UPDF para Windows
UPDF para Windows UPDF para Mac
UPDF para Mac UPDF para iPhone/iPad
UPDF para iPhone/iPad UPDF para Android
UPDF para Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Editar PDF
Editar PDF Anotar PDF
Anotar PDF Criar PDF
Criar PDF Formulário PDF
Formulário PDF Editar links
Editar links Converter PDF
Converter PDF OCR
OCR PDF para Word
PDF para Word PDF para Imagem
PDF para Imagem PDF para Excel
PDF para Excel Organizar PDF
Organizar PDF Mesclar PDF
Mesclar PDF Dividir PDF
Dividir PDF Cortar PDF
Cortar PDF Girar PDF
Girar PDF Proteger PDF
Proteger PDF Assinar PDF
Assinar PDF Redigir PDF
Redigir PDF Sanitizar PDF
Sanitizar PDF Remover Segurança
Remover Segurança Ler PDF
Ler PDF Nuvem UPDF
Nuvem UPDF Comprimir PDF
Comprimir PDF Imprimir PDF
Imprimir PDF Processamento em Lote
Processamento em Lote Sobre o UPDF AI
Sobre o UPDF AI Soluções UPDF AI
Soluções UPDF AI Guia do Usuário de IA
Guia do Usuário de IA Perguntas Frequentes
Perguntas Frequentes Resumir PDF
Resumir PDF Traduzir PDF
Traduzir PDF Converse com o PDF
Converse com o PDF Converse com IA
Converse com IA Converse com a imagem
Converse com a imagem PDF para Mapa Mental
PDF para Mapa Mental Explicar PDF
Explicar PDF Ferramentas de IA para PDF
Ferramentas de IA para PDF Ferramentas de IA para Imagem
Ferramentas de IA para Imagem Ferramentas de Chat com IA
Ferramentas de Chat com IA Ferramentas de Escrita com IA
Ferramentas de Escrita com IA Ferramentas de Estudo com IA
Ferramentas de Estudo com IA Ferramentas de Trabalho com IA
Ferramentas de Trabalho com IA Outras Ferramentas de IA
Outras Ferramentas de IA Geração de marcadores
Geração de marcadores Resumo de marcadores
Resumo de marcadores Geração de marca d’água
Geração de marca d’água Geração de fundo
Geração de fundo Geração de adesivos
Geração de adesivos Geração de carimbos
Geração de carimbos Suite de Redação
Suite de Redação UPDF Copilot
UPDF Copilot Gerenciamento de páginas
Gerenciamento de páginas Pesquisa Semântica
Pesquisa Semântica PDF para Word
PDF para Word PDF para Excel
PDF para Excel PDF para PowerPoint
PDF para PowerPoint Guia do Usuário
Guia do Usuário Truques do UPDF
Truques do UPDF Perguntas Frequentes
Perguntas Frequentes Avaliações do UPDF
Avaliações do UPDF Centro de Download
Centro de Download Blog
Blog Sala de Imprensa
Sala de Imprensa Especificações Técnicas
Especificações Técnicas Atualizações
Atualizações UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Precisa processar em lote PDFs digitalizados no Word? Preocupado com o custo do Adobe Acrobat ou os riscos de privacidade das ferramentas online? Projetos open-source no GitHub oferecem uma alternativa gratuita, então neste artigo vamos aprofundar se esse método é realmente adequado para nós, bem como suas vantagens, desvantagens e etapas operacionais detalhadas. E se você precisa de uma ferramenta profissional de OCR leve, fácil de usar e segura, este artigo ajuda você a escolher a abordagem certa de OCR.
Parte 1. Visão Geral de PDF ocr para Word do GitHub
As ferramentas de OCR para converter PDF para Word do GitHub escaneiam páginas e reconhecem o texto para criar documentos do Word editáveis a partir das digitalizações. Elas são flexíveis e privadas, mas mais difíceis de instalar, menos precisas e menos eficientes na preservação de layouts complexos. A maioria das opções funciona por meio de etapas e scripts de linha de comando para ajudar os usuários a se familiarizarem com os fluxos de trabalho técnicos. Agora, vamos explorar como essas ferramentas funcionam, onde elas são úteis e onde ainda apresentam limitações.
