 Windows
Windows Mac
Mac iPhone/iPad
iPhone/iPad Android
Android UPDF AI 在線
UPDF AI 在線 UPDF 數位簽名
UPDF 數位簽名 PDF 閱讀器
PDF 閱讀器 PDF 文件註釋
PDF 文件註釋 PDF 編輯器
PDF 編輯器 PDF 格式轉換
PDF 格式轉換 建立 PDF
建立 PDF 壓縮 PDF
壓縮 PDF PDF 頁面管理
PDF 頁面管理 合併 PDF
合併 PDF 拆分 PDF
拆分 PDF 裁剪 PDF
裁剪 PDF 刪除頁面
刪除頁面 旋轉頁面
旋轉頁面 PDF 簽名
PDF 簽名 PDF 表單
PDF 表單 PDF 文件對比
PDF 文件對比 PDF 加密
PDF 加密 列印 PDF
列印 PDF 批量處理
批量處理 OCR
OCR UPDF Cloud
UPDF Cloud 關於 UPDF AI
關於 UPDF AI UPDF AI解決方案
UPDF AI解決方案  AI使用者指南
AI使用者指南 UPDF AI常見問題解答
UPDF AI常見問題解答 總結 PDF
總結 PDF 翻譯 PDF
翻譯 PDF 解釋 PDF
解釋 PDF 與 PDF 對話
與 PDF 對話 與圖像對話
與圖像對話 PDF 轉心智圖
PDF 轉心智圖 與 AI 聊天
與 AI 聊天 AI 書籤產生器
AI 書籤產生器 AI 書籤摘要
AI 書籤摘要 AI 浮水印產生器
AI 浮水印產生器 AI 背景產生器
AI 背景產生器 AI 貼圖產生器
AI 貼圖產生器 AI 圖章產生器
AI 圖章產生器 AI 寫作工具組
AI 寫作工具組 UPDF 輔助工具
UPDF 輔助工具 AI 頁面管理
AI 頁面管理 AI 語意搜尋
AI 語意搜尋 PDF 轉成 Word
PDF 轉成 Word PDF 轉成 Excel
PDF 轉成 Excel PDF 轉成 PPT
PDF 轉成 PPT 使用者指南
使用者指南 技術規格
技術規格 產品更新日誌
產品更新日誌 常見問題
常見問題 使用技巧
使用技巧 部落格
部落格 UPDF 評論
UPDF 評論 下載中心
下載中心 聯絡我們
聯絡我們
OCR(光學字元辨識)代表著一種變革性的力量,它改變了我們從圖像和掃描文檔中提取文字的方式。這種技術能讓機器辨識列印或手寫文字,並轉換為可讀取的數據。雖然許多用戶想了解如何使用 TensorFlow 訓練自訂 OCR 模型,但也有部分用戶希望透過更簡單的方式達成目標。
TensorFlow 是一個開源 AI 平台,提供各種工具讓用戶構建高效的 OCR 工具。不過,了解其功能並選用合適的方法,對初學者來說可能相當有挑戰。本文將說明如何訓練與執行自訂模型,同時示範如何透過 TensorFlow 進行 OCR 辨識。另外,我們也會介紹如何透過更高效的方法簡化工作流程。
第 1 部分:如何使用 TensorFlow 訓練自訂 OCR 模型?
