 UPDF para Windows
UPDF para Windows UPDF para Mac
UPDF para Mac UPDF para iPhone/iPad
UPDF para iPhone/iPad UPDF para Android
UPDF para Android Nomostar
Nomostar UPDF AI ONLINE
UPDF AI ONLINE UPDF Sign
UPDF Sign IvyCraft
IvyCraft Editar PDF
Editar PDF Anotar PDF
Anotar PDF Crear PDF
Crear PDF Formulario PDF
Formulario PDF Editar enlaces
Editar enlaces Convertir PDF
Convertir PDF OCR
OCR PDF a Word
PDF a Word PDF a imagen
PDF a imagen PDF a Excel
PDF a Excel Organizar PDF
Organizar PDF Combinar PDF
Combinar PDF Dividir PDF
Dividir PDF Recortar PDF
Recortar PDF Girar PDF
Girar PDF Proteger PDF
Proteger PDF Firmar PDF
Firmar PDF Redactar PDF
Redactar PDF Desinfectar PDF
Desinfectar PDF Eliminar seguridad
Eliminar seguridad Leer PDF
Leer PDF UPDF Cloud
UPDF Cloud Comprimir PDF
Comprimir PDF Imprimir PDF
Imprimir PDF Proceso por lotes
Proceso por lotes Sobre UPDF IA
Sobre UPDF IA Soluciones de UPDF IA
Soluciones de UPDF IA Guía de Usuario de IA
Guía de Usuario de IA Preguntas frecuentes sobre UPDF IA
Preguntas frecuentes sobre UPDF IA Resumir PDF
Resumir PDF Traducir PDF
Traducir PDF Chat con PDF
Chat con PDF Chat con imagen
Chat con imagen PDF a Mapa Mental
PDF a Mapa Mental Chat con IA
Chat con IA Explicar PDF
Explicar PDF Herramientas IA para PDF
Herramientas IA para PDF Herramientas IA para Imagen
Herramientas IA para Imagen Herramientas IA de Chat
Herramientas IA de Chat Herramientas IA de Redacción
Herramientas IA de Redacción Herramientas IA de Estudio
Herramientas IA de Estudio Herramientas IA de Trabajo
Herramientas IA de Trabajo Otras Herramientas IA
Otras Herramientas IA Generación de Marcadores con IA
Generación de Marcadores con IA Resumen de Marcadores con IA
Resumen de Marcadores con IA Generación de Marcas de Agua con IA
Generación de Marcas de Agua con IA Generación de Fondos con IA
Generación de Fondos con IA Generación de Pegatinas con IA
Generación de Pegatinas con IA Generación de Sellos con IA
Generación de Sellos con IA Suite de Escritura con IA
Suite de Escritura con IA UPDF Copilot
UPDF Copilot Gestión de Páginas con IA
Gestión de Páginas con IA Búsqueda Semántica con IA
Búsqueda Semántica con IA PDF a Word
PDF a Word PDF a Excel
PDF a Excel PDF a PowerPoint
PDF a PowerPoint Guía del Usuario
Guía del Usuario Trucos de UPDF
Trucos de UPDF Preguntas Frecuentes
Preguntas Frecuentes Reseñas de UPDF
Reseñas de UPDF Centro de descargas
Centro de descargas Blog
Blog Sala de prensa
Sala de prensa Especificaciones Técnicas
Especificaciones Técnicas Actualizaciones
Actualizaciones UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
¿Cómo se convierte un PDF escaneado a formato Word para que sea editable en el software de Microsoft? La conversión de un archivo PDF escaneado o no editable requiere un proceso especial llamado OCR o reconocimiento óptico de caracteres. Una vez que haya procesado su documento usando OCR, puede proceder a convertir el PDF en un archivo de Word. Hay algunas formas diferentes de hacer esto, pero en este artículo, le mostraremos las formas más efectivas y convenientes de convertir archivos PDF escaneados a Word en Windows y Mac.
