 UPDF para Windows
UPDF para Windows UPDF para Mac
UPDF para Mac UPDF para iPhone/iPad
UPDF para iPhone/iPad UPDF para Android
UPDF para Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign Editar PDF
Editar PDF Anotar PDF
Anotar PDF Criar PDF
Criar PDF Formulário PDF
Formulário PDF Editar links
Editar links Converter PDF
Converter PDF OCR
OCR PDF para Word
PDF para Word PDF para Imagem
PDF para Imagem PDF para Excel
PDF para Excel Organizar PDF
Organizar PDF Mesclar PDF
Mesclar PDF Dividir PDF
Dividir PDF Cortar PDF
Cortar PDF Girar PDF
Girar PDF Proteger PDF
Proteger PDF Assinar PDF
Assinar PDF Redigir PDF
Redigir PDF Sanitizar PDF
Sanitizar PDF Remover Segurança
Remover Segurança Ler PDF
Ler PDF Nuvem UPDF
Nuvem UPDF Comprimir PDF
Comprimir PDF Imprimir PDF
Imprimir PDF Processamento em Lote
Processamento em Lote Sobre o UPDF AI
Sobre o UPDF AI Soluções UPDF AI
Soluções UPDF AI Guia do Usuário de IA
Guia do Usuário de IA Perguntas Frequentes
Perguntas Frequentes Resumir PDF
Resumir PDF Traduzir PDF
Traduzir PDF Converse com o PDF
Converse com o PDF Converse com IA
Converse com IA Converse com a imagem
Converse com a imagem PDF para Mapa Mental
PDF para Mapa Mental Explicar PDF
Explicar PDF Ferramentas de IA para PDF
Ferramentas de IA para PDF Ferramentas de IA para Imagem
Ferramentas de IA para Imagem Ferramentas de Chat com IA
Ferramentas de Chat com IA Ferramentas de Escrita com IA
Ferramentas de Escrita com IA Ferramentas de Estudo com IA
Ferramentas de Estudo com IA Ferramentas de Trabalho com IA
Ferramentas de Trabalho com IA Outras Ferramentas de IA
Outras Ferramentas de IA Geração de marcadores
Geração de marcadores Resumo de marcadores
Resumo de marcadores Geração de marca d’água
Geração de marca d’água Geração de fundo
Geração de fundo Geração de adesivos
Geração de adesivos Geração de carimbos
Geração de carimbos Suite de Redação
Suite de Redação UPDF Copilot
UPDF Copilot Gerenciamento de páginas
Gerenciamento de páginas Pesquisa Semântica
Pesquisa Semântica PDF para Word
PDF para Word PDF para Excel
PDF para Excel PDF para PowerPoint
PDF para PowerPoint Guia do Usuário
Guia do Usuário Truques do UPDF
Truques do UPDF Perguntas Frequentes
Perguntas Frequentes Avaliações do UPDF
Avaliações do UPDF Centro de Download
Centro de Download Blog
Blog Sala de Imprensa
Sala de Imprensa Especificações Técnicas
Especificações Técnicas Atualizações
Atualizações UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Fazer OCR em PDF no Windows
O recurso OCR do UPDF permite converter o texto digitalizado de um documento PDF em conteúdo pesquisável e editável. O texto nas imagens também pode ser editado após usar esse recurso, o que torna o documento interativo para os usuários. Clique no botão abaixo e siga o guia de texto ou o guia em vídeo para OCR de PDFs.
Windows • macOS • iOS • Android Seguro 100%
1. Como baixar e instalar o OCR
Ao abrir o documento, navegue até a opção Ferramentas no canto superior esquerdo da tela. Agora, no menu Ferramentas, escolha a opção OCR para iniciar o processo. Se for a primeira vez que você usa o UPDF OCR, será exibida uma janela para instalar o OCR.
