 UPDF para Windows
UPDF para Windows UPDF para Mac
UPDF para Mac UPDF para iPhone/iPad
UPDF para iPhone/iPad UPDF para Android
UPDF para Android UPDF AI ONLINE
UPDF AI ONLINE UPDF Sign
UPDF Sign Editar PDF
Editar PDF Anotar PDF
Anotar PDF Crear PDF
Crear PDF Formulario PDF
Formulario PDF Editar enlaces
Editar enlaces Convertir PDF
Convertir PDF OCR
OCR PDF a Word
PDF a Word PDF a imagen
PDF a imagen PDF a Excel
PDF a Excel Organizar PDF
Organizar PDF Combinar PDF
Combinar PDF Dividir PDF
Dividir PDF Recortar PDF
Recortar PDF Girar PDF
Girar PDF Proteger PDF
Proteger PDF Firmar PDF
Firmar PDF Redactar PDF
Redactar PDF Desinfectar PDF
Desinfectar PDF Eliminar seguridad
Eliminar seguridad Leer PDF
Leer PDF UPDF Cloud
UPDF Cloud Comprimir PDF
Comprimir PDF Imprimir PDF
Imprimir PDF Proceso por lotes
Proceso por lotes Sobre UPDF IA
Sobre UPDF IA Soluciones de UPDF IA
Soluciones de UPDF IA Guía de Usuario de IA
Guía de Usuario de IA Preguntas frecuentes sobre UPDF IA
Preguntas frecuentes sobre UPDF IA Resumir PDF
Resumir PDF Traducir PDF
Traducir PDF Chat con PDF
Chat con PDF Chat con imagen
Chat con imagen PDF a Mapa Mental
PDF a Mapa Mental Chat con IA
Chat con IA Explicar PDF
Explicar PDF Herramientas IA para PDF
Herramientas IA para PDF Herramientas IA para Imagen
Herramientas IA para Imagen Herramientas IA de Chat
Herramientas IA de Chat Herramientas IA de Redacción
Herramientas IA de Redacción Herramientas IA de Estudio
Herramientas IA de Estudio Herramientas IA de Trabajo
Herramientas IA de Trabajo Otras Herramientas IA
Otras Herramientas IA Generación de Marcadores con IA
Generación de Marcadores con IA Resumen de Marcadores con IA
Resumen de Marcadores con IA Generación de Marcas de Agua con IA
Generación de Marcas de Agua con IA Generación de Fondos con IA
Generación de Fondos con IA Generación de Pegatinas con IA
Generación de Pegatinas con IA Generación de Sellos con IA
Generación de Sellos con IA Suite de Escritura con IA
Suite de Escritura con IA UPDF Copilot
UPDF Copilot Gestión de Páginas con IA
Gestión de Páginas con IA Búsqueda Semántica con IA
Búsqueda Semántica con IA PDF a Word
PDF a Word PDF a Excel
PDF a Excel PDF a PowerPoint
PDF a PowerPoint Guía del Usuario
Guía del Usuario Trucos de UPDF
Trucos de UPDF Preguntas Frecuentes
Preguntas Frecuentes Reseñas de UPDF
Reseñas de UPDF Centro de descargas
Centro de descargas Blog
Blog Sala de prensa
Sala de prensa Especificaciones Técnicas
Especificaciones Técnicas Actualizaciones
Actualizaciones UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
OCR PDFs con UPDF en Mac
La función OCR de UPDF para Mac te permite convertir documentos PDF escaneados o con solo imagen en documentos editables y con capacidad de búsqueda. Además, te permite convertir tus PDF editables y con capacidad de búsqueda en documentos con solo imagen. Puedes hacer clic en el botón de abajo para descargar UPDF en Mac y seguir los pasos a continuación para aprender a usarlo.
Ahora, lo guiaremos a través del uso de la función OCR UPDF en Mac.
Como apoyo a las instrucciones dadas, le mostramos este video explicativo.
Windows • macOS • iOS • Android 100% Seguro
Paso 1. Descargue e instale OCR (solo para nuevos usuarios)
Si es la primera vez que usa esta herramienta, debe descargar el complemento de OCR para UPDF. Para ello, vaya a la opción Herramientas en la esquina superior izquierda y seleccione la opción OCR en la sección Editar PDF .
- Continúe el proceso haciendo clic en el botón Instalar en la ventana emergente.
