 UPDF para Windows
UPDF para Windows UPDF para Mac
UPDF para Mac UPDF para iPhone/iPad
UPDF para iPhone/iPad UPDF para Android
UPDF para Android UPDF AI ONLINE
UPDF AI ONLINE UPDF Sign
UPDF Sign Editar PDF
Editar PDF Anotar PDF
Anotar PDF Crear PDF
Crear PDF Formulario PDF
Formulario PDF Editar enlaces
Editar enlaces Convertir PDF
Convertir PDF OCR
OCR PDF a Word
PDF a Word PDF a imagen
PDF a imagen PDF a Excel
PDF a Excel Organizar PDF
Organizar PDF Combinar PDF
Combinar PDF Dividir PDF
Dividir PDF Recortar PDF
Recortar PDF Girar PDF
Girar PDF Proteger PDF
Proteger PDF Firmar PDF
Firmar PDF Redactar PDF
Redactar PDF Desinfectar PDF
Desinfectar PDF Eliminar seguridad
Eliminar seguridad Leer PDF
Leer PDF UPDF Cloud
UPDF Cloud Comprimir PDF
Comprimir PDF Imprimir PDF
Imprimir PDF Proceso por lotes
Proceso por lotes Sobre UPDF IA
Sobre UPDF IA Soluciones de UPDF IA
Soluciones de UPDF IA Guía de Usuario de IA
Guía de Usuario de IA Preguntas frecuentes sobre UPDF IA
Preguntas frecuentes sobre UPDF IA Resumir PDF
Resumir PDF Traducir PDF
Traducir PDF Chat con PDF
Chat con PDF Chat con imagen
Chat con imagen PDF a Mapa Mental
PDF a Mapa Mental Chat con IA
Chat con IA Explicar PDF
Explicar PDF Investigación académica
Investigación académica Búsqueda de documentos
Búsqueda de documentos Corrector de IA
Corrector de IA Redactor de IA
Redactor de IA Ayudante de tareas con IA
Ayudante de tareas con IA Generador de cuestionarios con IA
Generador de cuestionarios con IA Solucionador de Matemáticas IA
Solucionador de Matemáticas IA PDF a Word
PDF a Word PDF a Excel
PDF a Excel PDF a PowerPoint
PDF a PowerPoint Guía del Usuario
Guía del Usuario Trucos de UPDF
Trucos de UPDF Preguntas Frecuentes
Preguntas Frecuentes Reseñas de UPDF
Reseñas de UPDF Centro de descargas
Centro de descargas Blog
Blog Sala de prensa
Sala de prensa Especificaciones Técnicas
Especificaciones Técnicas Actualizaciones
Actualizaciones UPDF vs. Adobe Acrobat
UPDF vs. Adobe Acrobat UPDF vs. Foxit
UPDF vs. Foxit UPDF vs. PDF Expert
UPDF vs. PDF Expert
El formato PDF se ha convertido en el formato más adoptado por las empresas. Como la mayoría de las transacciones y los datos importantes de las empresas se guardan en archivos PDF, a menudo es necesario extraer texto de PDF . Ahora, si intenta extraer texto de archivos PDF manualmente, llevará años si está trabajando en archivos más grandes. Además, también interrumpirá el formateo del archivo.
Ciertos métodos y herramientas, tanto en línea como de pago, pueden extraer con precisión datos de archivos PDF. Este artículo le proporcionará una solución sobre cómo extraer información de archivos PDF con y sin usar la función OCR.
Forma 1.¿Cómo extraer texto de un PDF escaneado/de imagen?
A medida que aprende las técnicas para extraer texto de PDF con y sin OCR , ahora lo redirigiremos a un método simple que se puede usar para extraer texto después del reconocimiento. UPDF proporciona una función de OCR dedicada que puede ayudarlo a convertir documentos PDF escaneados en texto editable y extraíble. Para eso, debe descargar UPDF por el botón siguiente.