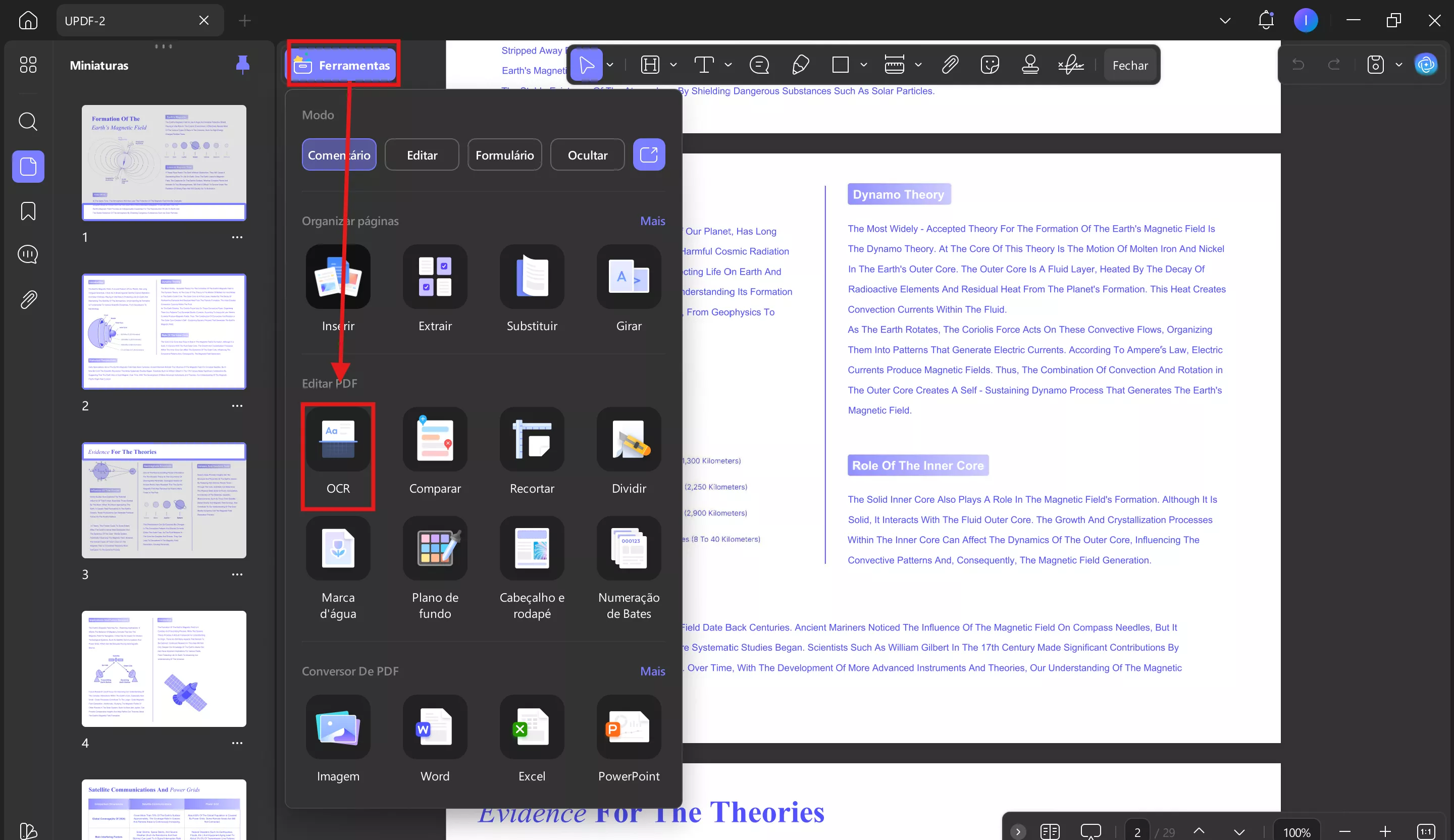
2. Como fazer OCR em PDFs
Após a instalação, feche a janela e navegue até a mesma opção Ferramentas para acessar a ferramenta de OCR no UPDF. Ao abrir, serão exibidas três opções diferentes de Tipo de Documento, incluindo PDF Editável, Somente Texto e Imagem e Somente PDF Pesquisável.
