 Windows版UPDF
Windows版UPDF Mac版UPDF
Mac版UPDF iPhone/iPad版UPDF
iPhone/iPad版UPDF Android版UPDF
Android版UPDF UPDF AI オンライン
UPDF AI オンライン UPDF Sign
UPDF Sign PDF編集
PDF編集 PDF注釈付け
PDF注釈付け PDF作成
PDF作成 PDFフォーム
PDFフォーム リンクの編集
リンクの編集 PDF変換
PDF変換 OCR機能
OCR機能 PDFからWordへ
PDFからWordへ PDFから画像へ
PDFから画像へ PDFからExcelへ
PDFからExcelへ PDFのページ整理
PDFのページ整理 PDF結合
PDF結合 PDF分割
PDF分割 ページのトリミング
ページのトリミング ページの回転
ページの回転 PDF保護
PDF保護 PDF署名
PDF署名 PDFの墨消し
PDFの墨消し PDFサニタイズ
PDFサニタイズ セキュリティ解除
セキュリティ解除 PDF閲覧
PDF閲覧 UPDF クラウド
UPDF クラウド PDF圧縮
PDF圧縮 PDF印刷
PDF印刷 PDFのバッチ処理
PDFのバッチ処理 UPDF AIについて
UPDF AIについて UPDF AIソリューション
UPDF AIソリューション AIユーザーガイド
AIユーザーガイド UPDF AIによくある質問
UPDF AIによくある質問 PDF要約
PDF要約 PDF翻訳
PDF翻訳 PDF付きチャット
PDF付きチャット AIでチャット
AIでチャット 画像付きチャット
画像付きチャット PDFからマインドマップへの変換
PDFからマインドマップへの変換 PDF説明
PDF説明 PDF AIツール
PDF AIツール 画像AIツール
画像AIツール AIチャットツール