在數位時代,大學時常需要將手寫課堂筆記數位化,方便存取與搜尋。一般標準的 OCR 工具可能難以應對多樣化的書寫風格,而透過 TensorFlow 訓練自訂 OCR 模型,就能提供更可靠的解決方案。以下是訓練自訂 OCR TensorFlow 模型的詳細步驟說明:
步驟 1:安裝 TensorFlow
在整合 OCR 模型前,請先透過指定指令安裝 TensorFlow,以便利用其機器學習功能進行後續訓練。

步驟 2:導入程式庫
導入 OpenCV、NumPy、Matplotlib、TensorFlow 與 Keras 等程式庫,分別用於圖像處理、模型建構與訓練作業。
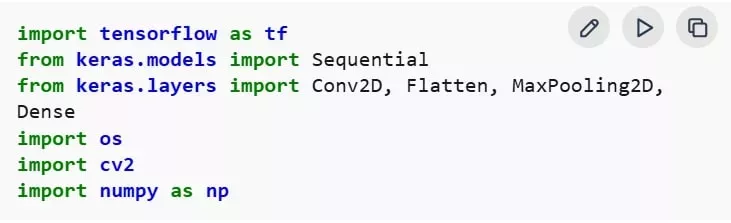
步驟 3:下載並準備資料集
下載並解壓縮資料集(內含用於 OCR 訓練的手寫文字圖像),確保資料格式符合後續處理需求。
步驟 4:圖像預處理
透過上述程式庫從資料集中讀取每一張圖像,將圖像尺寸調整為 64x64 像素,並將像素值標準化至指定範圍,為模型訓練做好準備。
步驟 5:轉換為 NumPy 數組
為提升計算效率,需將預處理後的圖像與其標籤轉換為 NumPy 數組(格式為三維數組),方便模型讀取與運算。

步驟 6:標籤數值化
透過「LabelEncoder」將文字形式的類別標籤轉換為數值格式,確保模型能順利進行訓練(模型僅支援數值型輸入)。

步驟 7:打亂資料集順序
打亂資料集順序以避免訓練時產生偏差,同時確保圖像與標籤的對應關係正確。為數據加入隨機性,有助於提升模型的泛化能力。

步驟 8:建構 OCR 模型
透過 Keras AI 建構 OCR 模型,並以 TensorFlow 作為後端支援:
- 首先加入一個含 16 個濾波器的卷積層;
- 接著分別加入含 32、64 與 128 個濾波器的卷積層,並透過 MaxPooling 降低數據維度;
- 將卷積層輸出結果展平後,傳遞至含 128 或 64 個神經元的 Dense Layer;
