 UPDF pro Windows
UPDF pro Windows UPDF pro Mac
UPDF pro Mac UPDF pro iOS
UPDF pro iOS UPDF pro Android
UPDF pro Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Upravit PDF
Upravit PDF Anotovat PDF
Anotovat PDF Vytvořit PDF
Vytvořit PDF PDF formuláře
PDF formuláře Upravit odkazy
Upravit odkazy Konvertovat PDF
Konvertovat PDF OCR
OCR PDF do Wordu
PDF do Wordu PDF do obrázku
PDF do obrázku PDF do Excelu
PDF do Excelu Organizovat PDF
Organizovat PDF Sloučit PDF
Sloučit PDF Rozdělit PDF
Rozdělit PDF Oříznout PDF
Oříznout PDF Otočit PDF
Otočit PDF Chránit PDF
Chránit PDF Podepsat PDF
Podepsat PDF Redigovat PDF
Redigovat PDF Sanitizovat PDF
Sanitizovat PDF Odstranit zabezpečení
Odstranit zabezpečení Číst PDF
Číst PDF UPDF Cloud
UPDF Cloud Komprimovat PDF
Komprimovat PDF Tisknout PDF
Tisknout PDF Dávkové zpracování
Dávkové zpracování O UPDF AI
O UPDF AI Řešení UPDF AI
Řešení UPDF AI AI příručka
AI příručka FAQ o UPDF AI
FAQ o UPDF AI Shrnutí PDF
Shrnutí PDF Překlad PDF
Překlad PDF Chat s PDF
Chat s PDF Chat s AI
Chat s AI Chat s obrázkem
Chat s obrázkem PDF na
PDF na Vysvětlení PDF
Vysvětlení PDF AI nástroje pro PDF
AI nástroje pro PDF AI nástroje pro obrázky
AI nástroje pro obrázky AI chatovací nástroje
AI chatovací nástroje AI nástroje pro psaní
AI nástroje pro psaní AI studijní nástroje
AI studijní nástroje AI pracovní nástroje
AI pracovní nástroje Ostatní AI nástroje
Ostatní AI nástroje Generování záložek pomocí AI
Generování záložek pomocí AI Shrnutí záložek pomocí AI
Shrnutí záložek pomocí AI Generování vodoznaků pomocí AI
Generování vodoznaků pomocí AI Generování pozadí pomocí AI
Generování pozadí pomocí AI Generování samolepek pomocí AI
Generování samolepek pomocí AI Generování razítek pomocí AI
Generování razítek pomocí AI AI sada pro psaní
AI sada pro psaní UPDF Copilot
UPDF Copilot Správa stránek pomocí AI
Správa stránek pomocí AI Sémantické vyhledávání pomocí AI
Sémantické vyhledávání pomocí AI PDF na Word
PDF na Word PDF na Excel
PDF na Excel PDF na PowerPoint
PDF na PowerPoint Uživatelská příručka
Uživatelská příručka UPDF Triky
UPDF Triky FAQs
FAQs Recenze UPDF
Recenze UPDF Středisko stahování
Středisko stahování Blog
Blog Tiskové centrum
Tiskové centrum Technické specifikace
Technické specifikace Aktualizace
Aktualizace UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
Nevíte, jak vyhledávat v naskenovaném PDF souboru s nápisem „Tato stránka obsahuje pouze obrázky“? Nebo jste se pokusili vyhledat slova pomocí funkce Hledat ve Windows nebo stisknutím kláves CTRL + F, ale nic nefungovalo? Pravděpodobně jste vyhledávali v naskenovaném PDF souboru. Pokud vás zajímá, jak vyhledávat v naskenovaných dokumentech PDF, máme pro vás řešení! Ponořte se do toho a prozkoumejte, jak na to.
Jak vyhledávat slova v naskenovaném PDF?
Problém je v tom, že naskenované dokumenty neobsahují žádný text! Protože se jedná pouze o obrázek dokumentu, neexistuje žádný skutečný text, který by Windows mohl indexovat.