El mejor convertidor de PDF escaneado a Word
Con soporte para más de 38 idiomas OCR, UPDF es definitivamente una de las herramientas de conversión de PDF a Word escaneadas más versátiles y poderosas que encontrará para Windows y Mac. Recuerde: convertir un documento escaneado con OCR requiere una gran precisión, y UPDF utiliza una potente función de OCR para sus conversiones. El resultado final será un documento PDF con el mismo diseño y formato que el documento original.
Windows • macOS • iOS • Android 100% Seguro
Veamos algunas de sus capacidades clave y cómo usar esta completa herramienta de conversión de PDF de Superace.
Las funciones de conversión
- Herramienta de conversión de PDF dedicada que admite muchos formatos de salida comunes, como Word, Excel, PPT, formatos de imagen, HTML, XML, texto y RTF.
- Función OCR para convertir PDF escaneado a formato Word editable.
- El formato se mantiene constante durante las conversiones: se requiere una corrección manual mínima.
Más características
- Solución todo en uno. También le permite editar documentos PDF, comentar documentos PDF, proteger documentos PDF, etc.
¿Cómo convertir PDF escaneado a Word editable con la función OCR?
¿Desea convertir un documento PDF escaneado en texto para poder usarlo en cualquier lugar que lo requiera? En lugar de escribir el texto, puede convertirlo fácilmente a Word editable con la ayuda de la herramienta OCR proporcionada por UPDF. Te permite convertir PDF escaneados a Word, lo que lo convierte en una excelente opción para obtener los datos textuales del documento. Para saber cómo se hace, mira los pasos que se muestran a continuación:
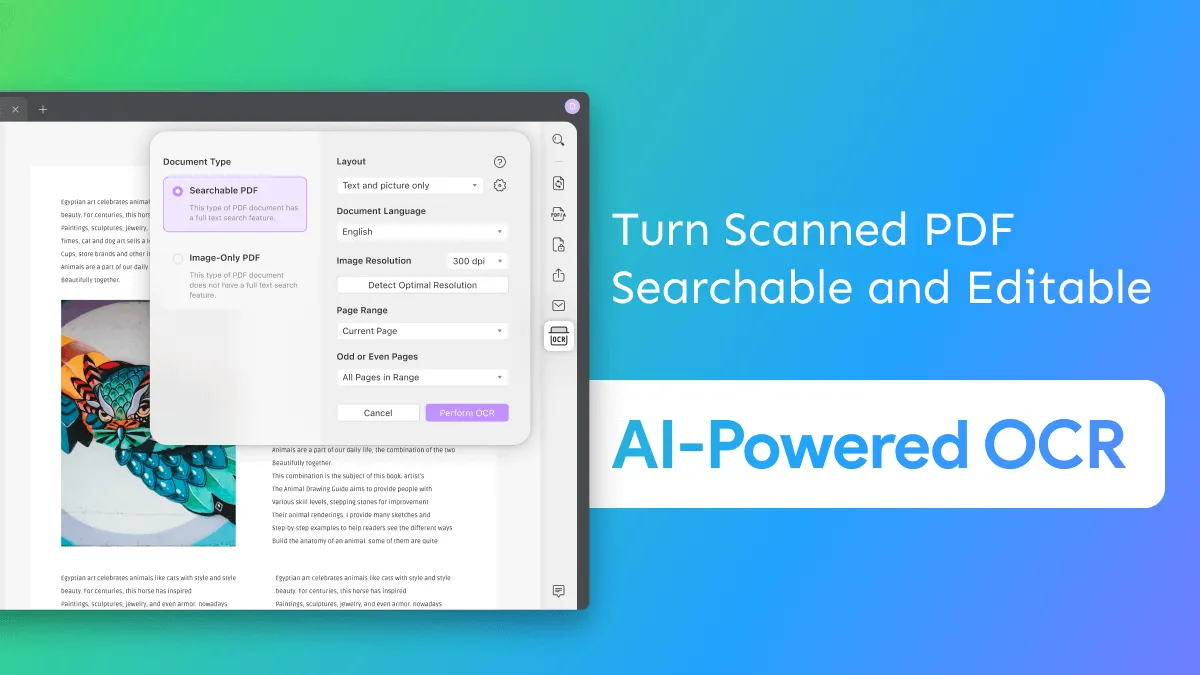
Paso 1: Definir el tipo de documento OCR
Vaya al botón "Reconocer texto usando OCR" en el panel derecho después de abrir el PDF. En la sección "Tipo de documento", seleccione "PDF con capacidad de búsqueda" y continúe con el proceso.
