Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 学術研究
学術研究 論文検索
論文検索 AI校正ツール
AI校正ツール AIライター
AIライター AI宿題ヘルパー
AI宿題ヘルパー AIクイズメーカー
AIクイズメーカー AI数学ソルバー
AI数学ソルバー PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド UPDFを使いこなすヒント
UPDFを使いこなすヒント よくあるご質問
よくあるご質問 UPDF レビュー
UPDF レビュー ダウンロードセンター
ダウンロードセンター ブログ
ブログ ニュースルーム
ニュースルーム 技術仕様
技術仕様 更新情報
更新情報 UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
スキャンしたPDFや画像ベースのPDFに変更を加えようとしたことがあれば、それがどれほど難しいかをご存知でしょう。ただし、PDF文字認識は最も簡単で最も効果的な方法です。この方法では、テキストの編集は簡単な作業です。この投稿では、PDF内の文字を認識する最も効率的な方法を説明します。
方法1. UPDFでPDF内の文字を認識する方法
PDF編集ソフトが必要な場合は、包括的なエンタープライズグレードのオプションであるUPDF以外に選択肢はありません。さまざまな機能があり、作成者は製品を改善するために常にフィードバックを取り入れています。
使い方は簡単で、便利な機能が満載です。UPDFは、単なるPDFエディターではなく、PDF閲覧、PDF注釈およびPDFオーガナイザーでもあります。UPDFの最も優れた点は、OCRを使用してPDF内の単語を認識しやすくなることです。さらに、他にも多くの機能があります。体験版をダウンロードできます。
Windows • macOS • iOS • Android 100%安全
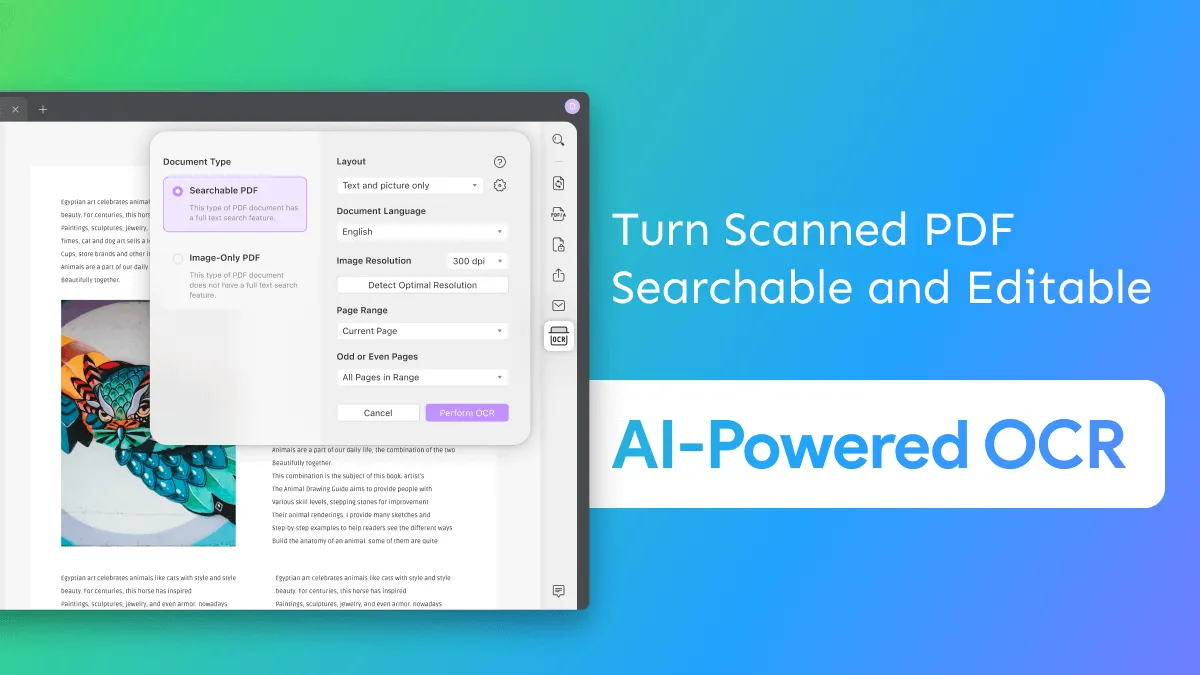
UPDFの最も重要で人気のある機能は次のとおりです。
- PDFはWord文書と同じように編集できるため、現在のコンテンツを簡単に編集できます。
- テキスト、段落、領域を強調表示することで、PDFドキュメントを目立たせることができます。