- 最後加入含 36 個神經元的「softmax」層,用於多類別分類任務。

步驟 9:編譯模型
- 採用「Adam」最佳化器以實現適應性學習,提升訓練效率;
- 透過「Sparse Categorical Crossentropy」處理含整數標籤的多類別分類問題;
- 設定以「準確率」作為核心指標,即時監控模型在訓練過程中的效能。
步驟 10:訓練 OCR 模型
最後,使用經過洗牌的資料集訓練模型,並採用驗證分割來監控訓練過程中的效能。

第 2 部分:如何使用 TensorFlow 對圖像或掃描文件執行 OCR 辨識
律師事務所也需將數千份掃描法律文件數位化,使其可編輯。依照上述步驟訓練好 OCR TensorFlow 模型後,就能以數位化方式儲存這些檔案,供全球研究人員存取使用。
若你使用的是掃描文件,需先將其轉換為圖像格式(如 JPG、PNG)。以下提供逐步教程,示範如何透過圖像測試整合 TensorFlow 的模型:
步驟 1:測試圖像預處理
測試圖像需經過與前述相同的處理步驟,包含調整尺寸、標準化與格式轉換,確保與模型訓練時的輸入格式一致,以便進行後續評估。
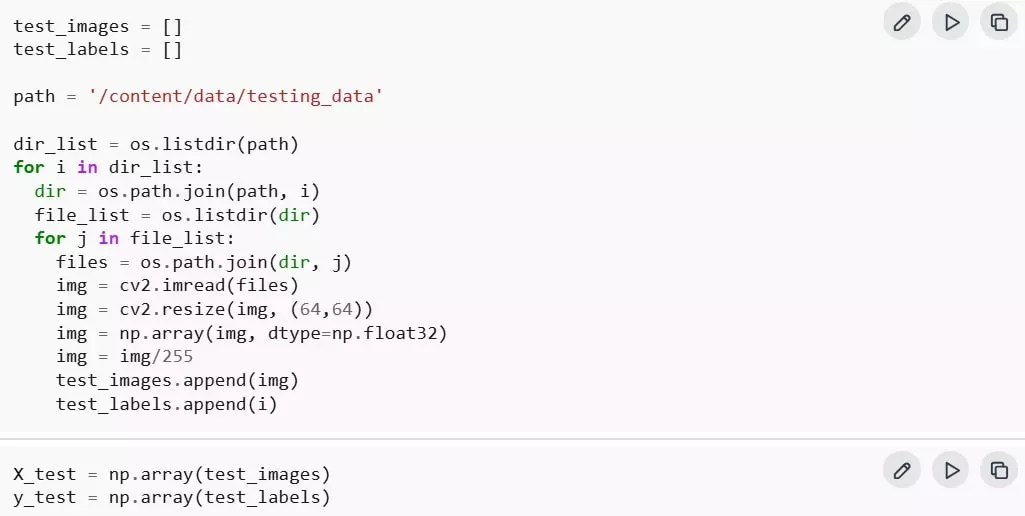
步驟 2:執行標籤預測
- 利用訓練完成的模型預測測試資料集的標籤;
- 透過「np.argmax」函數提取每個圖像樣本的對應類別;
- 再透過「LabelEncoder」將數值標籤轉換回原始文字格式;
- 最後顯示測試圖像及其對應的預測標籤,確認辨識結果是否正確。
輸出結果:
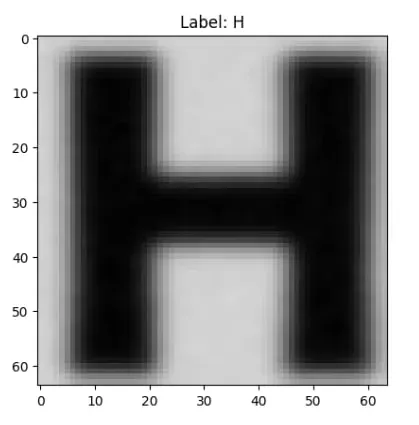
步驟 3:真實標籤處理
在模型評估階段,需透過「LabelEncoder」將測試資料集的真實標籤轉換為數值格式,確保標籤編碼方式與訓練時一致,避免評估結果出現偏差。
步驟 4:模型效能測試
