Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
PDF形式は、ビジネスでよく使われている形式である。ビジネスの重要なデータのほとんどがPDFに保存されているため、PDFからテキストを抽出することがよくあり、しかもさらに必要となるのではないかと思います。
ただし、特にPDFファイルがスキャンされたものから作成されたものである場合、適切な方法がなければ、そのPDFでのテキストのコピー、抽出、編集が不可能でしょう。それで、実行が難しいと感じるかもしれません。
OCRを使用してPDFからテキストを抽出するという方法をご存知の方もいるかもしれません。しかし、OCRを使用する場合は何ですか、OCRがなければどうでしょうかと心配している方もいるでしょう。
この記事では、OCR機能を使用する場合と使用しない場合のPDFからテキストを抽出する方法についての解決策を説明します。ご確認してください。
方法1.OCRを使用してPDFからテキストを抽出する方法
PDFファイルがスキャナーまたは画像によって作成された場合、PDFからテキストを抽出するにはどうすればいいですか?
一般的に使用される方法は、OCRツールを備えたPDFエディターを使用することです。
ここでは、UPDFを使用して、スキャンされたPDFまたは画像ベースのPDFからテキストを抽出する方法を説明します。

UPDFは、小規模で作業する個人のニーズだけでなく、大規模な組織のニーズを満たす完全なPDFファイルソリューションを提供する革新的なPDFエディターです。PDFファイルの編集、変換、結合、注釈付けなど、必要な機能をすべての提供します。
スキャンしたPDFからテキストを抽出する場合は、OCR機能を提供するUPDFを使用できます。以下に示す手順に従ってください。