Windows • macOS • iOS • Android 100% Seguro
Paso 1: Procesar diseño de OCR
Abre el PDF y presiona el botón "Reconocer texto usando OCR" a la derecha.
A continuación, deberá especificar el diseño en la configuración "Diseño". Seleccione "Solo texto e imágenes", "Texto sobre la imagen de la página" o "Texto debajo de la imagen de la página" (haga clic en OCR de PDF para ver la diferenciación) y si hay opciones de diseño avanzadas que debe tener en cuenta, seleccione el icono "Engranaje". y trabajar en las opciones, si es necesario.
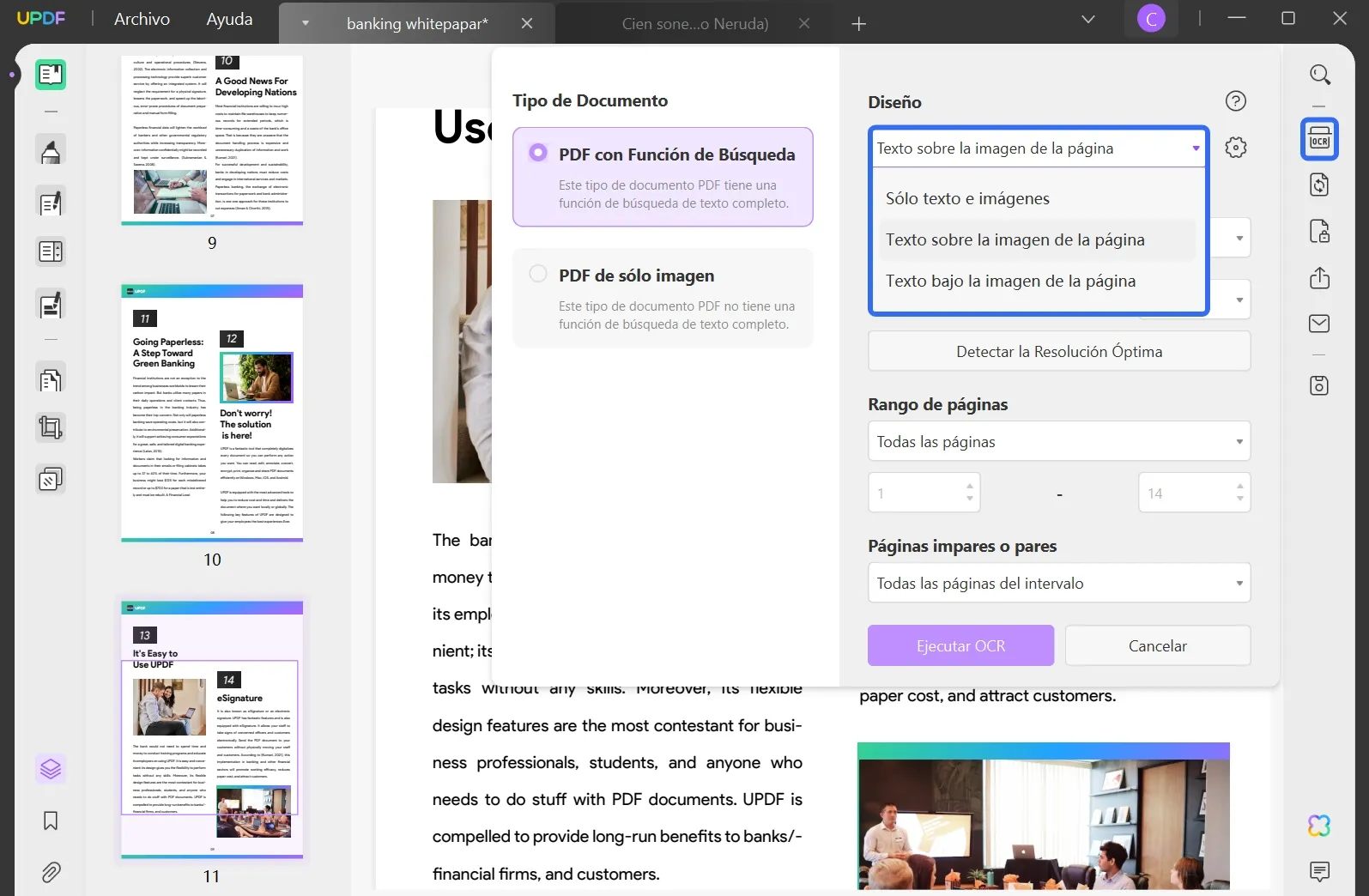
Paso 2: Configuración de idioma e imagen
Defina el idioma del documento de la lista de 38 idiomas diferentes disponibles. Después de esto, trabaja en la configuración de "Resolución de imagen" y establezca un valor particular de la lista provista con él. Si no está seguro, presione el botón "Detectar resolución óptima" y continúe.