AIチャットツール AIライティングツール
AIライティングツール AI学習ツール
AI学習ツール AI業務ツール
AI業務ツール その他のAIツール
その他のAIツール PDFからWordへ
PDFからWordへ PDFからExcelへ
PDFからExcelへ PDFからPowerPointへ
PDFからPowerPointへ ユーザーガイド
ユーザーガイド 公式ブログ
公式ブログ UPDF 活用術
UPDF 活用術 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs Foxit
UPDF vs Foxit UPDF vs PDF Expert
UPDF vs PDF Expert よくある質問(FAQ)
よくある質問(FAQ) ダウンロードセンター
ダウンロードセンター 動作環境・仕様
動作環境・仕様 お問い合わせ
お問い合わせ ニュースルーム
ニュースルーム アップデート履歴
アップデート履歴 ユーザーレビュー
ユーザーレビュー 会社概要
会社概要
皆さんは、大きなPDFファイルで特定の情報を探すのに苦労した経験がありますか?
スキャンした契約書や研究論文を受け取ったのに、文書内のキーワードを検索できないとしたらどうでしょう。とてもイライラしますよね?
もしそうであれば、PDFを検索可能にする方法で、皆さんのその悩みを解決することができます。それは、スキャンした文書や選択できないテキストを含むPDFで特に便利です。
UPDFなどの適切なツールを使えば、PDFを簡単に検索可能なファイルに変換できます。
このガイドでは、Adobeを使わずにUPDFを使ってPDFを検索可能にする方法をご紹介します。ドキュメントワークフローを効率化する方法を学び、下のボタンをクリックしてUPDFをダウンロードしてください。
Windows • macOS • iOS • Android 100%安全