Princípios Técnicos
Essas ferramentas transformam cada página de PDF em imagens e, em seguida, reconhecem o texto contido nelas. Vamos detalhar o processo de funcionamento em algumas etapas técnicas simples.
- Conversão de Imagem da Página: No início, o programa transforma cada página do PDF em uma imagem nítida. Isso fornece ao motor de OCR dados visuais limpos, prontos para análise posterior.
- Detecção de Texto: Em seguida, o motor analisa cada imagem para identificar parágrafos, linhas individuais e possíveis blocos de texto. Elementos não textuais, como fotos e gráficos, são filtrados para manter o foco no conteúdo escrito.
- Reconhecimento de Caracteres: Nesta etapa, o modelo analisa as formas de letras e números e as associa a caracteres reais. O aprendizado de padrões linguísticos ajuda a reduzir erros e aumentar a precisão de palavras e frases completas.
- Exportação para Documento: Na etapa final, o texto reconhecido é salvo em formatos compatíveis com o Word e outros editores. O arquivo digitalizado, antes bloqueado, torna-se um documento totalmente editável, pronto para ajustes e formatação.

Prós e contras
Após termos discutido como funcionam as ferramentas do GitHub para converter PDF em Word, vamos destacar seus principais pontos fortes e fracos:
Prós
- Funciona totalmente offline para contratos confidenciais e documentos internos de negócios.
- Automatiza scripts para processar grandes lotes de PDFs semelhantes de forma eficiente.
- Frequentemente suporta vários idiomas por meio de modelos e configurações de OCR treinados pela comunidade.
- Os usuários podem integrá-lo em pipelines de desenvolvimento existentes, como tarefas de CI.
Contras
- Instalação frequentemente falha devido a dependências, versões e bibliotecas de sistema em falta.
- Layouts complexos com tabelas e colunas são exportados como texto desorganizado e desalinhado.
- Anotações manuscritas e digitalizações de baixa qualidade são reconhecidas de forma imprecisa, exigindo correções manuais.
- A linha de comando e os ficheiros de configuração confundem utilizadores não técnicos, aumentando o tempo de configuração e utilização.
Projetos de OCR de código aberto no GitHub oferecem uma solução gratuita, mas sofrem com baixa precisão, graves distorções de layout e exigem conhecimentos de programação. Experimente o UPDF para resolver esses problemas num único pacote integrado.
Windows • macOS • iOS • Android Seguro 100%
Comparação com ferramentas profissionais de OCR para PDF
As ferramentas profissionais de OCR focam-se na precisão, na preservação do layout e em interfaces simples. O UPDF segue essa abordagem profissional, combinando um OCR potente, design moderno e ferramentas diárias de PDF num único lugar. Agora vamos comparar estas opções com os típicos projetos de PDF para Word OCR no GitHub para ver onde cada um se encaixa melhor:
| Recurso | Projetos de OCR do GitHub | UPDF | Adobe Acrobat/ABBYY |
| Facilidade de instalação | Difícil, requer scripts e linha de comando (CLI) | Instalador simples, configuração guiada | Instalador padrão, com guia |
| Interface | Mínima ou nenhuma | Limpo, moderno e fácil de usar | Profissional, porém mais complexo |
| Precisão de OCR | Bom para páginas básicas | Em destaque na maioria dos documentos | Alto nível, nível empresarial |
| Preservação do Layout | Frequentemente fraco em layouts complexos | Forte em texto, imagens e tabelas | Focado em documentos |
| Processamento em lote | Depende dos scripts | Recursos de lote integrados | Ferramentas de lote integradas |
| Privacidade Offline | Sim | Sim, funciona offline. | Sim, mas existem funcionalidades na nuvem. |
| Funcionalidades extra de PDF | Limitado | Geração de marcadores com IA, assistente Copilot, edição com IA | Edição e gestão completas |
| Curva de Aprendizagem | Íngreme para não programadores | Fácil para utilizadores em geral | Menus complexos |

Parte 2. Configure rapidamente PDF para Word OCR no GitHub
Depois de encontrar as melhores ferramentas do GitHub para converter PDF em Word, vamos escolher de forma inteligente e rápida:
- OCRmyPDF: Esta ferramenta adiciona uma camada de texto oculta em PDFs digitalizados após o processamento das páginas. Ótima opção quando você precisa principalmente de PDFs pesquisáveis antes de convertê-los em documentos do Word.
