 UPDF สำหรับ Windows
UPDF สำหรับ Windows UPDF สำหรับ Mac
UPDF สำหรับ Mac UPDF สำหรับ iPhone/iPad
UPDF สำหรับ iPhone/iPad UPDF สำหรับ Android
UPDF สำหรับ Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft แก้ไข PDF
แก้ไข PDF ใส่คำอธิบาย PDF
ใส่คำอธิบาย PDF สร้าง PDF
สร้าง PDF ฟอร์ม PDF
ฟอร์ม PDF แก้ไขลิงก์
แก้ไขลิงก์ แปลง PDF
แปลง PDF OCR
OCR PDF เป็น Word
PDF เป็น Word PDF เป็นรูปภาพ
PDF เป็นรูปภาพ PDF เป็น Excel
PDF เป็น Excel จัดระเบียบ PDF
จัดระเบียบ PDF รวม PDF
รวม PDF แยก PDF
แยก PDF ครอบตัด PDF
ครอบตัด PDF หมุน PDF
หมุน PDF ป้องกัน PDF
ป้องกัน PDF เซ็น PDF
เซ็น PDF ลบข้อความ PDF
ลบข้อความ PDF ล้าง PDF
ล้าง PDF เอาความปลอดภัยออก
เอาความปลอดภัยออก อ่าน PDF
อ่าน PDF UPDF Cloud
UPDF Cloud บีบอัด PDF
บีบอัด PDF พิมพ์ PDF
พิมพ์ PDF ประมวลผลเป็นชุด
ประมวลผลเป็นชุด เกี่ยวกับ UPDF AI
เกี่ยวกับ UPDF AI โซลูชั่น UPDF AI
โซลูชั่น UPDF AI คู่มือผู้ใช้ AI
คู่มือผู้ใช้ AI คำถามที่พบบ่อยเกี่ยวกับ UPDF AI
คำถามที่พบบ่อยเกี่ยวกับ UPDF AI สรุป PDF
สรุป PDF แปล PDF
แปล PDF แชทกับ PDF
แชทกับ PDF สนทนากับ AI
สนทนากับ AI แชทด้วยรูปภาพ
แชทด้วยรูปภาพ PDF เป็นแผนที่ความคิด
PDF เป็นแผนที่ความคิด อธิบาย PDF
อธิบาย PDF เครื่องมือ AI สำหรับ PDF
เครื่องมือ AI สำหรับ PDF เครื่องมือ AI สำหรับรูปภาพ
เครื่องมือ AI สำหรับรูปภาพ เครื่องมือแชท AI
เครื่องมือแชท AI เครื่องมือเขียน AI
เครื่องมือเขียน AI เครื่องมือการเรียนรู้ AI
เครื่องมือการเรียนรู้ AI เครื่องมือการทำงาน AI
เครื่องมือการทำงาน AI เครื่องมือ AI อื่น ๆ
เครื่องมือ AI อื่น ๆ การสร้างบุ๊กมาร์กด้วย AI
การสร้างบุ๊กมาร์กด้วย AI สรุปบุ๊กมาร์กด้วย AI
สรุปบุ๊กมาร์กด้วย AI สร้างลายน้ำด้วย AI
สร้างลายน้ำด้วย AI สร้างพื้นหลังด้วย AI
สร้างพื้นหลังด้วย AI สร้างสติกเกอร์ด้วย AI
สร้างสติกเกอร์ด้วย AI สร้างตราประทับด้วย AI
สร้างตราประทับด้วย AI ชุดเครื่องมือเขียนด้วย AI
ชุดเครื่องมือเขียนด้วย AI UPDF Copilot
UPDF Copilot จัดการหน้าด้วย AI
จัดการหน้าด้วย AI ค้นหาเชิงความหมายด้วย AI
ค้นหาเชิงความหมายด้วย AI แปลง PDF เป็น Word
แปลง PDF เป็น Word แปลง PDF เป็น Excel
แปลง PDF เป็น Excel แปลง PDF เป็น PowerPoint
