 UPDF pro Windows
UPDF pro Windows UPDF pro Mac
UPDF pro Mac UPDF pro iOS
UPDF pro iOS UPDF pro Android
UPDF pro Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Upravit PDF
Upravit PDF Anotovat PDF
Anotovat PDF Vytvořit PDF
Vytvořit PDF PDF formuláře
PDF formuláře Upravit odkazy
Upravit odkazy Konvertovat PDF
Konvertovat PDF OCR
OCR PDF do Wordu
PDF do Wordu PDF do obrázku
PDF do obrázku PDF do Excelu
PDF do Excelu Organizovat PDF
Organizovat PDF Sloučit PDF
Sloučit PDF Rozdělit PDF
Rozdělit PDF Oříznout PDF
Oříznout PDF Otočit PDF
Otočit PDF Chránit PDF
Chránit PDF Podepsat PDF
Podepsat PDF Redigovat PDF
Redigovat PDF Sanitizovat PDF
Sanitizovat PDF Odstranit zabezpečení
Odstranit zabezpečení Číst PDF
Číst PDF UPDF Cloud
UPDF Cloud Komprimovat PDF
Komprimovat PDF Tisknout PDF
Tisknout PDF Dávkové zpracování
Dávkové zpracování O UPDF AI
O UPDF AI Řešení UPDF AI
Řešení UPDF AI AI příručka
AI příručka FAQ o UPDF AI
FAQ o UPDF AI Shrnutí PDF
Shrnutí PDF Překlad PDF
Překlad PDF Chat s PDF
Chat s PDF Chat s AI
Chat s AI Chat s obrázkem
Chat s obrázkem PDF na
PDF na Vysvětlení PDF
Vysvětlení PDF AI nástroje pro PDF
AI nástroje pro PDF AI nástroje pro obrázky
AI nástroje pro obrázky AI chatovací nástroje
AI chatovací nástroje AI nástroje pro psaní
AI nástroje pro psaní AI studijní nástroje
AI studijní nástroje AI pracovní nástroje
AI pracovní nástroje Ostatní AI nástroje
Ostatní AI nástroje Generování záložek pomocí AI
Generování záložek pomocí AI Shrnutí záložek pomocí AI
Shrnutí záložek pomocí AI Generování vodoznaků pomocí AI
Generování vodoznaků pomocí AI Generování pozadí pomocí AI
Generování pozadí pomocí AI Generování samolepek pomocí AI
Generování samolepek pomocí AI Generování razítek pomocí AI
Generování razítek pomocí AI AI sada pro psaní
AI sada pro psaní UPDF Copilot
UPDF Copilot Správa stránek pomocí AI
Správa stránek pomocí AI Sémantické vyhledávání pomocí AI
Sémantické vyhledávání pomocí AI PDF na Word
PDF na Word PDF na Excel
PDF na Excel PDF na PowerPoint
PDF na PowerPoint Uživatelská příručka
Uživatelská příručka UPDF Triky
UPDF Triky FAQs
FAQs Recenze UPDF
Recenze UPDF Středisko stahování
Středisko stahování Blog
Blog Tiskové centrum
Tiskové centrum Technické specifikace
Technické specifikace Aktualizace
Aktualizace UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
S rostoucím využíváním digitálního obsahu se také zvyšuje potřeba optického rozpoznávání znaků (OCR) pro extrakci textu z obrázků nebo naskenovaných dokumentů. Jedním z populárních vyhledávání na webu je, jak provést skenování Bangla OCR. Proto jsme navrhli tohoto exkluzivního průvodce, který vám představí čtyři nejlepší softwarová řešení Bangla OCR a kroky, které musíte dodržet, abyste je mohli používat.
Část 1. Srovnání 4 nejlepších Bangla OCR nástrojů
Existuje mnoho online nástrojů Bangla OCR, ze kterých si můžete vybrat, ale ne všechny zajišťují přesnou extrakci textu. Provedli jsme tedy průzkum a vybrali čtyři nejlepší nástroje, které mohou uspokojivě odvést práci.
Podívejte se na srovnávací tabulku níže a získejte rychlý přehled o jejich schopnostech:
| Funkce | Online asistent UPDF s umělou inteligencí | Bangla Scan | i2OCR | Google Drive |
| Poháněno AI | Pomocí GPT-5 a Deepseek R1 | |||
| Přesnost | Nejvyšší (99 %) | Vysoká | Nízká | Nízká |
| Rychlost | Velmi vysoká | Vysoká | Vysoká | Střední |
| Podporované formáty souborů | Obrázek, PDF | Obrázek | Obrázek, PDF | Obrázek, PDF, Word, Excel, PPT atd. |
| Limit velikosti | Obrázek s neomezenou velikostí | Neomezená | Neomezená | Neomezená |
| Další užitečné funkce (překlad, chat s dokumenty atd.) | Překlad, chat s obrázky | Úprava textu po skenování | Překlad, úprava textu po skenování | Integrace s Google Docs, přímá úprava dokumentů |
1. Online asistent AI UPDF
Online asistent AI UPDF je nástroj Bangla OCR poháněný umělou inteligencí, který dokáže bez námahy provádět OCR na obrázcích a naskenovaných dokumentech. Poskytuje nejvyšší přesnost extrakce textu, protože je napájen přes GPT-5 a Deepseek R1. Stačí nahrát obrázek nebo naskenovaný soubor PDF a poté požádat umělou inteligenci o extrahování textu.
1. Online asistent AI UPDF
Online asistent AI UPDF je nástroj Bangla OCR poháněný umělou inteligencí, který dokáže bez námahy provádět OCR na obrázcích a naskenovaných dokumentech. Poskytuje nejvyšší přesnost extrakce textu, protože je napájen přes GPT-5 a Deepseek R1. Stačí nahrát obrázek nebo naskenovaný soubor PDF a poté požádat umělou inteligenci o extrahování textu.
