 Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF Nomostar
Nomostar UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
OCR機能
UPDFのOCR機能を使用すると、PDF文書のスキャンされたテキストを検索・編集可能なコンテンツに変換できます。
この機能を使用すると、画像上のテキストも編集できるため、ユーザーが文書をインタラクティブに操作できるようになります。
下のボタンをクリックして、テキストガイドまたはビデオガイドに従ってPDFのOCR処理を行ってください。
Windows • macOS • iOS • Android 100%安全
1. OCRのダウンロードとインストール方法
該当する文書を開いたら、画面左上の「ツール」オプションに移動します。 「ツール」メニューから「OCR」オプションを選択して処理を開始します。UPDF OCRを初めて使用する場合は、OCRをインストールするためのウィンドウがポップアップ表示されます。
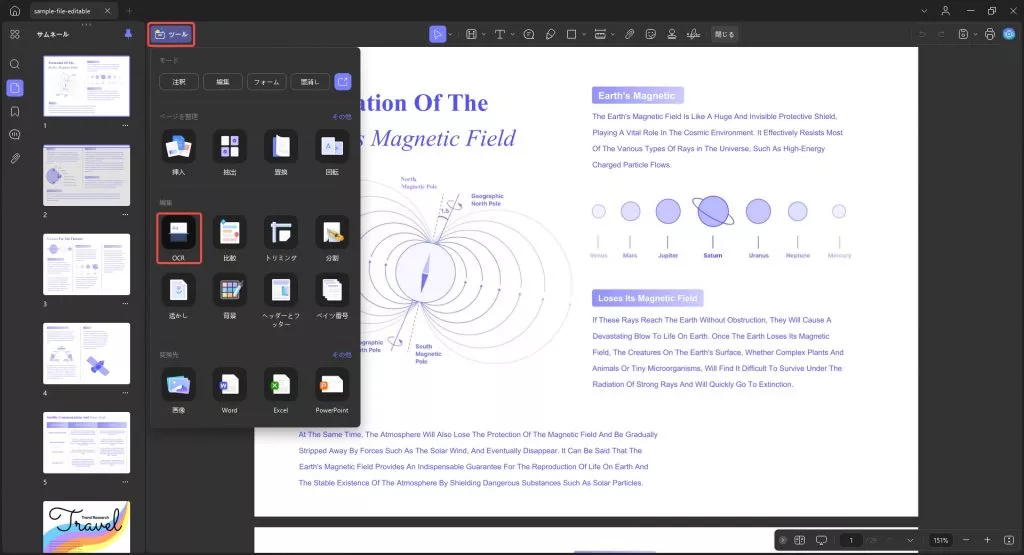
2. PDFをOCR処理する方法
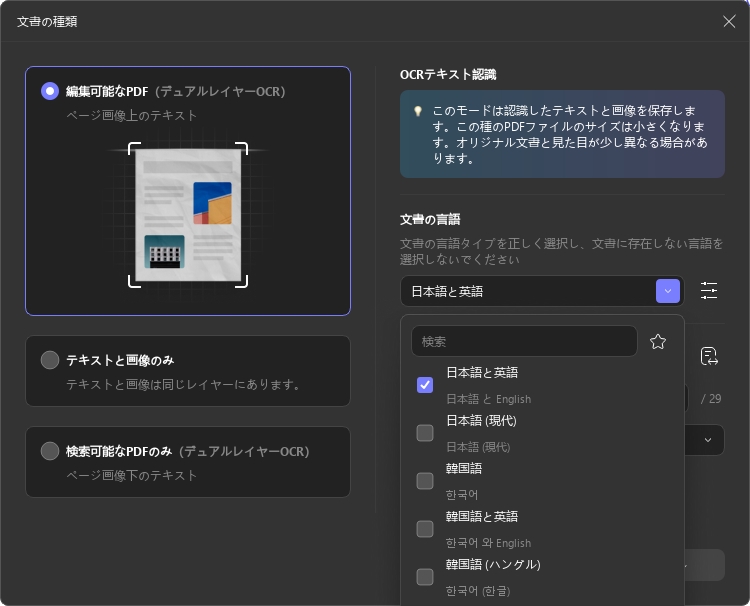
インストールが完了したら、ウィンドウを閉じて、UPDF全体でOCRツールにアクセスするための同じ「ツール」オプションに移動します。ツールが開くと、編集可能なPDF、テキストと画像のみ、検索可能なPDFのみの3つの異なるドキュメントタイプのオプションが表示されます。
