page contient uniquement des images » ? Ou bien vous avez essayé de rechercher des mots à l’aide de la fonction Rechercher de Windows ou du raccourci CTRL + F, sans aucun résultat ? Vous étiez sans doute en train de chercher dans un PDF numérisé. Si vous vous demandez comment effectuer une recherche dans des documents PDF numérisés, ne cherchez plus ! Plongeons ensemble dans la solution.
Comment rechercher des mots dans un PDF numérisé ?
Le fait est que les documents numérisés ne contiennent aucun texte ! Puisqu’il s’agit simplement d’une image du document, il n’existe aucun texte réel que Windows puisse indexer.
Pour rendre votre PDF consultable, vous devez exécuter une reconnaissance de texte afin de rendre le contenu de la page à la fois recherchable et modifiable. Vous pouvez utiliser n’importe quel logiciel doté d’une fonction OCR (reconnaissance optique de caractères). Ce processus analyse le document numérisé, identifie tout ce qui ressemble à une lettre ou à un mot, et le transforme en texte réel.
De nombreux éditeurs PDF proposent cette fonctionnalité, mais nous vous recommandons UPDF — votre solution PDF tout-en-un ! Grâce à sa fonction OCR alimentée par l’IA, UPDF convertit vos PDF numérisés, documents papier et images en PDF consultables et modifiables, avec trois types de mises en page de sortie, pour une expérience interactive et parfaitement adaptée à vos besoins.
Pour en savoir plus sur la fonction OCR d’UPDF, consultez cet article. Téléchargez d’abord UPDF avant de suivre les étapes d’instructions que nous allons présenter.
Windows • macOS • iOS • Android 100% sécurisé

Voici quelques fonctionnalités impressionnantes de ce logiciel OCR :
- Jusqu’à 99 % de précision : la technologie OCR avancée d’UPDF garantit des résultats hautement précis !
- La vitesse OCR la plus élevée : qui ne veut pas gagner du temps ? UPDF le sait, c’est pourquoi sa conversion est extrêmement rapide comparée à celle de ses concurrents.
- Taille de fichier réduite avec une qualité optimale : le fichier PDF converti est bien plus léger que le document original, tout en conservant une excellente qualité.
- Prise en charge de 38 langues : UPDF gère aussi les documents bilingues et permet de sélectionner plusieurs ensembles linguistiques.
En plus de tout cela, UPDF vous permet également de lire, organiser et annoter vos PDF, et de convertir des PDF numérisés de n’importe quelle taille ! Alors, qu’attendez-vous ? Suivez les étapes simples ci-dessous pour apprendre à rechercher des mots dans vos PDF numérisés et résoudre votre problème dès maintenant ! Quelques clics suffisent pour y parvenir rapidement !
Étape 1 : Ouvrir le PDF et accéder à l’icône OCR
Cliquez sur « Ouvrir un fichier » pour importer votre PDF. Vous pouvez également utiliser le raccourci Ctrl + O ou Cmd + O.
Cliquez ensuite sur l’option « OCR » dans le menu « Outils » situé dans la barre latérale gauche.
(Si c’est la première fois que vous utilisez cette fonction, UPDF vous proposera de télécharger un module complémentaire. Cliquez sur Télécharger dans la fenêtre qui s’affiche, puis patientez pendant son installation.)
