 Windows
Windows Mac
Mac iPhone/iPad
iPhone/iPad Android
Android UPDF AI 在線
UPDF AI 在線 UPDF 數位簽名
UPDF 數位簽名 PDF 閱讀器
PDF 閱讀器 PDF 文件註釋
PDF 文件註釋 PDF 編輯器
PDF 編輯器 PDF 格式轉換
PDF 格式轉換 建立 PDF
建立 PDF 壓縮 PDF
壓縮 PDF PDF 頁面管理
PDF 頁面管理 合併 PDF
合併 PDF 拆分 PDF
拆分 PDF 裁剪 PDF
裁剪 PDF 刪除頁面
刪除頁面 旋轉頁面
旋轉頁面 PDF 簽名
PDF 簽名 PDF 表單
PDF 表單 PDF 文件對比
PDF 文件對比 PDF 加密
PDF 加密 列印 PDF
列印 PDF 批量處理
批量處理 OCR
OCR UPDF Cloud
UPDF Cloud 關於 UPDF AI
關於 UPDF AI UPDF AI解決方案
UPDF AI解決方案  AI使用者指南
AI使用者指南 UPDF AI常見問題解答
UPDF AI常見問題解答 總結 PDF
總結 PDF 翻譯 PDF
翻譯 PDF 解釋 PDF
解釋 PDF 與 PDF 對話
與 PDF 對話 與圖像對話
與圖像對話 PDF 轉心智圖
PDF 轉心智圖 與 AI 聊天
與 AI 聊天 AI 書籤產生器
AI 書籤產生器 AI 書籤摘要
AI 書籤摘要 AI 浮水印產生器
AI 浮水印產生器 AI 背景產生器
AI 背景產生器 AI 貼圖產生器
AI 貼圖產生器 AI 圖章產生器
AI 圖章產生器 AI 寫作工具組
AI 寫作工具組 UPDF 輔助工具
UPDF 輔助工具 AI 頁面管理
AI 頁面管理 AI 語意搜尋
AI 語意搜尋 PDF 轉成 Word
PDF 轉成 Word PDF 轉成 Excel
PDF 轉成 Excel PDF 轉成 PPT
PDF 轉成 PPT 使用者指南
使用者指南 技術規格
技術規格 產品更新日誌
產品更新日誌 常見問題
常見問題 使用技巧
使用技巧 部落格
部落格 UPDF 評論
UPDF 評論 下載中心
下載中心 聯絡我們
聯絡我們
光學字元辨識(OCR)是一項實用技術,可用於將掃描 / 列印的文件與圖像轉換為可編輯、可搜尋的資料。透過 OCR,使用者能分析掃描文件、編輯既有文字,或提取資料用於後續的資料輸入作業等。
Mistral OCR 是 Mistral AI 近期推出的 API,為開發者提供高準確度的工具,可從文件與圖像中擷取文字。本完整指南將詳細介紹 Mistral OCR,涵蓋其功能、使用步驟、優缺點等資訊。
但若您需要更簡單易用、無須撰寫程式碼的替代方案,UPDF OCR 會是理想的 Mistral OCR 替代工具。您可直接安裝 UPDF,親身體驗其強大的 OCR 功能。或繼續閱讀下文,深入了解 Mistral OCR 的詳細資訊。
Windows • macOS • iOS • Android 100% 安全性
第 1 部分:什麼是 Mistral OCR?