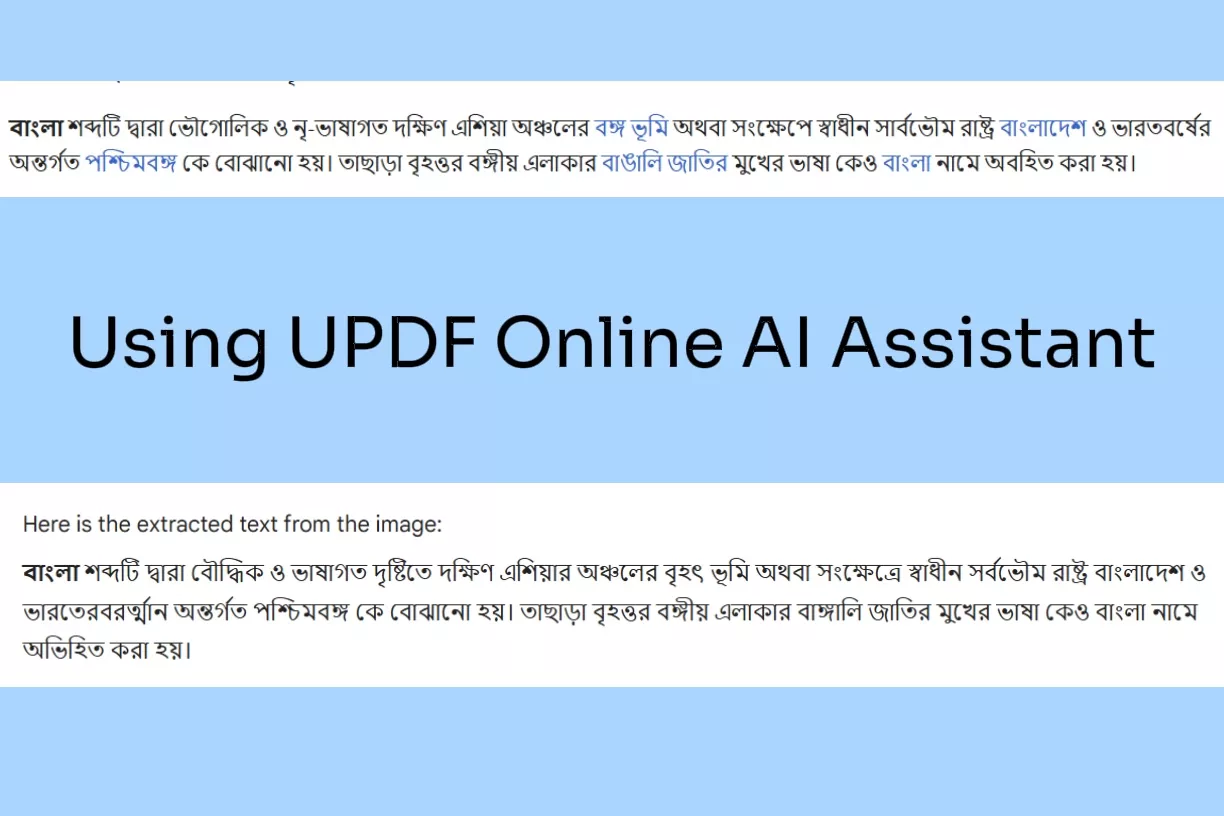
Nejlepší na UPDF je, že jeho asistent AI umí mnohem víc než OCR. Můžete jej také použít k překladu extrahovaného textu, požádat o vylepšení/přepsání textu nebo chatovat o čemkoli. Představte si to jako svého virtuálního asistenta, který může provádět OCR a pomáhat vám s dalšími činnostmi souvisejícími s dokumenty.
Mezi klíčové funkce online AI asistenta UPDF patří:
- OCR obrazy a naskenované dokumenty s vysokou přesností.
- Extrahujte text v bengálštině nebo jiném jazyce.
- Snadno použitelné rozhraní.
- Překládejte obrázky a naskenované dokumenty v bengálštině do jakéhokoli jiného jazyka.
- Chatujte s obrázky, například vysvětlovejte obrázky, generujte obsah reklamy a další.
- Získejte pomoc s umělou inteligencí při přepisování, korekturách, shrnutí, odpovídání na otázky a dalších.
Stručně řečeno, UPDF je průvodce, který vám umožní provádět OCR na obrázcích a naskenovaných dokumentech a získat další pomoc, kterou potřebujete.
Hodnocení: 4.5/5 (G2)
Kroky pro provádění OCR na obrázcích a naskenovaných dokumentech
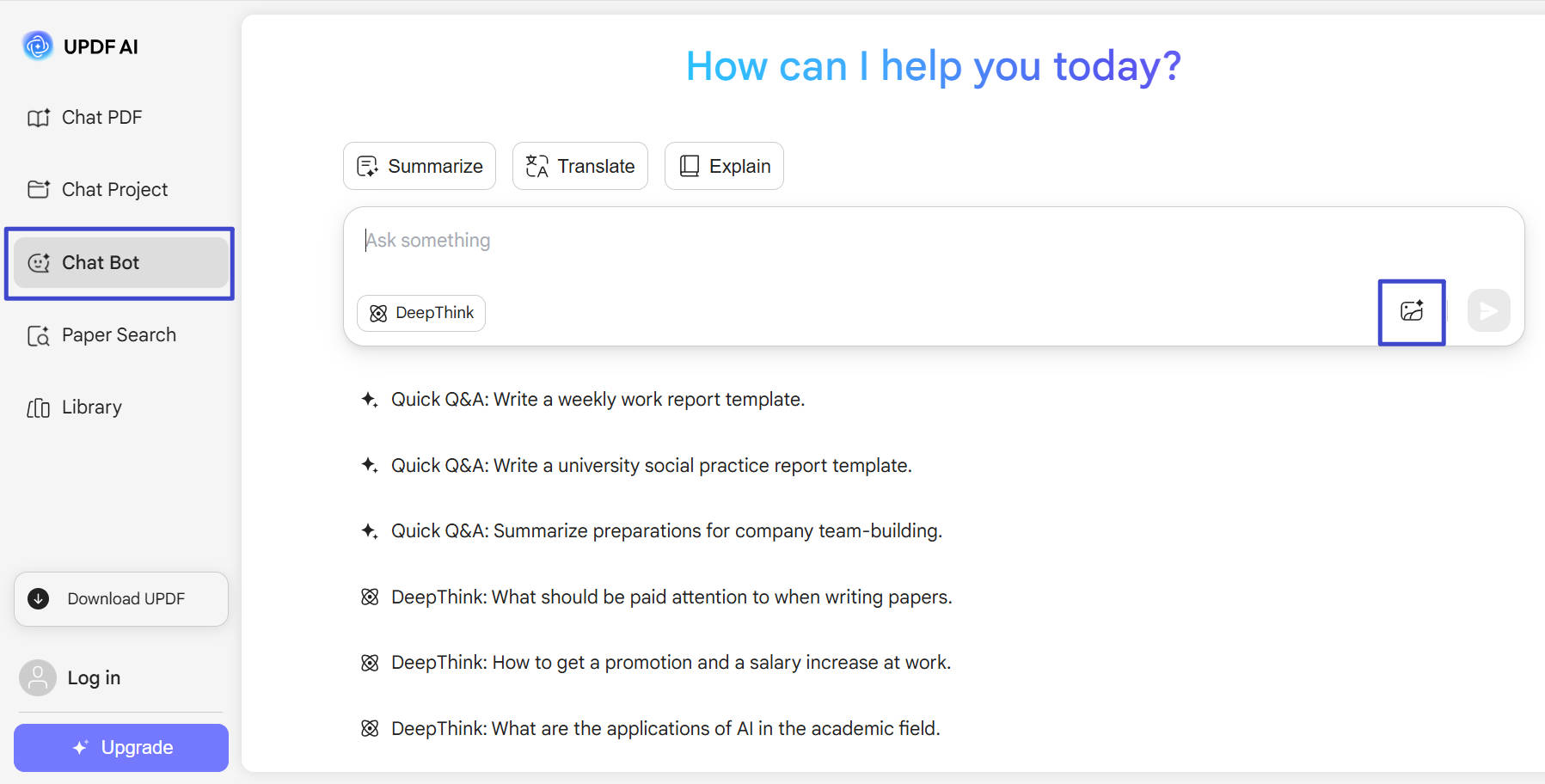
Krok 1. Kliknutím na tlačítko níže přejděte na https://ai.updf.com/cs/chat-bot/ webovou stránku a kliknutím na ikonu obrázku obrázek nahrajte.