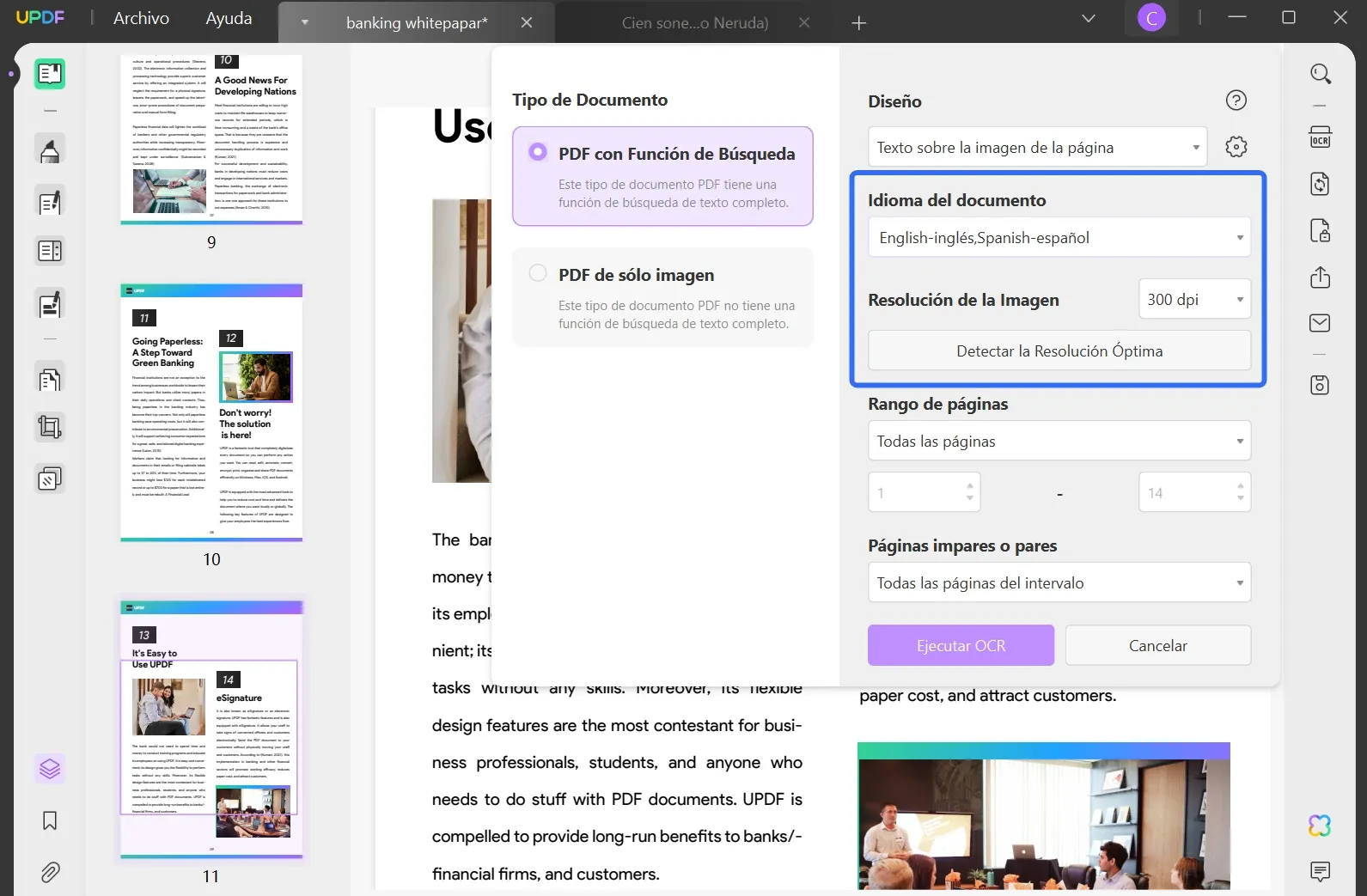
Paso 3: Realizar OCR con éxito
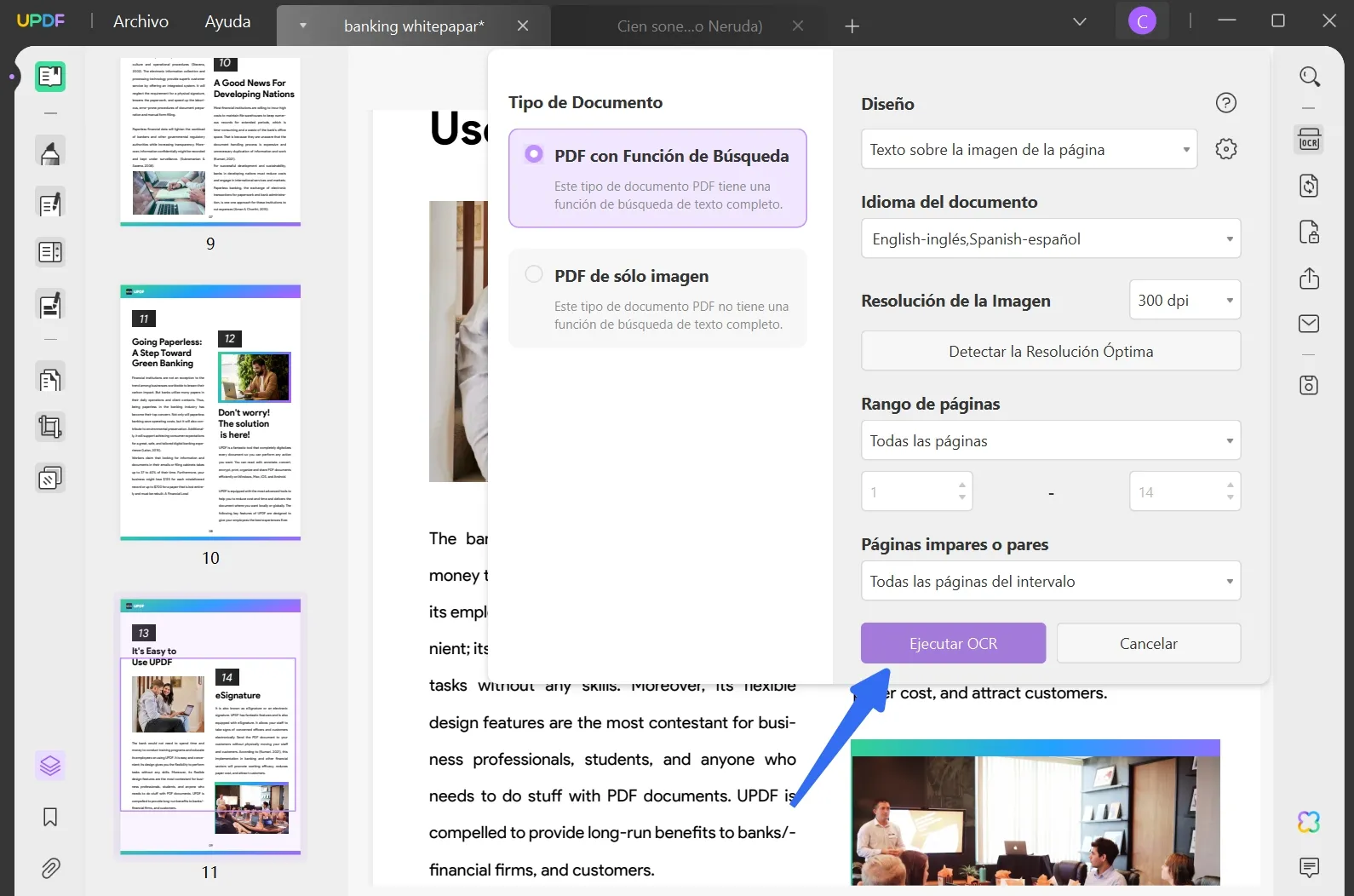
Trabaje en el rango de páginas en el que desea ejecutar la herramienta OCR. A continuación, seleccione el botón "Realizar OCR", defina la ubicación del documento OCR guardado y deje que se ejecute el proceso. Una vez hecho esto, se abre en UPDF, donde puede extraer el texto del PDF.
Windows • macOS • iOS • Android 100% Seguro
Forma 2. Cómo extraer texto de PDF a Word/Excel/otro formato
Es posible que el método anterior le resulte bueno si necesita copiar el texto de una parte en el PDF. Tomará mucho tiempo si necesita extraer todo el texto del PDF. Existe una forma rápida de utilizar UPDF. Mira cómo hacerlo aquí.
Paso 1. Abrir el PDF y vaya a la opción "Exportar PDF"
Inicie UPDF en su computadora, haga clic en "Abrir archivo" y seleccione el PDF de su computadora para abrirlo.
Navegue hasta " Exportar PDF " en el menú del lado derecho y haga clic en él. Seleccione el formato deseado que necesita. Por ejemplo, seleccione el formato que quiere.