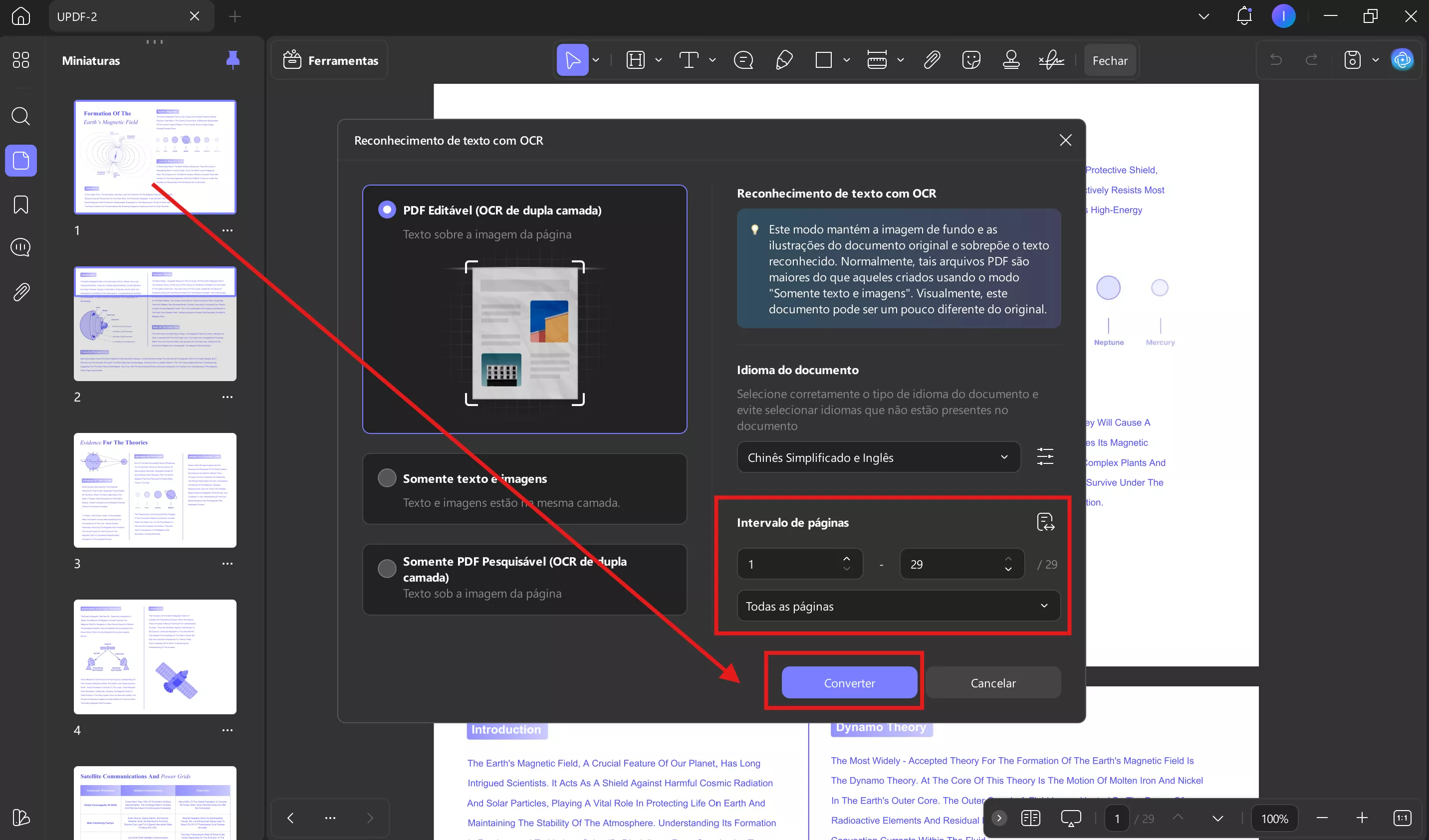
- PDF editável: Este modo salva textos e imagens reconhecidos. Um arquivo PDF deste tipo tem um tamanho relativamente pequeno. Visualmente, este documento pode diferir ligeiramente do original.
- Somente texto e imagem: Este modo mantém a imagem de fundo e as ilustrações do documento de origem e sobrepõe o texto reconhecido. Normalmente, esses arquivos PDF são maiores do que aqueles criados usando o modo Somente texto e imagens. Visualmente, este documento pode ser ligeiramente diferente do original.
- Somente PDF pesquisável: Neste modo, a imagem da página é mantida, enquanto o texto reconhecido é colocado em uma camada invisível abaixo da imagem. Visualmente, este documento é quase idêntico ao original. 2.1 Tipo de documento: PDF pesquisável
Defina um idioma de documento adequado com a opção de 38 idiomas diferentes no menu suspenso. Isso fornece ao UPDF uma base melhor para reconhecer texto com precisão em todo o documento.