パート 1. Adobeを使わずにPDFを検索可能にする方法
Adobeを使わずにPDFを検索可能にするなら、UPDFは素晴らしい選択肢です。
このツールは、OCR(光学文字認識)機能を使ってPDFを検索可能な文書に変換します。UPDFを使えば、PDF内のテキストを素早く正確にスキャン・認識できるため、文書内のテキストを簡単に検索、編集、コピーできます。
さらに、UPDFは使いやすいだけでなく、費用対効果も高く、Adobeのサブスクリプションを必要とせずに、様々な編集・変換オプションを利用できます。
UPDFのOCRツールは、英語、フランス語、ドイツ語、イタリア語など38 以上の言語に対応しており、世界中のユーザーにとって実用的なソリューションです。
さらに重要なのは、UPDFが複数言語の文書内のテキスト認識をサポートしていることです。
さらに、OCRとフォーマット変換を1 回の操作で実行できます。バッチ変換機能を使えば、複数のPDFファイルを他のフォーマットに変換し、同時にOCR 処理することも可能です。
UPDFを今すぐ試して、ドキュメントワークフローを効率化しましょう。
Windows • macOS • iOS • Android 100%安全
一般的な場合で検査可能なPDFに変換する:
UPDFを使用してPDFを検索可能にする一般的な場合には、次の簡単な手順に従います。
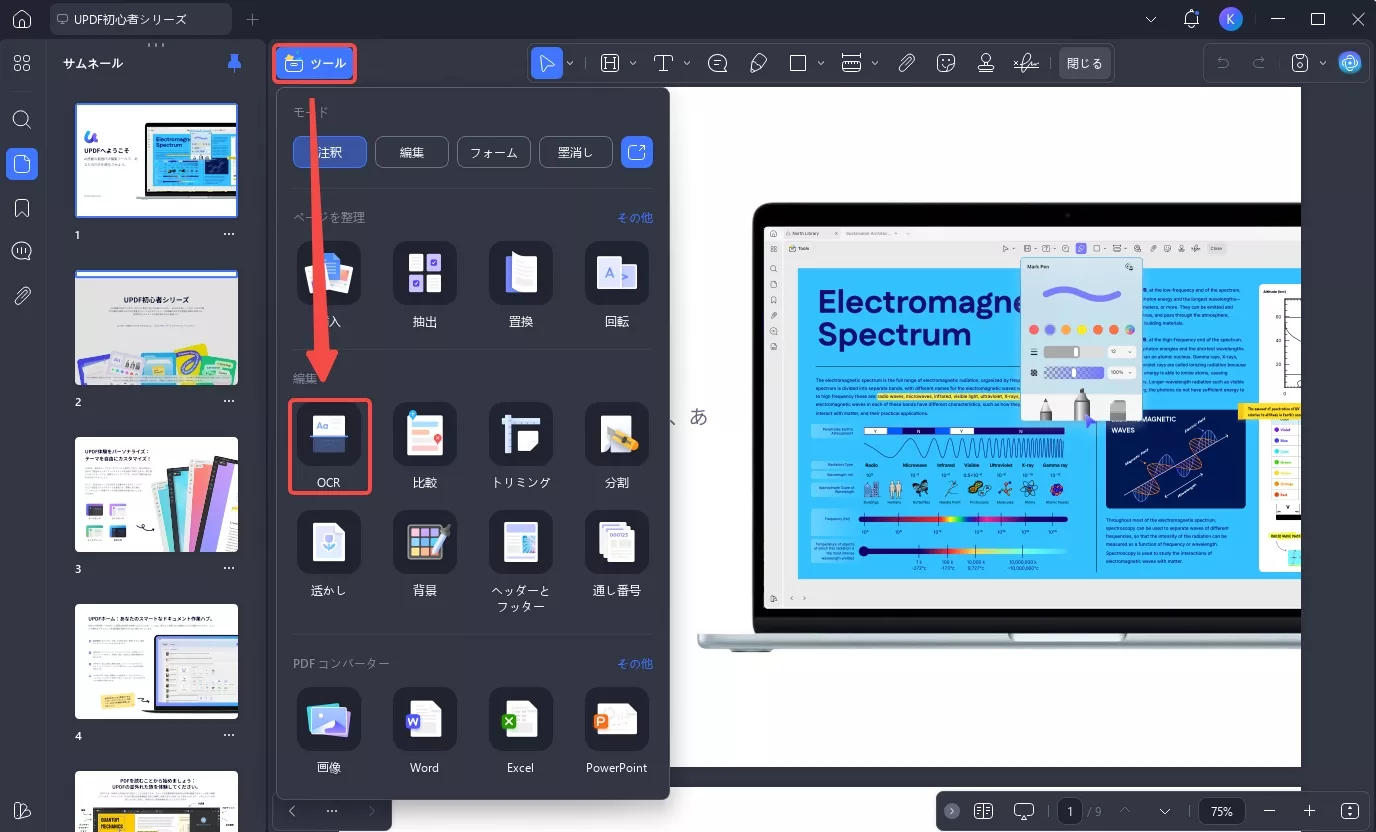
1. UPDFを起動し、「OCR」を選択する
UPDFでPDFファイルを開き、画面左上の「ツール」オプションに移動します。
「ツール」メニューから「OCR」オプションを選択して処理を開始します。
ただし、OCRを初めて使用する場合は、OCRをインストールするためのウィンドウがポップアップ表示されます。
2. 希望のレイアウトを選択する