Mistral OCR 是 Mistral 近期推出的光學字元辨識(OCR)API,具備基於 AI 的核心功能,能理解文件與圖像內容,並以極高準確度擷取文字。
Mistral OCR 可辨識複雜的版面配置,區分標題與主要內容,並精準解析表格、多欄結構等元素;無論是文字、圖像、數學公式或表格,皆能完整辨識。此外,將文件轉換為可編輯檔案時,還能保留原始的版面配置與格式,避免後續調整的麻煩。

Mistral OCR 的核心功能
- 複雜文件精準解析:擅長處理交错圖像、表格、數學公式、LaTeX 格式版面等複雜元素,確保資訊完整擷取。
- 版面與格式保留:透過進階 AI 模型,在擷取文字的同時,完整保留文件原始的版面配置與格式。
- 高效處理速度:單一節點每分鐘可處理約 2000 頁文件,適用大量文件的批量處理需求。
- 多語言支援:可處理多種語言與字元集的文件,執行 OCR 辨識作業。
- 自行托管選項:提供自行托管功能,確保敏感、機密資訊在企業自有基礎架構內儲存,提升資安保障。
- 靈活整合能力:內建 Python、TypeScript 用戶端程式庫,也支援透過 curl 進行直接 API 呼叫,方便開發者整合至既有系統。
- 多文件類型相容:可處理 PDF、圖像等多種文件格式,應用場景更廣泛。
- 高可擴充性:支援大規模文件處理工作,隨企業需求彈性調整資源。
上述功能讓 Mistral OCR 不僅是傳統 OCR 工具,更成為下一代文件智慧解決方案。
Mistral OCR 的應用場景
Mistral OCR 在需高品質文字提取的場景中表現突出,常見應用包括:
- 研究論文數位化:研究機構利用其將科學論文、期刊轉為數位格式,使其可支援 AI 分析或檢索。
- 歷史文化遺產保護:非營利組織與文化單位透過 Mistral OCR,將歷史文獻、文物圖像數位化,便於長期保存與查閱。
- 技術文獻轉換:企業將技術手冊、講義筆記、工程圖紙等轉換為可直接回應查詢的格式,提升資訊利用效率。
- 數據自動化輸入:從發票、表單等文件中提取結構化數據,並自動導入系統,減少人工數據輸入的錯誤與時間成本。
總體而言,Mistral OCR 可廣泛應用於各產業的文件處理需求,應用場景幾乎無限。
第 2 部分:Mistral OCR 的優缺點
Mistral OCR 雖是處理文件與圖像的優秀 OCR 工具,但實際使用前需先了解其操作流程與特性。以下為詳細的使用步驟與優缺點分析:
步驟 1:Mistral OCR API 設定
首先需建立 API key:
- 造訪 Mistral API 金鑰頁面,點選「create new key」。
- 為 key 命名,並設定到期日(確保資安)。
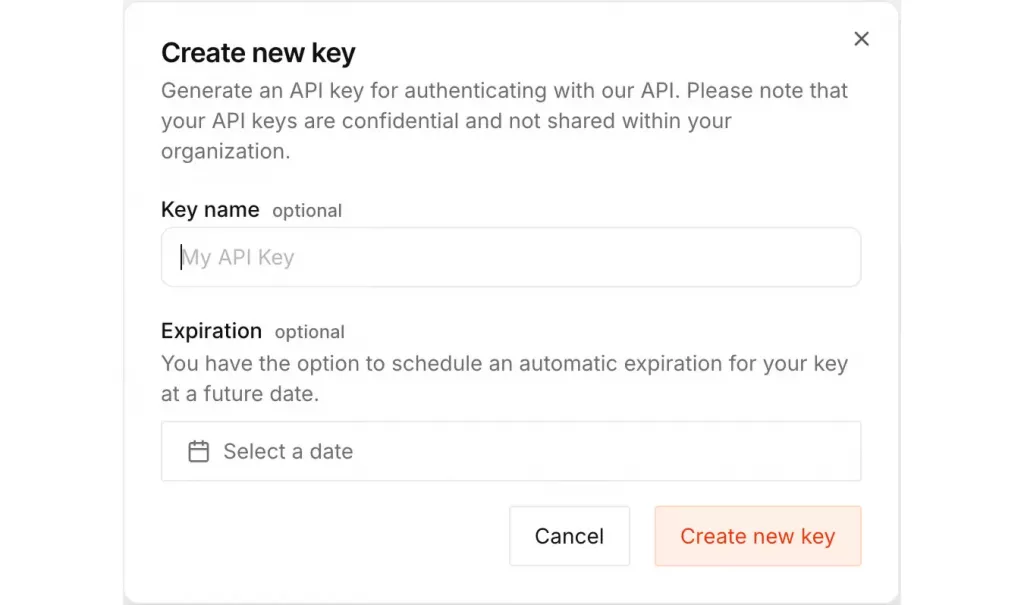
建立 key 後,複製 key 內容,並在將新增程式碼的同一目錄下建立「.env」檔案,格式如下:
MISTRAL_API_KEY=<your_api_key_here>(將<your_api_key_here>替換為實際 key)步驟 2:Python 環境設定