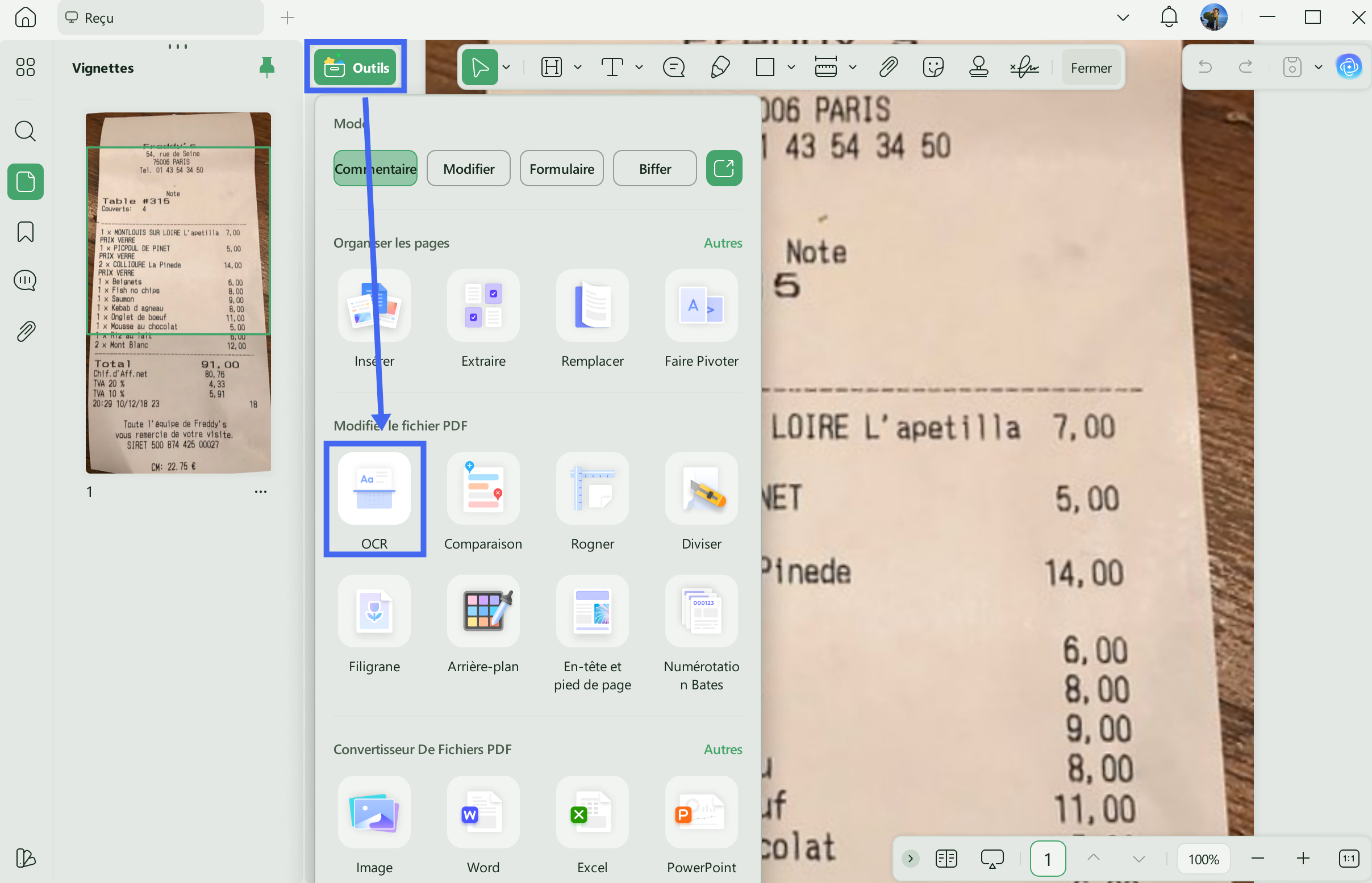
Étape 2 : Rendre le PDF numérisé consultable
Vous pouvez choisir entre trois modes : PDF éditable, Texte et images uniquement ou PDF consultable uniquement.
Si vous souhaitez modifier votre PDF numérisé, sélectionnez « PDF éditable », car cette option transforme le document scanné en fichier éditable.