UPDF OCRは、編集可能なPDF、テキストと画像のみ、検索可能なPDFのみの3種類のドキュメントタイプオプションを提供します。
ニーズに応じて、ご希望のモードをお選びください。
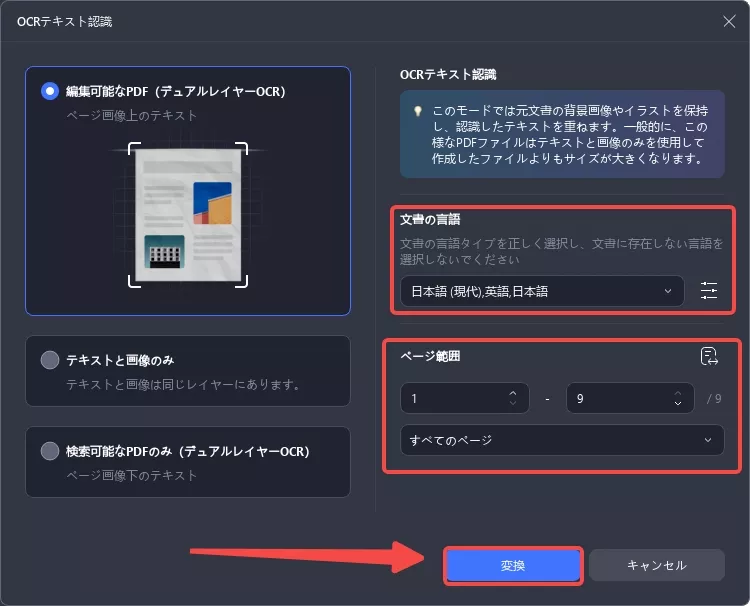
3. 言語と解像度を設定する
より正確なOCR 結果を得るには、認識したい言語(英語など)を正しく選択する必要があります。
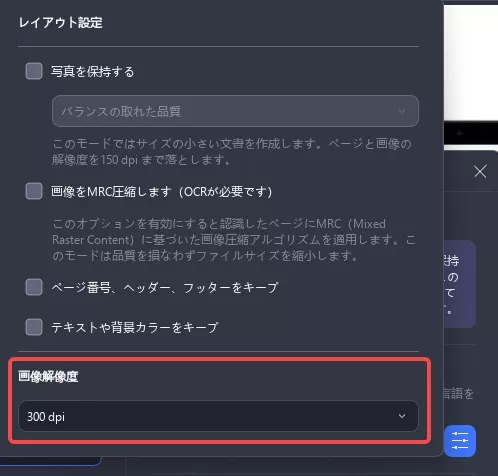
選択した言語の横にある「レイアウト設定」アイコンをクリックすると、「画像解像度」を変更できます。
解像度は、利用可能なオプション(300dpi、150dpi、72dpi)から選択するか、「自動」機能を使用して最適な設定を自動的に決定します。
4. OCRを実行する
ページ範囲を選択し、「変換」をクリックします。完了したら、検索可能な PDF を保存します。
これらの手順により、PDF を完全に検索可能にし、簡単にナビゲートできるようになります。
UPDFにはバッチOCRツールもあり、複数のスキャンされた PDF を検索可能または編集可能なドキュメントに変換して、作業をより迅速に行うことができます。
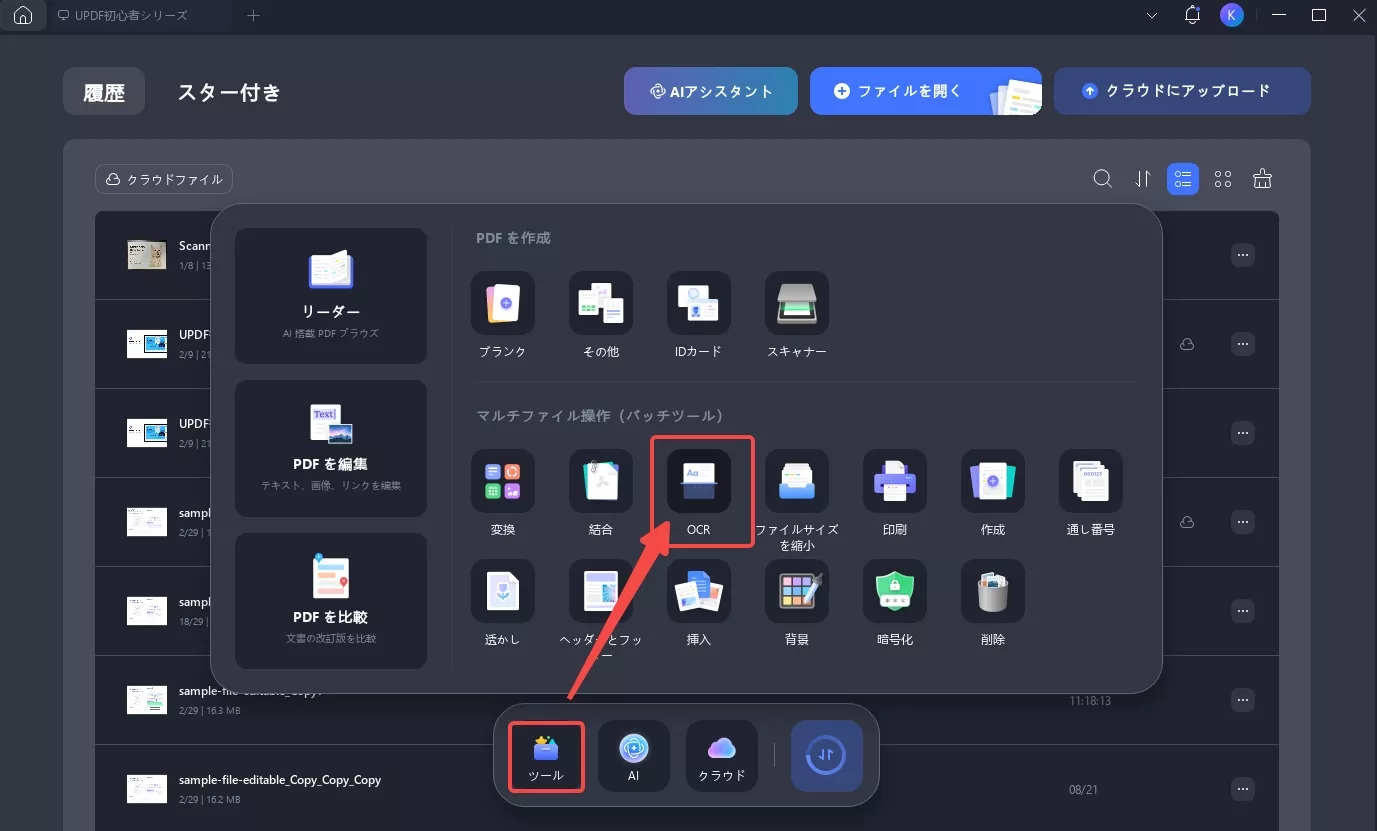
UPDF インターフェースの「ツール」に移動して「OCR」を選択します。
検索可能な PDF 形式に変換するすべてのファイルを追加し、適切なドキュメント言語を選択して「適用」をクリックするだけです。
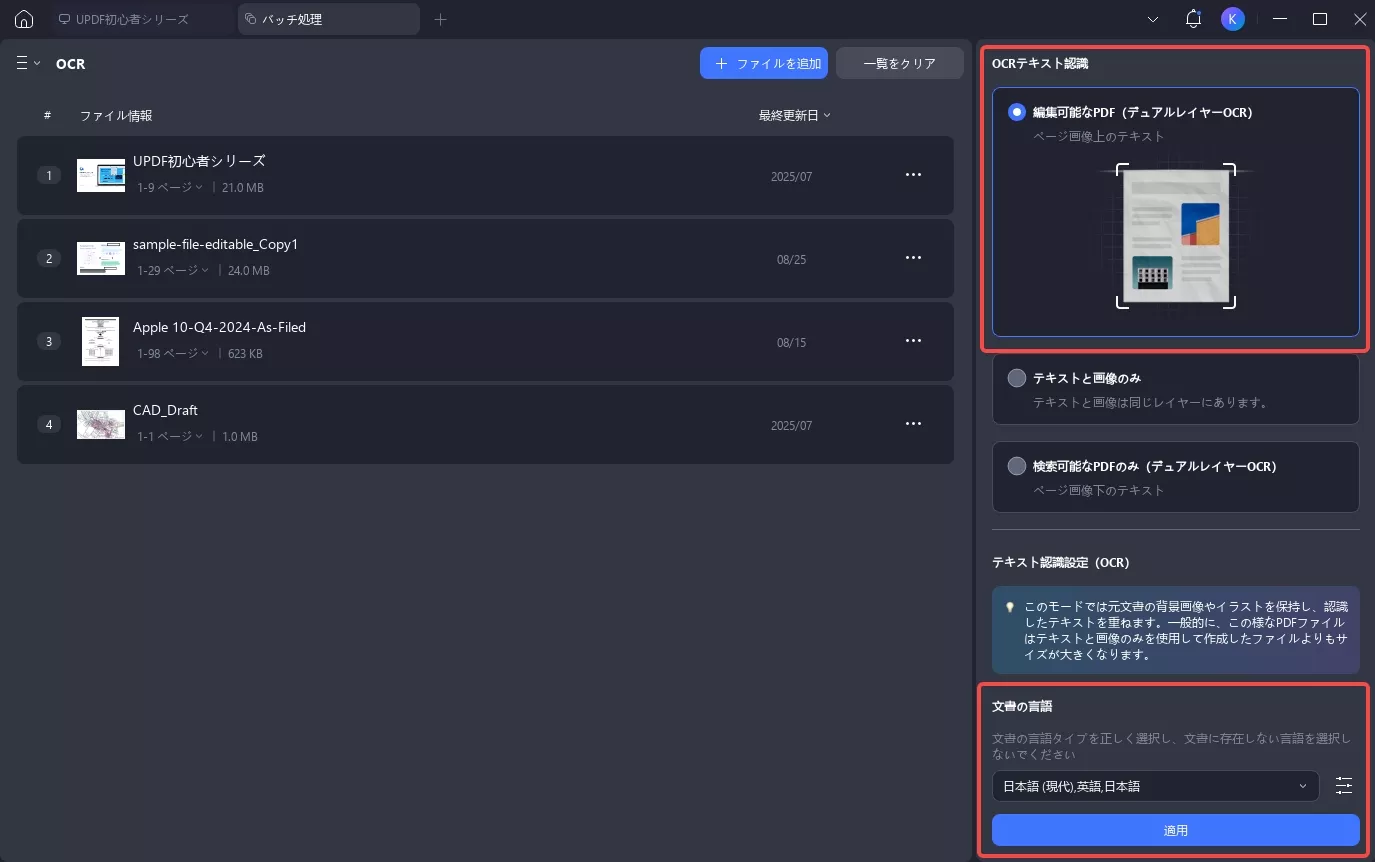
これで、UPDFでPDFを検索可能にする手順が終わりです。UPDFのそのユーザーフレンドリーなインターフェイスと手順で、検査可能なPDFを作成することもそこまで難しくないと思うようになりますよね!