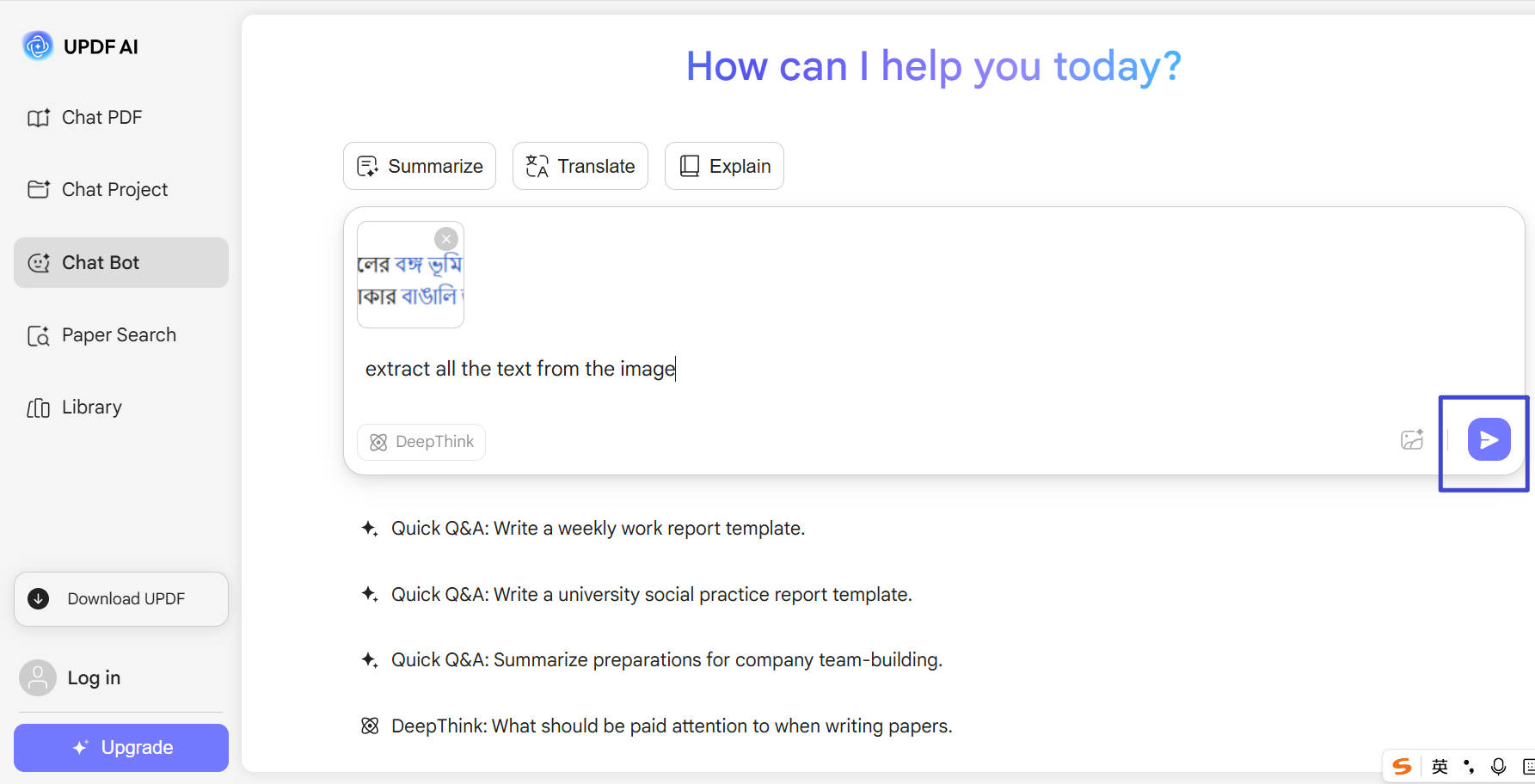
Krok 2. Do chatovacího pole napište výzvu jako "extrahujte veškerý text z obrázku" a klikněte na tlačítko "odeslat". UPDF AI okamžitě extrahuje text z obrázku.
Krok 3. Dále můžete zkopírovat extrahovaný text nebo požádat umělou inteligenci o další pomoc, například "Přeložte extrahovaný text do angličtiny". Případně můžete požádat umělou inteligenci, aby v posledním kroku přímo přeložila text bengálsky z obrázku.
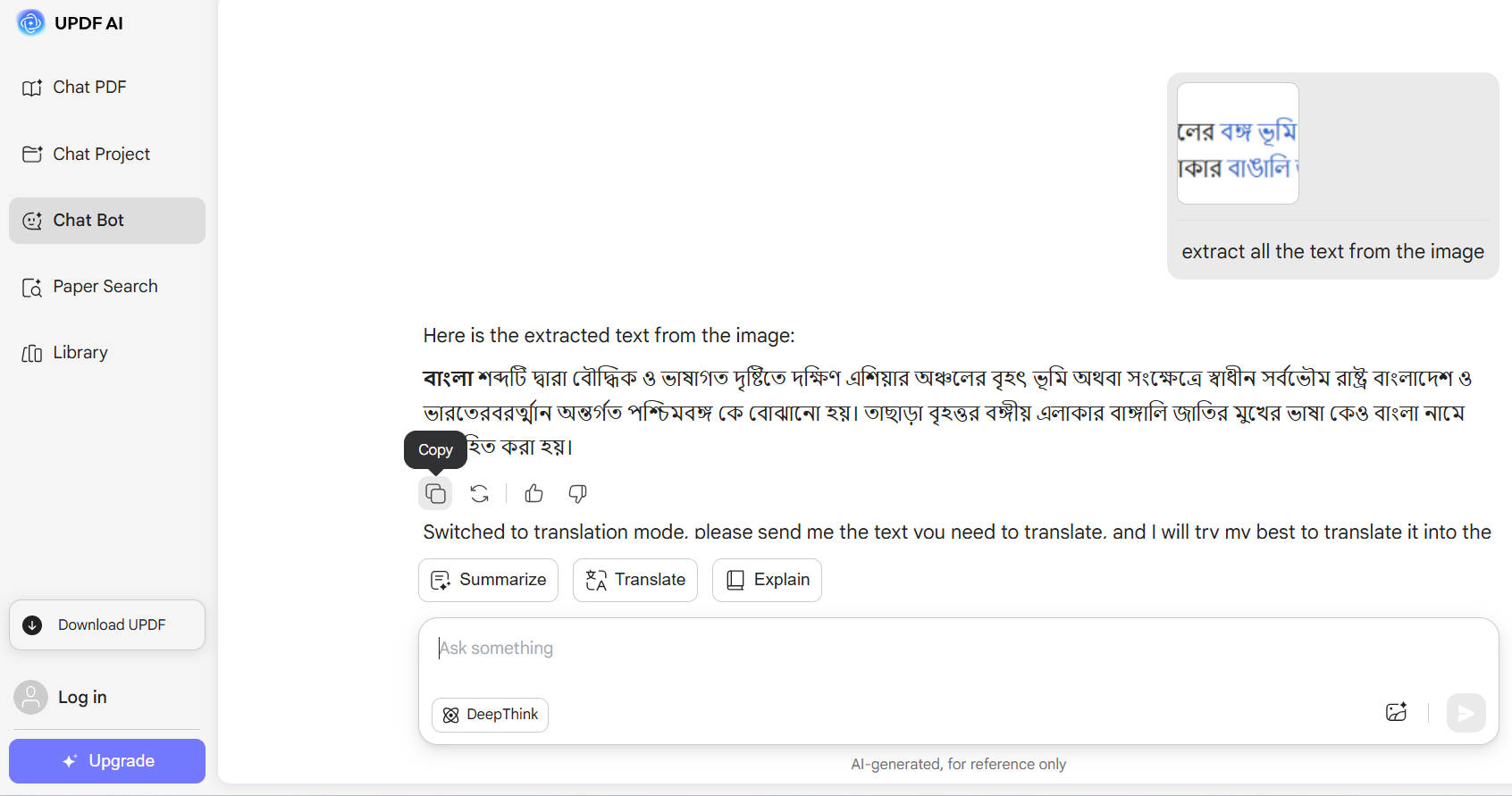
Tímto způsobem můžete získat přesné obrázky Bangla OCR s podporou AI pomocí UPDF. Přejděte na webovou stránku UPDF AI a získejte OCR skenování hned zdarma.