- PaddleOCR: Oferece OCR de alta precisão e bom suporte multilíngue para documentos complexos ou desorganizados. Ideal para quem se sente confortável executando scripts em Python e criando fluxos de trabalho personalizados.
- Tesseract: Um mecanismo de OCR consolidado com forte apoio da comunidade e muitos exemplos de integração. Útil para tarefas básicas de OCR ou para adicionar OCR a ferramentas de software existentes.
- EasyOCR: Uma biblioteca Python leve que simplifica bastante a instalação e os primeiros testes. Uma ótima opção para experimentos rápidos ou projetos pequenos que ainda precisam de um OCR robusto.
- Pdf2docx: Projetado especificamente para converter conteúdo de PDF diretamente em arquivos DOCX editáveis do Word. Útil quando você se preocupa principalmente em preservar o layout e a formatação dentro do Word.
- DocTR: Utiliza modelos de aprendizado profundo para reconhecer texto em layouts de documentos complexos e estruturados. Ideal para formulários, relatórios e páginas com várias colunas que confundem mecanismos de OCR mais simples.
Exemplos de planos de configuração
Muitos usuários desejam exemplos claros de como combinar ferramentas em um fluxo de trabalho OCR funcional no GitHub. Agora, vamos descrever dois planos simples que mostram diferentes maneiras de construir esse tipo de fluxo de trabalho.
Plan A: OCRmyPDF + Pandoc
Este plano utiliza inicialmente o OCRmyPDF para adicionar texto pesquisável a arquivos PDF digitalizados localmente. Em seguida, o pandoc converte o PDF processado por OCR em um documento Word básico que você pode abrir e editar. Veja os passos abaixo para entender o fluxo:
Passo 1. Instale o OCRmyPDF e o Pandoc no seu computador usando os instaladores oficiais ou as instruções.