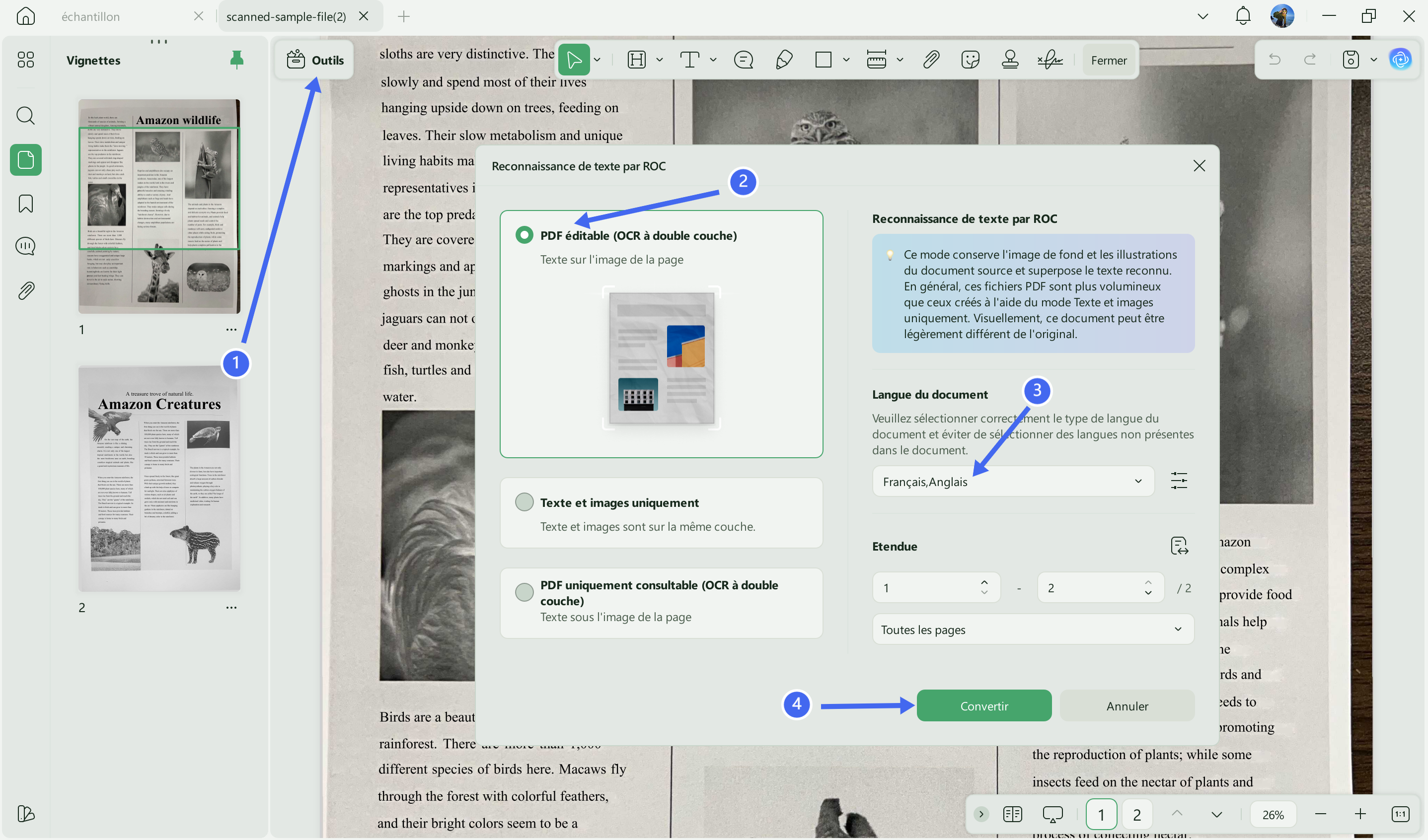
Vous devez également définir la langue du document correspondant à la langue source, ainsi que la plage de pages à traiter.
Cliquez ensuite sur l’option « Convertir », choisissez l’emplacement où vous souhaitez enregistrer le fichier, puis cliquez sur « Enregistrer ».