Poznámka: Chcete-li převést naskenované soubory PDF, musíte pořídit snímek obrazovky obsahu, který chcete extrahovat, a poté podle výše uvedených kroků extrahovat text.
Profesionálové:
- Snadné OCR obrázků a naskenovaných dokumentů
- 99% přesnost extrakce textu
- Podpora rozpoznávání obrázků/naskenovaných dokumentů libovolného jazyka
- Webové rozhraní, kompatibilní se všemi operačními systémy
- Použití asistenta AI pro jiné účely, jako je překlad, vysvětlení a další
Nevýhody:
- Přímé OCR nelze provádět v dokumentech. Pokud však potřebujete převést naskenované soubory PDF do jazyků, jako je angličtina, němčina, italština, japonština, čínština, francouzština a další (úplný seznam 38+ podporovaných jazyků naleznete zde), můžete si stáhnout PC a mobilní verzi UPDF. Aplikace UPDF umožňuje provádět OCR do PDF při zachování původního rozvržení souboru.
Windows • macOS • iOS • Android 100% bezpečné

- Provedení OCR na PC:
Krok 1. Nainstalujte a spusťte UPDF na svém počítači (Windows nebo Mac). Přetáhněte soubor PDF nebo obrazový soubor, u kterého chcete provést rozpoznávání OCR.
Krok 2. Klikněte na možnost "OCR" v části "Nástroje" na levém postranním panelu. Po otevření nové karty vyberte požadovaný režim na levé straně nastavení:
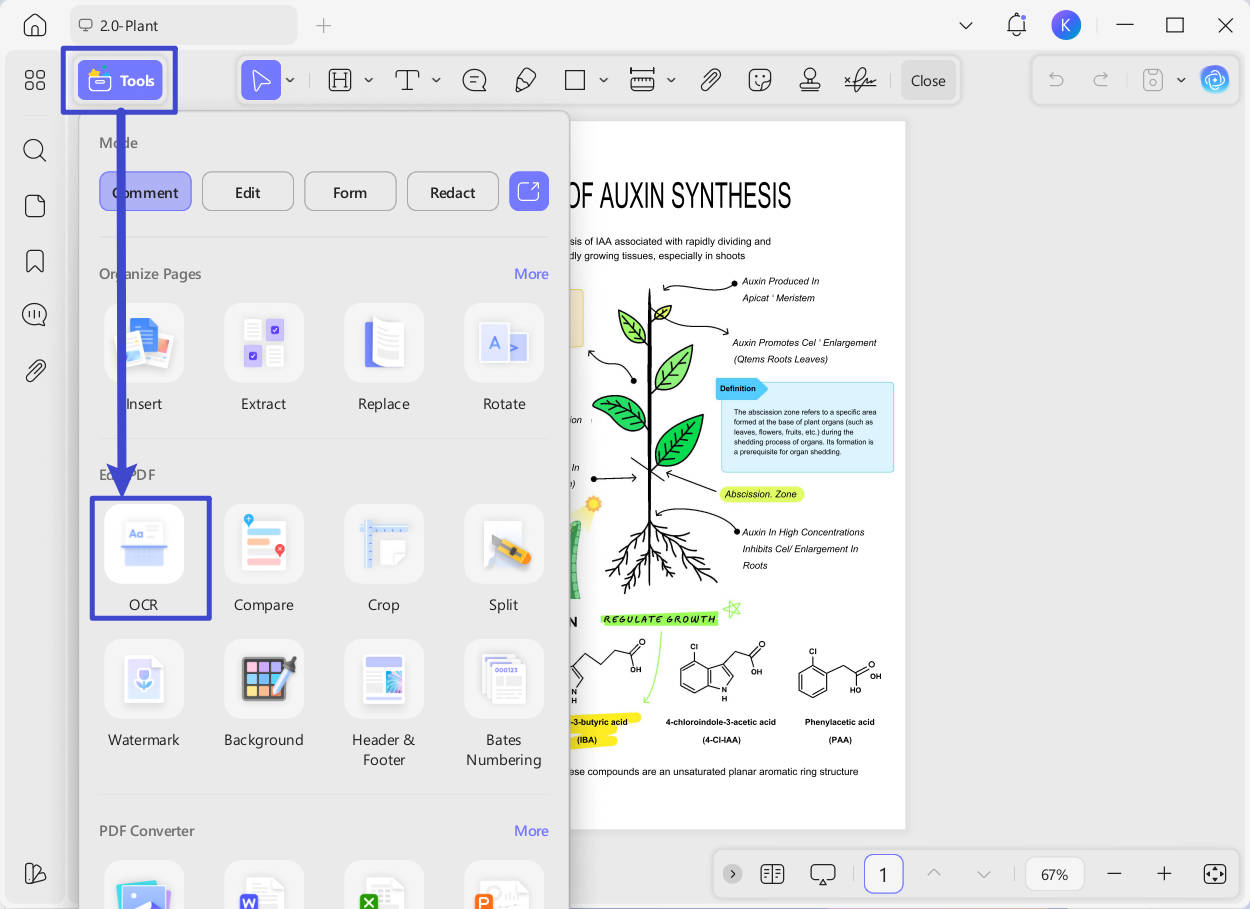
- Upravitelné PDF
- Pouze text a obrázky
- Pouze prohledávatelné soubory PDF
Přizpůsobte nastavení OCR, například jazyk, který odpovídá zdrojovému dokumentu, rozsahu stránek atd. Po dokončení klikněte na "Převést".
Krok 3. UPDF provede důkladné OCR a vytvoří nový soubor, který je upravitelný a prohledávatelný.
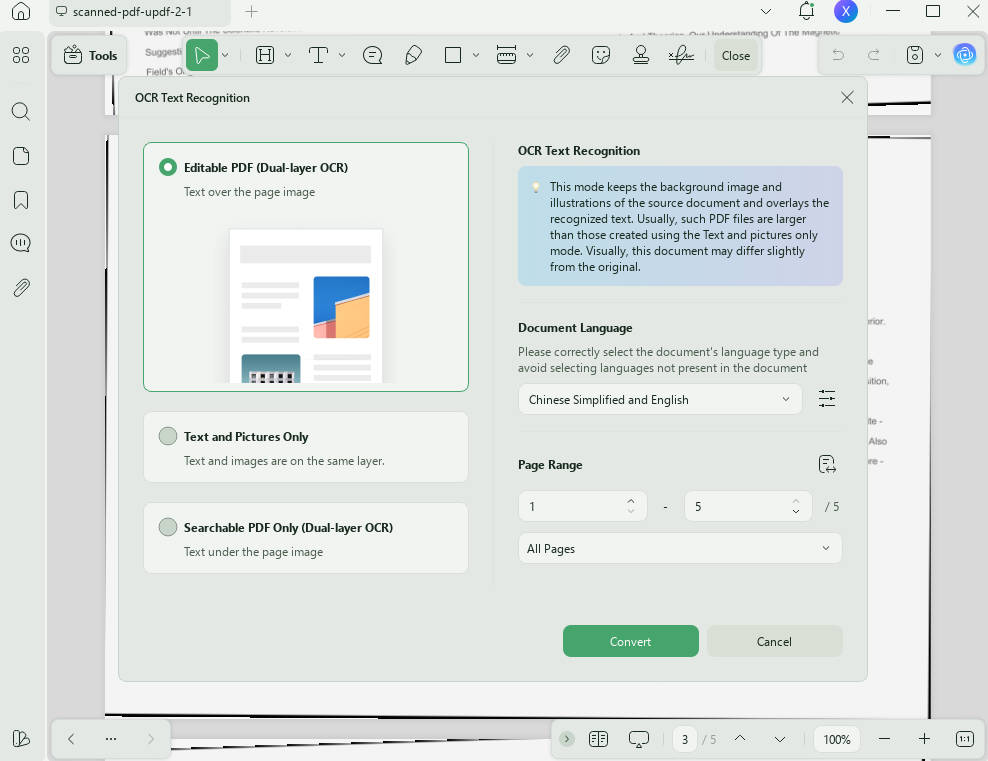
Pokud máte více naskenovaných dokumentů, UPDF podporuje i dávkové OCR.
