 UPDF para Windows
UPDF para Windows UPDF para Mac
UPDF para Mac UPDF para iPhone/iPad
UPDF para iPhone/iPad UPDF para Android
UPDF para Android Nomostar
Nomostar UPDF AI ONLINE
UPDF AI ONLINE UPDF Sign
UPDF Sign IvyCraft
IvyCraft Editar PDF
Editar PDF Anotar PDF
Anotar PDF Crear PDF
Crear PDF Formulario PDF
Formulario PDF Editar enlaces
Editar enlaces Convertir PDF
Convertir PDF OCR
OCR PDF a Word
PDF a Word PDF a imagen
PDF a imagen PDF a Excel
PDF a Excel Organizar PDF
Organizar PDF Combinar PDF
Combinar PDF Dividir PDF
Dividir PDF Recortar PDF
Recortar PDF Girar PDF
Girar PDF Proteger PDF
Proteger PDF Firmar PDF
Firmar PDF Redactar PDF
Redactar PDF Desinfectar PDF
Desinfectar PDF Eliminar seguridad
Eliminar seguridad Leer PDF
Leer PDF UPDF Cloud
UPDF Cloud Comprimir PDF
Comprimir PDF Imprimir PDF
Imprimir PDF Proceso por lotes
Proceso por lotes Sobre UPDF IA
Sobre UPDF IA Soluciones de UPDF IA
Soluciones de UPDF IA Guía de Usuario de IA
Guía de Usuario de IA Preguntas frecuentes sobre UPDF IA
Preguntas frecuentes sobre UPDF IA Resumir PDF
Resumir PDF Traducir PDF
Traducir PDF Chat con PDF
Chat con PDF Chat con imagen
Chat con imagen PDF a Mapa Mental
PDF a Mapa Mental Chat con IA
Chat con IA Explicar PDF
Explicar PDF Herramientas IA para PDF
Herramientas IA para PDF Herramientas IA para Imagen
Herramientas IA para Imagen Herramientas IA de Chat
Herramientas IA de Chat Herramientas IA de Redacción
Herramientas IA de Redacción Herramientas IA de Estudio
Herramientas IA de Estudio Herramientas IA de Trabajo
Herramientas IA de Trabajo Otras Herramientas IA
Otras Herramientas IA Generación de Marcadores con IA
Generación de Marcadores con IA Resumen de Marcadores con IA
Resumen de Marcadores con IA Generación de Marcas de Agua con IA
Generación de Marcas de Agua con IA Generación de Fondos con IA
Generación de Fondos con IA Generación de Pegatinas con IA
Generación de Pegatinas con IA Generación de Sellos con IA
Generación de Sellos con IA Suite de Escritura con IA
Suite de Escritura con IA UPDF Copilot
UPDF Copilot Gestión de Páginas con IA
Gestión de Páginas con IA Búsqueda Semántica con IA
Búsqueda Semántica con IA PDF a Word
PDF a Word PDF a Excel
PDF a Excel PDF a PowerPoint
PDF a PowerPoint Guía del Usuario
Guía del Usuario Trucos de UPDF
Trucos de UPDF Preguntas Frecuentes
Preguntas Frecuentes Reseñas de UPDF
Reseñas de UPDF Centro de descargas
Centro de descargas Blog
Blog Sala de prensa
Sala de prensa Especificaciones Técnicas
Especificaciones Técnicas Actualizaciones
Actualizaciones UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
¿Alguna vez ha querido copiar texto de un documento escaneado? ¿O desea extraer texto de un PDF con capturas de pantalla o notas manuscritas? Si es así, está en el lugar indicado para encontrar una solución.
Reconocer texto a partir de escaneos o imágenes le permite extraer detalles clave sin tener que volver a escribir todo manualmente. Puede extraer o editar fácilmente el texto y buscar secciones específicas según lo necesite.
Pero, ¿cómo se reconoce el texto en un PDF? Este artículo será su guía. Le mostraremos cómo reconocer texto de PDFs escaneados y notas manuscritas.
Aunque existen varias soluciones, le recomendamos usar UPDF. Con su potente herramienta OCR, puede reconocer texto en aproximadamente 38 idiomas, ¡manteniendo siempre la estructura intacta!
También puede buscar texto y editarlo directamente dentro de UPDF sin cambiar a otra plataforma. Y si desea extraer escritura manuscrita en PDF con precisión, UPDF lo hace posible gracias a su potente asistente de IA.
¿Por qué no probarlo usted mismo? ¡Descargue UPDF ahora! Luego, siga la guía a continuación para extraer texto de cualquier PDF de manera sencilla.
Windows • macOS • iOS • Android 100% Seguro
Parte 1. Reconocer texto en documentos PDF escaneados
Si desea reconocer texto en PDFs escaneados o en imágenes, la herramienta OCR de UPDF ofrece una solución sencilla. Analiza rápidamente el texto de su documento y lo convierte en un PDF editable y buscable con una precisión notable.
Aquí están algunas de sus funciones destacadas:
- Puede convertir escaneos con 3 diseños: solo texto e imagen, texto sobre la imagen de fondo o texto debajo de ella.