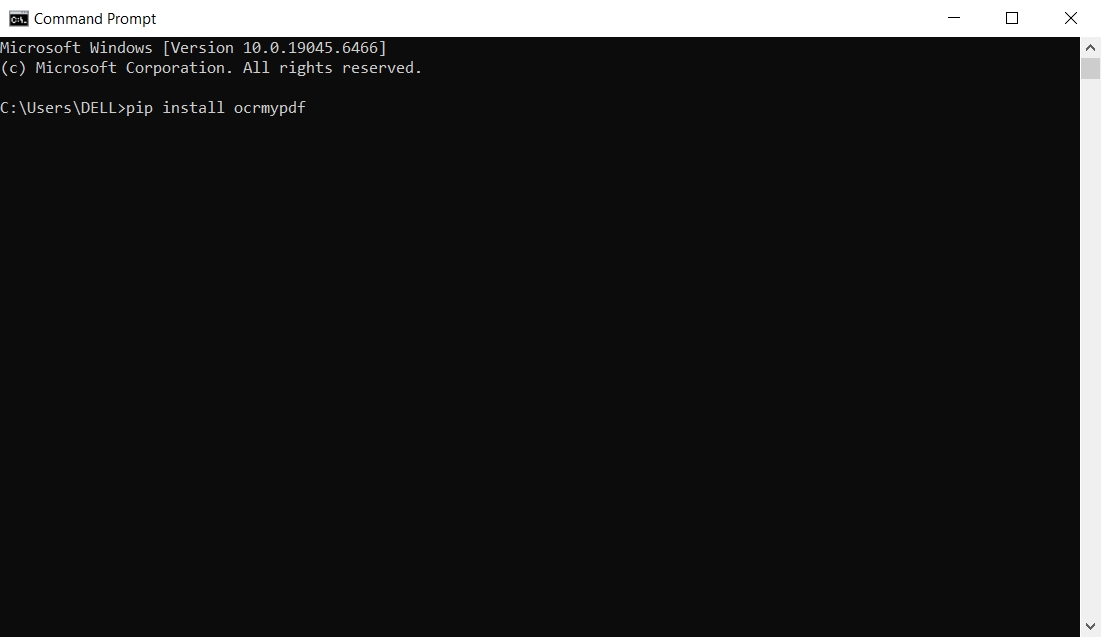
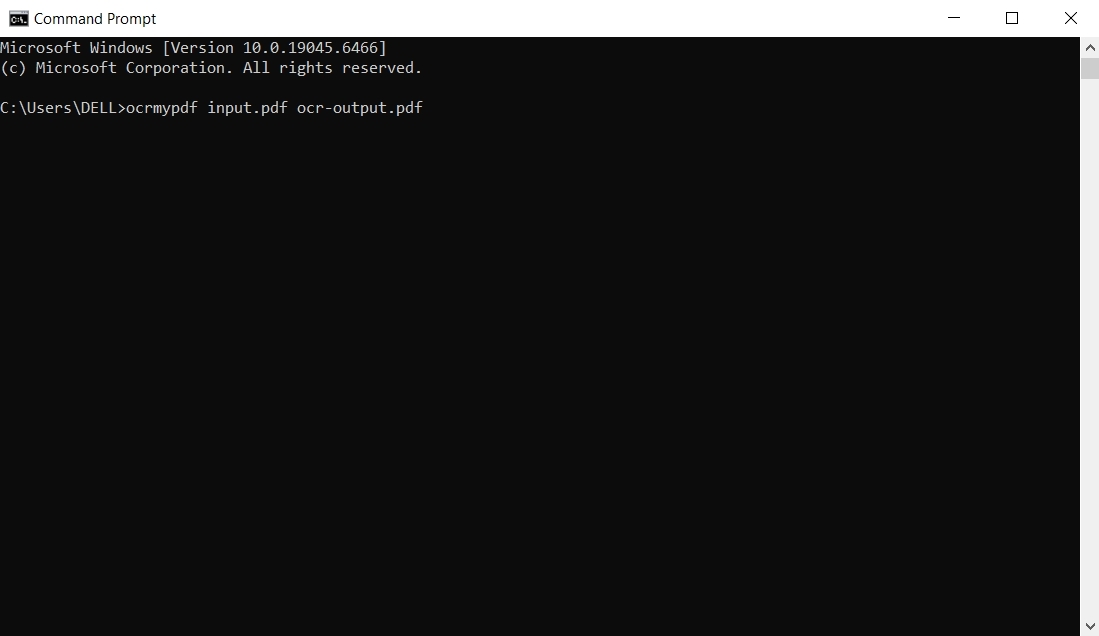
Passo 2. Coloque um PDF digitalizado em uma pasta simples e execute o OCRmyPDF para criar um PDF com OCR. Em seguida, use o Pandoc nesse PDF com OCR para gerar um arquivo Word básico.
Plano B: PaddleOCR + Python-docx
Este plano utiliza fluxos de trabalho de OCR em PDF com Python para ler texto de páginas digitalizadas com o PaddleOCR. O texto reconhecido é então adicionado a um novo documento do Word programaticamente, usando a biblioteca python-docx. Vejamos como essa configuração pode ajudar usuários que se sentem à vontade para escrever e executar scripts simples em Python:
Passo 1. Instale o PaddleOCR e o python-docx no Python usando o pip.
Passo 2. Abra o Bloco de Notas e cole o script. Em seguida, defina o nome do arquivo, escolha a opção “Todos os arquivos” e clique no botão “Salvar”.
Passo 3. Coloque o PDF digitalizado na área de trabalho e execute o script python ocr_to_word.py para criar o arquivo Word editável a partir das páginas digitalizadas.
Parte 3. Bônus: Ferramenta Profissional de PDF para Word OCR
Muitos usuários têm dificuldades com PDFs digitalizados que se recusam a ser convertidos corretamente em documentos editáveis. Conversores gratuitos frequentemente quebram a formatação, omitem texto ou ignoram completamente páginas com digitalizações de baixa qualidade. É aí que o UPDF entra em cena, oferecendo uma solução profissional e fácil de usar para conversão OCR confiável.
Ele combina um OCR poderoso com uma interface intuitiva para ajudar usuários sem conhecimento técnico a trabalharem sem preocupações. Ao contrário das complexas configurações de conversão de PDF para Word no GitHub, o UPDF mantém tudo em um só lugar com fluxos de trabalho visuais e guiados.