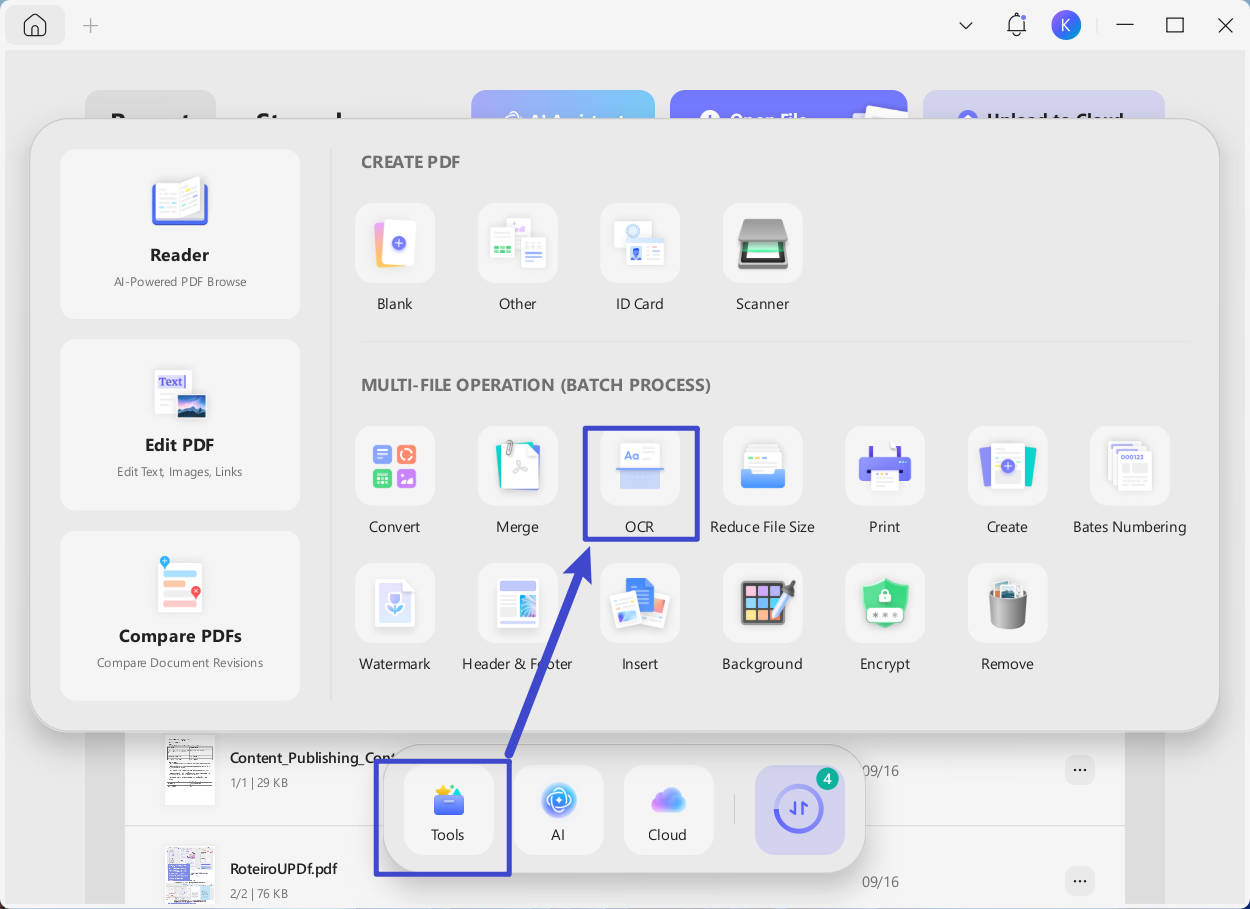
Krok 1. Spusťte software UPDF. V hlavním rozhraní vyhledejte sekci "Multi-File Operation (Batch Process)". Najděte a vyberte ikonu "OCR".
Windows • macOS • iOS • Android 100% bezpečné
Krok 2. V levé části okna Dávkové zpracování můžete přidat soubory PDF buď: přetažením do určené oblasti nebo kliknutím na tlačítko "+ Přidat soubory" a výběrem souborů z počítače.
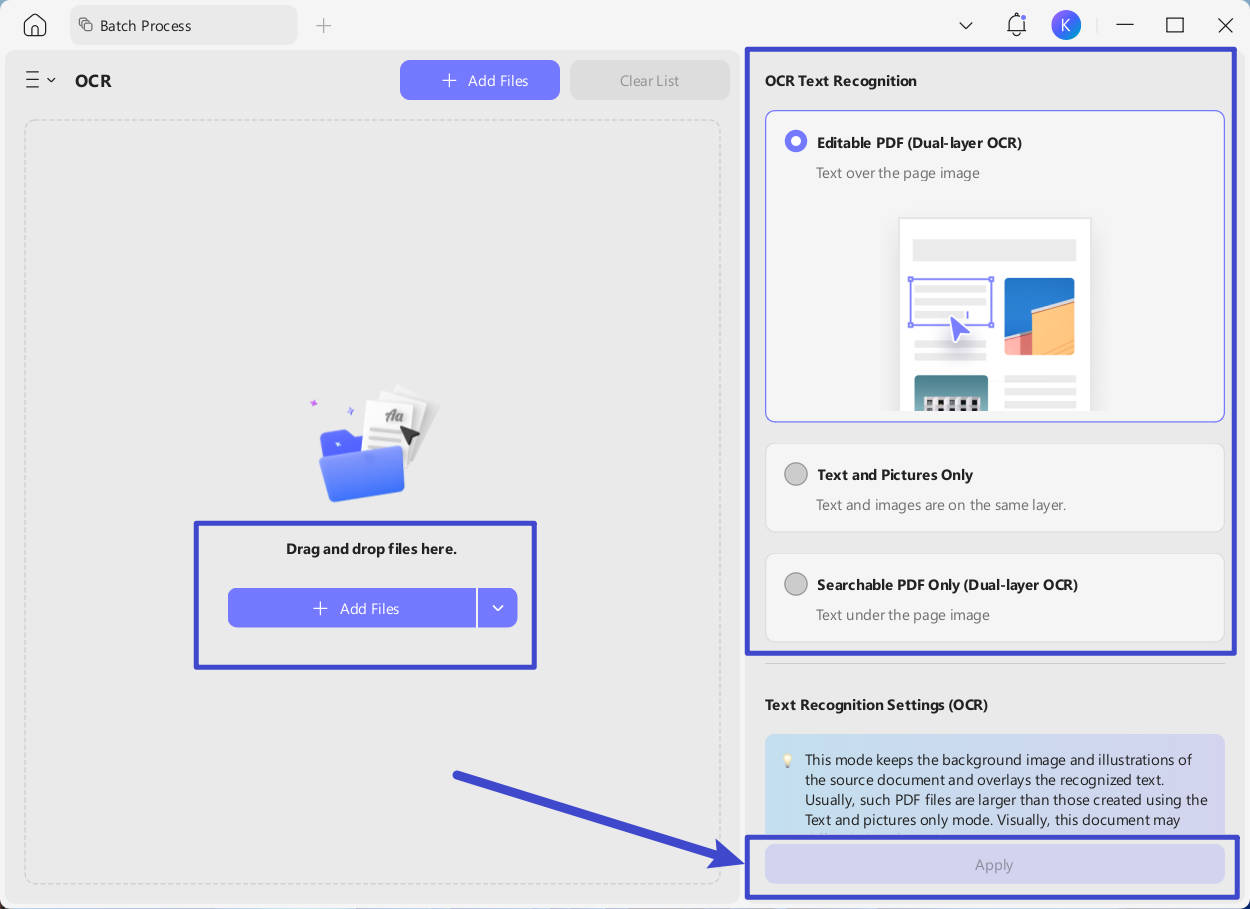
Krok 3. Na pravé straně vyberte požadovaný režim a jazyk, který odpovídá zdrojovému dokumentu.