- 空白ページやその他のPDFページは、UPDFを使用して挿入できます。UPDFを使用すると、単一ページまたはPDF全体を置き換えることができます。
- いくつかの異なる読み取り形式から選択できます。複数のPDFファイルを一度に開くことができます。
- PDFドキュメントに簡単に電子署名することもできます。
OCRテキスト認識を行う方法は次のとおりです。
ステップ1: OCRツールに進む
PDFドキュメントを開き、右側のパネルから「OCRを使用してテキストを認識」ボタンに移動します。
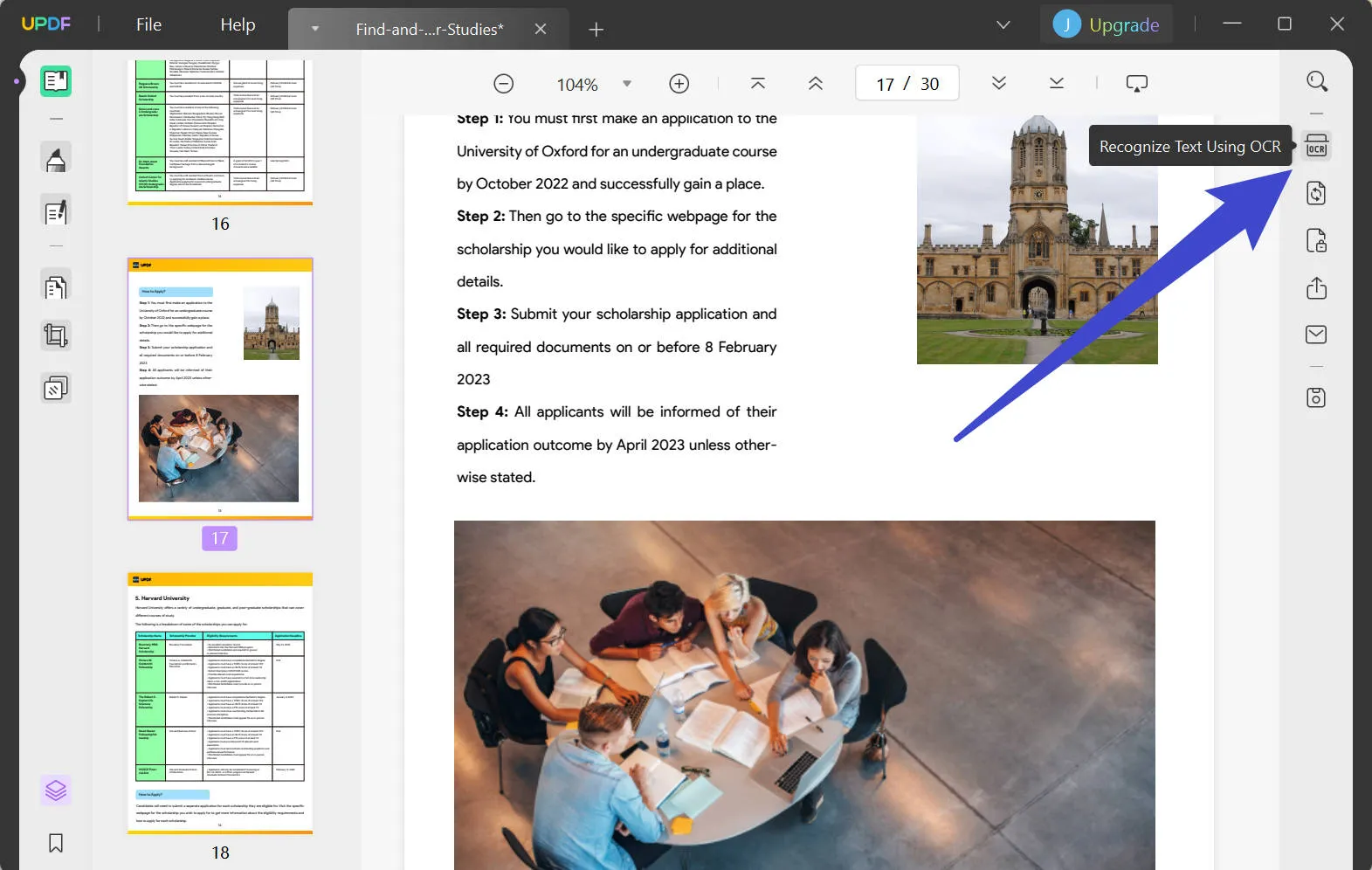
ステップ2: OCR設定
突き出たメニューで、ドキュメントの種類セクションで「検索可能なPDF」を選択します。
- メニューで利用可能なオプションを使用して、OCRツールが従う「レイアウト」を定義できます。「歯車」アイコンを選択して、詳細なレイアウト設定を開きます。プロセスで取り上げたいオプションにチェックマークを付けます。
- レイアウト設定のセットアップが完了したら、「ドキュメント言語」にプロパゲートし、UPDFで利用可能な38のオプションの中から特に検出したい言語を選択します。
- リスト内の利用可能なオプションを使用して「画像解像度」の設定に進みます。解像度がよくわからない場合は、「最適な解像度を検出する」ボタンを選択してください。
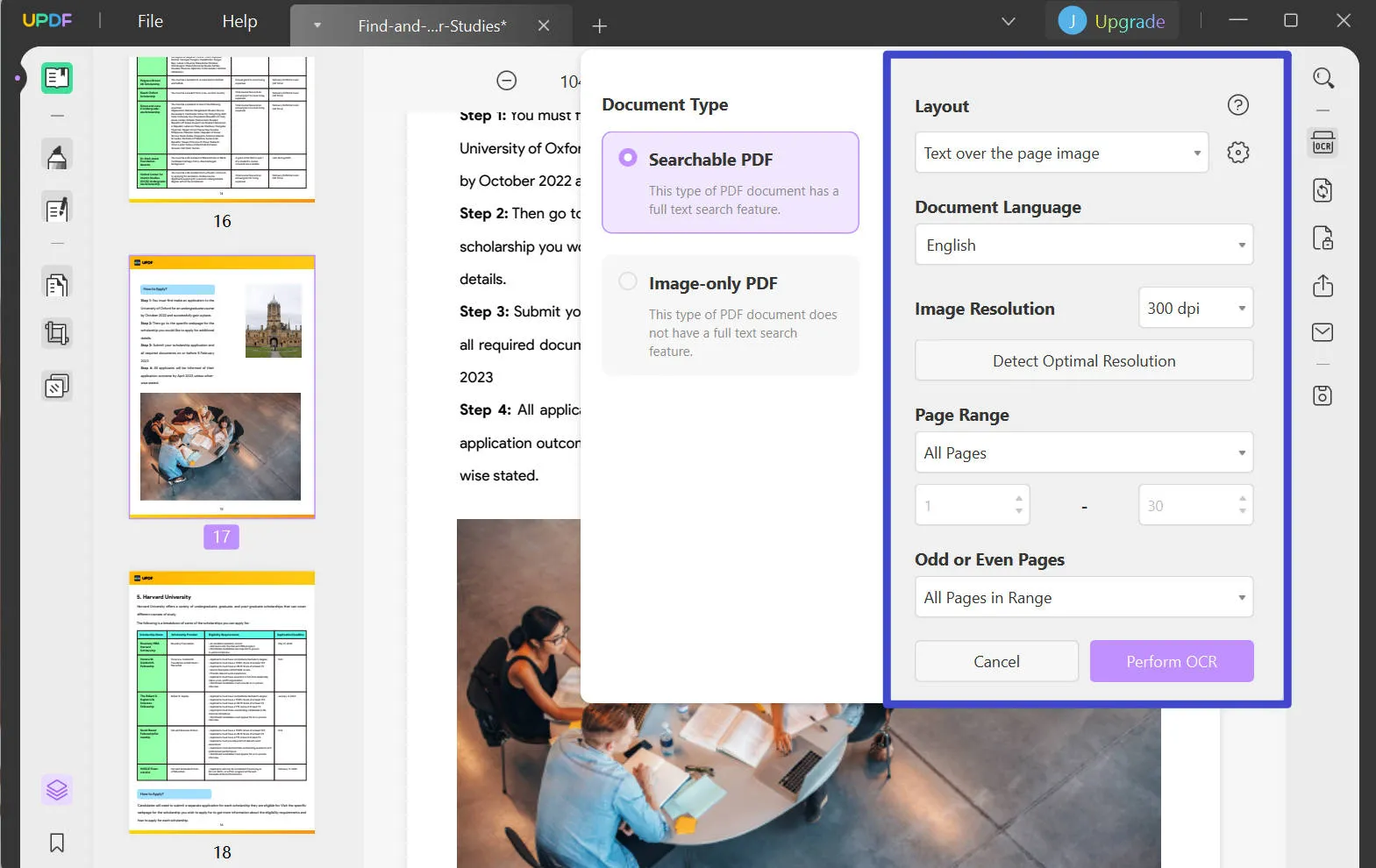
ステップ3: PDF内のテキストをOCR認識する方法
OCRを実行する必要があるドキュメントの特定のページ範囲を指定し、OCRを実行するために「OCRを実行します」ボタンをクリックします。PDF内のテキストを認識するには、変換されたドキュメントの保存場所を指定し、「保存」をクリックする必要があります。
Windows • macOS • iOS • Android 100%安全
方法2. Adobe Acrobatを使用してPDF内の文字を認識する方法
PDFファイルの作成、編集、読み取りに関しては、Adobe Acrobatが標準的なアプリです。MacまたはPC上でドキュメントを迅速にOCRする必要がある場合は、Adobeの文字認識を使用するのが最適なアプリケーションです。
- Adobe Acrobat Pro DCを起動し、ファイルを開きます。
- 右側のサイドバーで、「スキャンとOCR」を選択します。