ステップ1.UPDFをダウンロードしてインストールする
まず、UPDFをダウンロードし、以下のガイドに従って、スキャンしたPDFからテキストを抽出する方法を学んでください。
Windows • macOS • iOS • Android 100%安全
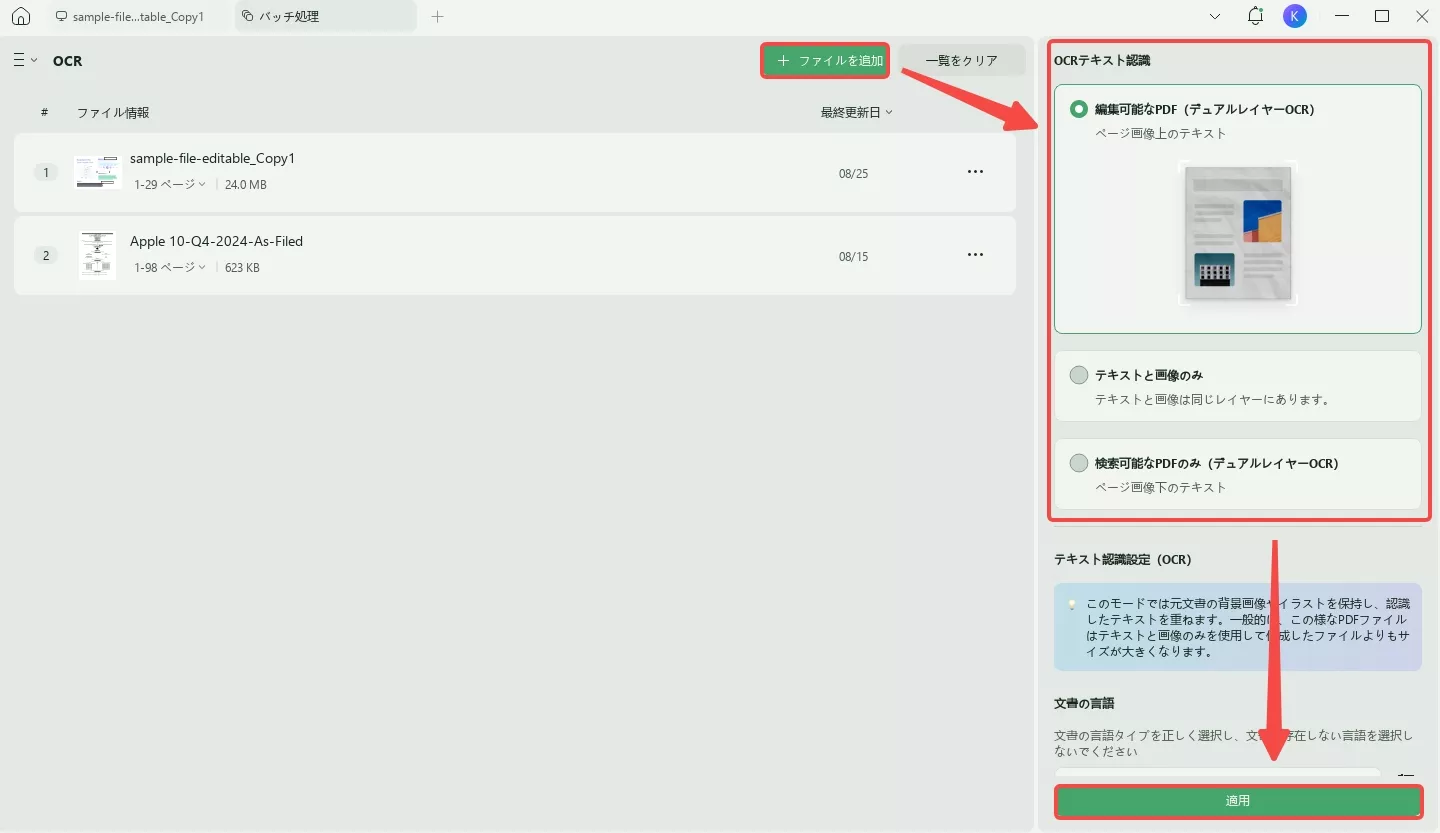
ステップ2:OCR機能にアクセスする
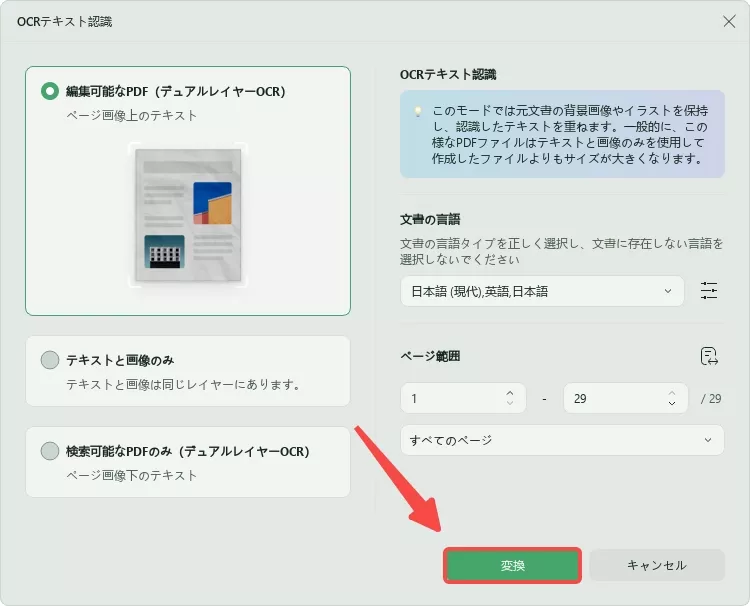
UPDFでPDFを開き、左上隅にある「ツール」で「OCR」ボタンを押すことで開始できます。
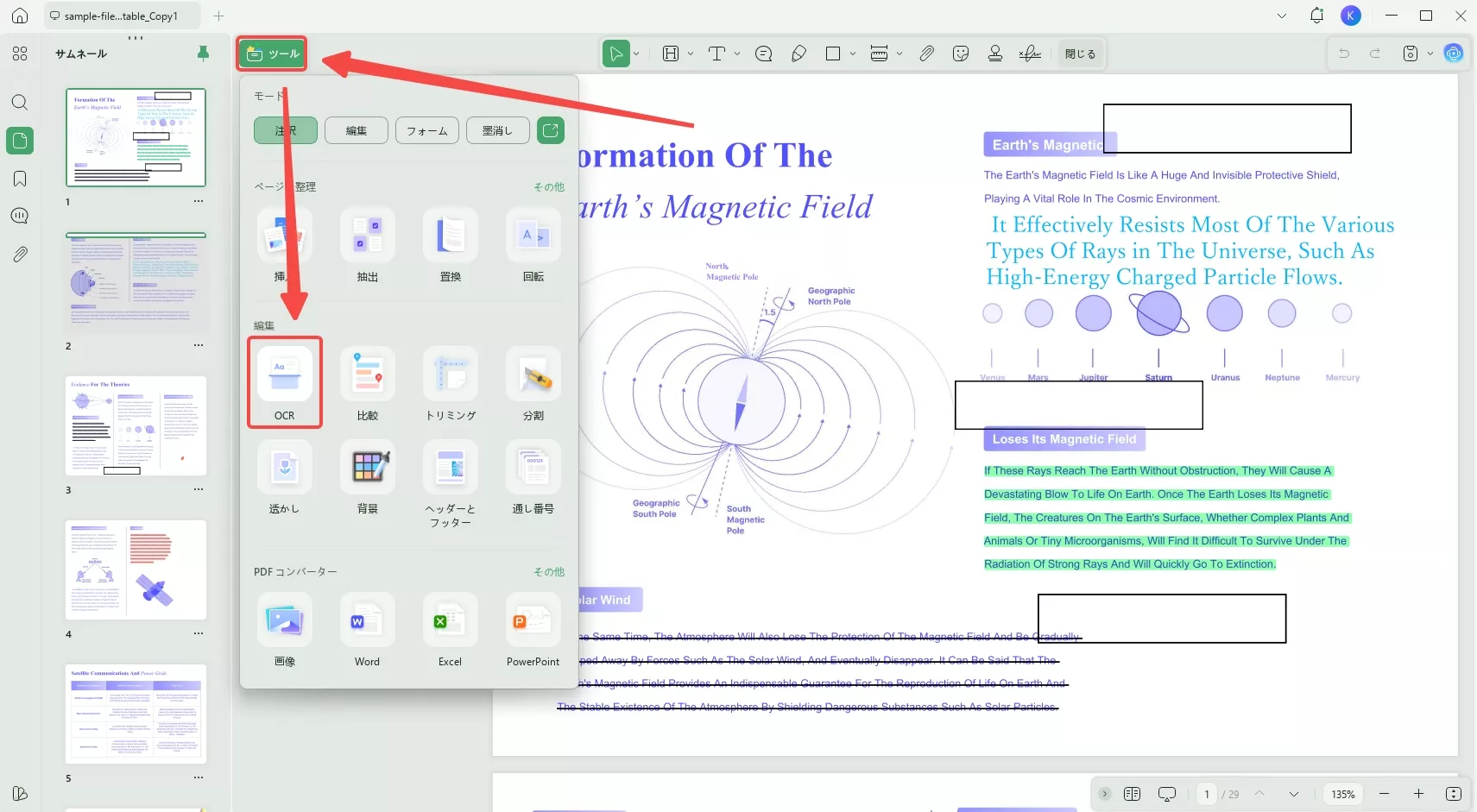
ポップアップウィンドウで「テキストと画像のみ」、「ページ画像上のテキスト」、または「ページ画像下のテキスト」を選択します。
また、注意すべき高度なレイアウトオプションがある場合は、必要に応じて「文書の言語」の右側にあるアイコンを選択し、オプションを操作します。
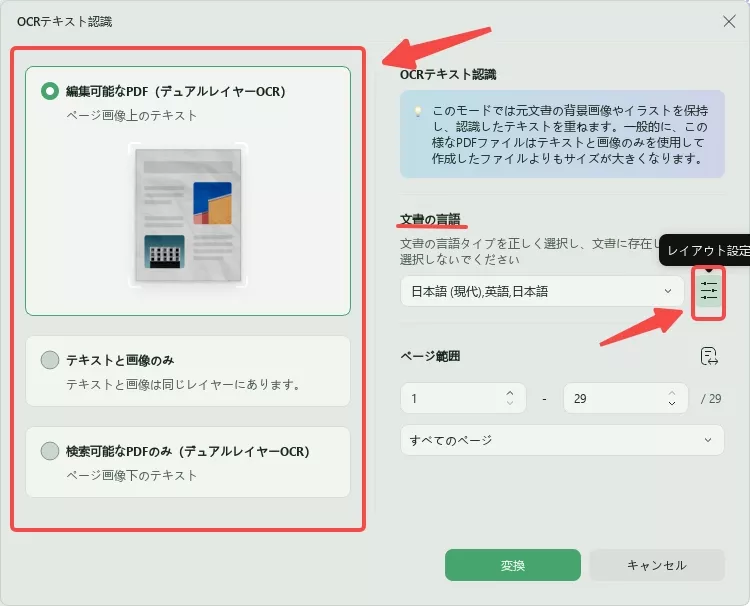
「文書の言語」には、使用可能な38種類の言語が選択できます。これに続いて、「画像解像度」設定に取り組み、付属のリストから特定の値を設定します。
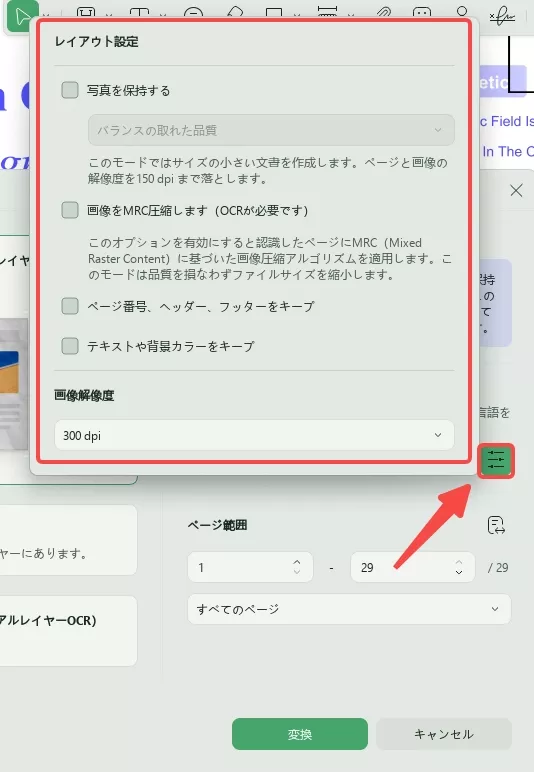
ステップ3:OCRを正常に実行する
OCRツールを実行するページ範囲を選択します。次に、「変換」ボタンを選択し、OCRドキュメントを保存する場所を選択して、プロセスを実行します。完了すると、UPDFが開き、PDFからテキストを抽出できます。
ステップ4.PDFからテキストを抽出またはコピーする
