 Windows
Windows Mac
Mac iPhone/iPad
iPhone/iPad Android
Android Nomostar
Nomostar UPDF AI 在線
UPDF AI 在線 UPDF 數位簽名
UPDF 數位簽名 IvyCraft
IvyCraft PDF 閱讀器
PDF 閱讀器 PDF 文件註釋
PDF 文件註釋 PDF 編輯器
PDF 編輯器 PDF 格式轉換
PDF 格式轉換 建立 PDF
建立 PDF 壓縮 PDF
壓縮 PDF PDF 頁面管理
PDF 頁面管理 合併 PDF
合併 PDF 拆分 PDF
拆分 PDF 裁剪 PDF
裁剪 PDF 刪除頁面
刪除頁面 旋轉頁面
旋轉頁面 PDF 簽名
PDF 簽名 PDF 表單
PDF 表單 PDF 文件對比
PDF 文件對比 PDF 加密
PDF 加密 列印 PDF
列印 PDF 批量處理
批量處理 OCR
OCR UPDF Cloud
UPDF Cloud 關於 UPDF AI
關於 UPDF AI UPDF AI解決方案
UPDF AI解決方案  AI使用者指南
AI使用者指南 UPDF AI常見問題解答
UPDF AI常見問題解答 總結 PDF
總結 PDF 翻譯 PDF
翻譯 PDF 解釋 PDF
解釋 PDF 與 PDF 對話
與 PDF 對話 與圖像對話
與圖像對話 PDF 轉心智圖
PDF 轉心智圖 與 AI 聊天
與 AI 聊天 AI 書籤產生器
AI 書籤產生器 AI 書籤摘要
AI 書籤摘要 AI 浮水印產生器
AI 浮水印產生器 AI 背景產生器
AI 背景產生器 AI 貼圖產生器
AI 貼圖產生器 AI 圖章產生器
AI 圖章產生器 AI 寫作工具組
AI 寫作工具組 UPDF 輔助工具
UPDF 輔助工具 AI 頁面管理
AI 頁面管理 AI 語意搜尋
AI 語意搜尋 PDF 轉成 Word
PDF 轉成 Word PDF 轉成 Excel
PDF 轉成 Excel PDF 轉成 PPT
PDF 轉成 PPT 使用者指南
使用者指南 技術規格
技術規格 產品更新日誌
產品更新日誌 常見問題
常見問題 使用技巧
使用技巧 部落格
部落格 UPDF 評論
UPDF 評論 下載中心
下載中心 聯絡我們
聯絡我們
很多人在處理 PDF 文件時,都曾經遇過這種情況:明明文件已經開啟了,但內容卻無法複製文字、搜尋關鍵字和編輯內容。尤其是掃描論文、拍照文件或舊教材 PDF,最容易出現這種問題。這時很多人就會開始接觸一個名詞 OCR PDF。
不過對大部分使用者來說,真正困惑的通常是:
- OCR PDF 是什麼?
- OCR PDF 和一般 PDF 差在哪?
- 為什麼有些 PDF 能搜尋,有些不行?
- OCR 後的 PDF 真的能編輯嗎?
而這也是現在越來越多人搜尋「OCR PDF 和一般 PDF 有什麼差別」的原因。因為 PDF 早就不只是閱讀工具,而是很多人日常工作、研究與文件管理的重要格式。理解 OCR PDF 的差異,其實也代表你開始真正理解 PDF 的運作邏輯。

一、什麼是一般 PDF?
一般 PDF,其實可以再細分成兩種類型。
| 類型 | 特點 |
| 可編輯 PDF | 可選取文字、搜尋內容 |
| 圖片型 PDF | 本質是圖片,無法搜尋文字 |
很多人以為只要副檔名是 PDF,內容就一定可以複製,但其實不是。
例如Word 匯出的 PDF或者PowerPoint 匯出的 PDF,通常屬於「可編輯 PDF」。而掃描文件、拍照教材、舊書電子檔,則通常屬於「圖片型 PDF」。這也是為什麼很多 PDF 明明看得到文字,卻完全無法搜尋。
二、什麼是 OCR PDF?
OCR 的全名是 Optical Character Recognition(光學文字辨識),它的作用是把圖片中的文字,轉換成可辨識文字。也就是說,OCR PDF 本質上其實是原本不能搜尋的圖片型 PDF,經過 OCR 後變成可搜尋 PDF。
例如一份掃描論文,原本只是一張一張圖片,但經過 OCR 後,系統就能辨識上面的文字,後續就能搜尋內容、複製文字、翻譯段落和編輯 PDF。
三、OCR PDF 和一般 PDF 最大差異在哪?
真正核心差異,其實在於 PDF 裡是否存在可辨識文字層。下面這個差異最容易理解。
| 功能 | 一般圖片型 PDF | OCR PDF |
| 搜尋文字 | 不行 | 可以 |
| 複製文字 | 不行 | 可以 |
| AI 摘要 | 限制較多 | 可以 |
| 翻譯段落 | 不方便 | 可以 |
| PDF 編輯 | 幾乎無法 | 可進一步處理 |
| OCR 辨識 | 未處理 | 已完成 |
因此,OCR 真正重要的,其實不是「把圖片變文字」而已,而是讓 PDF 從靜態圖片,變成可互動文件。
四、為什麼現在越來越多人需要 OCR PDF?