แปลง PDF เป็น PowerPoint คู่มือการใช้งาน
คู่มือการใช้งาน เคล็ดลับ UPDF
เคล็ดลับ UPDF คำถามที่พบบ่อย
คำถามที่พบบ่อย รีวิว UPDF
รีวิว UPDF ศูนย์ดาวน์โหลด
ศูนย์ดาวน์โหลด บล็อก
บล็อก ห้องข่าว
ห้องข่าว ข้อมูลจำเพาะทางเทคนิค
ข้อมูลจำเพาะทางเทคนิค อัปเดต
อัปเดต UPDF เทียบกับ Adobe Acrobat
UPDF เทียบกับ Adobe Acrobat UPDF เทียบกับ Foxit
UPDF เทียบกับ Foxit UPDF เทียบกับ PDF Expert
UPDF เทียบกับ PDF Expert
ไม่ทราบว่าจะค้นหาใน PDF ที่สแกนแล้ว ซึ่งระบุว่า "หน้านี้มีเฉพาะรูปภาพ" ได้อย่างไร หรือคุณพยายามค้นหาคำโดยใช้ฟีเจอร์ค้นหาของ Windows หรือ CTRL + F แต่ก็ไม่สำเร็จใช่หรือไม่ คุณคงกำลังค้นหาใน PDF ที่สแกนอยู่ หากคุณสงสัยว่าจะค้นหาในเอกสาร PDF ที่สแกนได้อย่างไร เรามีคำตอบให้คุณ! เจาะลึกลงไปเพื่อดูว่าทำอย่างไร
จะค้นหาคำใน PDF ที่สแกนได้อย่างไร?
ปัญหาคือเอกสารที่สแกนไม่มีข้อความใดๆ อยู่ในนั้น เนื่องจากเป็นเพียงรูปภาพของเอกสาร จึงไม่มีข้อความใดๆ ให้ Windows สร้างดัชนี
หากต้องการให้ PDF ของคุณสามารถค้นหาได้ คุณต้องใช้ฟังก์ชันการจดจำข้อความเพื่อให้สามารถค้นหาและแก้ไขเนื้อหาในหน้าได้ คุณสามารถใช้ซอฟต์แวร์ฟังก์ชัน OCR (Optical Character Recognition) ใดก็ได้ ซอฟต์แวร์จะสแกนเอกสาร ระบุสิ่งที่คล้ายกับตัวอักษรหรือคำ แล้วแปลงเป็นข้อความจริง
โปรแกรมแก้ไข PDF หลายโปรแกรมมีฟังก์ชันนี้ แต่เราขอแนะนำ UPDF ซึ่งเป็นโซลูชัน PDF แบบครบวงจรสำหรับคุณ! เป็นฟีเจอร์ OCR ที่ขับเคลื่อนด้วย AI ที่แปลง PDF ที่สแกน เอกสารกระดาษ และรูปภาพของคุณเป็น PDF ที่ค้นหาและแก้ไขได้ โดยมีรูปแบบเอาต์พุตสามแบบเพื่อให้เป็นแบบโต้ตอบได้และตอบสนองทุกความต้องการของคุณ เรียนรู้เพิ่มเติมเกี่ยวกับฟีเจอร์ OCR ของ UPDF ได้จากการอ่านบทความนี้ดาวน์โหลด UPDF ก่อนที่เราจะเริ่มแนะนำคำแนะนำ
Windows • macOS • iOS • Android ปลอดภัย 100%

ต่อไปนี้เป็นคุณสมบัติที่น่าประทับใจบางประการของซอฟต์แวร์ OCR นี้ :
- ความแม่นยำสูงถึง 99%: เทคโนโลยี OCR ขั้นสูงของ UPDF มอบผลลัพธ์ที่มีความแม่นยำสูง!
- ความเร็ว OCR สูงสุด: ใครบ้างที่ไม่ต้องการประหยัดเวลา UPDF เข้าใจเรื่องนี้ ดังนั้นการแปลงจึงรวดเร็วมากเมื่อเทียบกับคู่แข่ง
- เอาต์พุตขนาดเล็กคุณภาพสูง: ขนาดของเอกสาร PDF ที่แปลงแล้วจะเล็กกว่าขนาดเดิมมาก!