これで、PDF内でコピーして抽出したいテキストをクリックして選択し、それらをコピーして希望の保存先に貼り付けることができます。
✎関連記事:写真の文字を高速かつ正確にコピーする
✎関連記事:簡単でPDFから画像をコピーする方法
方法2.PDFからWord/Excel/その他の形式にテキストを抽出する方法
PDF内の一部のテキストをコピーする必要がある場合は、上記の方法が適していることがわかります。PDFからすべてのテキストを抽出する必要がある場合は、時間がかかります。
UPDFを簡単に使用する方法があります。その方法については、こちらをご覧ください。
ステップ1.PDFを開いて「PDFコンバーター」オプションへ移動する
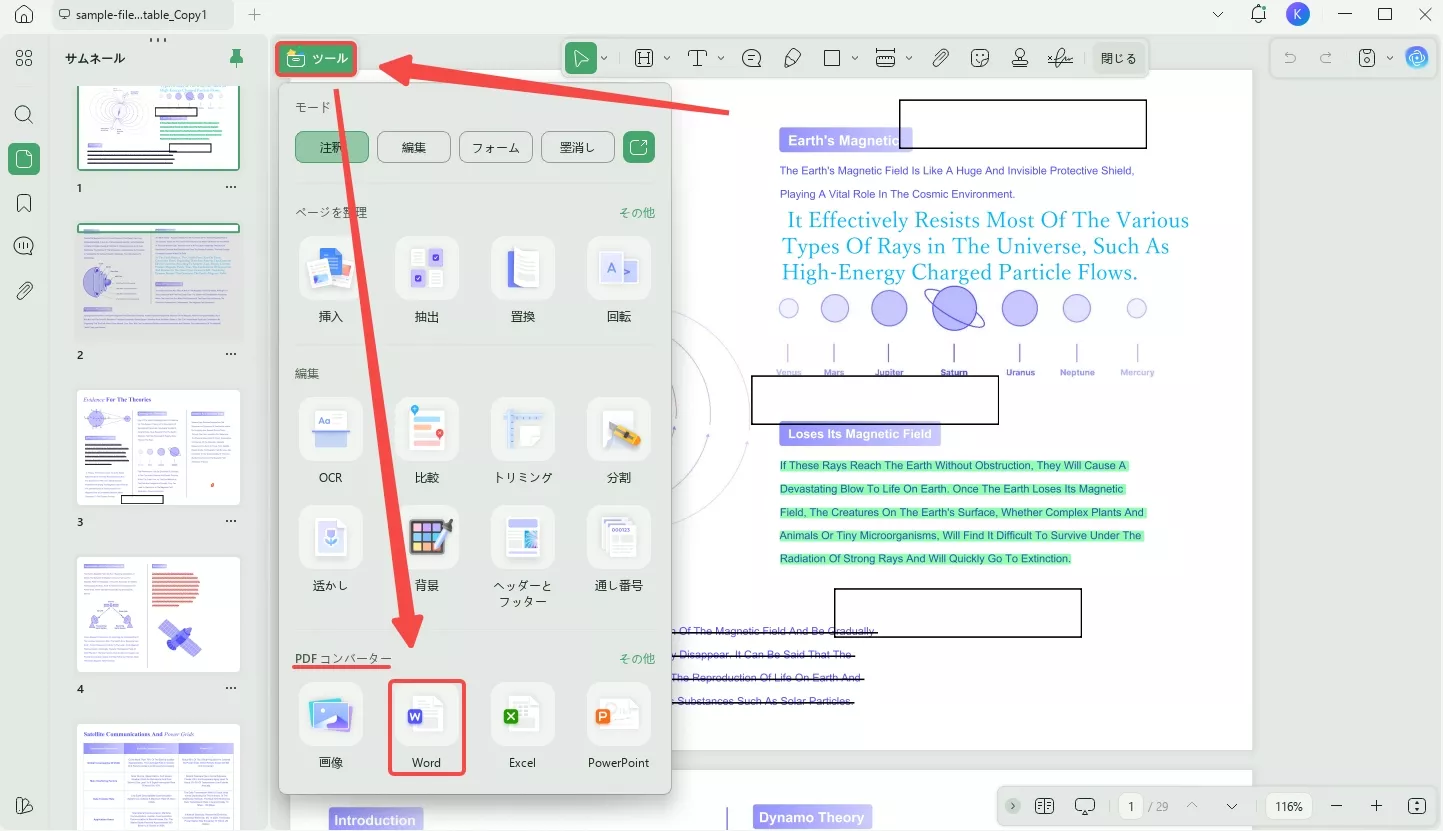
コンピュータ上でUPDFを起動し、「ファイルを開く」をクリックしてコンピュータからPDFを選択して開きます。
左上隅にある「ツール」で「PDFコンバーター」へ移動し、変換したい形式のアイコンをクリックします。ここでは例として「ワード」を選択します。
注意:
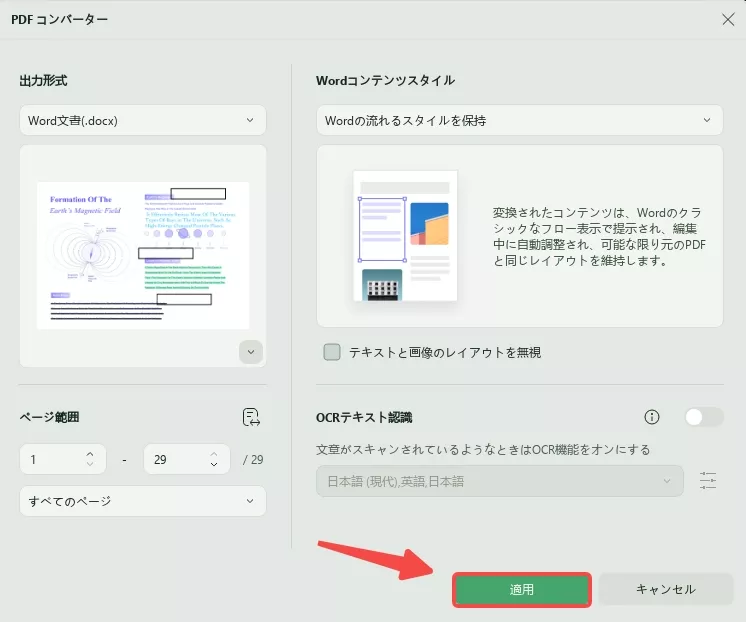
ステップ2.PDFをExcel/Word/任意の形式に変換する
形式を選択した後、必要に応じて新しいウィンドウでページ範囲を設定できます。すべて完了したら、「適用」ボタンをクリックし、変換されたファイルを保存する場所を選択します。
このプロセスが完了すると、スキャンされたPDFからすべてのテキストがExcel、Word、または必要な形式に正常に抽出されます。コンピュータ上で編集可能なファイルを開いて、任意の操作を行うことができます。
方法3.PDFからテキストをバッチ抽出する方法