Étape 3 : Rechercher des mots dans le PDF numérisé
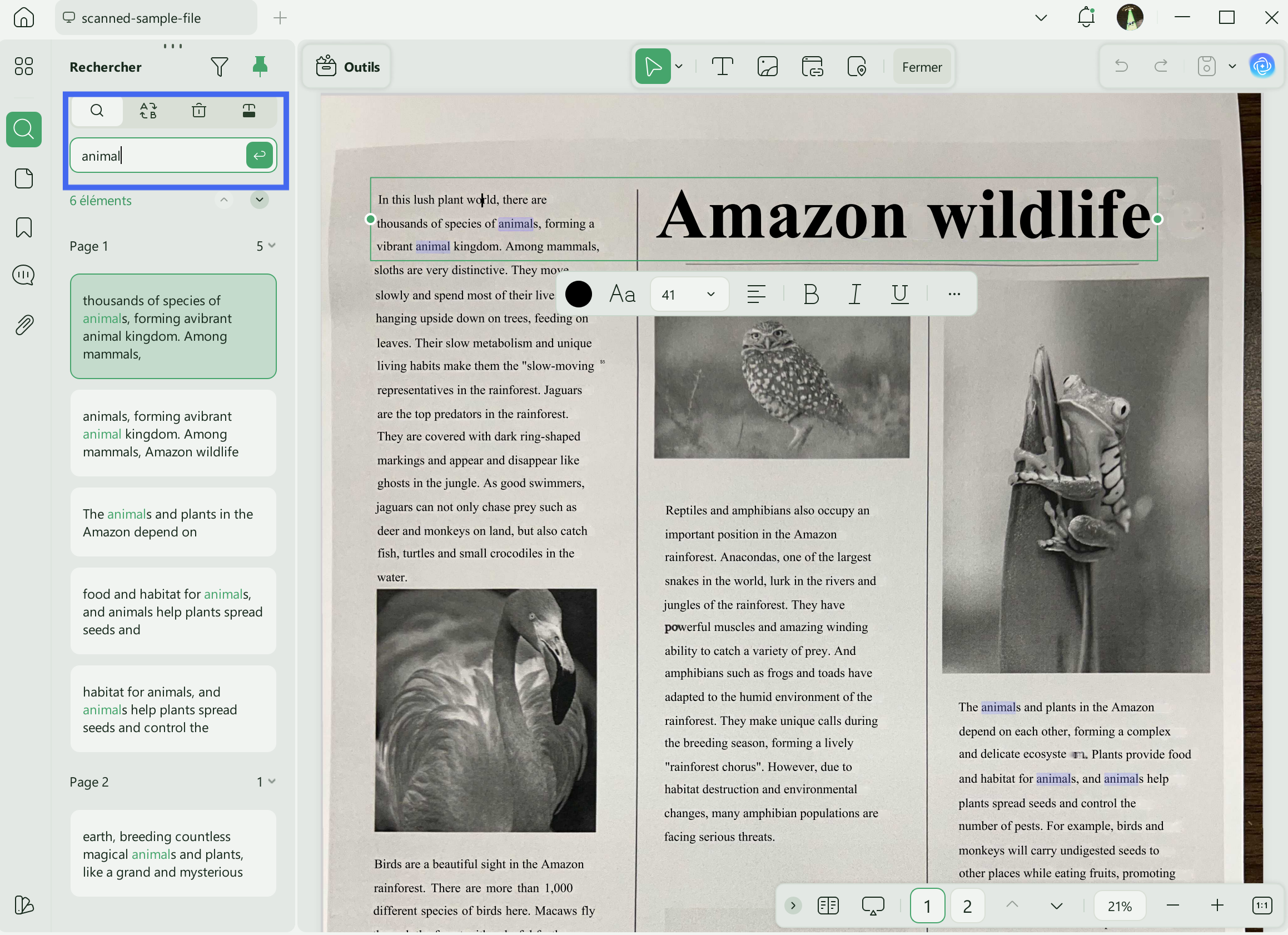
Une fois la reconnaissance OCR effectuée, le fichier PDF consultable s’ouvrira automatiquement dans UPDF.
Vous pouvez alors rechercher des mots dans votre document en appuyant sur Ctrl + F ou en cliquant sur l’icône de recherche située en haut à droite.
Saisissez le mot que vous souhaitez trouver : UPDF affichera tous les résultats correspondants dans le document. Vous pouvez cliquer sur n’importe quel résultat pour être redirigé directement vers la page concernée.