- รองรับ 38 ภาษา: นอกจากนี้ยังรองรับเอกสารสองภาษาและให้คุณเลือกชุดภาษาต่างๆ ได้หลายชุด
นอกจากนี้ โปรแกรมยังอ่าน จัดระเบียบ และใส่คำอธิบายประกอบ PDF ของคุณ และแปลงไฟล์ PDF ที่สแกนได้ทุกขนาด! แล้วคุณยังรออะไรอีก? ทำตามขั้นตอนง่ายๆ ด้านล่างเพื่อค้นหาคำใน PDF ที่สแกน และแก้ไขปัญหาของคุณได้ทันที! เพียงไม่กี่ขั้นตอนง่ายๆ ก็เสร็จเรียบร้อยอย่างรวดเร็ว!
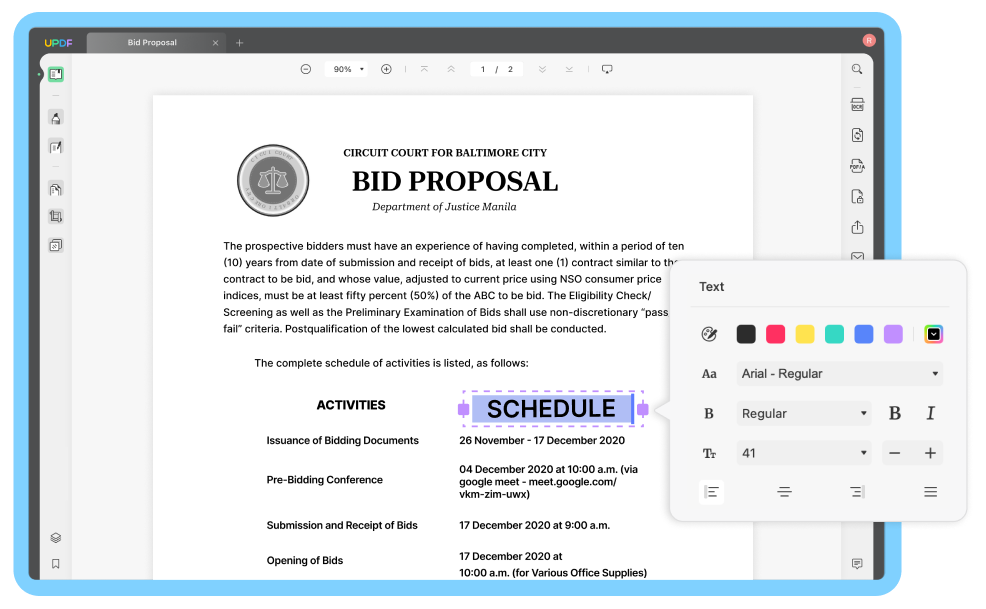
ขั้นตอนที่ 1: เปิด PDF และเข้าถึงไอคอน OCR
คลิก " เปิดไฟล์ " เพื่อนำเข้าไฟล์ PDF นอกจากนี้คุณยังสามารถใช้ปุ่มลัด Ctrl + หรือ Cmd + O ได้อีกด้วย
คลิกตัวเลือก " จดจำข้อความโดยใช้ OCR " บนแถบเครื่องมือทางขวา (หากนี่เป็นครั้งแรกที่คุณใช้ฟีเจอร์นี้ ระบบจะนำคุณไปยังหน้าดาวน์โหลดปลั๊กอิน ดาวน์โหลดในหน้าต่างถัดไป และรอจนกว่าจะติดตั้งเสร็จ)
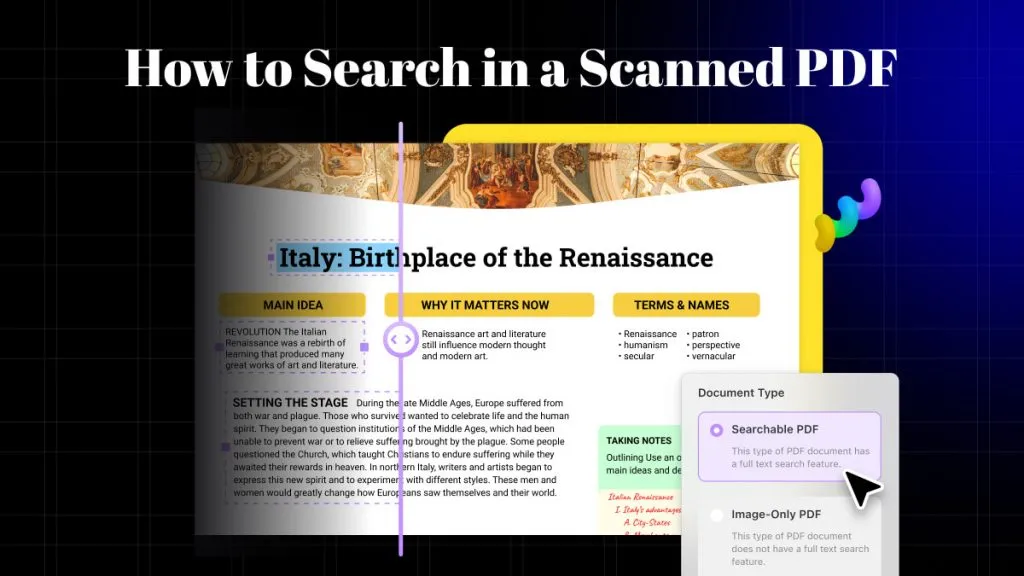
ขั้นตอนที่ 2: เปลี่ยน PDF ที่สแกนให้เป็นแบบค้นหาได้
เมื่อติดตั้งแล้ว ให้คลิกปุ่ม "จดจำข้อความโดยใช้ OCR" อีกครั้ง คุณจะได้รับตัวเลือกประเภทเอกสารสองแบบ เลือก " PDF ที่ค้นหาได้ " เพราะตัวเลือกนี้จะแปลงเอกสารที่สแกนเป็น เอกสารที่แก้ไขและค้นหาได้
คุณต้องตัดสินใจเลือกเค้าโครงจากตัวเลือก "ข้อความและรูปภาพเท่านั้น" "ข้อความบนภาพหน้า" และ "ข้อความใต้ภาพหน้า" นอกจากนี้ คุณต้องตัดสินใจเลือกภาษาเอกสาร ความละเอียดของภาพ และช่วงกระดาษด้วย