UPDFを使用すると、単一ファイルからのテキストの抽出をいくつかの手順で行うことができます。
しかし、複数のPDFファイルからテキストを抽出するにはどうすればよいでしょうか?こちらでも対応させていただきます。
もし、UPDFをまだダウンロードしない場合、まず以下のボタンをクリックして、このツールをダウンロードします。
Windows • macOS • iOS • Android 100%安全
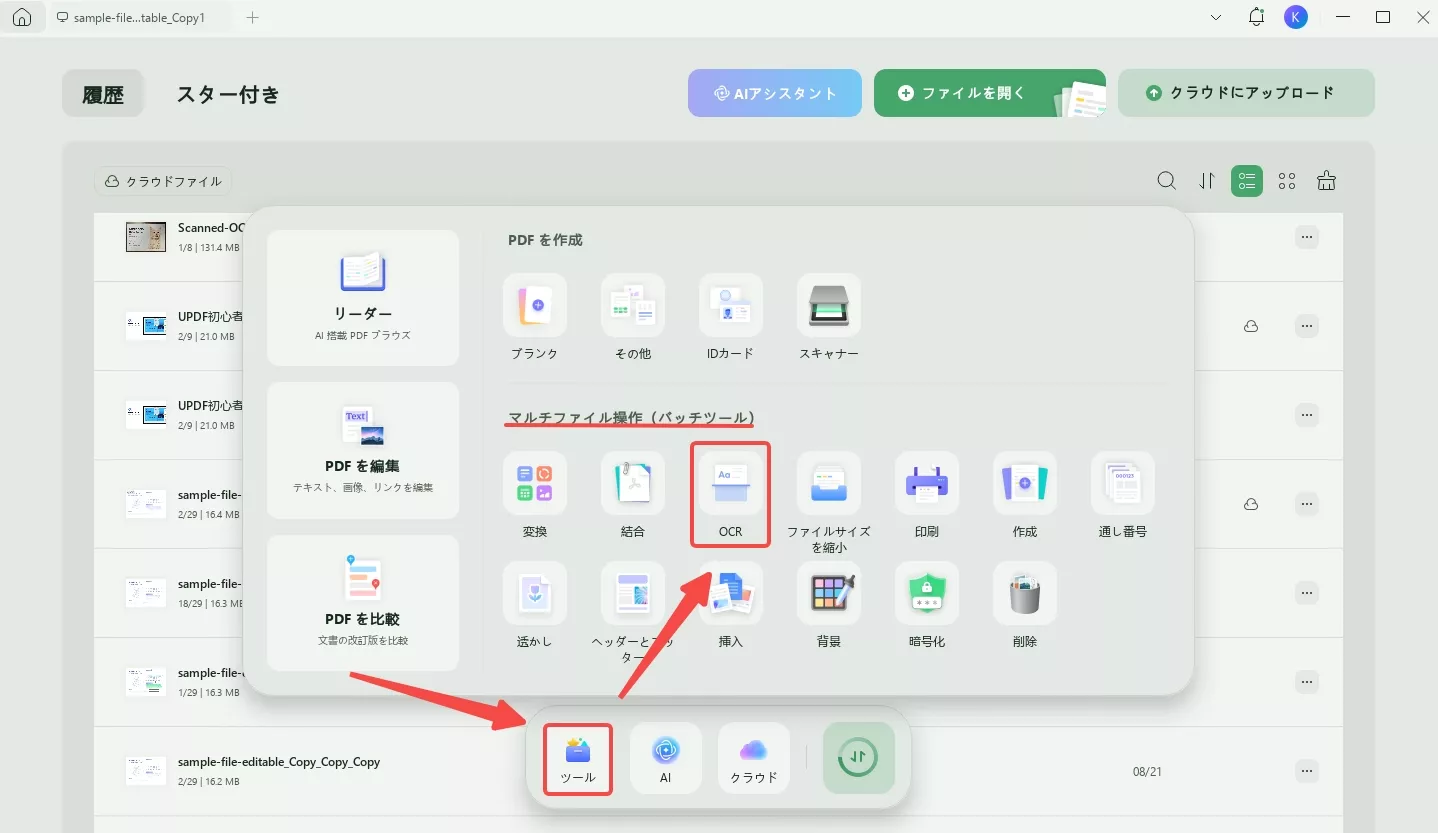
ステップ1.UPDFを起動する
デスクトップ上のUPDFアイコンをダブルクリックして実行します。ホーム画面に「ツール」をタブし、「マルチファイル操作(バッチツール)」へ移動し、「OCR」アイコンをクリックします。
ステップ2.複数のPDFファイルにOCRを行い、テキストを抽出できるようにする
新しいウィンドウで、OCRに関する設定を変更し、「適用」をクリックし、保存する場所を選択して、「保存」をクリックしてプロセスを実行します。
完了すると、ポップアップの場所に編集可能なファイルが表示されます。
方法4.OCRを使用せずにPDFからテキストを抽出する方法
以上の手順で、OCRはPDFからテキストを抽出する優れた方法ではないかと思います。
ただし、通常のPDFを持っていてテキストを抽出したい場合や、OCR機能を使用できない場合もあります。
理由が何であれ、OCRを使用せずにPDFからテキストを抽出する方法も必要ではないかと思います。ここでは、OCRを使わない方にとって効果的な3つの方法を紹介します。
スキャナーや画像で作成されたPDFファイルではなく、通常のPDFファイルを使用している場合は、UPDF編集機能を使用してPDFからテキストを抽出できます。その方法は次のとおりです。