Krok 4. Po dokončení klikněte na tlačítko "Použít" a spusťte proces dávkového OCR.
- Provedení OCR na mobilním zařízení:
Krok 1. Otevřete si v telefonu aplikaci UPDF (Android/iOS). UPDF Mobile si můžete stáhnout z App Store a Google Play. Klikněte na ikonu "+" v pravém dolním rohu a klepnutím na "Soubory" vyberte naskenovaný soubor PDF.
Windows • macOS • iOS • Android 100% bezpečné
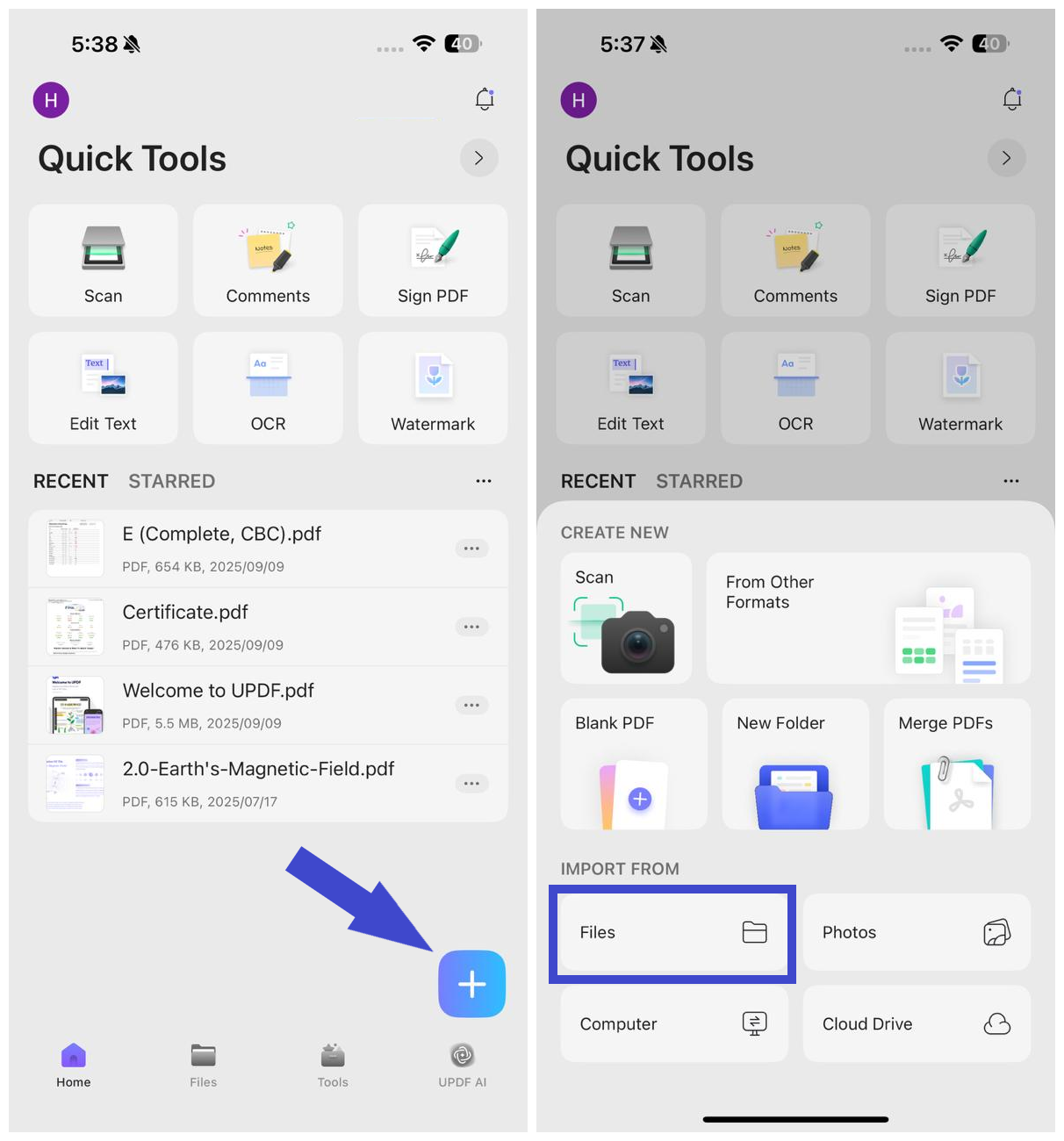
Krok 2. Klikněte na "OCR" v "Rychlých nástrojích" nebo klepněte na "Nástroje > OCR".
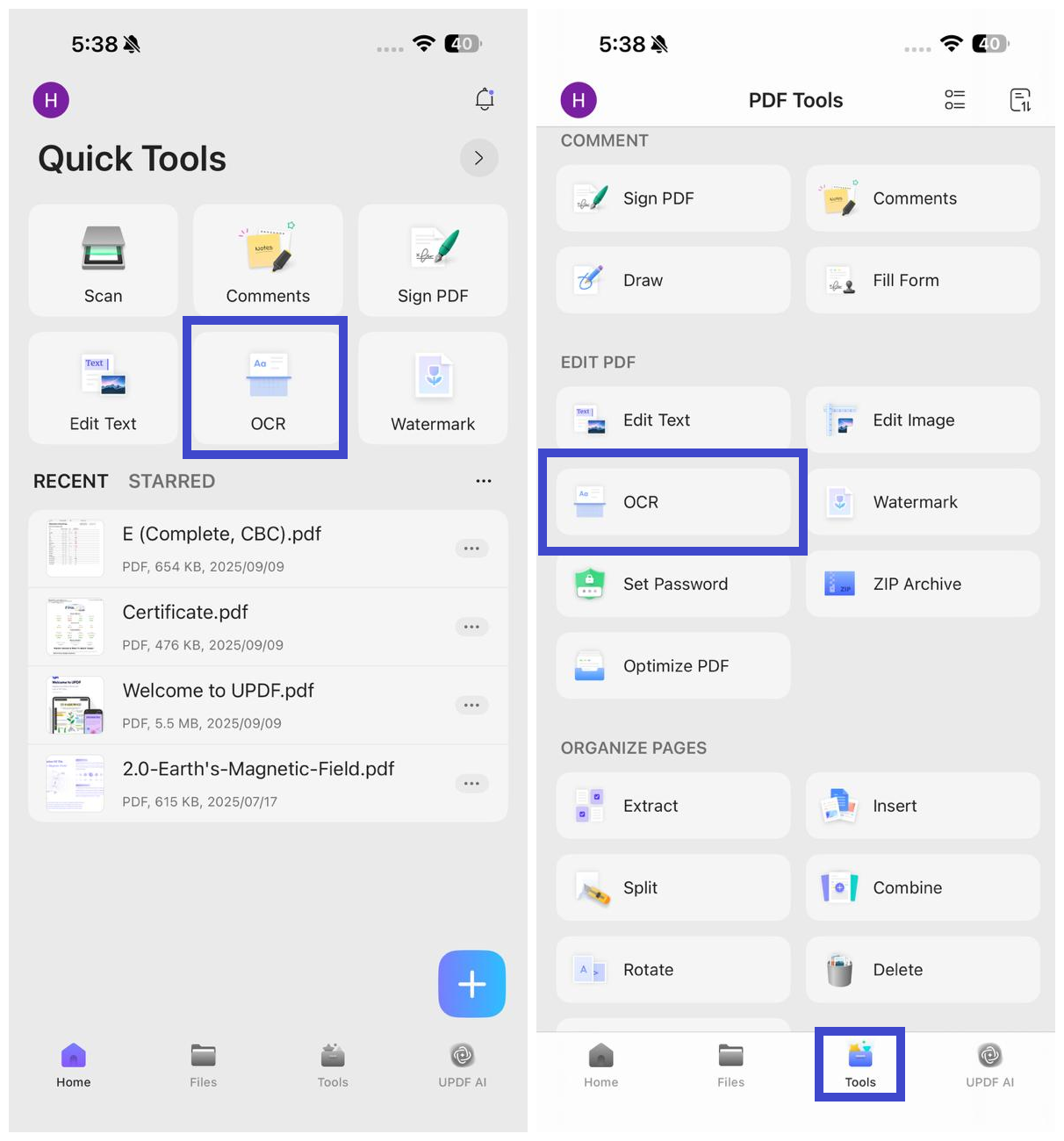
Krok 3. Vyberte naskenovaný soubor PDF.