Paso 2: Establecer la configuración de diseño
Comenzando con la configuración de los parámetros para la herramienta OCR, deberá configurar la configuración de "Diseño" de este proceso. Para eso, se le proporcionarán tres configuraciones de diseño diferentes, que se explican a continuación:
- Solo texto e imágenes: esta configuración de diseño guarda todo el texto y las imágenes en un documento PDF. El archivo que se crea es más pequeño que el original y no tiene un formato específico seguido.
- Texto sobre la imagen de la página: si bien es el diseño predeterminado establecido durante el proceso de OCR PDF, este modo en particular contiene las imágenes e ilustraciones de acuerdo con el archivo original. Si bien son grandes, no son tan diferentes del documento PDF original.
- Texto debajo de la imagen de la página: la estructura completa de la imagen en el documento PDF original se conserva en este modo particular. El texto está presente debajo de la capa de imagen del documento, por lo que no se puede editar; sin embargo, se puede buscar.
Una vez que haya terminado, vaya a la sección "Idioma del documento", donde debe seleccionar el idioma particular que se va a detectar. Puede elegir cualquier idioma apropiado de las 38 opciones disponibles en el menú.
Continúe con la sección "Resolución de imagen" y establezca el valor correcto utilizando los disponibles en el menú. Si no está seguro, puede hacer clic en el botón "Detectar resolución óptima" y continuar.
Paso 3: Convertir el PDF escaneado en palabras editables
A continuación, proporcione el rango de páginas donde desea ejecutar la función y haga clic en "Realizar OCR". Establezca la ubicación correcta para el documento convertido para que pueda convertirse en texto editable.
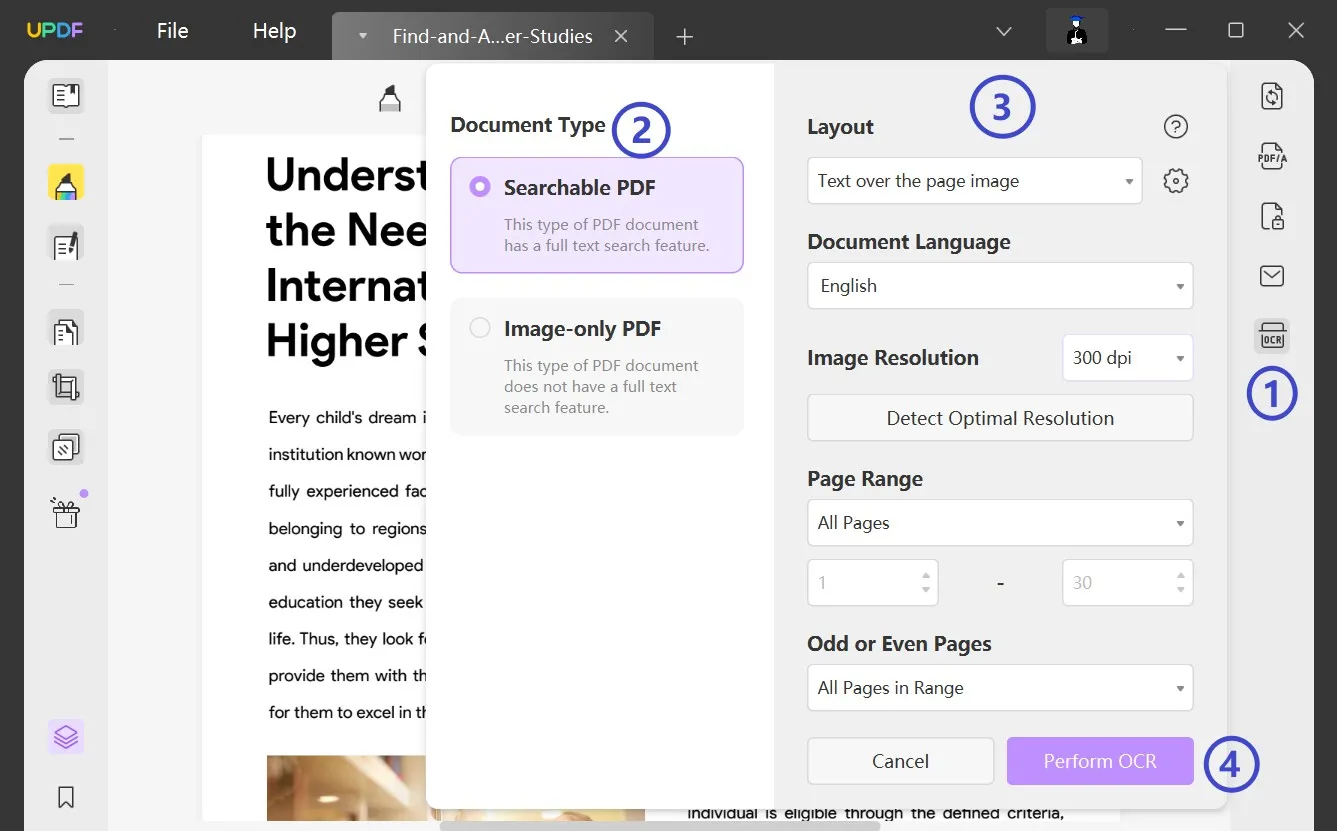
Puede editar el PDF ahora. Pero si desea convertirlo a formato Word, puede usar la función de exportación de PDF UPDF para convertir PDF a formato Word . Estos son los pasos para convertir PDF a Word:
- Abra el archivo PDF en UPDF y haga clic en "Exportar PDF" en la barra de herramientas derecha.
- Seleccione el formato "Word" y luego haga clic en "Exportar" en la ventana emergente.
- Asigne un nombre al archivo y guárdelo en la carpeta de sus dispositivos.
Es posible que algunas fuentes no se traduzcan con precisión, especialmente si su archivo escaneado tiene escritura a mano, pero el contenido será lo más parecido posible a la copia escaneada.
Video tutorial sobre cómo convertir un PDF escaneado a Word
Windows • macOS • iOS • Android 100% Seguro
¿Cuáles son algunos problemas comunes con la conversión de archivos PDF escaneados a Word?
En general, el motor OCR puede convertir la mayoría de los archivos PDF escaneados. Sin embargo, no todos los archivos escaneados son iguales. En primer lugar, si está trabajando con archivos escaneados, asegúrese de haber habilitado la opción OCR en el programa.
Antes de abrir y convertir un archivo escaneado, vaya a la configuración de OCR y seleccione Convertir usando OCR. Si el archivo no se convierte, esta podría ser la causa: el espacio entre los caracteres del documento es demasiado pequeño y el OCR no puede detectar cada carácter.
La mala calidad de imagen del documento escaneado, una combinación de fuentes utilizadas en los documentos escaneados y tipos de letra en cursiva y subrayados, todos los cuales pueden enturbiar la claridad y la forma de los caracteres individuales, son problemas que pueden afectar el resultado de OCR. Como resultado, confirmar que el carácter "reconocido" por el software OCR corresponde al carácter del papel escaneado es mucho más complicado.
Lo más importante es que debe saber que, con UPDF OCR, no necesita preocuparse por ninguno de estos problemas, ya que le brindará resultados y precisión perfectos. Pruebalo ahora.