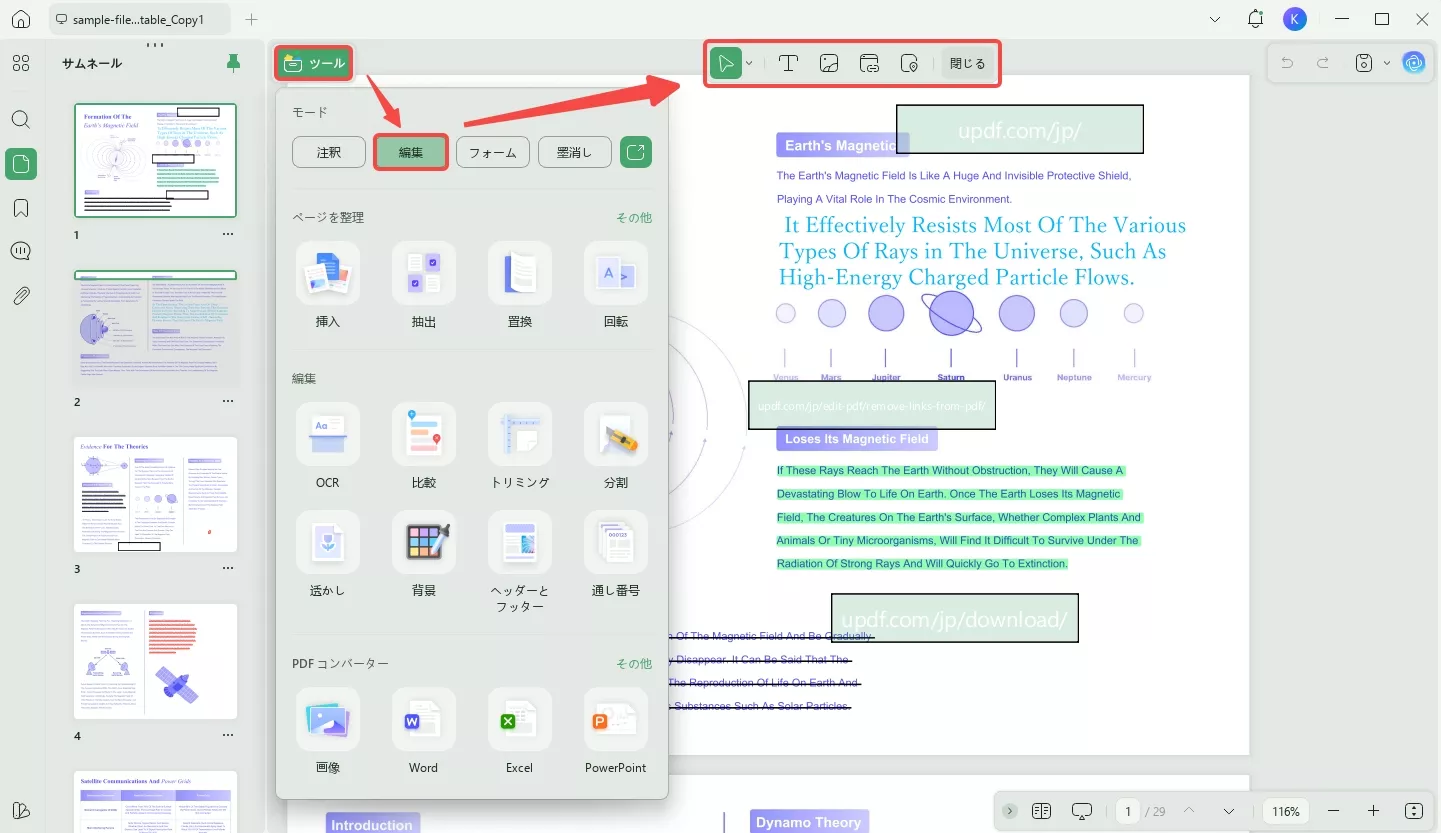
ステップ1:編集モードに移動する
最初のステップは、テキストを抽出するPDFファイルをUPDFで開くことです。これを行うには、UPDFインターフェースの中央にある「ファイルを開く」ボタンをクリックします。
PDFをUPDFにインポートした後、左上隅にある「ツール」をクリックして、「編集」タブをクリックしてファイルに編集モードを適用します。
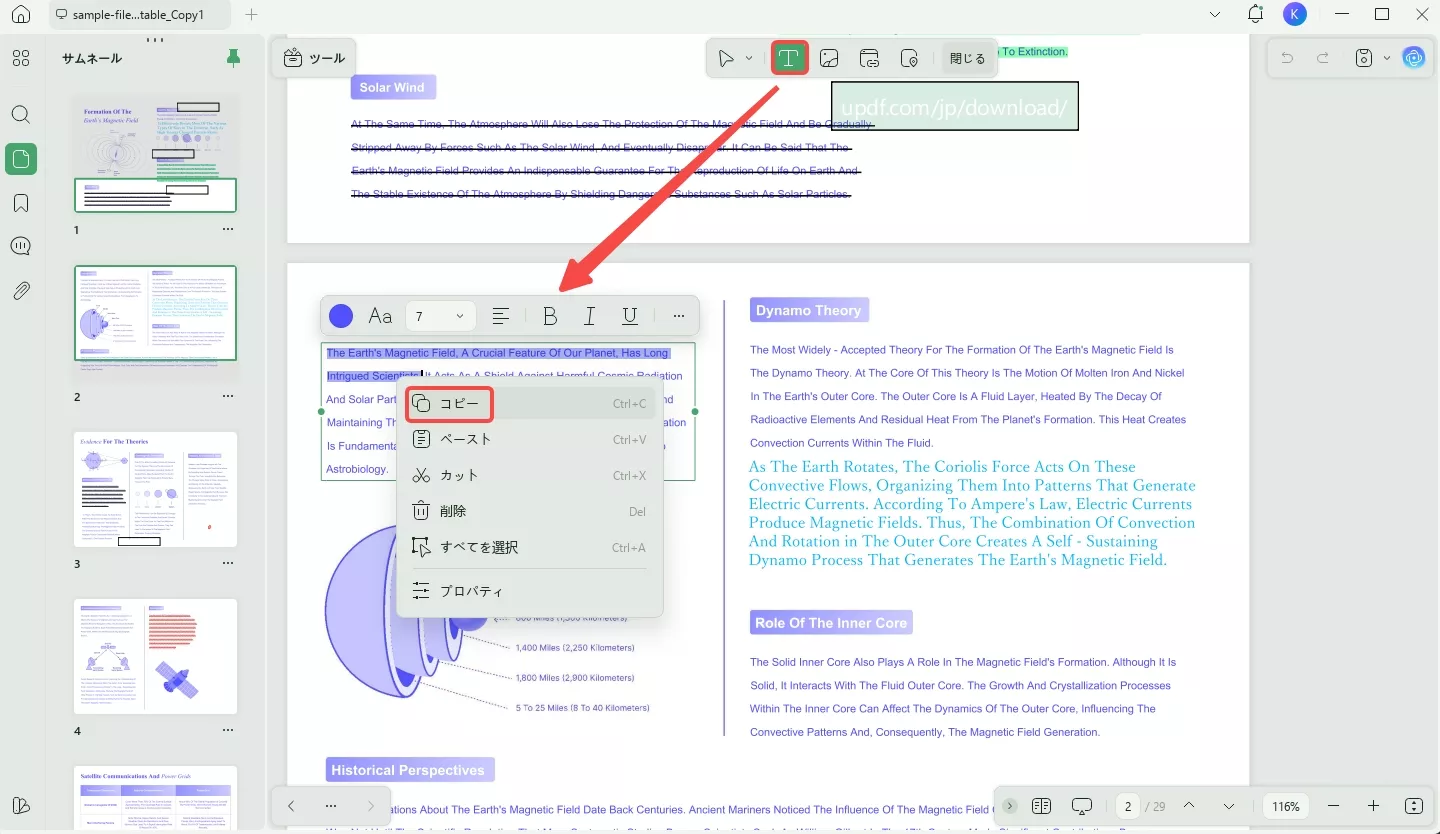
ステップ2:PDFから単語を抽出する
次に、「テキストを挿入&編集」ボタンをクリックします。
そして、PDFから抽出したいテキストを右クリックして選択し、「コピー」オプションをクリックするか、「Ctrl+C」ショートカットを使用します。
テキストをコピーした後、抽出したテキストをWordファイルまたは他のファイル形式に貼り付けることができます。
さらに、UPDFはMac、Windows、iOS、Androidデバイスで利用でき、すべてのプラットフォームでひとつのライセンスをサポートしているため、さまざまなオペレーティングシステムのユーザーにとって理想的なソリューションとなります。
PDFからテキストを抽出する以外にも、UPDFには他にも多くの機能があります。その主な機能の一部を次に示します。
UPDFの主な機能:
UPDFはユーザーにさまざまな重要な機能を提供し、日常的なPDFエディタです。これらの機能の一部を以下に示します。
- PDFを画像、Word、Excel、PPT、その他必要な形式に変換:UPDFは、PDFをあらゆるファイル形式に変換する機能をサポートしています。PDFからテキストをWord、Excel、またはその他の形式に直接抽出する必要がある場合、これを使用すると手間なく実行できます。