- 「テキストを認識」オプションがフローティングツールバーに表示されます。
- これにアクセスするには、ドロップダウンメニューからそれを選択し、「このファイル内」をクリックします。
- ツールバーにアクセスするには、「設定」を選択します。
- 最終的な画像のサイズを小さくするには、「出力」として「検索可能な画像」を選択し、「ダウンサンプル先」として「600dpi」を選択します。OCR処理後、ファイルサイズは小さくなります。
- ファイルサイズを気にしない場合は「検索可能な画像(正確)」をご利用ください。OCR処理後の出力は、元のドキュメントに可能な限り近くなります。
- OCRは、青色の「テキストを認識」アイコンをクリックすると開始できます。
- 完了したら、もう一度「テキストを認識」をクリックします。
- ドロップダウンメニューをクリックし、「認識されたテキストの修正」を選択します。
- Acrobatが誤読の可能性があるテキストを検出した場合、そのテキストが赤色で強調表示されます。
- 赤いボックスの外側には認識の不正確さが存在する可能性があります。Acrobatでは、ページの画像を表示するのではなく、左上で検索するオプションを選択すると、検索される可能性のあるテキストレイヤーが表示されます。
- ページの画像を再度表示したい場合は、「レビュー」ボックスのチェックを外すか、「キャンセル」をクリックしてください。
- テキストが適切に識別されるまで続けます。正確に識別されたテキストは赤色で強調表示されません。
方法3. Bluebeamで文字を認識する方法
Bluebeam Revuの作成、編集、測定、マーキングのためのプロフェッショナルなデザインツールは、世界中の建築家、エンジニア、その他の専門家に愛用されています。プログラムのインターフェイスは暗く、開くといくつかの描画ツールに囲まれています。
- 「ファイル」>「開く」を選択して、認識可能なファイルをロードします。
- OCRダイアログボックスには、さまざまなタブと設定が含まれています。
- 14の言語とドキュメントの種類を選択できます。さらに、「ファイル」タブを使用してファイルをアップロードすることもできます。
- 「OK」ボタンをクリックして、テキスト認識ツールの使用に進むことができます。
- 「編集」>「PDFコンテンツ」>「テキストの選択」を選択して、検索可能なPDF内のテキストを検索してコピーします。