需安裝以下套件,才能在 Python 中呼叫 Mistral OCR API:
- mistralai:與 Mistral API 溝通的官方用戶端。
- python-dotenv:從.env 檔案載入環境變數(即 API 金鑰)。
- datauri:處理圖像數據,並轉換為 API 可辨識的格式。
透過以下指令安裝所有必要套件:
pip install mistralai python-dotenv datauri環境設定完成且 API 金鑰就緒後,即可開始使用 Mistral OCR。
步驟 3:透過文件 URL 執行 OCR
以下程式碼可透過文件 URL 執行 OCR,並列印結構化的 Markdown 格式結果:
python
import os
from mistralai import Mistral
class SimpleOCRAgent:
def __init__(self, api_key):
self.client = Mistral(api_key=api_key)
def process_document(self, document_url):
response = self.client.ocr.process(
model="mistral-ocr-latest",
document={
"type": "document_url",
"document_url": document_url
},
include_image_base64=True
)
return response
if __name__ == "__main__":
api_key = os.environ.get("MISTRAL_API_KEY")
if not api_key:
raise ValueError("Please set the MISTRAL_API_KEY environment variable.")
agent = SimpleOCRAgent(api_key=api_key)
document_url = "https://arxiv.org/pdf/2202.04234" # 可依需求替換URL
result = agent.process_document(document_url)
print("OCR Result:")
print(result)
程式碼說明
- 初始化階段:代理程式(Agent)載入 API 金鑰,完成 Mistral OCR 服務的驗證。
- 文件處理階段:透過
process_document方法,將文件 URL 提交至 OCR 引擎進行辨識。 - 結果輸出階段:API 回應包含結構化的 OCR 數據,以 Markdown 格式呈現,整合了擷取的文字與中繼數據,提升可讀性。
透過類似程式碼片段,可調整參數以應對不同的 OCR 使用場景。
Mistral OCR 的優缺點
| 優點 | 缺點 |
|---|---|
| 處理速度快(單節點每分鐘 2000 頁) | 文件大小限制 50MB 以內,頁數不超過 1000 頁 |
| 支援複雜格式,版面保留效果佳 | 僅提供 API 形式的 OCR 功能,無本機桌面介面 |