- Puede personalizar configuraciones para el diseño, la resolución de la imagen, el rango de páginas y más.
- Puede extraer texto de un documento multilingüe.
- La función OCR inversa permite convertir un PDF editable en un formato solo de imagen.
- Admite tanto documentos escaneados como imágenes.
¿Listo para reconocer texto en documentos PDF escaneados? Así es como funciona:
Paso 1: Abra UPDF en su dispositivo. Luego haga clic en "Abrir archivo" para importar su PDF escaneado. Para archivos de imagen, puede arrastrarlos a la interfaz principal de UPDF para abrirlos.
Paso 2: Una vez que se abra su archivo, haga clic en "OCR" en Herramientas desde el panel izquierdo.
Paso 3: Se abrirá un menú de configuración de OCR. En Tipo de documento, seleccione "PDF editable".
Paso 4: Seleccione el diseño deseado y ajuste otras configuraciones como idioma del documento, resolución de imagen, rango de páginas, etc.
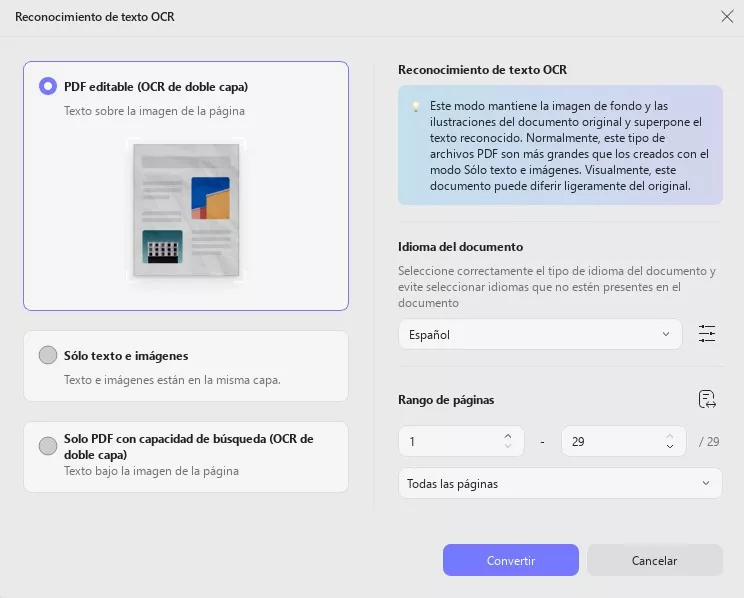
Paso 5: Haga clic en el ícono de engranaje junto al menú desplegable de Diseño para configuraciones avanzadas. Esto abrirá el menú de configuración de diseño, donde puede seleccionar opciones como compresión MRC y más. Haga clic en "Convertir" una vez que haya terminado de ajustar las configuraciones.
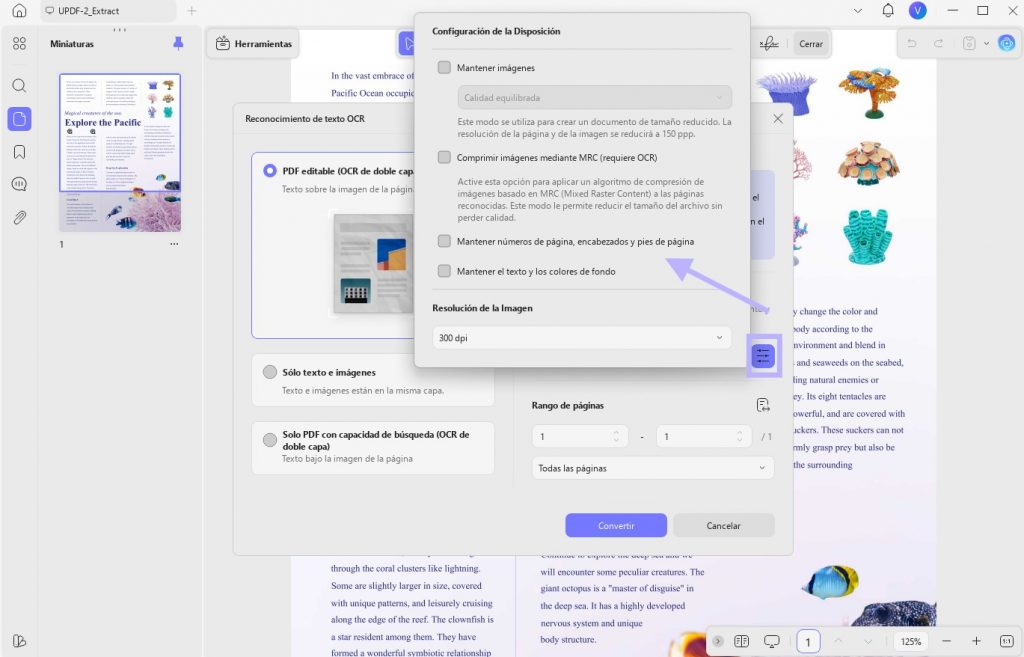
Paso 6: Una vez completado el OCR, el PDF convertido se abrirá en una nueva pestaña. Luego podrá seleccionar, buscar y editar el texto en el PDF.