Windows • macOS • iOS • Android 100% Seguro
Preguntas frecuentes sobre PDF escaneado
¿ Qué es OCR (reconocimiento óptico de caracteres)?
El proceso de convertir una imagen de texto en un formato de texto legible por máquina se conoce como reconocimiento óptico de caracteres (OCR). Por ejemplo, cuando escanea un formulario o un recibo, su computadora guarda el escaneo como un archivo de imagen. Con un editor de texto, no puede modificar, buscar o contar las palabras en el archivo de imagen. Sin embargo, puede utilizar OCR para transformar la imagen en un documento de texto, con el contenido guardado como datos de texto.
La mayoría de los flujos de trabajo comerciales implican obtener información de los medios impresos. Los procesos comerciales incluyen formularios en papel, facturas, documentos legales escaneados y contratos impresos. Estas grandes cantidades de papeleo requieren mucho tiempo y espacio para almacenar y manejar. Si bien la gestión de documentos sin papel es el camino a seguir, escanear un documento en una imagen presenta dificultades. El procedimiento requiere la participación manual y puede llevar mucho tiempo y ser ineficaz.
Además, la digitalización del contenido de este documento genera archivos de imagen que contienen el texto que contienen. El texto de la imagen no puede ser procesado por un software de procesamiento de textos de la misma manera que los documentos de texto. El problema se resuelve con la tecnología OCR, que convierte las imágenes de texto en datos que otras aplicaciones comerciales pueden evaluar. Luego, los datos se pueden usar para análisis, agilizar operaciones, automatizar procedimientos y aumentar la productividad.
¿Qué es un archivo PDF nativo?
Un PDF nativo es un PDF de un documento que "nació digital", lo que significa que se creó a partir de una versión electrónica del documento en lugar de una versión impresa. Por otro lado, un PDF escaneado de un documento impreso, como cuando escanea páginas de un diario impreso y guarda el archivo como PDF.
¿Cuál es la diferencia entre un PDF escaneado y un PDF nativo?
¿ Quiere conocer las diferencias entre un PDF escaneado y un PDF nativo ? Los PDF escaneados son PDF creados con imágenes escaneadas de un determinado documento. Debido a que un PDF escaneado es una colección de imágenes, el usuario a menudo no puede buscar en el texto. Los PDF nativos, por otro lado, son PDF de documentos que "nacieron" digitales, lo que significa que el PDF se formó a partir de una versión electrónica original del documento, como un documento de Microsoft Word. Cada vez más contenido en las bases de datos de ProQuest "nace" digital y, por lo tanto, está disponible como PDF nativo en formato PDF (parte del texto completo solo está disponible en ASCII/HTML). El porcentaje de información nacida en formato digital aportada a las bases de datos de ProQuest crece año tras año.
¿Cuáles son los tipos de archivos PDF escaneados?
Los archivos PDF escaneados se clasifican en tres categorías.
- PDF de imagen: el tipo de PDF más frecuente es un PDF de imagen. Esto es cierto cuando un documento impreso se escanea en un archivo PDF.
- PDF escaneables con texto que se puede buscar: este documento PDF escaneado puede contener texto oculto detrás de la imagen.
- PDF escaneados con contenido mixto: este PDF puede contener fotos escaneadas y elementos PDF generados electrónicamente.
Conclusión
De las introducciones anteriores de conversión de PDF escaneado a Word, podemos saber que UPDF es el mejor convertidor de PDF escaneado a Word. Es asequible, preciso, dedicado, versátil y está disponible para los sistemas Windows, Mac, iOS y Android. Además, puede convertir archivos PDF a varios otros formatos para que los archivos se puedan editar en sus aplicaciones nativas. Pruébelo y únase al UPDF en el que muchos usuarios confían para su flujo de trabajo de documentos diario.
Windows • macOS • iOS • Android 100% Seguro









 Estrella López
Estrella López 