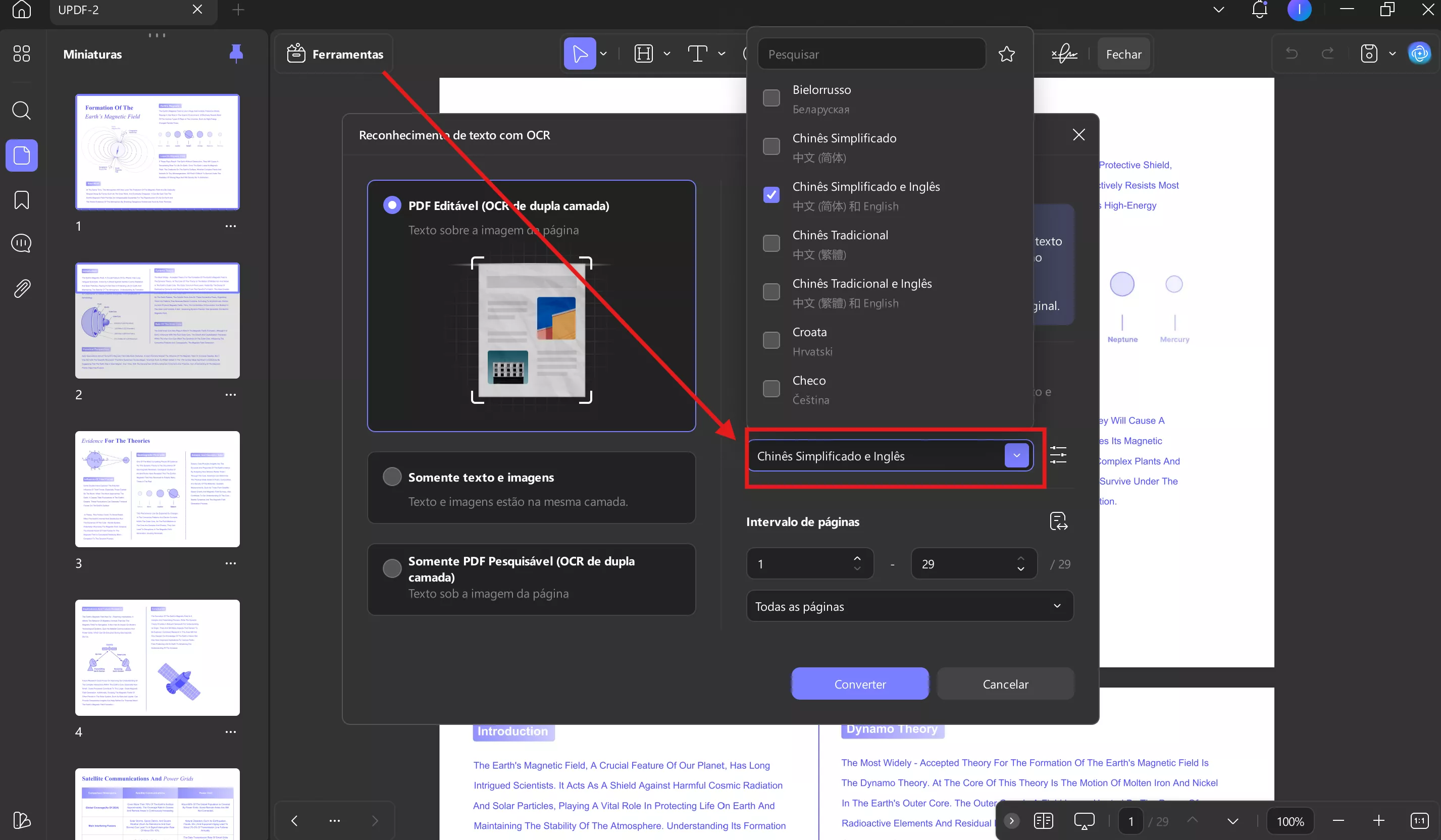
Trabalhe no Intervalo de Páginas e escolha as páginas manualmente ou expanda o menu para selecionar as opções Todas as Páginas, Páginas Pares e Páginas Ímpares na lista. Uma vez feito isso, pressione o botão Converter para executar o OCR em todas as páginas.
O teste do recurso OCR na versão de teste gratuita é gratuito. No entanto, você só pode experimentar, não pode salvar, copiar ou editar o PDF com OCR. Para ter todos os recursos necessários, você pode fazer o upgrade para a versão profissional.
Windows • macOS • iOS • Android Seguro 100%