- PDFテキストの編集、画像、テキスト、リンクのPDFへの追加:UPDFを使用すると、PDFテキストの編集、フォント、色、サイズの変更、画像サイズの変更、テキスト、画像、リンクのPDFへの追加が可能です。
- PDFに注釈を付ける:付箋、テキストコメント、ハイライト、取り消し線、下線、図形、ステッカーなどのコメント機能をPDFに追加します。
- PDFの管理と整理:UPDFは、ページの挿入、削除、抽出、分割、およびページの回転をサポートします。
- 開くパスワードと許可パスワードを追加する:UPDFでは、ユーザーがPDFファイルにパスワードを追加して、重要なPDFドキュメントやフォームに追加のセキュリティ層を追加することもできます。
- PDFをスライドショーで再生します。
UPDFの素晴らしい機能をすべて学んだ後、この強力なソフトウェアをどこからダウンロードできるのか疑問に思うかもしれません。以下の「無料ダウンロード」ボタンをクリックして、今すぐインストールしてください。
Windows • macOS • iOS • Android 100%安全
方法5.Googleドライブを使用してオンラインでPDFからテキストを抽出する方法
PDFからテキストを抽出したい場合は、書式が壊れても構わないなら、Googleドライブを試すこともできます。
ユーザーは、ソフトウェアをダウンロードしたりインストールしたりしなくても、PDFからテキストやその他の要素を簡単に抽出できます。
PDFファイルからテキストを抽出する他の方法と比較して、簡単、便利、信頼性の高い方法です。Googleドライブの方法を使用してオンラインでPDFファイルから情報を抽出する手順を以下に説明します。