- Serás redirigido automáticamente a la siguiente ventana, que mostrará el progreso de la instalación de la función. Espera a que se instale correctamente en tu Mac antes de usarla.
Paso 2. OCR PDF con UPDF para Mac
Después de la instalación, cierre la ventana, navegue hasta la misma opción Herramientas y presione la opción OCR en el menú.
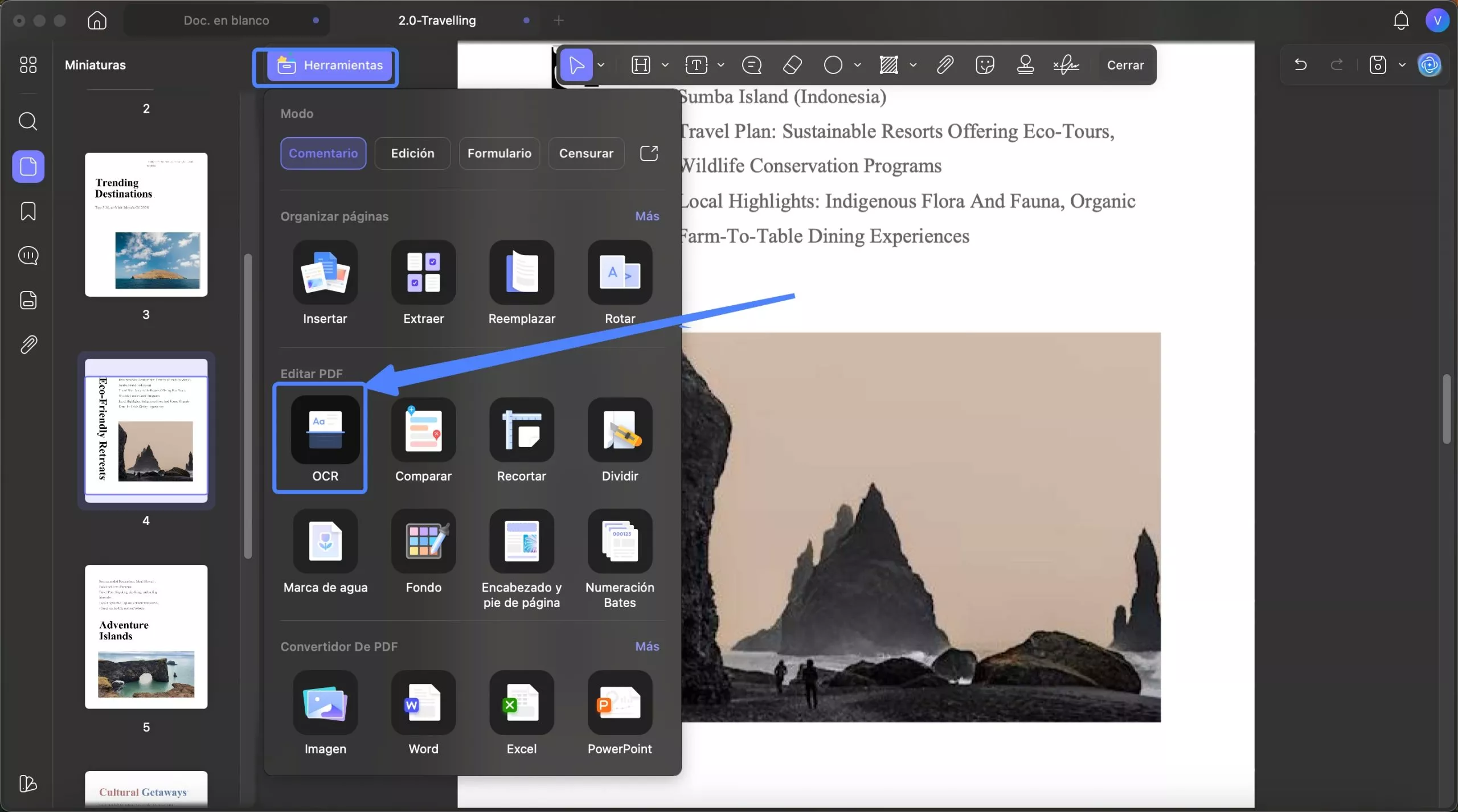
A continuación se abrirá una nueva ventana que le proporcionará 3 opciones para el Tipo de documento .
