UPDF na Windows
UPDF na Windows UPDF na Mac
UPDF na Mac UPDF na iPhone/iPad
UPDF na iPhone/iPad UPDF na Android
UPDF na Android UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign Edytuj PDF
Edytuj PDF Zaznacz PDF
Zaznacz PDF Utwórz PDF
Utwórz PDF Formularz PDF
Formularz PDF Edytuj linki
Edytuj linki Przekonwertuj PDF
Przekonwertuj PDF OCR
OCR PDF do Word
PDF do Word PDF do obrazu
PDF do obrazu PDF do Excel
PDF do Excel Zarządzaj PDF
Zarządzaj PDF Scalać PDF
Scalać PDF Podziel PDF
Podziel PDF Przytnij PDF
Przytnij PDF Obróć PDF
Obróć PDF Zabezpiecz PDF
Zabezpiecz PDF Podpisz PDF
Podpisz PDF Redaguj PDF
Redaguj PDF Oczyść PDF
Oczyść PDF Usuń ochronę
Usuń ochronę Otwórz PDF
Otwórz PDF UPDF Chmura
UPDF Chmura Skompresuj PDF
Skompresuj PDF Drukuj PDF
Drukuj PDF Przetwarzanie wsadowe
Przetwarzanie wsadowe O UPDF AI
O UPDF AI Rozwiązania UPDF AI
Rozwiązania UPDF AI Podręcznik użytkownika AI
Podręcznik użytkownika AI FAQ dotyczące UPDF AI
FAQ dotyczące UPDF AI Podsumuj PDF
Podsumuj PDF Przetłumacz PDF
Przetłumacz PDF Porozmawiaj z PDF-em
Porozmawiaj z PDF-em Porozmawiaj z AI
Porozmawiaj z AI Porozmawiaj z obrazem
Porozmawiaj z obrazem PDF do mapy myśli
PDF do mapy myśli Wyjaśnij PDF
Wyjaśnij PDF Narzędzia PDF AI
Narzędzia PDF AI Narzędzia obrazu AI
Narzędzia obrazu AI Czat AI
Czat AI Pisanie AI
Pisanie AI Nauka z AI
Nauka z AI Praca z AI
Praca z AI Inne narzędzia AI
Inne narzędzia AI PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF do PowerPoint
PDF do PowerPoint Przewodnik użytkownika
Przewodnik użytkownika Sztuczki UPDF
Sztuczki UPDF FAQs
FAQs Recenzje UPDF
Recenzje UPDF Centrum pobierania
Centrum pobierania Blog
Blog Sala prasowa
Sala prasowa Specyfikacja techniczna
Specyfikacja techniczna Aktualizacje
Aktualizacje UPDF a Adobe Acrobat
UPDF a Adobe Acrobat UPDF a Foxit
UPDF a Foxit UPDF a PDF Expert
UPDF a PDF Expert
Format PDF stał się najczęściej przyjmowanym formatem dla firm. Ponieważ większość ważnych danych firm jest zapisywana w plikach PDF, często wymagane jest wyodrębnienie tekstu z pliku PDF . Jednak może się to okazać trudne, ponieważ kopiowanie, wyodrębnianie i edytowanie tekstów w plikach PDF nie jest możliwe bez odpowiednich metod i narzędzi, szczególnie jeśli pliki PDF są skanowane lub tworzone z obrazów.
Niektórzy z Was mogą wiedzieć, że można wyodrębnić tekst z PDF za pomocą OCR. Ale kiedy należy lub nie należy używać OCR? Dla wygody ten artykuł przedstawi rozwiązania dotyczące wyodrębniania tekstów z plików PDF z użyciem funkcji OCR i bez niej. Czytaj dalej.
Sposób 1. Jak wyodrębnić tekst z pliku PDF za pomocą OCR?
Jeśli pliki PDF są tworzone przez skaner lub obrazy, powszechnie stosowaną metodą wyodrębniania tekstu z PDF jest użycie edytora PDF z narzędziem OCR. Tutaj użyjemy UPDF , aby pokazać, jak wyodrębnić tekst z zeskanowanych lub opartych na obrazach plików PDF.

UPDF to innowacyjny edytor PDF oferujący kompletne rozwiązanie plików PDF, które spełnia potrzeby dużych organizacji, jak również osób pracujących na małą skalę. Oferuje wszystkie potrzebne funkcje, takie jak edycja, konwersja, scalanie i adnotowanie plików PDF.
Jeśli chcesz wyodrębnić tekst z zeskanowanych plików PDF, możesz użyć UPDF, ponieważ zapewnia on specjalną funkcję OCR, która może pomóc Ci przekształcić zeskanowane dokumenty PDF w edytowalny i wyodrębnialny tekst. Możesz wykonać poniższe kroki:
Krok 1. Pobierz i zainstaluj UPDF
Teraz pobierz UPDF i postępuj zgodnie z poniższym przewodnikiem, aby dowiedzieć się, jak wyodrębnić tekst z zeskanowanych plików PDF.