利用測試圖像與真實標籤對訓練完成的模型進行測試,評估過程會輸出「測試損失(Test Loss)」與「測試準確率(Test Accuracy)」,作為衡量模型在測試數據中誤差與精確度的核心指標。
步驟 5:列印出測試準確率數值
在測試資料集上完成模型評估後,列印出測試準確率數值,明確判斷模型在未接觸過的資料上的效能表現,驗證模型的實用性。

很明顯,透過 TensorFlow 進行 OCR 辨識相當耗時,因此推薦使用 UPDF 這類簡化工具。用戶只需點擊幾下,就能從圖像與掃描文件中提取文字,無需撰寫任何程式碼或進行複雜設定。趕緊下載 UPDF,快速獲取可精準搜尋的文字內容吧!
Windows • macOS • iOS • Android 100% 安全性
第 3 部分:使用 UPDF 更高效地對圖像和掃描 PDF 文檔執行 OCR 辨識
UPDF 是一款全方位的 PDF 文檔編輯器,能即時簡化文件管理作業。儘管透過 TensorFlow 進行 OCR 需撰寫程式碼與訓練模型,UPDF 的 OCR 功能則能快速轉換掃描文件與圖像,不僅可為最終輸出結果選擇對應語言與圖像解析度,還能設定頁面範圍,只對特定頁面執行 OCR 辨識,大幅提升效率。
教程 1:使用 UPDF 對圖像執行 OCR 辨識
以下為詳細步驟,教你透過 UPDF 功能對圖像執行 OCR 辨識:
步驟 1:將圖像轉換為 PDF 文檔
- 在裝置上安裝並打開 UPDF;
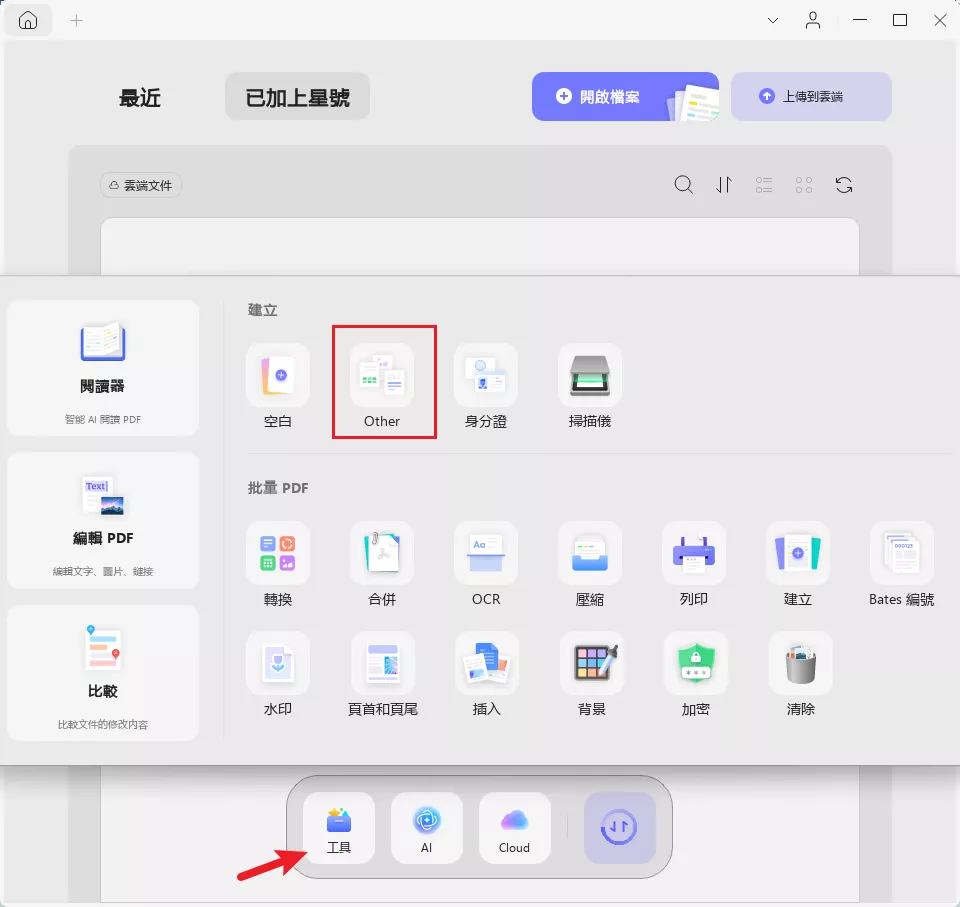
- 點擊軟體中的「工具」選項,開啟彈窗;
- 從清單中點選「other」,再從展開的子選單中選擇「從檔案建立 PDF 文檔」,將目標圖像匯入並轉換為 PDF 格式。
步驟 2:設定 OCR 參數並執行
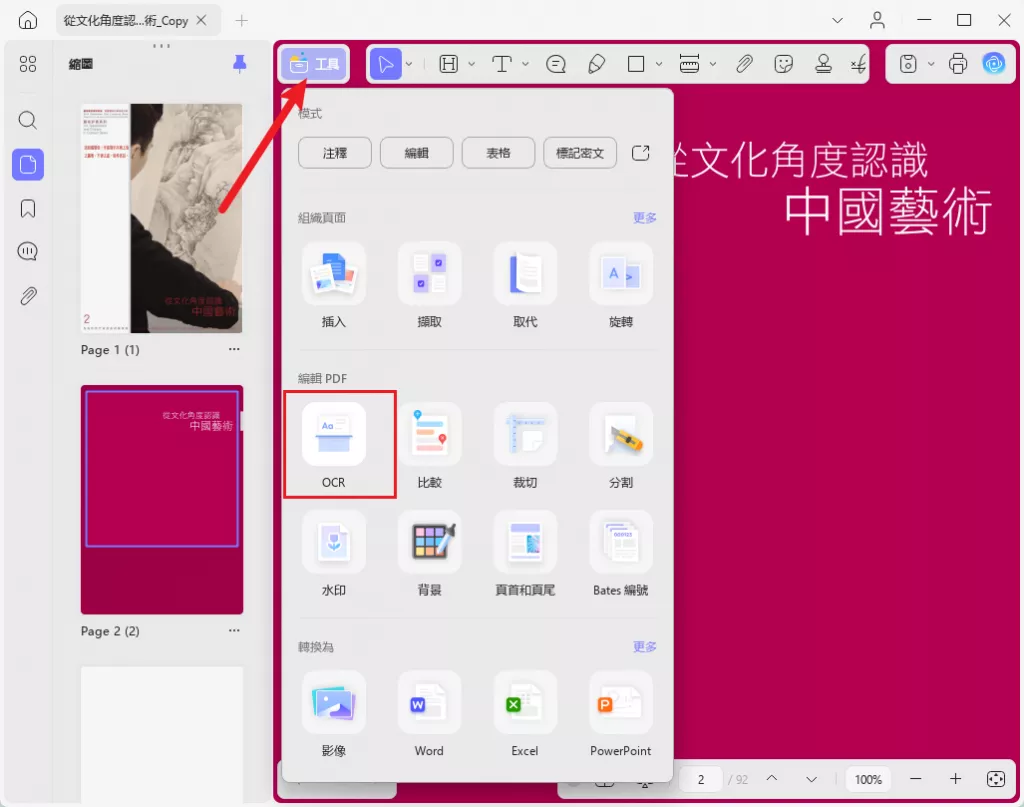
- 圖像轉換為 PDF 文檔後,點擊工具中的「OCR」選項;
- 從顯示的選單中展開「佈局」設定,選擇「僅文字和圖片」選項(符合一般辨識需求);
- 點選「偵測最佳解析度」自動調整圖像解析度,並選擇文件對應的語言(如繁體中文、英文等);