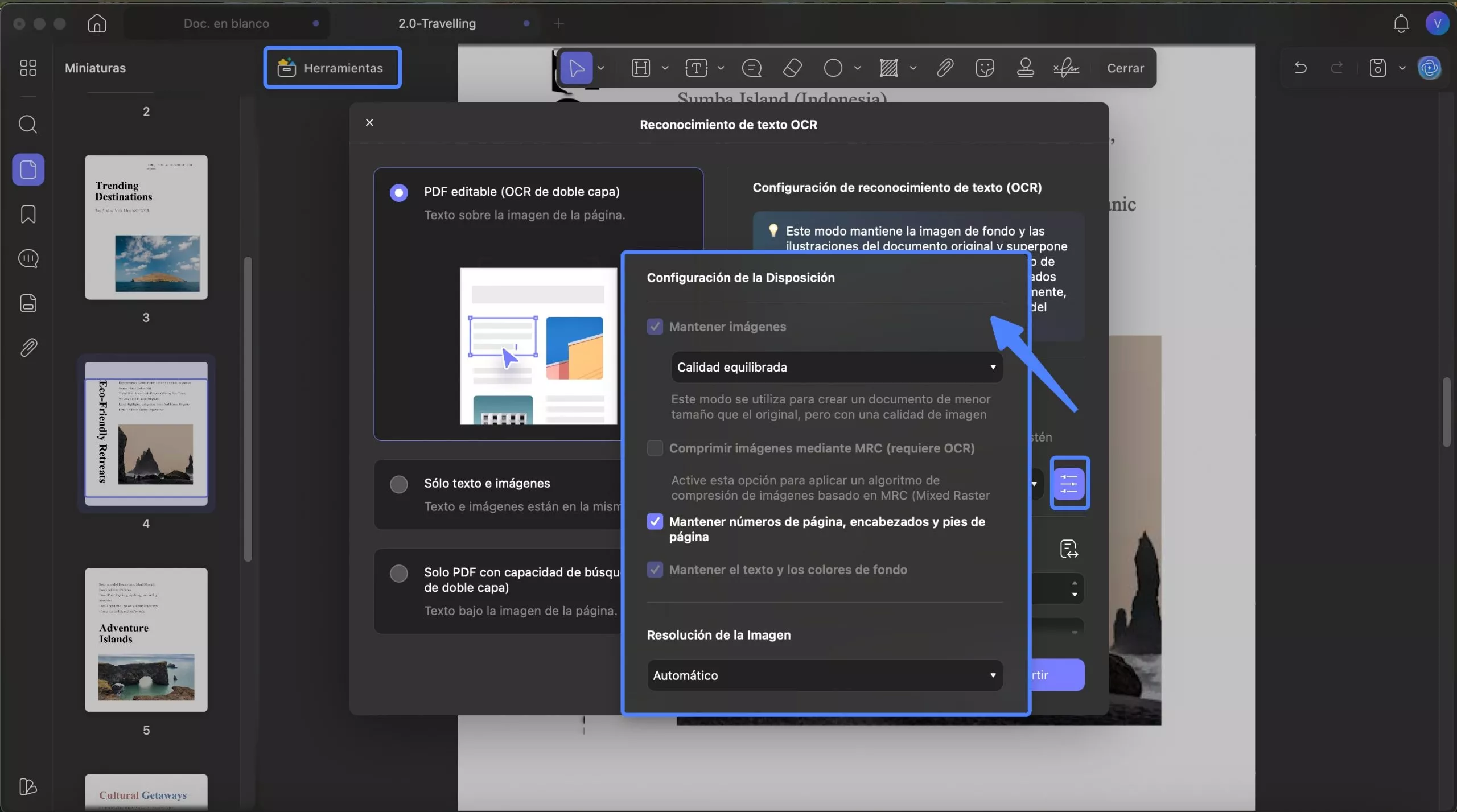
1. PDF editable (OCR de doble capa)
Al seleccionar este modo de OCR, se guardan el texto y las imágenes reconocidos, que difieren ligeramente del documento original. Sin embargo, antes de realizar el OCR, puede configurar las propiedades como se muestra en la imagen y se describe brevemente.
- Configuración de diseño: en la ventana de configuración de diseño , puede ajustar la calidad con opciones que incluyen Calidad equilibrada, Alta calidad y Baja calidad para mantener las imágenes .
Proporciona opciones para marcar Comprimir imágenes usando MRC , Mantener números de página, encabezados y pies de página, o Mantener colores de texto y fondo .