(Tenga en cuenta: si su documento PDF es escaneado, primero debe seguir las instrucciones de la Forma 1 para realizar el OCR. El documento OCR realizado se abrirá automáticamente en UPDF).
Paso 2. Convertir PDF a Excel/Word/cualquier formato
Después de seleccionar el formato, puede configurar el rango de páginas si es necesario en la nueva ventana. Cuando todo esté hecho, haga clic en el botón " Exportar " y seleccione la ubicación donde desea guardar los archivos convertidos.
Una vez finalizado el proceso, extraerá con éxito todo el texto del PDF escaneado a Excel, Word o cualquier formato que necesite. Puede abrir el archivo editable en su computadora y realizar cualquier operación.

Forma 3. Cómo extraer texto por lotes de un PDF
La extracción de texto de un solo archivo se puede realizar con varios pasos con UPDF. Pero, ¿cómo se puede extraer texto de varios archivos PDF? No se preocupe, también lo cubriremos aquí.
Paso 1. Iniciar UPDF
Haga doble clic en el icono de UPDF en su escritorio para ejecutarlo. Puede encontrar que hay algunas opciones en la pantalla de inicio. Vaya a hacer clic en el icono " Lote ".

Y luego encontrarás que hay varias opciones. Seleccione la opción " Convertir ".

Paso 2. Extraer texto por lotes de varios archivos PDF
En la nueva ventana, seleccione el formato de salida, cambie otras configuraciones, haga clic en " Aplicar ", seleccione la ubicación para almacenar y haga clic en "Guardar" para realizar el proceso. Una vez hecho esto, podrá encontrar los archivos editables en la ubicación emergente.

Forma 4. ¿Cómo extraer texto de un PDF sin OCR?
OCR es una excelente manera de extraer texto de archivos PDF. Sin embargo, es posible que tenga un PDF normal y desee extraer texto, o simplemente no desee utilizar las funciones de OCR. Cualesquiera que sean los motivos, está buscando una forma de extraer texto de un PDF sin OCR. Conocemos sus escenarios y aquí le presentamos tres formas efectivas.