フォーマット変換中で検査可能なPDFに変換する:
PDFを検索可能にするには、UPDFがそれだけでありません。さらに便利なのは、フォーマット変換中にシームレスにOCR処理が行えることです。
UPDFを使えば、スキャンしたPDF、画像、紙の文書を、ワンステップで簡単に、完全に編集可能なWord、Excel、またはPowerPointファイルに変換できます。
内蔵のOCR(光学文字認識)テクノロジーにより、UPDFはスキャンしたテキストをインテリジェントに認識しながら、必要なフォーマットに変換するため、別途OCR処理を施す必要はありません。
主なメリット:
- ワンクリックで変換:手動のOCR手順はもう不要です。テキストの変換と抽出を同時に実行して、より速く結果を得ることができます。
- 元のレイアウトを保持:変換中に書式、表、画像を維持し、プロフェッショナルな外観のドキュメントを作成します。
- 多言語サポート:中国語、日本語、英語を含む 38 言語のテキストを正確に認識して変換します。
- バッチ処理:品質を損なうことなく、複数のスキャンされたファイルを一度に変換することで時間を節約します。
- 検索可能で編集可能な出力:検索不可能なスキャンを完全に編集可能かつ検索可能なデジタル ファイルに変換します。
形式変換によりPDFを検索可能にする手順は次のとおりです:
- スキャンされた単一の文書の場合
ステップ 1:UPDF を起動した後、スキャンしたドキュメントをドラッグ アンド ドロップしてアップロードします。
Windows • macOS • iOS • Android 100%安全
ステップ2:UPDFでドキュメントを開いた後、「ツール」>「PDFコンバーター」セクションに移動して、変換する形式(例:Word)を選択します。
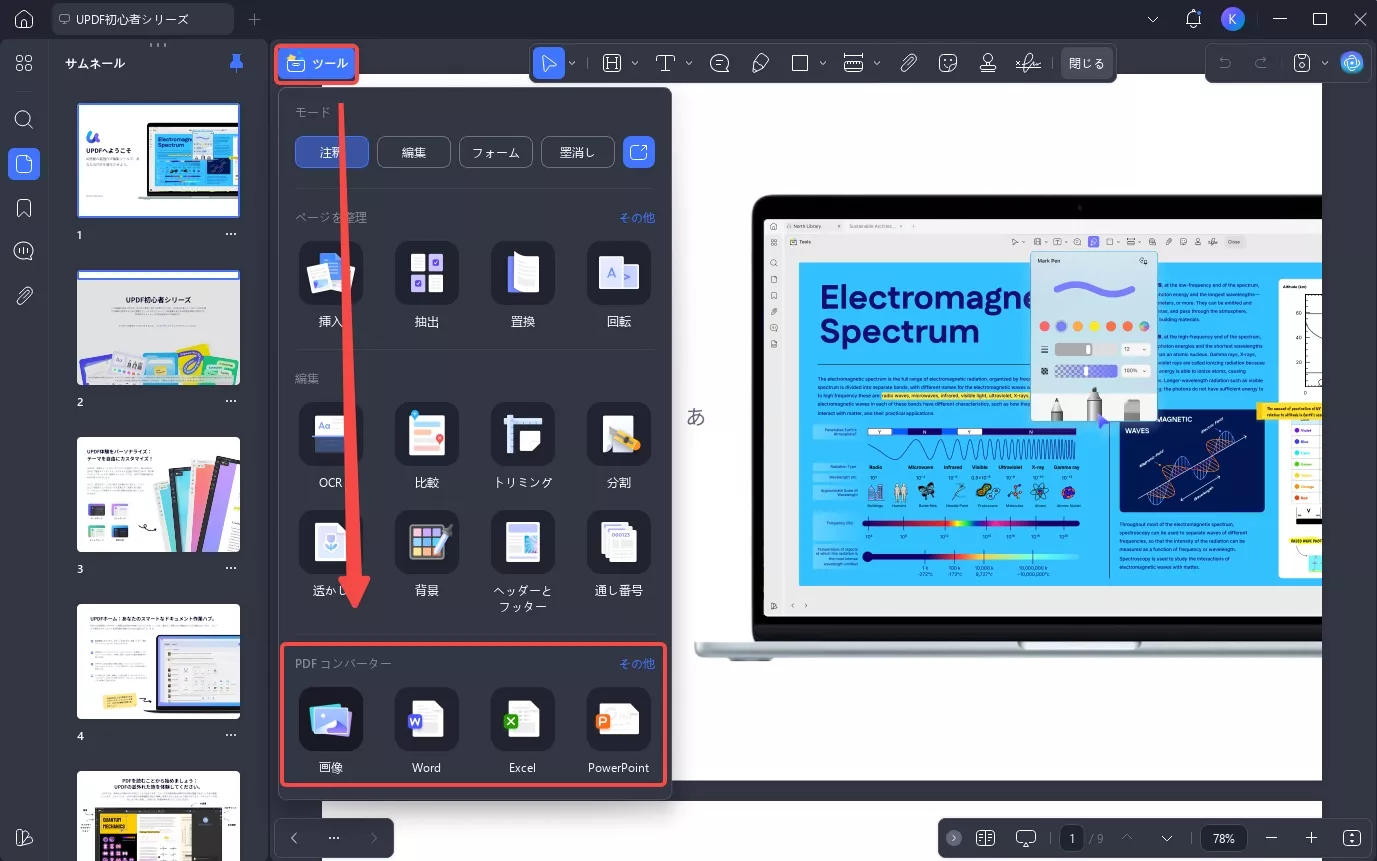
ステップ3:ポップアップウィンドウで、出力形式が正しく選択されているか確認してください。
出力形式としてWordを選択した場合は、ページ範囲とコンテンツスタイルを設定できます。
「OCRテキスト認識」をオンにし、文書の言語タイプを正しく選択します。「適用」ボタン(右下)をクリックして変換を開始します。
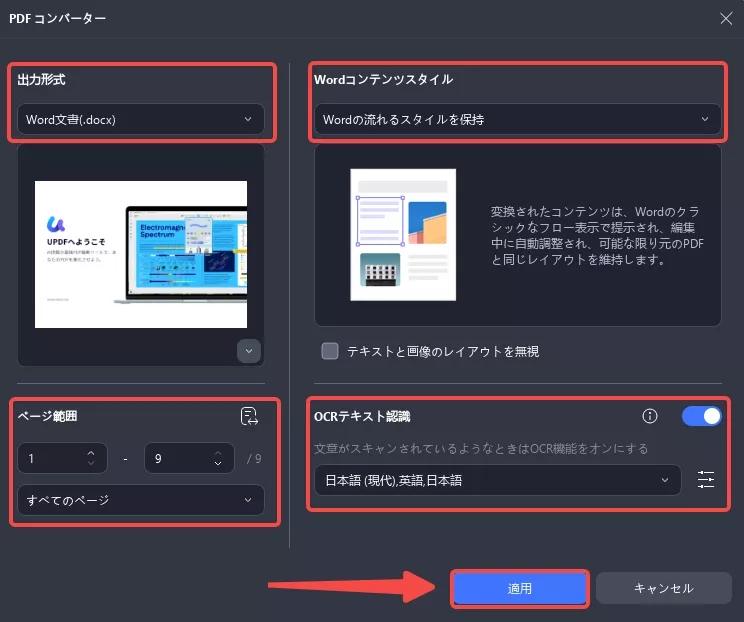
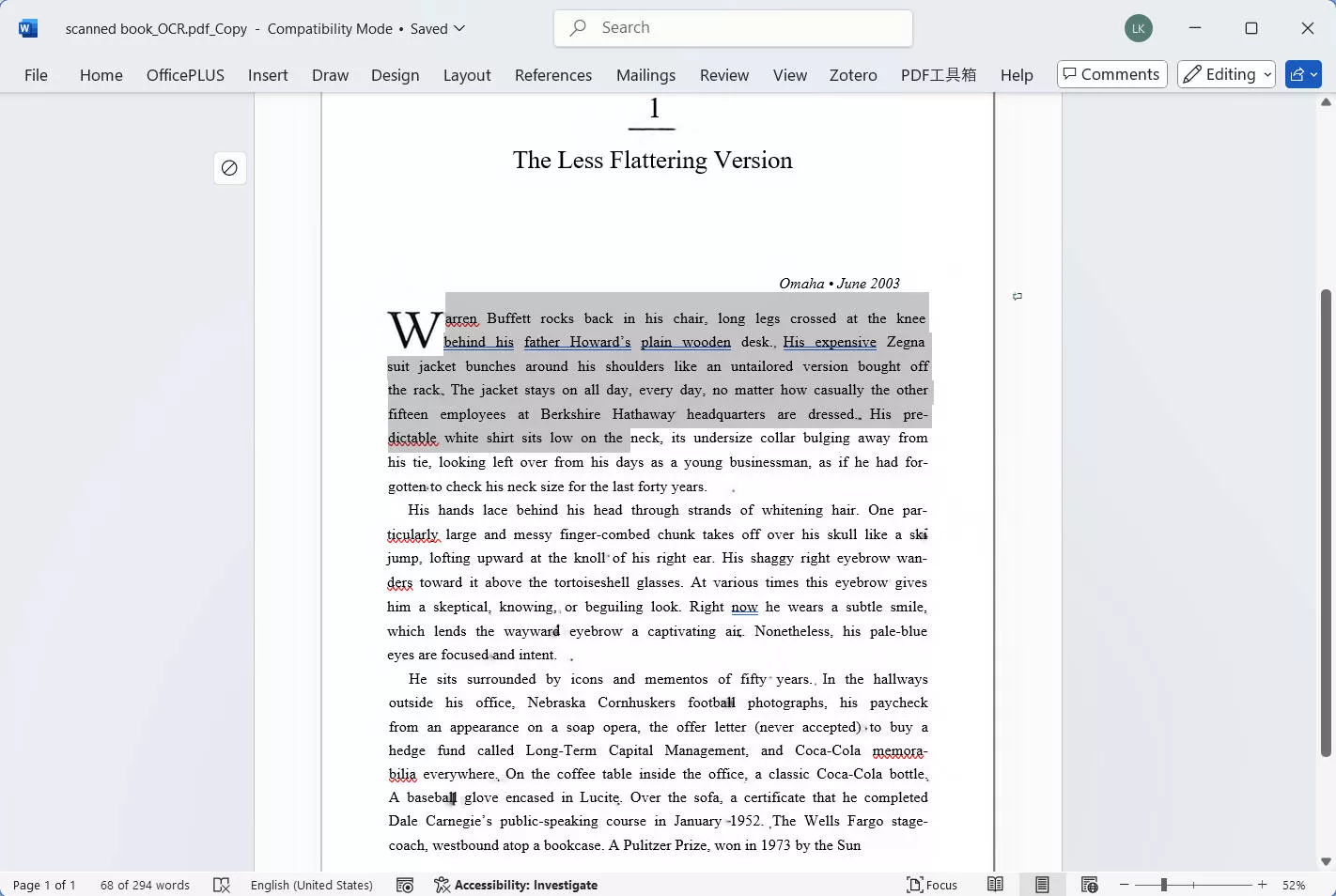