Principais Características
- Saída compacta: Produz ficheiros de menor tamanho, mantendo alta qualidade visual após o OCR.
- Suporte a idiomas: Reconhece 38 idiomas para um OCR preciso em diversos documentos.
- Alta precisão: Tecnologia avançada garante até 99% de precisão no reconhecimento de texto em digitalizações nítidas.
- Suporte de formatos: Exporta para Word, Excel, PowerPoint e ficheiros TXT editáveis.
- Processamento em lote: Envia e converte vários ficheiros em texto editável com um único clique.
- OCR de UPDF AI: Permite transformar texto baseado em imagem em ficheiros Word editáveis com um único clique.
Guia definitivo: Transformar PDFs digitalizados em Word com OCR
Depois de explorar uma alternativa robusta às ferramentas de OCR para PDF e Word do GitHub, você pode estar se perguntando como usá-la na prática. Siga os passos abaixo para converter seu PDF digitalizado em um documento Word editável usando o UPDF:
Windows • macOS • iOS • Android Seguro 100%
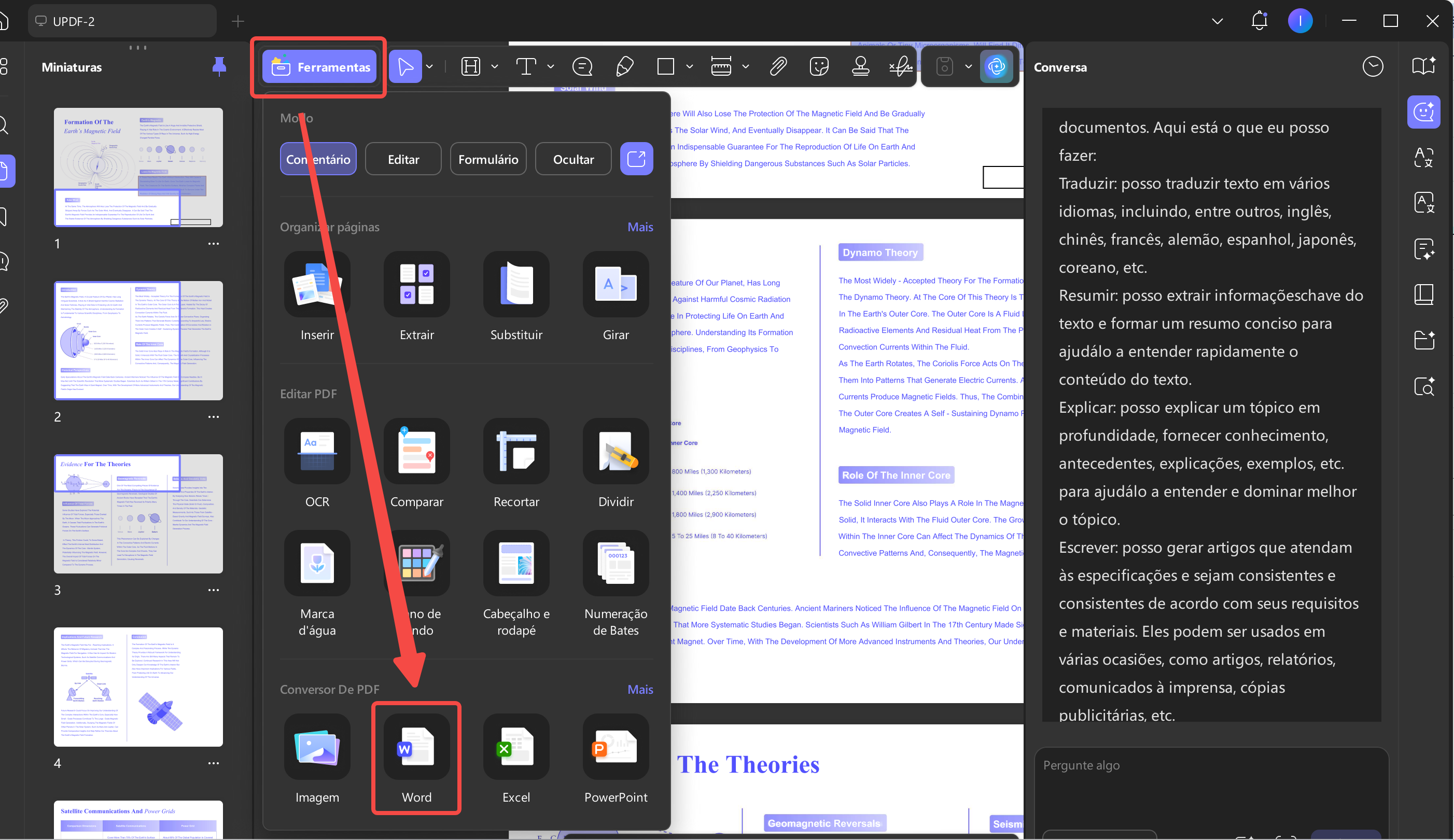
Passo 1. Acesse o conversor de PDF para Word.