Si está utilizando un archivo PDF normal en lugar de los creados por escáneres o imágenes, puede utilizar las funciones de edición de UPDF para extraer texto de un PDF. Aquí es cómo.
Paso 1: Navegar al modo de edición
Tras descargar UPDF, el primer paso consiste en abrir un archivo PDF en UPDF del que desea extraer texto. Para hacerlo, haga clic en el botón "Abrir archivo" en el centro de la interfaz UPDF.
Windows • macOS • iOS • Android 100% Seguro
Después de importar PDF a UPDF, navegue hasta la barra de herramientas y haga clic en la pestaña " Editar PDF " para aplicar el modo de edición a su archivo.
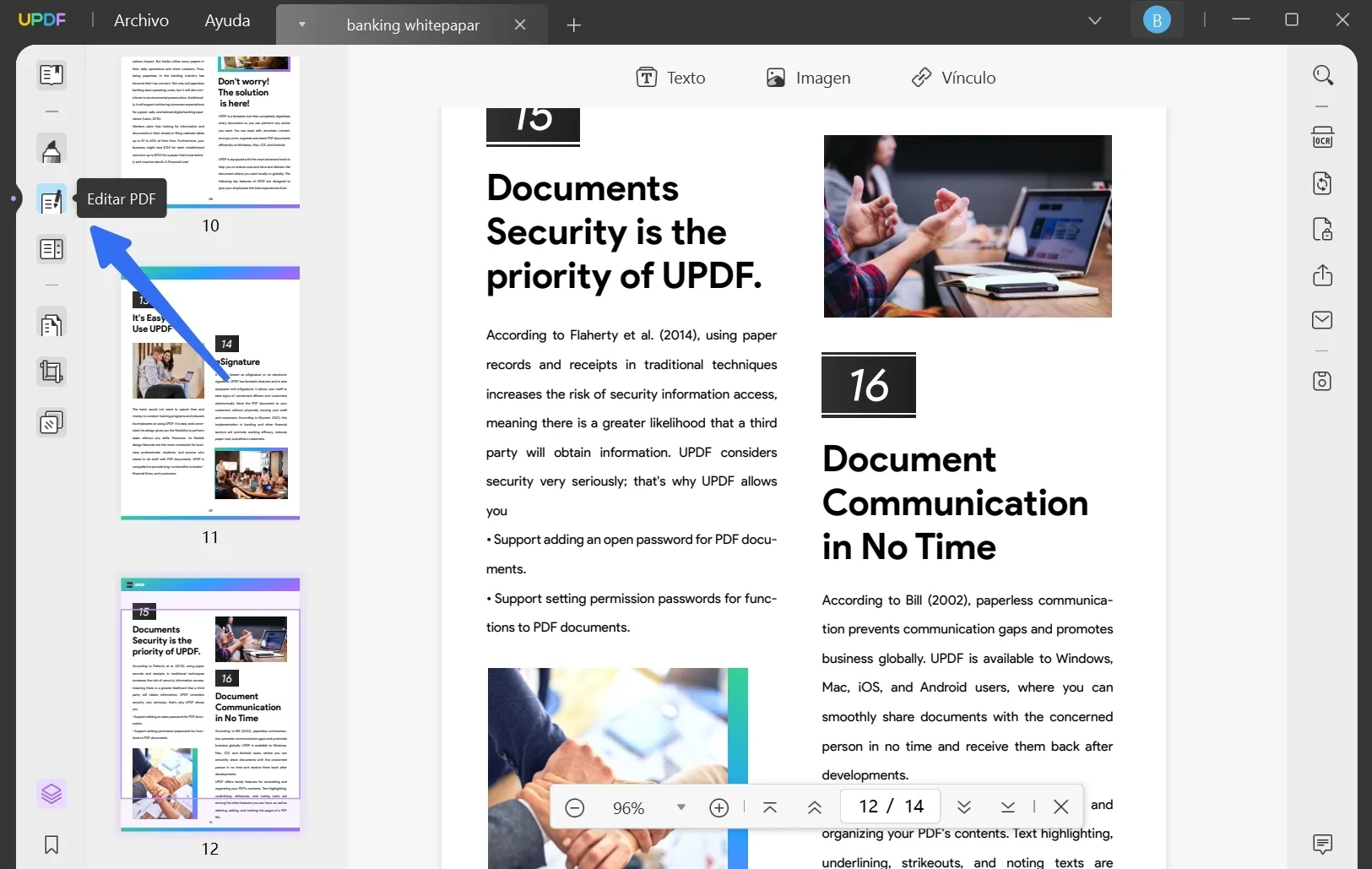
Paso 2: Extraer palabras del PDF
Seleccione el texto que desea extraer de un PDF haciendo clic derecho en él y luego haga clic en la opción " Copiar " o use el acceso directo "Ctrl + C". Después de copiar el texto, puede pegar el texto extraído en un archivo de Word u otros formatos de archivo.