ステップ4:変換およびOCR 処理されたファイルを保存する場所を選択します。それでは結果をプレビューしてみましょう。
UPDFでOCR 処理を行った後、Wordに変換されたPDFは元の文書とほぼ同じ書式とレイアウトを維持しながら、テキストのフル編集機能も利用できます。
- 複数のスキャンされた文書の場合:
ステップ1:UPDF を起動した後、「ツール」ボタンをクリックし、ポップアップ メニューから、「マルチファイル操作(バッチツール)」パネルの下にある「変換」を選択します。
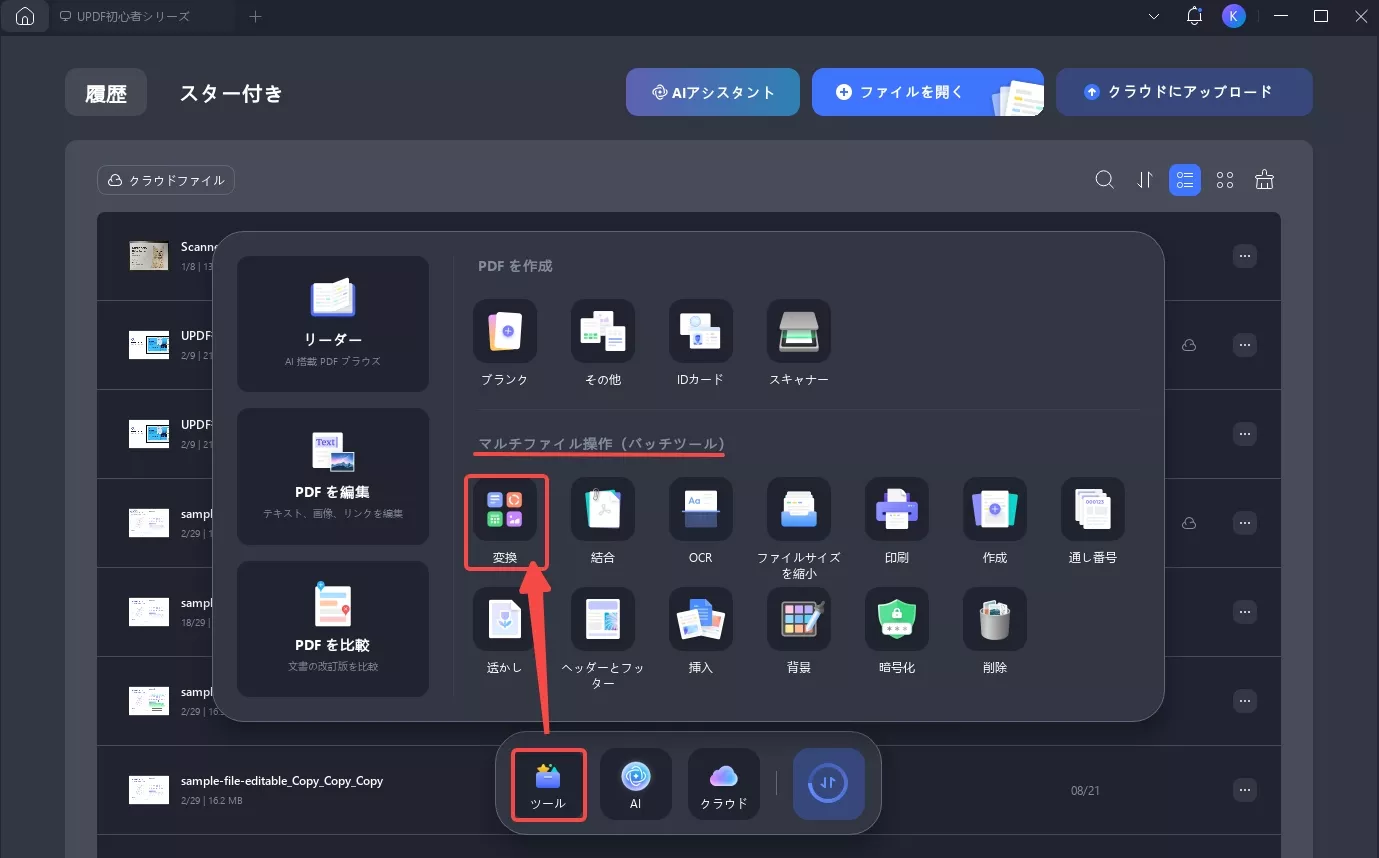
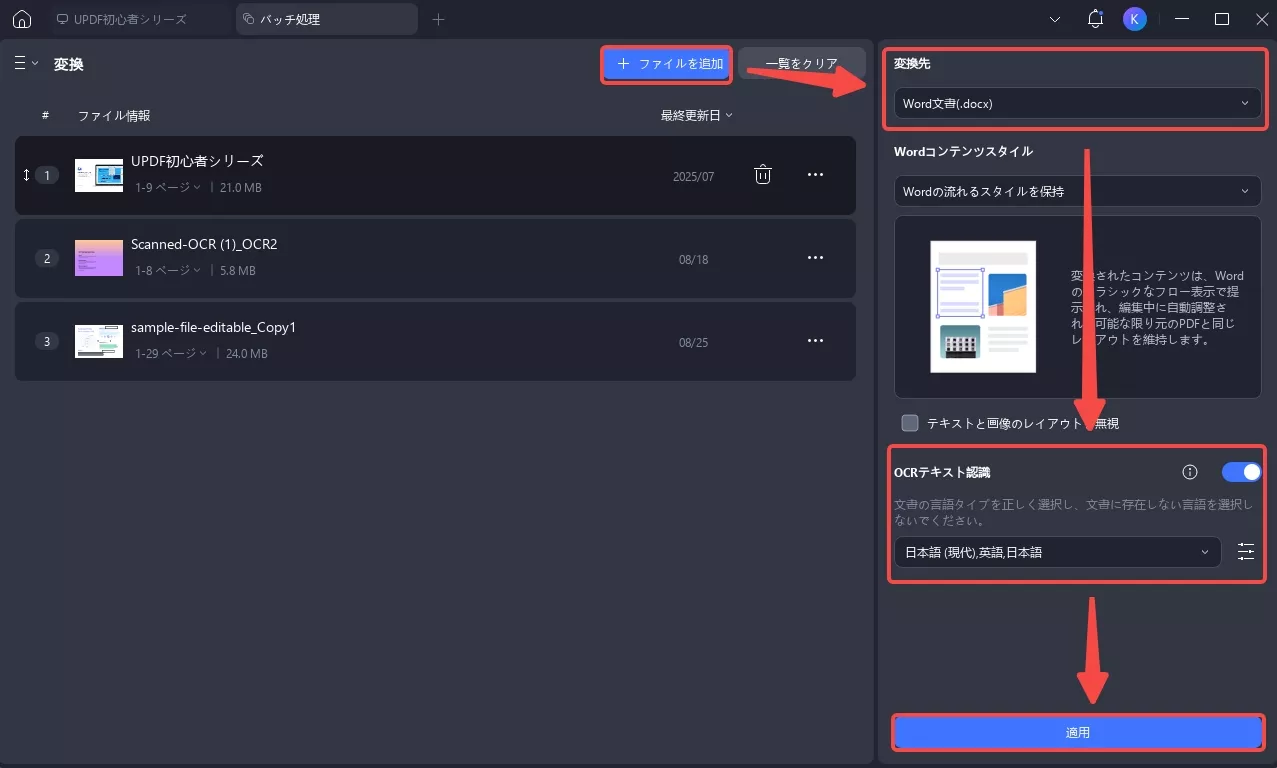
ステップ2:スキャンした文書をドラッグ&ドロップしてアップロードします。「変換先」ドロップダウンで、変換したい出力形式(例:Word)を選択します。
「OCRテキスト認識」をオンにし、文書の言語タイプを正しく選択します。紫色の「適用」ボタン(右下)をクリックして、一括変換を開始します。
UPDFでPDFを検索可能にする方法の詳細な手順を知りたい場合は、次のビデオでビジュアル ガイドをご覧になり、またはmycomputerlifeのこのレビュー記事をお読みください!