¡Eso es todo! Ahora sabe cómo reconocer texto en un PDF con imágenes escaneadas. Si aprende mejor visualmente, vea el video a continuación para una guía fácil sobre la herramienta OCR de UPDF.
Parte 2. Reconocer texto manuscrito en PDF
A veces, puede que necesite extraer texto manuscrito de un archivo PDF. Aunque las herramientas OCR pueden ayudarle a reconocerlo, pueden ser inexactas, especialmente si la escritura no es clara.
Pero no se preocupe. UPDF ofrece una solución sencilla con su asistente de IA integrado. Solo proporciónele una captura de pantalla de la escritura y extraerá el texto en segundos. Luego, podrá copiarlo y pegarlo en cualquier editor de texto para su edición manual.
¡Esta es la función de chat con imagen en acción! Esto es lo que más puede hacer con ella:
- Puede extraer texto con un solo comando a partir de imágenes y capturas de pantalla.
- Admite todos los idiomas tanto para texto manuscrito como digital.
- Puede obtener un análisis detallado de gráficos de datos y diagramas complejos.
- Puede ofrecer comentarios de expertos, sugerencias para mejorar el diseño y más.
- Puede generar contenido para redes sociales basado en el archivo.
Entonces, ¿está listo para reconocer texto manuscrito en PDF? Descargue e instale UPDF en su Windows o Mac. Luego, use la guía a continuación para extraer texto manuscrito rápida y fácilmente.
Windows • macOS • iOS • Android 100% Seguro
Paso 1: Abra UPDF en su escritorio. Haga clic en "Abrir archivo" y seleccione el PDF con texto manuscrito.
Paso 2: Una vez que su PDF se abra, haga clic en "UPDF AI" en la parte inferior derecha. Luego, seleccione el modo "Chat" en la parte superior.
Paso 3: Navegue a la página del PDF con texto manuscrito. Luego, seleccione la herramienta "Captura de pantalla" en la parte inferior derecha.
Paso 4: Haga clic y arrastre el cursor sobre el área con texto manuscrito. Una vez que lo suelte, la captura de pantalla se cargará en UPDF AI.
Paso 5: Escriba un comando solicitando a UPDF AI que extraiga la escritura de la imagen. Luego, presione el botón "Enviar". UPDF AI analizará rápidamente la escritura y la convertirá en formato digital.
Comando: Extraer el texto manuscrito de esta imagen.
¡Y así es como se reconoce texto manuscrito en PDF con IA! UPDF AI lo hace rápido y sencillo. No necesita pasos largos ni navegación compleja. Y aún mejor, ofrece 100 tareas gratuitas para que comience.
Parte 3. ¿Por qué no se reconoce mi texto en PDF?
A veces, un OCR puede no reconocer el texto, lo que provoca una conversión inexacta. Si se enfrenta a este problema, no se preocupe. Aquí hay algunas posibles razones y cómo solucionarlas:
- Escaneos de baja calidad: Un escaneo con texto borroso o desalineado es difícil de reconocer para el OCR.
- Caligrafía desordenada: Las herramientas OCR pueden tener dificultades para identificar texto manuscrito poco legible.
- Fuentes estilizadas: El PDF puede contener texto decorativo o complejo que confunde al OCR.
- Bajo contraste: Si no hay suficiente contraste entre el texto y el fondo, diferenciar los caracteres puede ser complicado.
- PDF protegido: El PDF puede tener restricciones para realizar OCR y editar el texto, limitando el reconocimiento de texto.
Soluciones para cuando el texto no se reconoce en PDF
Aquí tiene algunas recomendaciones para solucionar el problema de “texto no reconocido en PDF”:
- Use escaneos de alta calidad: Escanee el documento a una resolución mayor para obtener texto claro y legible.
- Use OCR multilingüe: Si su PDF contiene varios idiomas, utilice una herramienta OCR que admita documentos multilingües.
- Revise la configuración de OCR: Seleccione el idioma correcto del documento, el diseño y el tipo de salida. Configuraciones incorrectas pueden causar problemas en el reconocimiento del texto.
- Use IA: Si el resultado no es el esperado, intente convertir el PDF escaneado en imágenes o hacer capturas de pantalla, y luego use una herramienta de IA como UPDF AI para extraer el texto.
Conclusión
Eso es todo sobre cómo reconocer texto en PDF. El proceso es sencillo gracias a las versátiles capacidades de reconocimiento de texto de UPDF. Puede usar la herramienta OCR para reconocer texto de documentos escaneados o el asistente de IA para extraer texto con un esfuerzo mínimo. Pruébelo. ¡Descargue UPDF en su escritorio hoy mismo! Encontrará una forma eficiente de manejar sus PDFs escaneados y mucho más.
Windows • macOS • iOS • Android 100% Seguro








 Thanakorn Srisuwan
Thanakorn Srisuwan 