Además, UPDF está disponible en dispositivos Mac, Windows, iOS y Android y admite una licencia para todas las plataformas, lo que la convierte en una solución ideal para usuarios de diferentes sistemas operativos. Además de extraer texto de un PDF, UPDF también tiene muchas otras funciones. Estas son algunas de sus características clave:
Características clave del editor de PDF fácil de usar de UPDF :
UPDF ofrece varias funciones clave para sus usuarios, lo que lo convierte en un centro de soluciones para los editores de PDF cotidianos. Algunas de esas características se mencionan a continuación:
- Convierta PDF a imagen, Word, Excel, PPT y cualquier formato que necesite : UPDF admite la función de convertir PDF a cualquier formato de archivo. Si necesita extraer texto de PDF directamente a Word, Excel u otros formatos, puede hacerlo sin problemas.
- Editar textos PDF y agregue imágenes, textos y enlaces a PDF : UPDF le permite editar textos PDF, cambiar sus fuentes, color y tamaño, cambiar el tamaño de la imagen y agregar textos, imágenes y enlaces a PDF.
- Anotar PDF: agregue notas adhesivas, comentarios de texto, resaltados, tachados, subrayados, formas, pegatinas y más funciones de comentarios a su PDF.
- Administre y organice PDF : UPDF admite insertar, eliminar, extraer, dividir páginas y rotar páginas.
- Agregar una contraseña de apertura y permiso : UPDF también permite a los usuarios agregar una contraseña a los archivos PDF para agregar una capa adicional de seguridad a documentos y formularios PDF importantes.
- Reproducir el PDF en Presentación de diapositivas .
Después de conocer todas las increíbles funciones de UPDF, quizás te preguntes dónde puedes descargar este poderoso software. Haga clic en el botón "Descarga gratuita" a continuación e instálelo ahora.
Windows • macOS • iOS • Android 100% Seguro
Cómo extraer texto de un PDF en línea (sin necesidad de OCR)
Google Drive es una opción alternativa para extraer texto de un PDF escaneado en línea. Los usuarios pueden extraer fácilmente texto y otros elementos de un PDF sin descargar ni instalar software. Es un método fácil, conveniente y confiable en comparación con otros métodos para extraer texto de archivos PDF. A continuación se describen los pasos para extraer información de un archivo PDF en línea utilizando el método de Google Drive:
Paso 1: acceda a Google Drive en su navegador de Internet y haga clic en la pestaña "Nuevo". A continuación, haga clic en "Cargar archivo" en el menú desplegable para buscar el archivo PDF desde su computadora y cargarlo en Google Drive.
Paso 2: Tan pronto como se cargue el archivo PDF, se mostrará en su Mi unidad. Haga clic con el botón derecho en el archivo PDF cargado, toque "Abrir con" y siga eligiendo "Documentos de Google" para abrir el PDF en Documentos de Google.