- これで、ページ上のほとんどのテキストにアクセスできるようになります。

OCR文字認識の3つの方法の比較
PDF内の文字をOCRする3つの方法を紹介した後、どの方法を選択すればよいか迷ってしまいますよね? 心配しないでください。ここでは、賢明な決定を下すための比較表を作成します。
| UPDF | Adobe Acrobat DC Pro | Bluebeam | |
| 使いやすさ | 使い方は非常に簡単で、たった3つのステップでPDF内のOCRテキストを作成できます。 | PDF内のテキストをOCRするための多くの手順があり複雑 | 普通 |
| OCR機能付きの価格 | 39. 99米ドル/年 59. 99米ドル/永久 | 239. 88米ドル/年 | 基本: 240米ドル/年 コア: 300米ドル/年 コンプリート: 400米ドル/年 |
| OCR言語 | UPDFはOCR用に38言語をサポートしています。(ドキュメントに複数の言語がある場合は、複数の言語を選択することもできます) | 12ヵ国語 | 14ヵ国語 |
| ユーザーインターフェース | 美しくて使いやすい | 普通 | 古風 |
| 概要評価 | 4. 9 | 4. 8 | 4. 0 |
3つのツールをすべて比較した結果、UPDFはPDF内のテキストをOCRする最も簡単な方法であるだけでなく、快適なインターフェイスを備えた最もコスト効率の高いソリューションであることがわかります。迷わずお選びください。
オンラインで無料のPDFテキスト認識はあるのかと疑問に思う人もいるかもしれません。実際には、役立つツールがいくつかあります。ただし、オンラインでPDF内のテキストを認識すると品質が低いことが判明したため、この記事では説明しませんでした。最良の結果を確実に得るために、安定したデスクトップソリューションを使用してOCRテキスト認識を実行することを常にお勧めします。
まとめ
PDF内の文字を認識するためにこれらすべての方法が利用できるため、UPDFを使用することをお勧めします。高速、安全、信頼性が高いです。UPDFは、スキャンしたPDFドキュメントを編集可能なドキュメントに変換することでPDF内のテキストを認識できるOCRツールを提供します。OCRツールではダイナミクスが異なるため、UPDFの機能に特別な追加機能が加えられます。
Windows • macOS • iOS • Android 100%安全