Após importar um PDF, clique na opção “Ferramentas” e pressione o ícone “Word” na seção “Conversor de PDF”.
Passo 2. Ativar o reconhecimento de texto OCR
Em seguida, na janela pop-up, escolha um intervalo de páginas e selecione um “Estilo de conteúdo do Word” apropriado. Depois, ative o “Reconhecimento de Texto com OCR” e escolha os idiomas corretos. Feito isso, clique no botão “Aplicar” para iniciar a conversão.
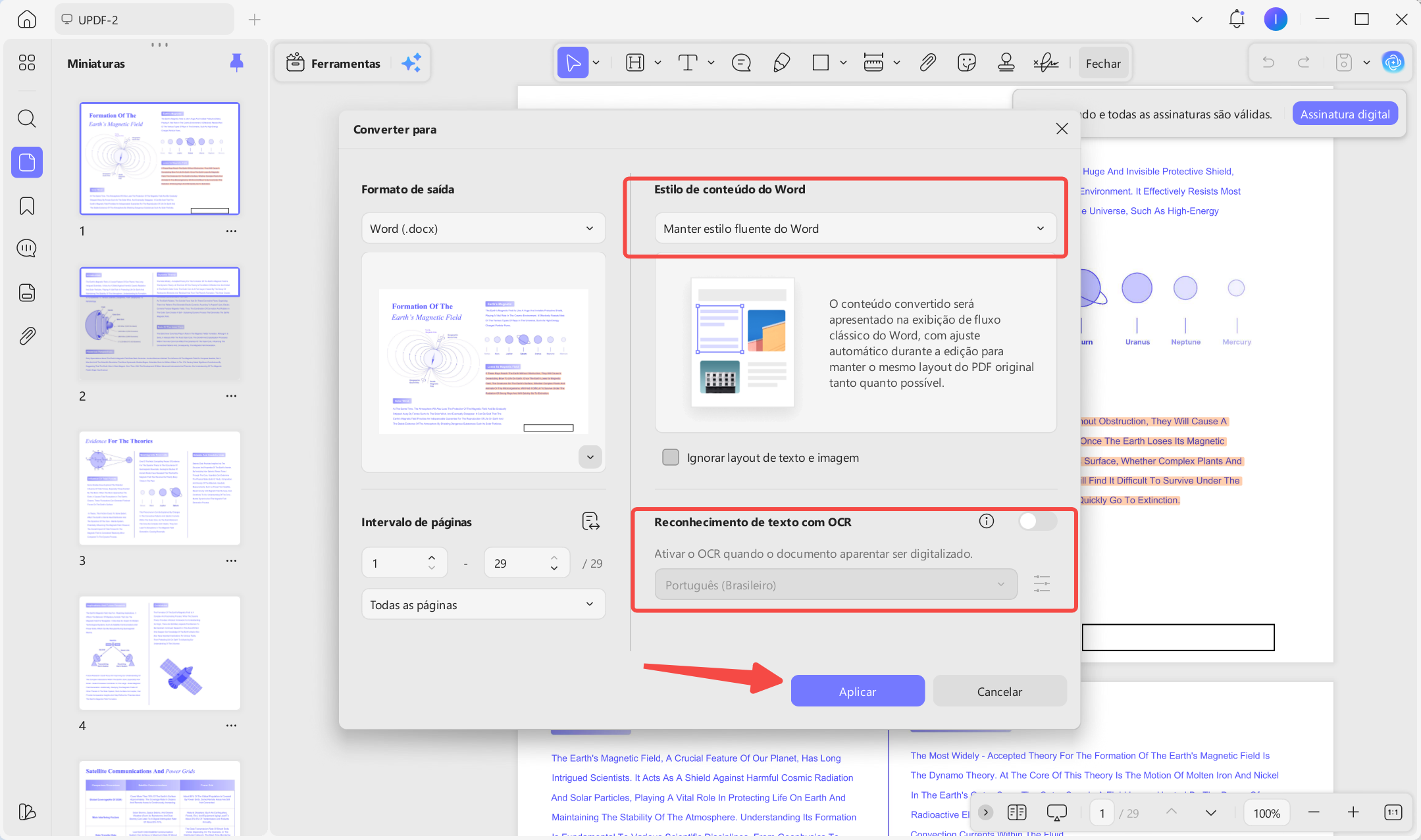
Passo 3. Revise o arquivo Word convertido.