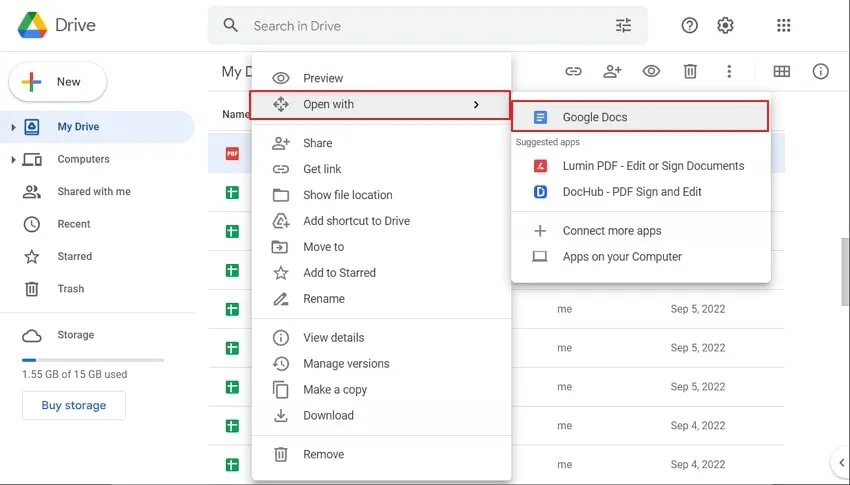
Paso 3: después de abrir el archivo PDF en Google Docs, el texto del archivo PDF se podrá editar automáticamente y podrá extraer fácilmente el texto del PDF en línea de forma gratuita.
Cómo extraer texto de un PDF usando Python
¿Quién hubiera pensado que Python también podría ser una fuente para extraer texto de un PDF? Si está en su computadora y es un usuario frecuente de Python, puede utilizar el paquete PyPDF2 para ejecutar esta tarea. Debe seguir el script que se proporciona a continuación para obtener más información sobre este método:
desde PyPDF2 importar PdfReader
reader = PdfReader("example.pdf")
page = reader.pagers[0]
text = page.extract_text()
print(text)
Preguntas frecuentes sobre la extracción de texto de PDF
1. ¿Se puede extraer texto de una imagen PDF?
Sí, puede extraer texto de imágenes PDF utilizando la función OCR que ofrece UPDF. Importe la imagen PDF en UPDF y haga clic en el icono "Reconocer texto usando OCR" en el panel derecho de la ventana UPDF. Después de hacer clic en "Reconocer texto usando OCR", seleccione la opción "Realizar OCR" para iniciar el proceso de conversión de imagen PDF a PDF editable y con capacidad de búsqueda. Puede extraer texto en los PDF de OCR tan pronto como se complete la conversión.
2. ¿Cómo puedo extraer texto de un PDF sin Acrobat?
Puede extraer texto de un PDF utilizando UPDF en lugar de Adobe Acrobat, ya que es una solución más confiable, potente y compatible, ya que funciona para Mac, Windows, Android e iOS.
3. ¿Puedo extraer texto de PDF en Linux?
Sí, puede extraer contenido de PDF en Linux utilizando diferentes herramientas en línea disponibles en el mercado, como el método Google Drive o la función OCR PDF24 Tools en su sistema operativo Linux.
Conclusión
Si bien hay muchas opciones disponibles en el mercado para extraer texto de PDF, sin embargo, es la opción más sabia y confiable usar herramientas dedicadas y reconocidas para archivos PDF. En ese sentido, UPDF es la mejor opción ya que, además de completar la tarea de manera eficiente y precisa, también mantiene sus datos seguros.
UPDF ofrece una solución simple en la que puede extraer fácilmente texto en archivos PDF siguiendo dos métodos. Descargue UPDF hoy en su computadora con Windows o MacBook y aproveche una experiencia de usuario satisfactoria.
Windows • macOS • iOS • Android 100% Seguro








 Estrella López
Estrella López 