Krok 4. V části "Typ rozpoznávání OCR" vyberte jednu z následujících možností:
- Upravitelné PDF
- Pouze text a obrázky.
- Pouze prohledávatelné soubory PDF
Krok 5. Klikněte na "Vybrat jazyk PDF" a vyberte jazyk dokumentu. Vyberte více jazyků, pokud dokument obsahuje text ve více než jednom jazyce.
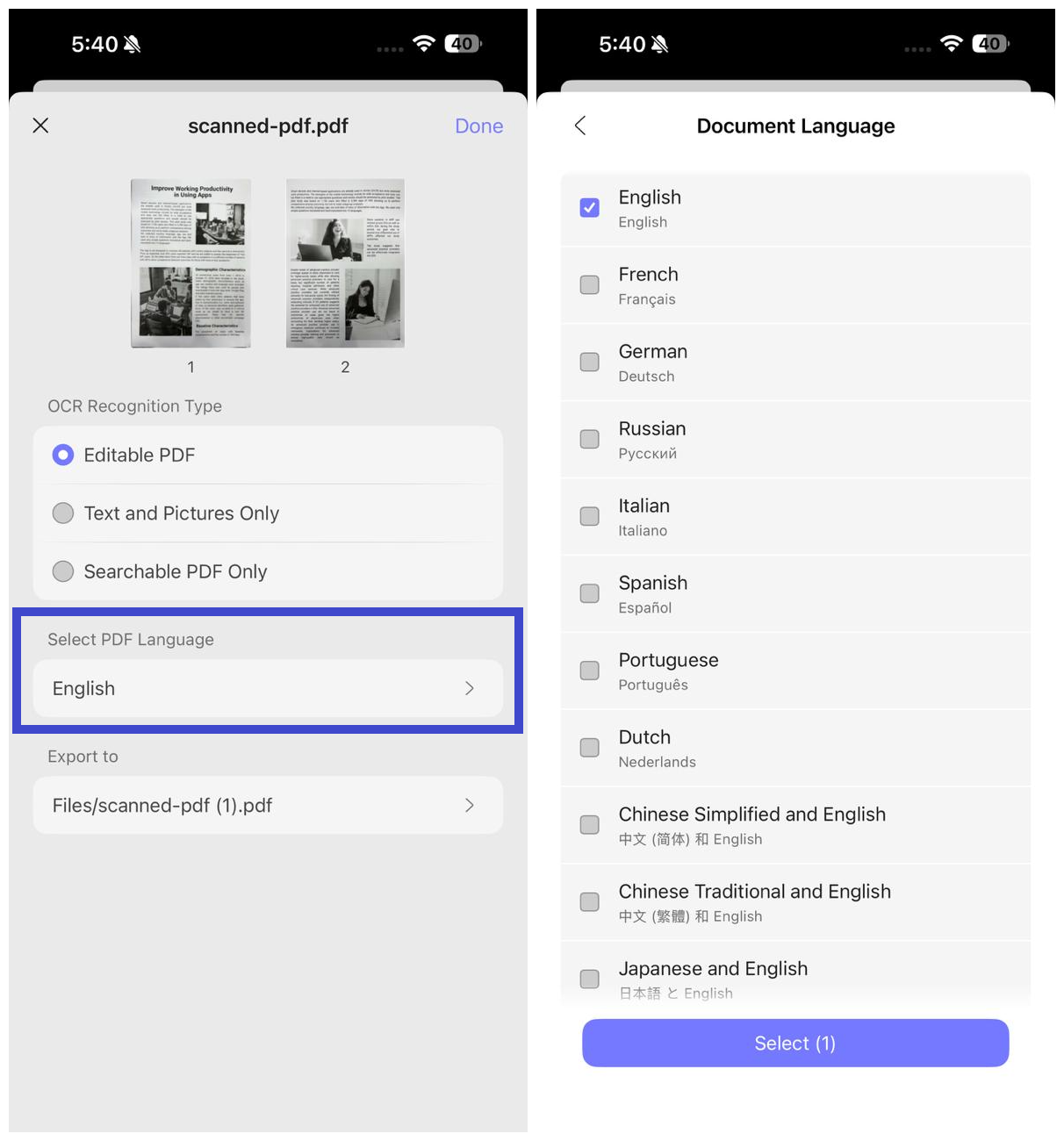
Krok 6. Nakonfigurujte umístění "Exportovat do" a určete, kam chcete uložit soubor PDF s OCR, a stisknutím tlačítka "Hotovo" spusťte OCR.