UPDFの無料版でも優れた基本機能はご利用いただけますが、プロ版にアップグレードすると、OCRツールの真価が発揮されます。
UPDFプロでは、処理速度の向上、高度なレイアウトオプションへのアクセス、そして大規模で複雑なPDFファイルの容易な処理を実現できます。
プロ版では、複数のPDFを1つに結合するバッチOCRにも対応しており、複数の文書を同時に処理できます。ドキュメント管理をさらに効率化するために、今すぐUPDFプロにアップグレードしましょう!
パート2. PDFを検索可能にする方法によくある質問
1. PDF内の特定のテキストを検索する方法は何ですか。
PDF内の特定のテキストを検索するには、UPDFのようなツールを使うと、プロセスがシンプルかつ効率的になります。単語一つでも特定のフレーズでも、UPDFを使えばわずか数クリックで必要な情報を見つけることができます。
使い方は以下のとおりです。
① UPDF をダウンロードして起動し、「ファイルを開く」ボタンをクリックして PDF を読み込みます。
② 右上の「検索」アイコンをクリックするか、「Ctrl + F」(Windows) または「Cmd + F」(Mac) を押します。
③ 検索したいテキストを入力すると、UPDF はドキュメント内のすべてのインスタンスを強調表示します。
④ より正確に検索するには、「フィルター」ツールバーの「大文字と小文字を区別する」または「単語全体のみ」のオプションを使用して検索を絞り込みます。
2. PDF でテキストが認識されないのはなぜですか。
PDFがテキストを認識しない理由はいくつかありますが、通常は文書の形式や品質に問題があることが原因です。
解像度の低いスキャン、画像の鮮明度の低さ、歪んだテキストなどは、正確なテキスト認識の大きな障害となります。
また、PDFがスキャン画像であり、選択可能なテキストが含まれていないことも原因として考えられます。
この問題を解決するために、UPDFの強力なOCRツールは、スキャンしたPDFを検索・編集可能な文書に変換するのに役立ちます。
38 言語に対応し、レイアウトオプションもカスタマイズ可能なUPDFのOCRは、低品質のスキャンデータでも正確に処理します。
UPDFで文書を開き、「ツール」メニューの「OCR」機能を使用するだけで、テキスト認識率が向上し、PDFが完全に検索可能になります。
3.PDFを読み取り専用にする方法は何ですか。
PDFを読み取り専用にするには、UPDFの権限制御設定を使用して、編集、印刷、コピーを制限できます。簡単なガイドを以下に示します。
① PDF 文書を開く:UPDFを起動し、保護したいPDFファイルを開きます。右上隅の「保存」アイコンの横にある下向き矢印をクリックして、「パスワードを使用して保護」オプションを選択します。
② 権限の設定:「権限パスワード」オプションから「+追加」を選択すると、ドキュメントの権限を制御するためのパスワードを設定できます。
③ 制限のカスタマイズ:デフォルトでは、権限パスワードを設定すると、編集、印刷、コピーが制限されます。必要に応じて、「その他のオプション」をクリックして、これらの制限を微調整してください。
④ PDFを保存します。「保存」をクリックして、読み取り専用設定を確定します。
これにより、不正な変更が防止され、PDF が安全に編集不可能な状態を維持されます。
終わりに
以上の方法の通りに、PDFを検索可能にするのは、必ずしも複雑な作業ではありません。このガイドに記載されている手順に従い、UPDFのOCRと検索機能を使えば、PDFを簡単に検索可能な文書に変換できます。
スキャンしたファイルを扱う場合でも、PDFのコンテンツをより細かく制御したい場合でも、UPDFは強力で費用対効果の高いソリューションを提供します。
まずは無料版をお試しください。バッチOCRなどのより高度な機能が必要な場合は、UPDF Proにアップグレードして、文書管理エクスペリエンスをさらに向上させましょう。
今すぐUPDFをダウンロードして、生産性を向上させましょう!
Windows • macOS • iOS • Android 100%安全