ステップ1:インターネットブラウザでGoogleドライブにアクセスし、「新規」タブをクリックします。
次に、ドロップダウンメニューから「ファイルのアップロード」をクリックして、コンピューターからPDFファイルを参照し、Googleドライブにアップロードします。
ステップ2:PDFファイルがアップロードされるとすぐに、マイドライブに表示されます。
アップロードしたPDFファイルを右クリックし、「プログラムから開く」をタップし、続いて「Googleドキュメント」を選択してGoogleドキュメントでPDFを開きます。
ステップ3:GoogleドキュメントでPDFファイルを開くと、PDFファイル上のテキストが自動的に編集可能になり、オンラインでPDFからテキストを無料で簡単に抽出できます。

✎関連記事:簡単!GoogleドキュメントでPDFを編集する方法
方法6.PythonでPDFからテキストを抽出する方法
PythonがPDFからテキストを抽出するソースにもなるなんて、想像したでしょうか?コンピューターを使用していてPythonを頻繁に使用する場合は、PyPDF2パッケージを使用してこのタスクを実行できます。
この方法について詳しく知るには、以下に提供されているスクリプトに従う必要があります。
from PyPDF2 import PdfReader
reader=PdfReader("example.pdf")
page=reader.pagers[0]
text=page.extract_text()
print(text)
✎関連記事:Pythonを使ってPDF編集はどうやるのか?
よくある質問
1.PDF画像からテキストを抽出できますか?
はい、UPDFが提供するOCR機能を使用してPDF画像からテキストを抽出できます。