- 編集可能なPDF:このモードでは、認識されたテキストと画像が保存されます。このタイプのPDFファイルは比較的サイズが小さく、見た目は元の文書と若干異なる場合があります。
- テキストと画像のみ:このモードでは、元の文書の背景画像とイラストはそのまま残り、認識されたテキストが重ねて表示されます。通常、このモードで作成されたPDFファイルは、「テキストと画像のみ」モードで作成されたPDFファイルよりもサイズが大きくなります。見た目は元の文書と若干異なる場合があります。
- 検索可能なPDFのみ:このモードでは、ページ画像は保持され、認識されたテキストは画像の下の非表示レイヤーに配置されます。視覚的には、この文書は元の文書とほぼ同じです。2.1 文書タイプ:検索可能なPDF
ドロップダウンメニューから38種類の言語を選択し、適切な文書言語を定義します。これにより、UPDFは文書全体のテキストを正確に認識できるようになります。
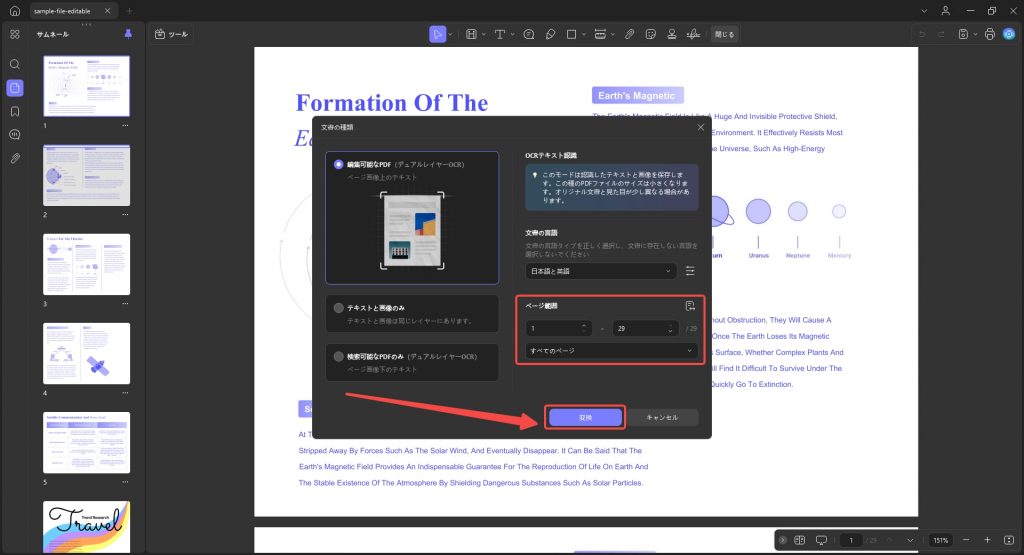
ページ範囲を手動で選択するか、メニューを展開してリストから「すべてのページ」「偶数ページ」「奇数ページ」のオプションを選択します。完了したら、 「変換」ボタンを押して、OCRを実行します。
無料トライアル版ではOCR機能を無料でお試しいただけます。ただし、OCR処理したPDFを保存、コピー、編集することはできません。必要な機能をすべてご利用いただくには、プロ版にアップグレードしてください。
Windows • macOS • iOS • Android 100%安全