C’est aussi simple que cela pour rechercher du texte dans un PDF !
Pour en savoir plus sur la manière d’appliquer l’OCR à un PDF, regardez la vidéo ci-dessous.
Bonus
Les utilisateurs intéressés peuvent explorer nos différentes fonctionnalités via la barre de navigation supérieure. Vous pouvez également consulter notre article pour découvrir comment UPDF se compare à Adobe Acrobat. Et en prime, nous proposons une licence perpétuelle à un prix bien plus abordable qu’Adobe Acrobat >>
Astuce : quel type de mise en page cho isir lors de l’OCR ?
Pour les PDF consultables, il est essentiel de choisir la mise en page appropriée selon vos besoins ou le contexte d’utilisation. UPDF propose plusieurs options ; voici leurs différences :
PDF éditable
Ce mode conserve à la fois le texte reconnu et les images, puis les regroupe dans un fichier PDF généralement plus léger.
Petit avertissement : le rendu visuel peut différer légèrement du document original — avec de légères variations de mise en page ou de couleur, mais le contenu reste intégralement accessible et modifiable.
Texte et images uniquement
Ce mode conserve toutes les illustrations et images d’arrière-plan du fichier original, puis superpose le texte reconnu par-dessus.
Résultat : les fichiers générés sont souvent plus volumineux, mais visuellement très proches du document d’origine. Il peut y avoir de subtiles différences d’apparence, sans altérer la lisibilité.
PDF consultable uniquement
Ici, l’image d’origine reste intacte, et le texte reconnu est discrètement placé dans une couche invisible en dessous.
Ainsi, à l’œil nu, le document semble identique à l’original, mais vous pouvez désormais effectuer des recherches textuelles ou copier du texte à volonté.
FAQ : recherche dans un PDF numérisé
Pour les PDF consultables, il est essentiel de choisir la mise en page appropriée selon vos besoins ou le contexte d’utilisation. UPDF propose plusieurs options ; voici leurs différences :
Q1. Pourquoi ne puis-je pas rechercher dans un PDF numérisé ?
Lorsque vous numérisez un document, le scanner capture simplement une image plane de la page. Il n’y a donc aucun texte réel que Windows ou un lecteur PDF puisse reconnaître.
Pour rendre le fichier consultable, utilisez la fonction OCR d’UPDF, qui convertit votre scan en texte lisible et indexable.
Q2. Puis-je utiliser Ctrl + F dans un document scanné ?
Non. La fonction de recherche Windows (Ctrl + F) ne fonctionne que sur les documents contenant du texte lisible.
Pour rechercher du texte dans un PDF scanné, vous devez d’abord convertir le fichier via un logiciel prenant en charge l’OCR, comme UPDF.
Q3. Pourquoi Ctrl + F ne fonctionne-t-il pas dans mon PDF ?
Parce que votre fichier contient uniquement des images (comme les documents scannés), sans texte réel que le système puisse reconnaître. Seule une conversion OCR permet d’activer cette fonction.
Conclusion
Vous ne savez toujours pas comment rechercher un mot dans un PDF scanné ? Pas d’inquiétude — UPDF est la solution qu’il vous faut.
Son moteur OCR intelligent est à la fois rapide, précis et incroyablement simple d’utilisation.
Il peut même reconnaître le texte dans un document flou, là où d’autres logiciels échouent. Grâce à son algorithme de compression d’image basé sur MRC, UPDF peut convertir n’importe quelle image en texte détectable, ou transformer votre fichier en PDF image uniquement selon vos besoins.
Alors, qu’attendez-vous ? Téléchargez UPDF dès maintenant pour interagir librement avec vos PDF et profiter d’une expérience fluide et intelligente grâce à ses outils IA. Vous pouvez aussi passer à la version Premium afin de débloquer toutes les fonctionnalités sans aucune limite.
Windows • macOS • iOS • Android 100% sécurisé







 Freddy Leroy
Freddy Leroy 