Aby byl váš PDF soubor prohledávatelný, musíte spustit rozpoznávání textu, aby byl obsah stránky prohledávatelný a upravitelný. Můžete použít libovolný software s funkcí OCR (optické rozpoznávání znaků). Ten prochází naskenovaným dokumentem, identifikuje vše, co se podobá písmenu nebo slovu, a převede to na skutečný text.
Tuto funkci nabízí několik editorů PDF, ale my doporučujeme UPDF – vaše univerzální řešení pro práci s PDF! Jedná se o funkci OCR s umělou inteligencí, která převádí naskenované PDF soubory, papírové dokumenty a obrázky do prohledávatelných a upravitelných PDF souborů se třemi výstupními rozvrženími, takže je interaktivní a splňuje všechny vaše potřeby. Více se o funkci OCR v UPDF dozvíte v tomto článku. Než začneme s představením pokynů, nejprve si stáhněte UPDF.S
Windows • macOS • iOS • Android 100% bezpečné

Zde jsou některé působivé vlastnosti tohoto OCR softwaru :
- Přesnost až 99 %: Pokročilá technologie OCR v UPDF nabízí vysoce přesné výsledky!
- Nejvyšší rychlost OCR: Kdo by nechtěl ušetřit čas? UPDF to chápe; proto je jeho konverze v porovnání s konkurencí super rychlá.
- Malý výstup s vysokou kvalitou: Velikost převedeného PDF dokumentu je mnohem menší než jeho originál!
- Podporuje 38 jazyků: Podporuje také dvojjazyčné dokumenty a umožňuje vybrat více jazykových sad.
Kromě toho všeho také čte, organizuje a anotuje vaše PDF soubory a dokáže převést naskenované PDF soubory libovolné velikosti! Tak na co ještě čekáte? Postupujte podle níže uvedených jednoduchých kroků, jak vyhledávat slova v naskenovaných PDF souborech, a vyřešte svůj problém hned teď! Stačí jen pár jednoduchých kroků a budete rychle hotovi!
Krok 1: Otevřete PDF a získejte přístup k ikoně OCR
Klikněte na „ Otevřít soubor “ pro import PDF. Můžete také použít klávesovou zkratku Ctrl + nebo Cmd + O.
Klikněte na možnost „ Rozpoznat text pomocí OCR “ na pravém panelu nástrojů. (Pokud tuto funkci používáte poprvé, budete přesměrováni ke stažení pluginu. Stáhněte si jej v následujícím okně a počkejte na jeho instalaci.)
Krok 2: Změňte naskenovaný PDF soubor na prohledávatelný
Po instalaci klikněte znovu na stejné tlačítko „Rozpoznat text pomocí OCR“. Zobrazí se vám dvě různé možnosti typu dokumentu. Vyberte „ Prohledávatelné PDF “, protože tato možnost převede naskenované dokumenty na dokumenty s možností úprav a vyhledávání.
Musíte zvolit rozvržení z možností „Pouze text a obrázky“, „Text přes obrázek stránky“ a „Text pod obrázkem stránky“. Musíte také zvolit jazyk dokumentu, rozlišení obrázku a rozsah papíru.
Pro zobrazení pokročilých možností rozvržení klikněte na ikonu „Ozubené kolo“. Získáte tak přístup k dalším nastavením rozvržení, jako například:
- Pokud zaškrtnete políčko „Zachovat obrázky“, budete muset zvolit kvalitu („Nízká“, „Vyvážená“ nebo „Vysoká“).
- Komprimovat obrázky
- Zachovat ostatní prvky dokumentu (záhlaví, zápatí, čísla stránek, text a barvy pozadí)
Klikněte na možnost „ Provést OCR “, poté vyberte umístění, kam chcete soubor uložit, a klikněte na „Uložit“.