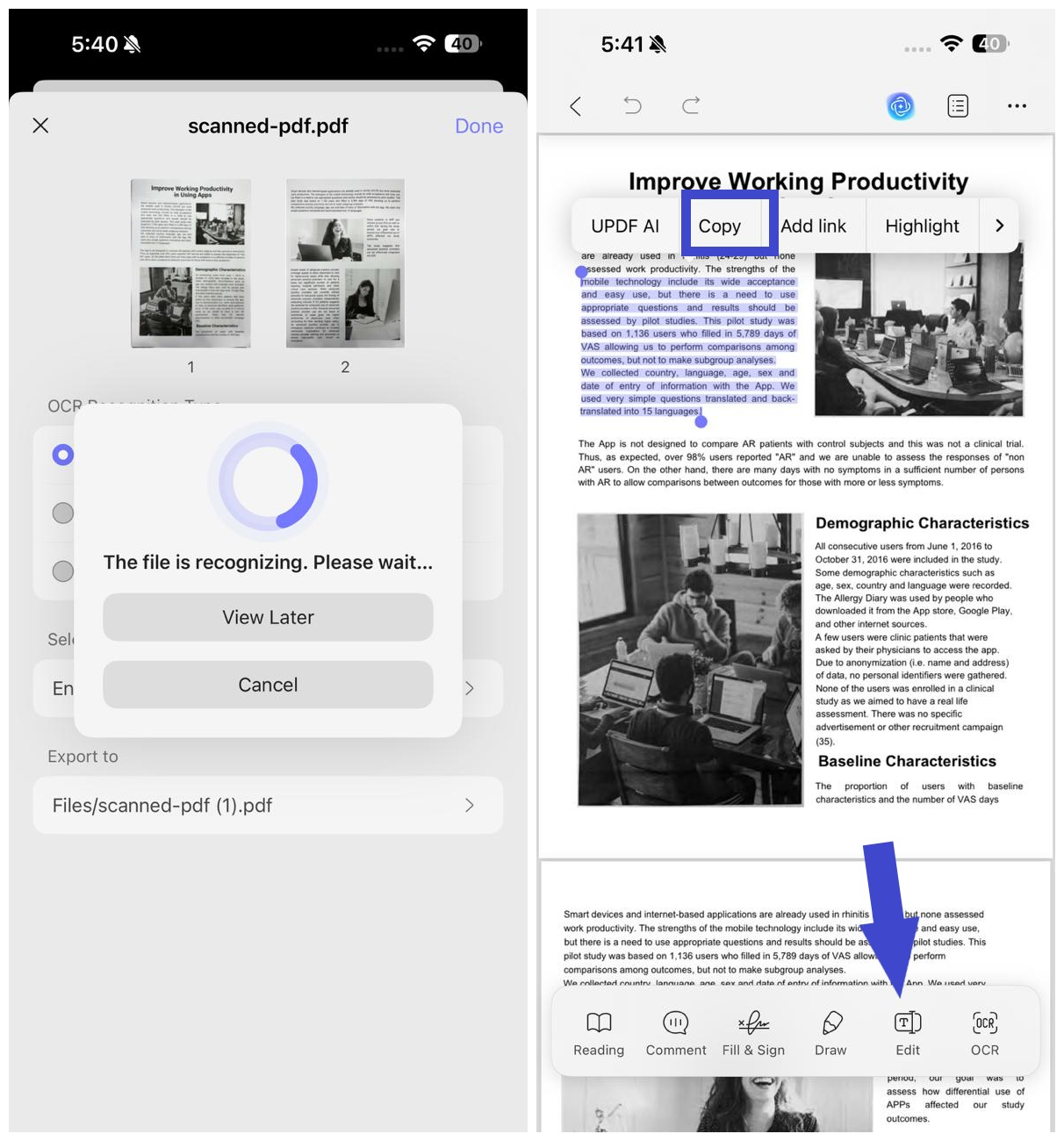
Krok 7. Počkejte na dokončení rozpoznávání OCR. Po dokončení rozpoznávání OCR přejděte na kartu "Soubory" a otevřete nově vygenerovaný soubor PDF s OCR. Zkopírujte text nebo použijte funkci úprav UPDF pro úpravu textu a obrázků.
2. Skenování v bengálštině
Pokud vaše potřeby souvisejí s extrahováním textu z obrázků přímo z telefonu Android, můžete použít Bangla Scan.
Bangla Scan je aplikace pro Android, která nabízí intuitivní rozhraní pro provádění OCR na obrázcích. Umožňuje vám nahrát obrázek nebo jej naskenovat přímo z fotoaparátu. Poté může z obrázku okamžitě extrahovat bengálský nebo anglický text. Po extrahování můžete text přímo upravit nebo jej uložit jako textový soubor nebo soubor PDF.
Hodnocení: 3.8/5 (Google Play)

Schody
Krok 1. Nainstalujte si "Image to Text OCR Bangla Scan" z Google Play a spusťte jej.
Krok 2. Nahrajte obrázek nebo jej zachyťte pomocí fotoaparátu.
Krok 3. Aplikace okamžitě provede OCR. Poté můžete text upravit přímo nebo stisknout příslušnou možnost a uložit text do souboru TXT nebo PDF.

Profesionálové:
- Bezplatná aplikace Bangla OCR založená na Androidu
- Vysokorychlostní skenování OCR
- Snadno použitelné rozhraní
- Přímá úprava textu
Nevýhody:
- Podpora pouze zařízení Android
- Žádná možnost extrahování textu z naskenovaných PDF
- Obsahové reklamy
3. i2OCR
i2OCR je online nástroj Bangla OCR, který dokáže extrahovat text z obrázků a naskenovaných souborů PDF. Dokáže převést obrazový soubor na text, který lze prohledávat a upravovat, a poté jej stáhnout ve formátu PDF, Doc nebo HTML. Umožňuje také přeložit extrahovaný text do jiných jazyků.
i2OCR poskytuje webové rozhraní, do kterého můžete nahrát soubor a okamžitě získat rozpoznání textu. Je zdarma k použití a nevyžaduje žádnou registraci.
Hodnocení: Není k dispozici
Schody
Krok 1. Přejděte na webovou stránku i2OCR. Vyberte, zda chcete provést OCR obrázku nebo PDF.
Krok 2. Vyberte jazyk "bengálština", vyberte rozvržení obrázku, nahrajte obrázek a klikněte na "Extrahovat text".
Krok 3. Nástroj okamžitě provede OCR a vygeneruje nový dokument s extrahovaným textem. Dále můžete extrahovaný text upravit, přeložit nebo stáhnout ve svém preferovaném formátu.

Profesionálové:
- Zdarma webový software Bangla OCR
- Rychlá extrakce textu
- Překlady a korektury textů
Nevýhody:
- Nemusí vždy poskytnout přesné výsledky
4. Disk Google
Posledním a dalším účinným způsobem, jak provést skenování Bangla OCR, je Disk Google. Je to známá platforma cloudového úložiště, ale může za vás také provádět OCR.
Nejprve musíte obrázek nebo dokument nahrát na Disk Google a poté jej otevřít pomocí Dokumentů Google. Během tohoto procesu systém provede rozpoznávání textu a umožní vám snadno zkopírovat, upravit nebo uložit text z Dokumentů Google.
Hodnocení: 4.6/5 (Gartner)
Schody
Krok 1. Přejděte na stránku Drive.Google.com a přihlaste se pomocí svého účtu Google.
Krok 2. Klikněte na možnost Nový > Odeslat soubor a nahrajte soubor PDF nebo obrázek.
Krok 3. Klikněte na "3 tečky" vedle souboru a vyberte Otevřít v > Dokumentech Google.

Krok 4. Počkejte, až se soubor otevře v Dokumentech Google. Během tohoto procesu bude také provádět OCR.
Krok 5. Jakmile se soubor otevře v Dokumentech Google, můžete text upravit, zkopírovat nebo uložit v požadovaném formátu, jako je DOCX, PDF, TXT atd.

Profesionálové:
- Bezplatný způsob provádění Bangla OCR
- Bezpečné ukládání dokumentů a extrakce textů
- Proces založený na kliknutí
Nevýhody:
- Nelze zachovat původní formátování a rozvržení
- Ignorování obrazů z naskenovaného PDF během OCR
- Může ignorovat extrahování nějakého textu
Závěr
Existuje mnoho online nástrojů Bangla OCR, které vám mohou pomoci snadno extrahovat bengálský text z obrázků nebo jiných dokumentů. Výše uvedené čtyři možnosti jsou nejlepší pro snadnou extrakci textu. Ze všech jsme zjistili, že UPDF je nejlepší volbou díky OCR podporovanému umělou inteligencí a nejvyšší přesnosti. Kromě toho můžete také překládat a používat asistenta AI pro další nákupy. Vyzkoušejte proto online AI asistenta UPDF pro nejlepší extrakci bengálského textu.






 Lizzy Lozano
Lizzy Lozano 