สำหรับตัวเลือกเค้าโครงขั้นสูง ให้คลิกที่ไอคอน 'เฟือง' เพื่อเข้าถึงการตั้งค่าเค้าโครงเพิ่มเติม เช่น:
- หากคุณเลือก 'เก็บภาพ' คุณจะต้องตัดสินใจเลือกคุณภาพ ('ต่ำ' 'สมดุล' หรือ 'สูง')
- การบีบอัดรูปภาพ
- เก็บองค์ประกอบเอกสารอื่นๆ (ส่วนหัว ส่วนท้าย หมายเลขหน้า ข้อความ และสีพื้นหลัง)
คลิกที่ตัวเลือก " ดำเนินการ OCR " จากนั้นเลือกตำแหน่งที่คุณต้องการบันทึกไฟล์ และคลิก "บันทึก"

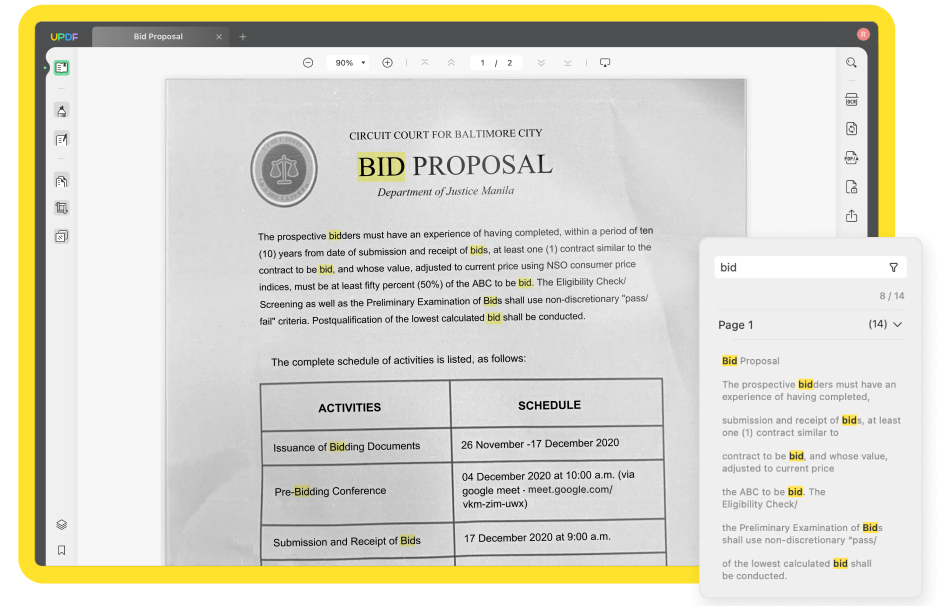
ขั้นตอนที่ 3: ค้นหาคำใน PDF ที่สแกน
หลังจากทำ OCR แล้ว ไฟล์ PDF ที่ค้นหาได้จะเปิดขึ้นใน UPDF โดยอัตโนมัติ ตอนนี้คุณสามารถค้นหาคำที่ต้องการใน PDF ที่สแกนได้โดยคลิก Ctrl + F หรือไอคอนค้นหา ที่มุมขวาบน
ป้อนคำที่คุณต้องการค้นหา จากนั้นระบบจะแสดงผลลัพธ์ทั้งหมดในเอกสารนี้ คุณสามารถคลิกผลลัพธ์ใดๆ เพื่อข้ามไปยังหน้าโดยตรง นี่คือวิธีค้นหาคำใน PDF ได้อย่างง่ายดาย

หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการ OCR ไฟล์ PDF โปรดดูวิดีโอแนะนำด้านล่าง
โบนัส
เคล็ดลับ: ฉันควรเลือกเค้าโครงใดเมื่อดำเนินการ OCR?
สำหรับ PDF ที่ค้นหาได้ คุณต้องเลือกเค้าโครงที่เหมาะสมโดยขึ้นอยู่กับวัตถุประสงค์หรือสถานการณ์ที่คุณใช้เค้าโครงนั้น โดยใช้ตัวเลือกที่มี คุณสามารถเลือกอย่างใดอย่างหนึ่งต่อไปนี้:
ข้อความและรูปภาพเท่านั้น:
OCR จะจดจำและบันทึกข้อความและรูปภาพในไฟล์ PDF ลงในไฟล์ขนาดเล็กลง จะไม่มีเลเยอร์รูปภาพโปร่งใสเพื่อรักษาการจัดรูปแบบให้คงเดิม ดังนั้น ภาพของไฟล์ที่แปลงแล้วอาจแตกต่างจากเวอร์ชันต้นฉบับ
ข้อความบนภาพหน้า:
โหมดนี้จะเก็บภาพประกอบและภาพพื้นหลังในไฟล์ต้นฉบับไว้เป็นเลเยอร์ใต้ข้อความของเอกสาร โดยจะรักษารูปแบบดั้งเดิมของเอกสารเอาไว้ แม้ว่าไฟล์เหล่านี้จะมีขนาดใหญ่กว่า แต่ภาพที่ปรากฏจะแตกต่างไปจากไฟล์ต้นฉบับ

ข้อความใต้ภาพหน้า:
รูปภาพ PDF จะยังคงอยู่ แต่ข้อความจะอยู่ใต้รูปภาพภายใต้เลเยอร์ที่มองไม่เห็น ดังนั้นการจัดรูปแบบของเอกสารจะคงอยู่โดยการวางเลเยอร์ไว้เหนือข้อความ ประเภทไฟล์นี้จะเหมือนกับไฟล์ต้นฉบับทุกประการ สามารถค้นหาข้อความได้ แต่ไม่สามารถแก้ไขได้
คำถามที่พบบ่อยเกี่ยวกับวิธีค้นหาในไฟล์ PDF ที่สแกน
หากคุณมีคำถามเกี่ยวกับวิธีการค้นหาคำในไฟล์ PDF ที่สแกน ไม่ต้องกังวล เราช่วยคุณได้
ทำไมฉันจึงค้นหาไฟล์ PDF ที่สแกนไม่ได้
เมื่อคุณสแกนเอกสาร สแกนเนอร์จะจับภาพหน้าต่างๆ เป็นภาพแบน ซึ่งหมายความว่าไม่มีข้อความที่ Windows สามารถสร้างดัชนีหรือโปรแกรมอ่าน PDF ใดๆ สามารถอ่านได้ คุณจะต้องใช้ฟีเจอร์ OCR ของ UPDF เพื่อแปลงเอกสารที่สแกนเป็นรูปแบบที่อ่านได้ดังที่อธิบายไว้ข้างต้นในบทความนี้
ฉันใช้ Ctrl F กับเอกสารที่สแกนได้หรือไม่