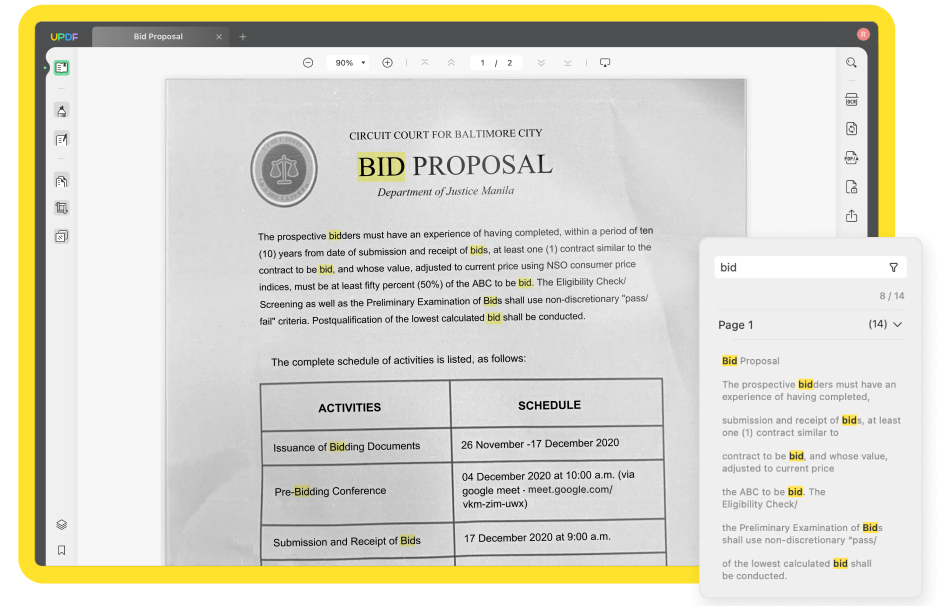
Krok 3: Vyhledávání slov v naskenovaném PDF
Po provedení OCR se prohledávatelný soubor PDF automaticky otevře v UPDF. Nyní můžete v naskenovaném PDF souboru vyhledat požadovaná slova kliknutím na Ctrl + F nebo ikonu Hledat v pravém horním rohu.
Zadejte slovo, které chcete vyhledat, a zobrazí se všechny výsledky v tomto dokumentu. Kliknutím na libovolný výsledek můžete přejít přímo na danou stránku. Takto snadno najdete slova v PDF .

Chcete-li se dozvědět více o tom, jak OCR soubor v PDF, podívejte se na níže uvedený video návod.
Bonus
Tip: Jaké rozvržení mám zvolit při provádění OCR?
U prohledávatelných PDF souborů je nutné zvolit správné rozvržení v závislosti na účelu nebo situaci, pro kterou rozvržení používáte. Pomocí dostupných možností si můžete vybrat jednu z následujících možností:
Pouze text a obrázky:
OCR rozpozná a uloží text a obrázky z PDF souboru do menšího souboru. Nebude k dispozici žádná průhledná obrazová vrstva, aby se zachovalo formátování. Vizuální vzhled převedeného souboru se tedy může lišit od původní verze.