Además de esto, puedes mejorar la resolución de la imagen entre Automático, 300, 150 y 72 DPI .
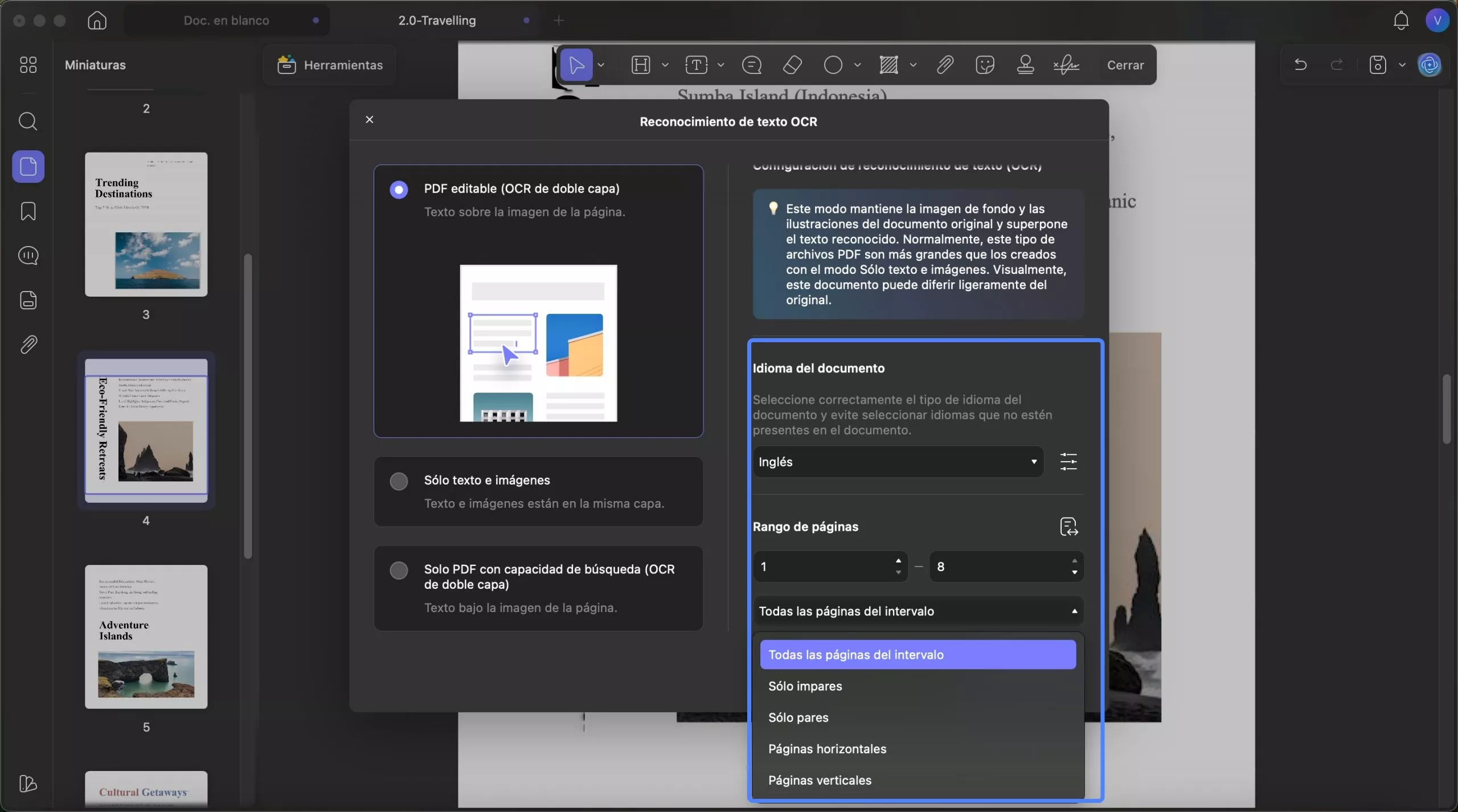
- Idioma del documento: UPDF proporciona 38 idiomas para que usted seleccione antes del OCR.
- Rango de páginas: con esta opción, puede elegir manualmente el rango de páginas o acceder a las opciones para Todas las páginas , Páginas pares e Impares .