- 最後點選底部的「執行 OCR」按鈕,等待處理完成後即可得到可編輯的文件。
步驟 3:編輯 OCR 辨識結果
在 OCR 處理完成的文件中,切換至右側工具面板的「編輯 PDF 文檔」圖示,選取文件中的文字進行標註、更改顏色或調整字體,方便後續整理與使用。
教程 2:使用 UPDF 對掃描 PDF 文檔執行 OCR 辨識
除了前述基於 TensorFlow 的 OCR 方法外,以下教程將說明如何透過 UPDF 對掃描 PDF 文檔執行 OCR 辨識:
步驟 1:匯入掃描 PDF 文檔
- 開啟 UPDF 工具,從主畫面點選「開啟檔案」按鈕;
- 選擇目標掃描 PDF 文檔,將其匯入工具中,準備執行 OCR 辨識。
步驟 2:配置 OCR 辨識設定
- 切換至左側面板右上角的「OCR」圖示;
- 展開「版面配置」設定(可依需求選擇「保留原有版面」「僅文字」或「僅文字和圖片」);
- 選擇文件對應的語言,並手動調整解析度(或勾選「偵測最佳解析度」);
- 若只需處理部分頁面,可在「頁面範圍」中設定具體頁數(如「1-5」「7」等)。
步驟 3:編輯辨識後的文件
- 點選「執行 OCR」按鈕,完成後即可獲取可存取、可編輯的 PDF 文檔;
- 切換至右側工具列的「編輯 PDF 文檔」圖示,選取文件中的任意文字,調整字體大小、顏色或內容,即時進行編輯作業。
總結
總結來說,採用機器學習方法從掃描文件中提取文字,不僅能針對各類應用場景進行自訂與調整,也是相當可靠的做法。但透過 TensorFlow 進行光學字元辨識,需進行模型設定與訓練,不僅流程複雜,也相當耗時。
因此,UPDF 可說是最佳解決方案,不僅能生成高品質的辨識結果(準確率達 99%),更支援用戶調整最終 OCR 文件的頁面範圍與版面配置,無論是個人日常使用還是企業文書處理,都能大幅提升工作效率。
Windows • macOS • iOS • Android 100% 安全性