ไม่ได้ ฟีเจอร์ค้นหาของ Windows นี้ใช้งานได้กับเอกสารที่มีข้อความที่อ่านได้เท่านั้น คุณสามารถใช้ฟีเจอร์นี้ได้โดยดาวน์โหลดซอฟต์แวร์ที่รองรับเทคโนโลยี OCR เช่น UPDF เท่านั้น ซึ่งจะแปลงการสแกนเป็น PDF ที่สามารถค้นหาได้
ทำไมฉันจึงใช้ Ctrl F กับ PDF ไม่ได้
ฟีเจอร์ค้นหาไม่ทำงานกับเอกสารหรือ PDF ที่มีรูปภาพเท่านั้น เช่น ในกรณีของเอกสารที่สแกน รูปภาพเหล่านี้ไม่มีข้อความที่ Windows สามารถจดจำได้
บทสรุป
คุณคิดไม่ออกว่าจะค้นหาคำในเอกสาร PDF ที่สแกนได้อย่างไร ไม่ต้องกังวล UPDF คือโซลูชันที่ดีที่สุดสำหรับคุณ ฟังก์ชัน OCR เข้าถึงได้ง่ายและใช้งานง่าย และยังสามารถตรวจจับข้อความในเอกสารที่สแกนแบบเบลอได้ ซึ่งเป็นสิ่งที่แม้แต่ซอฟต์แวร์อื่นยังไม่สามารถทำได้ คุณสามารถแปลงรูปภาพใดๆ ให้เป็นข้อความที่ตรวจจับได้ด้วยอัลกอริทึมการบีบอัดรูปภาพขั้นสูงตาม MRC หรือเปลี่ยน PDF เป็นเอกสารที่มีแต่รูปภาพ!
คุณกำลังรออะไรอยู่ ดาวน์โหลด UPDF เลยตอนนี้เพื่อให้คุณสามารถโต้ตอบกับ PDF ของคุณได้อย่างง่ายดายและมีประสบการณ์ที่ราบรื่นยิ่งขึ้นด้วยเครื่องมือ AI ที่ยอดเยี่ยม คุณยังสามารถอัปเกรด เป็นเวอร์ชันพรีเมียมเพื่อปลดล็อกคุณสมบัติทั้งหมดโดยไม่มีข้อจำกัดใดๆ ทั้งหมดนี้ทำให้คำแนะนำของเราเกี่ยวกับวิธีการค้นหาใน PDF ที่สแกนเสร็จสมบูรณ์
Windows • macOS • iOS • Android ปลอดภัย 100%







 Thanakorn Srisuwan
Thanakorn Srisuwan 