PDF画像をUPDFにインポートし、UPDFウィンドウの左上隅にある「ツール」で「OCR」アイコンをクリックします。
「OCR」をクリックした後、「変換」オプションを選択して、PDF画像から編集可能および検索可能なPDFへの変換プロセスを開始します。変換が完了するとすぐに、PDF内のテキストを抽出できます。
2.Acrobatを使用せずにPDFからテキストを抽出する方法は何ですか。
Adobe Acrobatの代わりにUPDFを使用してPDFからテキストを抽出できます。これは、よりコスト効率が高く、高速で直感的なソリューションであるためです。Mac、Windows、Android、iOSで動作します。
3.Linux上でPDFからテキストを抽出できますか?
はい、LinuxオペレーティングシステムのGoogleドライブ方式やPDF24ツールOCR機能など、市販のさまざまなオンラインツールを使用して、Linux上のPDFからコンテンツを抽出できます。
結論
OCRありまたはOCRなしでPDFからテキストを抽出するために市場には多くのオプションが用意されていますが、最も信頼性の高い選択は、PDFファイル専用の有名なツールを使用することです。
それに関して、UPDFはタスクを効率的かつ正確に完了するだけでなく、データを安全に保ち、PDFを編集し、PDFを変換するなどのサポートを提供するため、最良の選択です。
今なら特別オファーがあり、今すぐUPDF Proにアップグレードできます。WindowsコンピューターまたはMacBookにUPDFを今すぐダウンロードして、満足のいくユーザーエクスペリエンスを活用することもできます。
Windows • macOS • iOS • Android 100%安全