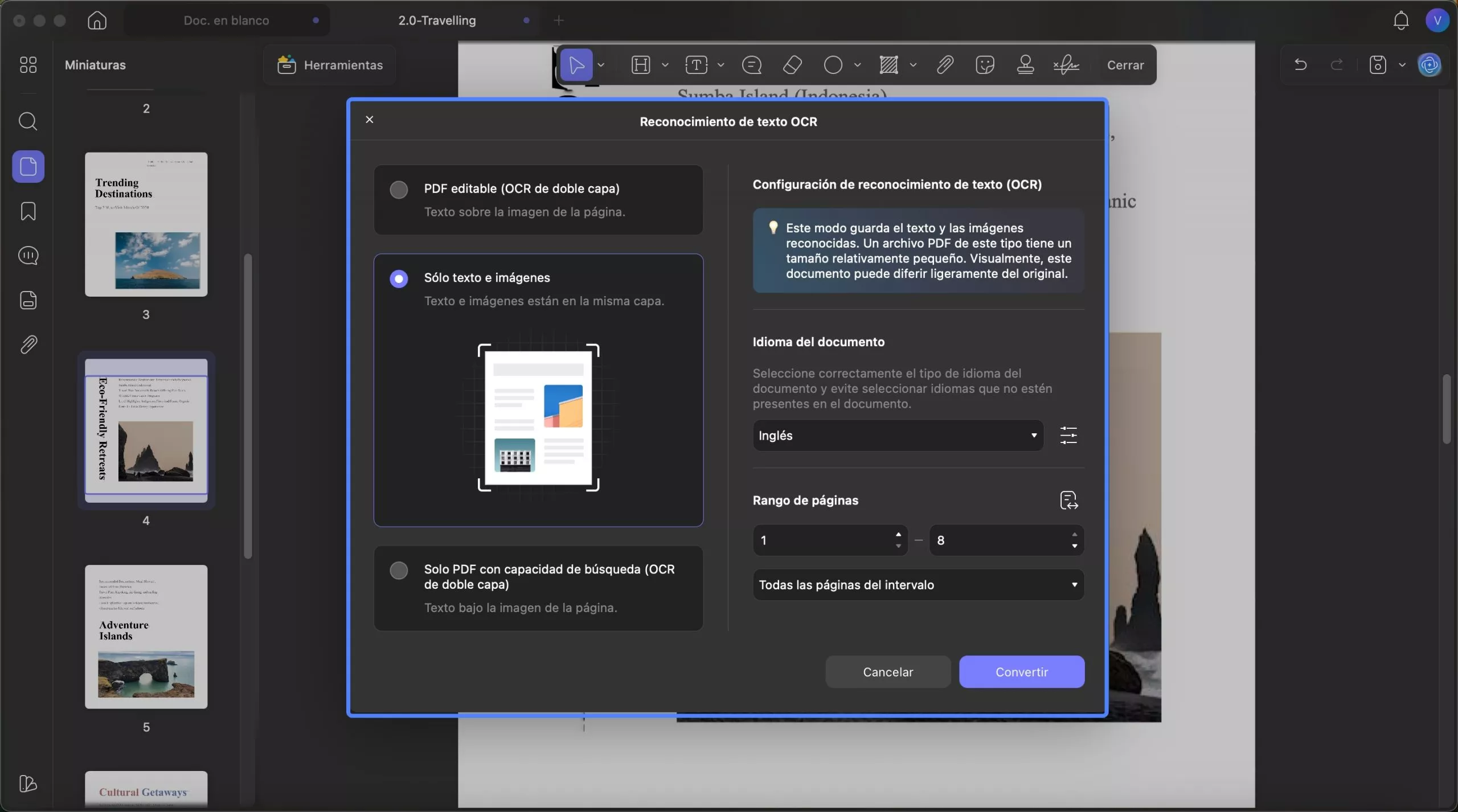
2. Solo texto e imagen
Este modo almacena la imagen de fondo y las ilustraciones del documento original, superponiéndolas al texto reconocido. Para configurar las propiedades antes del OCR, consulte la captura de pantalla a continuación. Sin embargo, ofrece configuraciones de documento similares a las descritas para PDF editables .