因為現在很多文件來源,其實都不是原始電子檔。例如手機拍照文件、掃描教材、紙本論文、合約掃描檔、歷史資料、PDF 截圖整理。這些文件如果沒有 OCR,後續幾乎很難處理。
尤其現在 AI 工具越來越普及,很多功能其實都建立在文字可被辨識。例如AI 摘要、AI 翻譯、AI 問答、PDF 搜尋等等。因此 OCR 已經不只是掃描功能,而是很多 AI PDF 工作流的基礎。
五、如何使用 UPDF 將一般 PDF 轉成 OCR PDF?
如果 PDF 是掃描檔或圖片型文件,可以直接使用 UPDF 的 OCR 功能。
Windows • macOS • iOS • Android 100% 安全性
操作流程如下:
- 開啟 UPDF。
- 點擊底部「工具」。
- 在「多文件操作(批量工具)」區域選擇「OCR」。
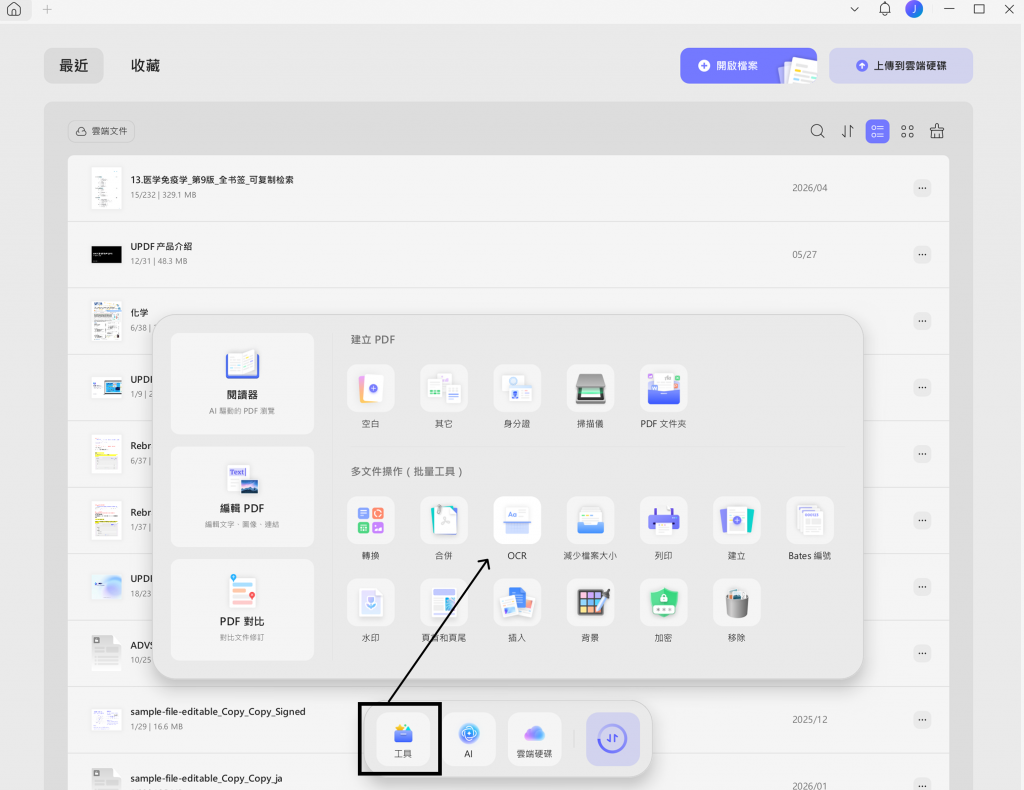
- 點擊「添加文檔」。
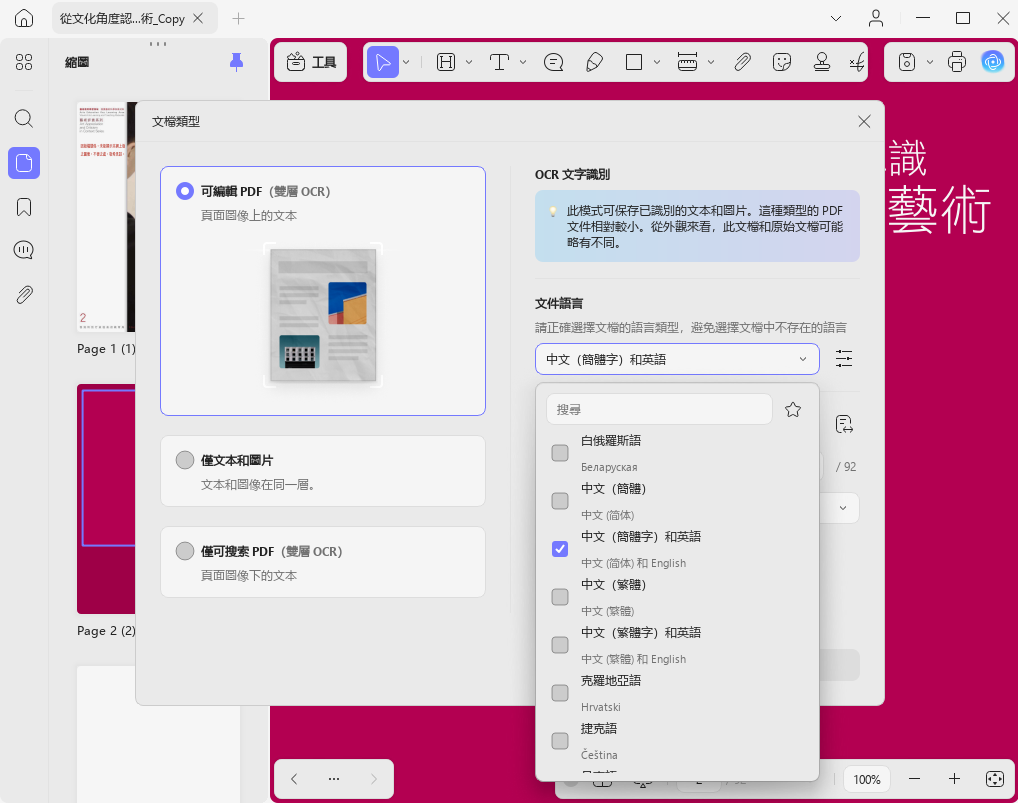
- 匯入需要辨識的 PDF。
- 選擇 OCR 模式,例如「可編輯 PDF(雙層 OCR)」。
- 選擇文件語言。
- 點擊右下角「套用」。
完成後,原本無法搜尋的 PDF,就會變成可辨識文件。後續可以直接搜尋關鍵字、選取文字、AI 翻譯、AI 摘要、匯出 Word 等等。
六、OCR PDF 後真的能直接編輯嗎?
很多人會以為 OCR 完就等於 Word,其實不是。OCR 的主要目的,是建立文字辨識層,而不是完全重建文件。
不過現在像 UPDF 這類工具,通常已經能在 OCR 後進一步做到 PDF 編輯、文字修改、內容搜尋、AI 問答、文件翻譯,因此實際工作流程會比以前方便很多。
七、OCR PDF 最常遇到哪些問題?
OCR 雖然很好用,但實際辨識品質,仍然會受到原始文件影響。以下是常見問題。
| 問題 | 原因 |
| 辨識錯字 | 圖片解析度不足 |
| 中文亂碼 | 文件品質過低 |
| 表格跑掉 | 原始版面複雜 |
| 無法辨識手寫字 | OCR 主要辨識印刷文字 |
| 辨識速度慢 | 文件頁數過多 |