| 多語言辨識能力強 | 需技術整合,對非開發者不友好 |
| 可擴充性高,適用大規模作業 | 需具備程式碼撰寫能力,學習曲線陡峭 |
第 3 部分:更易用的 OCR 替代方案 ——UPDF
Mistral OCR 適合熟悉技術整合的開發者,但多數用戶若需要簡單直觀的點擊式介面,UPDF 會是更理想的選擇。
UPDF 是一款進階的 PDF 編輯器與 OCR 工具,搭載 AI 功能,介面易於操作。無論是掃描 PDF、紙本文件或圖片,皆可透過 UPDF 快速轉換為可編輯、可搜尋的 PDF 檔案;只需幾下滑鼠,即可執行 OCR,並支援 38 種語言的文字擷取。
UPDF 採用先進辨識技術,不僅 OCR 準確率高達 99%,處理速度快,還能完整保留文件原始的版面配置與格式,避免後續調整格式的麻煩。
Windows • macOS • iOS • Android 100% 安全性
UPDF OCR 的核心功能
- 高準確度 OCR 辨識
可處理包含圖形、表格、數學公式的複雜文件,輸出結果不僅可編輯、可搜尋,還能完整保留原始格式。 - 自訂 OCR 設定
支援調整版面配置、解析度、辨識頁面範圍等參數,並能智慧偵測文件中的多種語言,提升辨識精準度。 - 直覺式使用者介面
無須撰寫任何程式碼,透過點擊即可完成 OCR 操作:打開文件後,幾步簡單設定就能執行辨識,零學習曲線。 - 跨平台相容性
支援在 Windows、macOS、iOS 裝置上執行 OCR,無論是電腦或行動裝置,皆可靈活使用。 - 豐富的延伸功能
UPDF 不僅是 OCR 工具,還整合了 PDF 編輯、註解、轉換、壓縮、整理、簽署等功能;內建的 AI 功能更能協助分析 PDF,如生成摘要、翻譯文字、對談互動、建立心智圖等,一站解決所有 PDF 處理需求。
UPDF 執行 OCR 的步驟
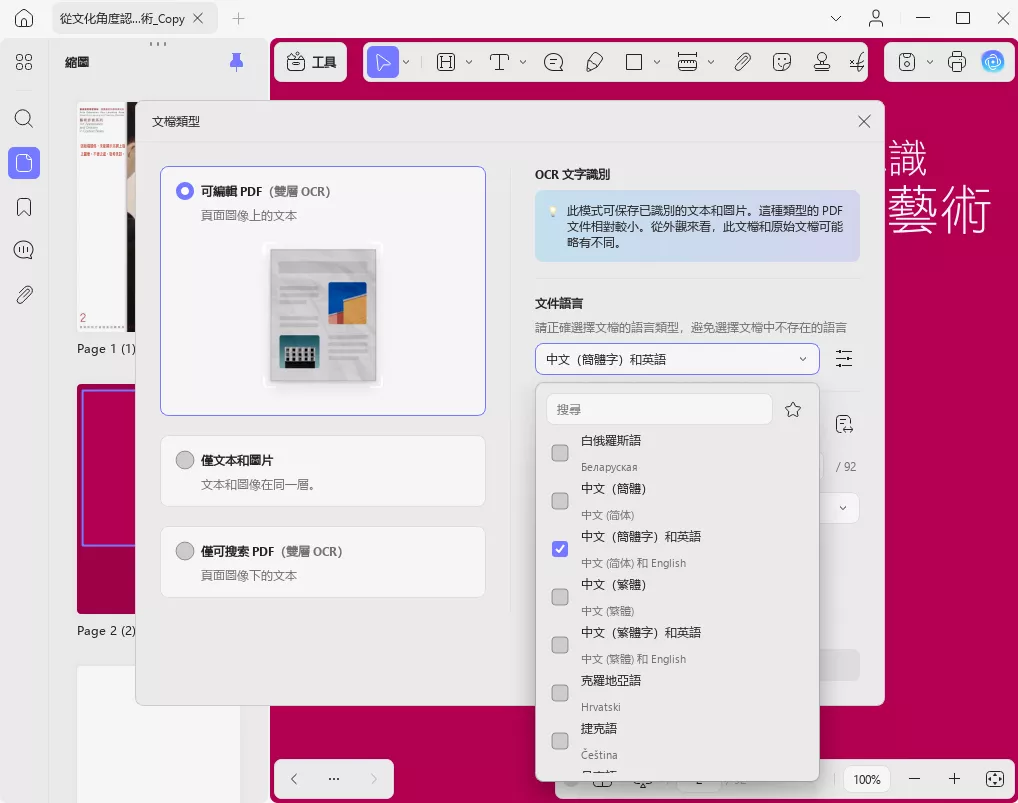
- 在 Windows 或 Mac 電腦上安裝並啟動 UPDF,將 PDF 或圖像檔案拖曳至主儀表板,即可開啟文件。
- 文件開啟後,從右側面板的「工具」選單中點選「OCR」;依需求調整版面配置、辨識語言、解析度等參數,設定完成後點擊「轉換」。
幾秒鐘內,UPDF 就會生成新的 PDF 檔案 —— 不僅包含可編輯、可搜尋的文字,還能完整保留原始文件的格式與版面。
結論
Mistral OCR 作為一款強大的 OCR API,確實能高效處理複雜文件,其準確、快速的文字擷取能力也吸引不少開發者在各場景中部署。但它缺乏圖形化使用者介面(GUI)、文件大小受限,且需要技術整合能力,對一般用戶來說使用門檻較高。
相較之下,UPDF 不僅具備與 Mistral OCR 同等的 OCR 辨識品質,還提供更直觀的操作體驗,無須程式碼即可上手;同時整合了豐富的 PDF 處理功能,能一站式解決文件管理需求。因此,若您想避免技術整合的繁瑣步驟,UPDF 會是更實用的 OCR 工具選擇。
Windows • macOS • iOS • Android 100% 安全性