3. Solo PDF con capacidad de búsqueda (OCR de doble capa)
En este modo, se conserva la imagen de la página, mientras que el texto reconocido se coloca en una capa invisible debajo de la imagen. Además, este tipo de documento es prácticamente idéntico al original. En cuanto a la configuración de diseño y otras propiedades, consulte la captura de pantalla proporcionada:
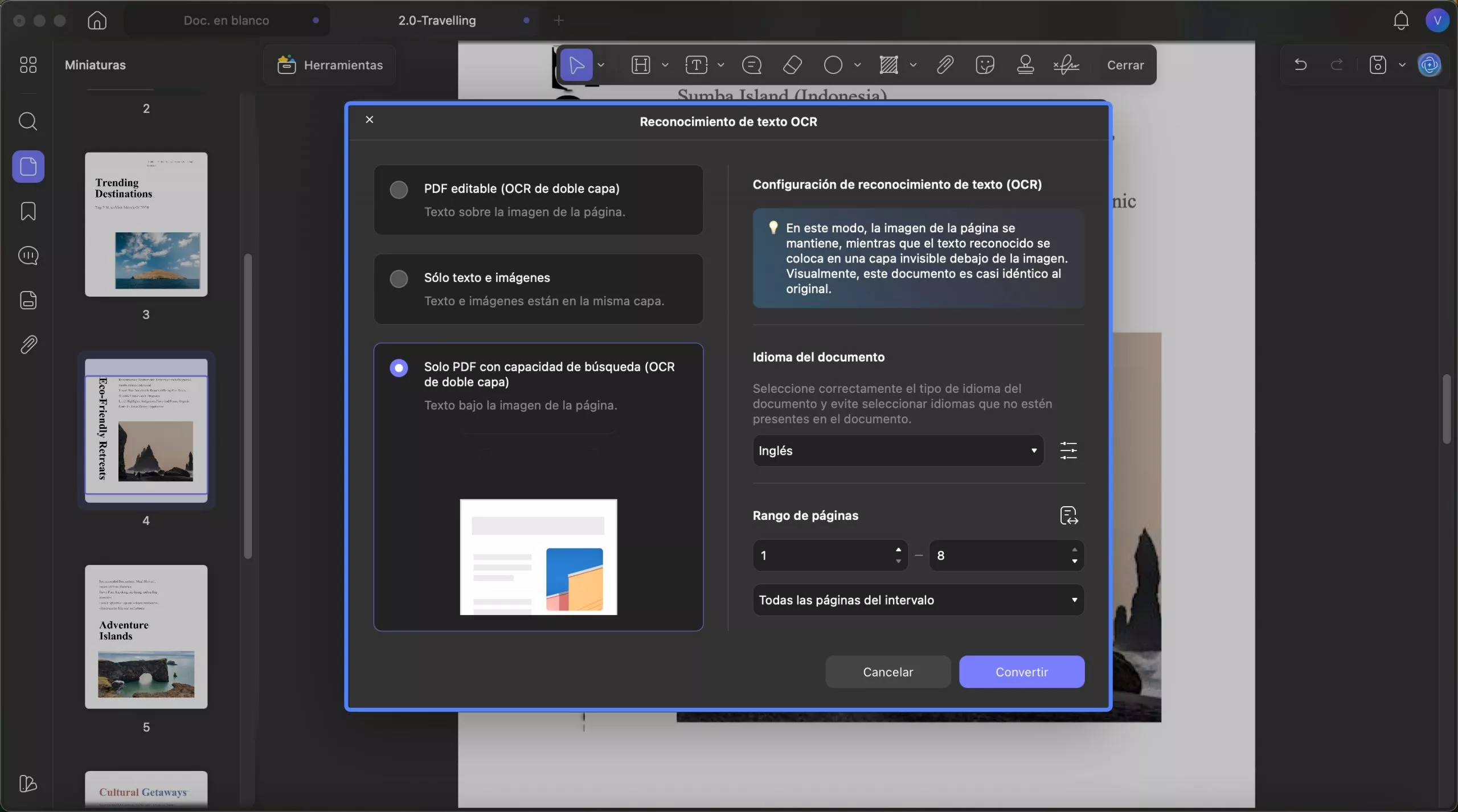
Al finalizar la configuración, puede hacer clic en el botón Convertir para seleccionar dónde desea guardar el PDF con OCR. Una vez finalizado el proceso, el PDF con OCR se abrirá automáticamente en UPDF. Ahora puede hacer clic en Editar PDF para realizar cambios o hacer clic en el icono Guardar para guardarlo en su dispositivo después de realizarlos.
Puedes probar el OCR en la versión de prueba gratuita. Si te gusta, puedes actualizar a la versión pro haciendo clic aquí con un gran descuento.