因此,原始掃描品質其實很重要,通常解析度越高、文件越清晰、文字越端正,OCR 效果就越穩定。
八、除了 OCR,UPDF 還能做哪些 PDF 處理?
很多人開始使用 OCR 後,會發現真正需要的其實不只是辨識。例如 PDF 編輯、PDF 翻譯、AI 摘要、PDF 合併、PDF 壓縮、PDF 加密、PDF 轉 Word,而這也是 UPDF 和單純 OCR 工具最大的差異。
它其實更像 AI PDF 文件工作平台。因此在 OCR 完成後,還能直接翻譯論文、問 AI 文件重點,不需要再切換不同軟體。
九、哪些人特別需要 OCR PDF?
這類需求其實非常廣。
| 使用者 | 常見情境 |
| 研究生 | 掃描論文整理 |
| 教師 | 教材數位化 |
| 行政人員 | 掃描文件管理 |
| 律師 | 合約搜尋 |
| 醫療人員 | 病歷文件整理 |
尤其現在很多工作流程,都開始依賴 AI 搜尋、文件整理、關鍵字查詢,因此 OCR PDF 幾乎已經變成基礎能力。
十、常见问题
OCR PDF 和一般 PDF 最大差別是什麼?
OCR PDF 多了可辨識文字層,因此能搜尋與複製文字。
掃描 PDF 一定要 OCR 嗎?
如果需要搜尋、翻譯或編輯,通常都需要 OCR。
OCR 後可以直接修改 PDF 嗎?
可以進一步進行文字搜尋、複製與部分編輯。
十一、結論:OCR PDF 的核心,其實是讓文件真正能被理解
很多人在搜尋「OCR PDF 和一般 PDF 有什麼差別」時,原本只是想解決無法複製文字、PDF 不能搜尋的问题。但真正開始長期處理文件後才會發現,OCR 真正重要的,其實是:
- 提高文件可讀性
- 建立搜尋能力
- 支援 AI 理解內容
- 提升後續整理效率
如果只是單純閱讀 PDF,一般文件或許已經足夠;但若需要長期整理論文、掃描文件與大量資料,像 UPDF 這類支援 OCR、AI 翻譯、PDF 編輯與文件管理的工具,會更適合建立完整數位文件工作流程。因為現在的 PDF,早就不只是「看文件」,而是如何讓文件真正能被搜尋、理解與利用。
Windows • macOS • iOS • Android 100% 安全性