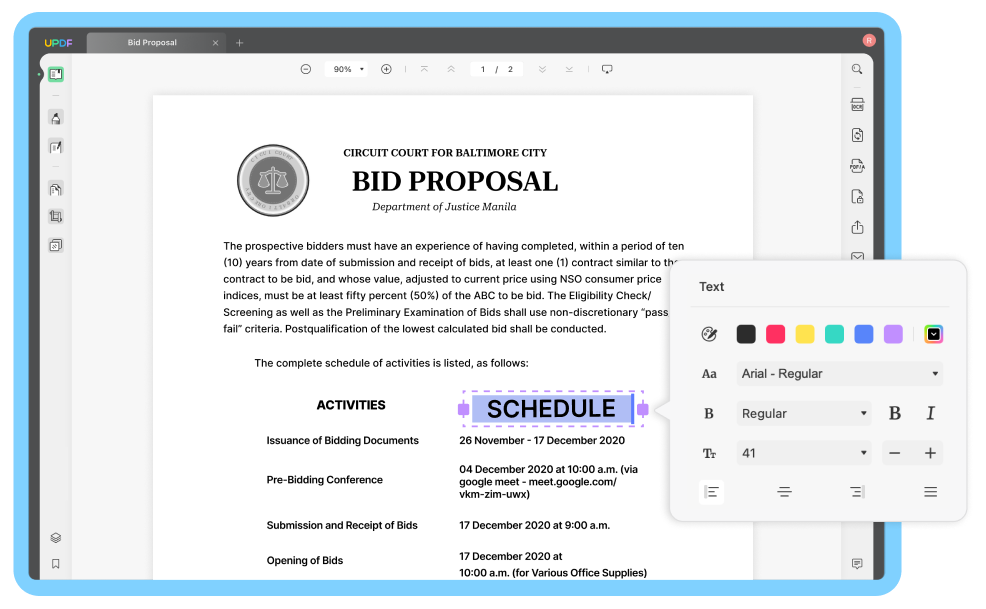
Text přes obrázek stránky:
Tento režim zachová ilustrace a obrázky na pozadí ve zdrojovém souboru jako vrstvu pod textem dokumentu. Zachovává původní formát dokumentu. I když jsou tyto soubory rozsáhlejší, vizuálně se liší od původních.

Text pod obrázkem stránky:
Obrázky PDF zůstanou zachovány, ale text je umístěn pod obrázky pod neviditelnou vrstvou. Formátování dokumentu je tedy zachováno umístěním vrstvy nad text. Tento typ souboru je identický s původním. Text lze vyhledávat, ale nelze jej upravovat.
Často kladené otázky k vyhledávání v naskenovaném PDF
Přesto máte nějaké otázky ohledně vyhledávání slov v naskenovaném PDF. Nebojte se. Postaráme se o vás.
Proč nemohu vyhledávat v naskenovaném PDF?
Při skenování dokumentu skener zachytí stránky jako plochý obraz, což znamená, že neobsahuje žádný text, který by systém Windows mohl indexovat nebo který by mohl přečíst jakýkoli prohlížeč PDF. K převodu naskenovaného dokumentu do čitelného formátu budete muset použít funkci OCR v UPDF, jak jsme vysvětlili výše v tomto článku.
Mohu na naskenované dokumenty použít Ctrl F?
Ne. Tato funkce Hledat ve Windows funguje pouze na dokumentech, které obsahují čitelný text. Tuto funkci můžete použít pouze stažením softwaru podporujícího technologii OCR, jako je UPDF, který převede sken do prohledávatelného PDF.
Proč nemohu na PDF použít Ctrl F?
Funkce Hledat nefunguje na dokumentech ani na PDF souborech pouze s obrázky, jako je tomu v případě naskenovaných dokumentů. Tyto obrázky neobsahují text, který by systém Windows dokázal rozpoznat.
Závěr
Takže si nevíte rady, jak vyhledat slovo v naskenovaném PDF dokumentu? Žádný problém – UPDF je pro vás ideálním řešením. Jeho funkce OCR je snadno dostupná a snadno se používá a dokáže dokonce detekovat text v rozmazaném naskenovaném dokumentu, s čímž se potýkají i jiné programy! Pomocí pokročilého algoritmu komprese obrázků založeného na MRC můžete převést jakýkoli obrázek na detekovatelný text nebo změnit PDF na dokument pouze s obrázky!
Na co ještě čekáte? Stáhněte si UPDF hned teď a budete moci bez námahy pracovat se svými PDF soubory a mít mnohem plynulejší zážitek díky jeho skvělým nástrojům umělé inteligence. Můžete také upgradovat na prémiovou verzi a odemknout si všechny funkce bez jakýchkoli omezení. Tímto dokončujeme naše pokyny, jak vyhledávat v naskenovaném PDF.
Windows • macOS • iOS • Android 100% bezpečné









 Čserná Anna
Čserná Anna