Em seguida, abra o arquivo convertido e verifique se o texto é editável ou não.
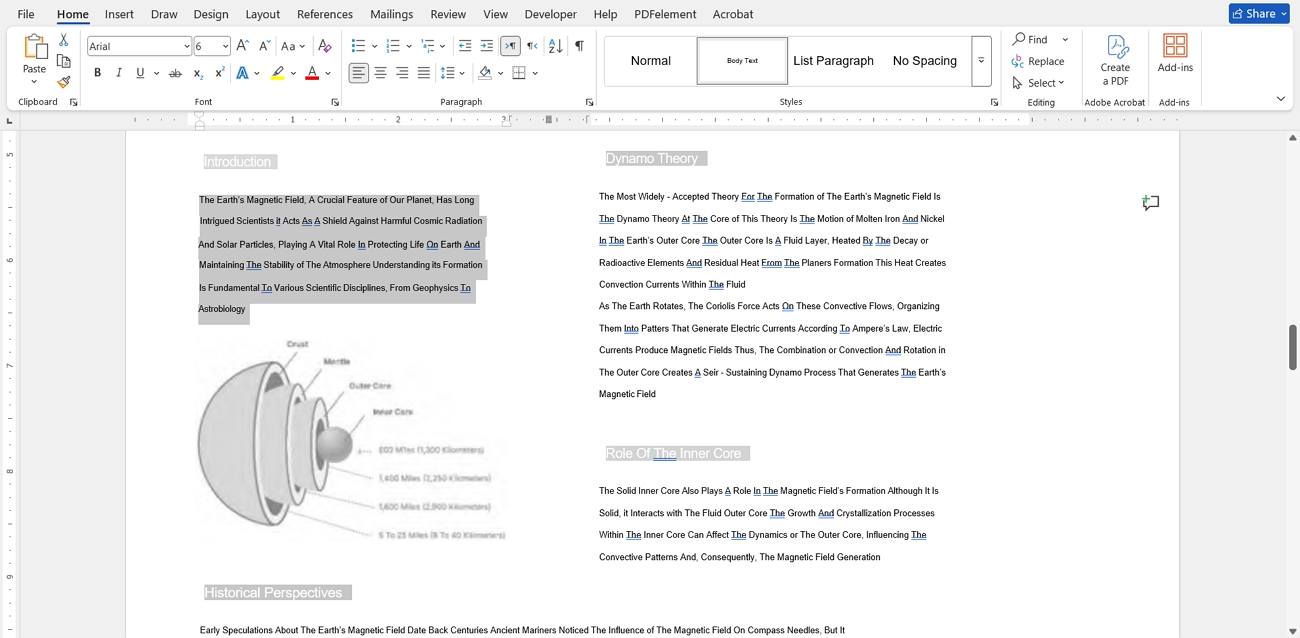
Palavras Finais
Em resumo, as ferramentas de OCR de código aberto do GitHub para PDF para Word oferecem poder e controle, mas exigem paciência. Elas ainda apresentam dificuldades com layouts complexos, grandes lotes de dados e usuários sem conhecimento técnico que simplesmente desejam resultados rápidos. Se você prioriza precisão, simplicidade e conversões confiáveis para o dia a dia a partir de digitalizações, experimente o UPDF para sua próxima conversão de PDF para Word.
Windows • macOS • iOS • Android Seguro 100%