Windows • macOS • iOS • Android 100% bezpieczne
Krok 2: Uzyskaj dostęp do funkcji OCR
Możesz zacząć od otwarcia pliku PDF w UPDF i kliknięcia przycisku „ Rozpoznaj tekst za pomocą OCR ” po prawej stronie.
W oknie pop-up wybierz „PDF z możliwością wyszukiwania”, a następnie określ układ w ustawieniach „Układ”. Wybierz „Tylko tekst i obrazy”, „Tekst na obrazie strony” lub „Tekst pod obrazem strony” i jeśli są jakieś zaawansowane opcje układu, na które warto zwrócić uwagę, wybierz ikonę „Koła zębatego” i w razie potrzeby popracuj nad opcjami.
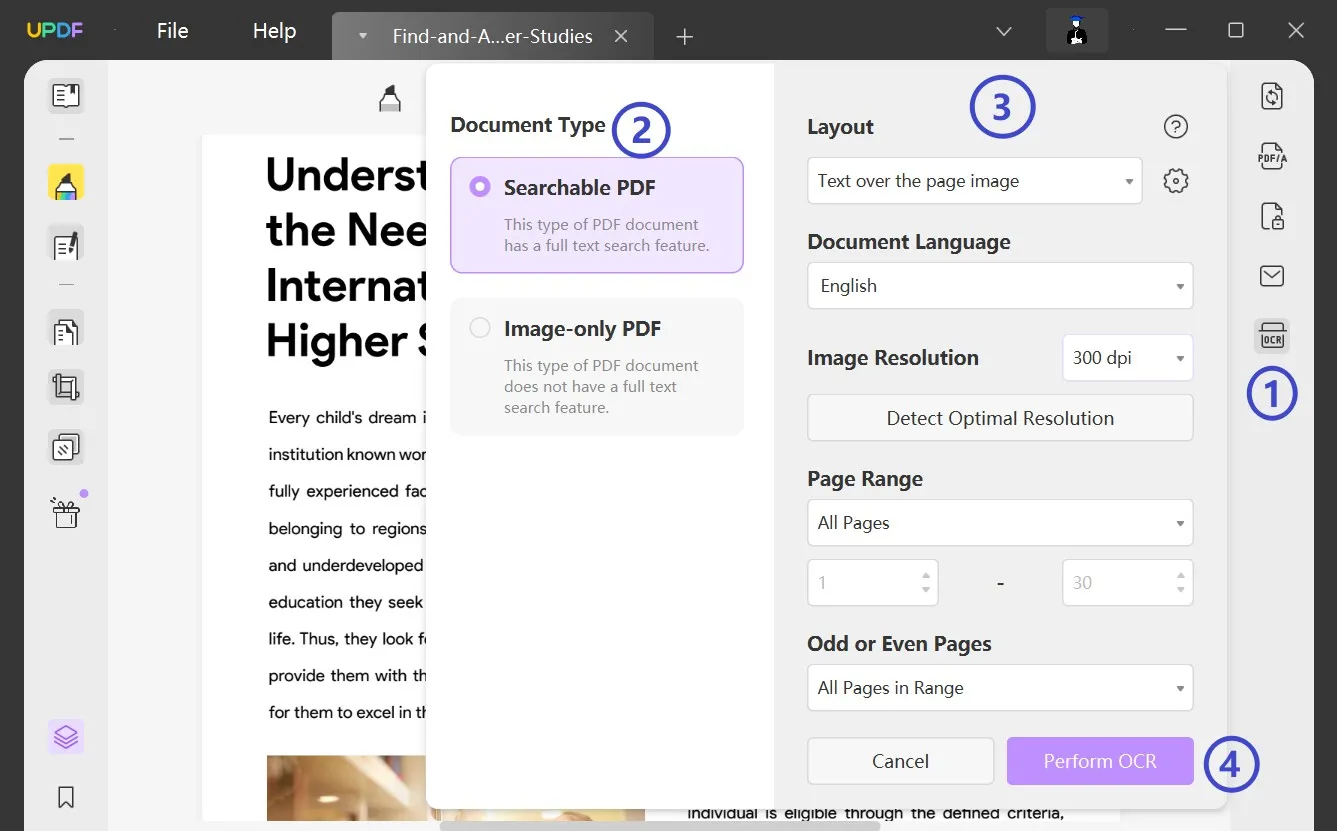
Wybierz Język dokumentu z listy 38 różnych dostępnych języków. Następnie pracuj nad ustawieniami „Rozdzielczość obrazu” i ustaw konkretną wartość z listy z nią związanej. Jeśli nie jesteś pewien, naciśnij przycisk „Wykryj optymalną rozdzielczość” i kontynuuj.
Krok 3: Wykonaj OCR pomyślnie
Wybierz zakres stron, na których chcesz uruchomić narzędzie OCR. Następnie wybierz przycisk „ Wykonaj OCR ”, wybierz lokalizację do zapisania dokumentu OCR i pozwól procesowi się wykonać. Po wykonaniu otwiera się w UPDF, gdzie możesz wyodrębnić tekst z pliku PDF.
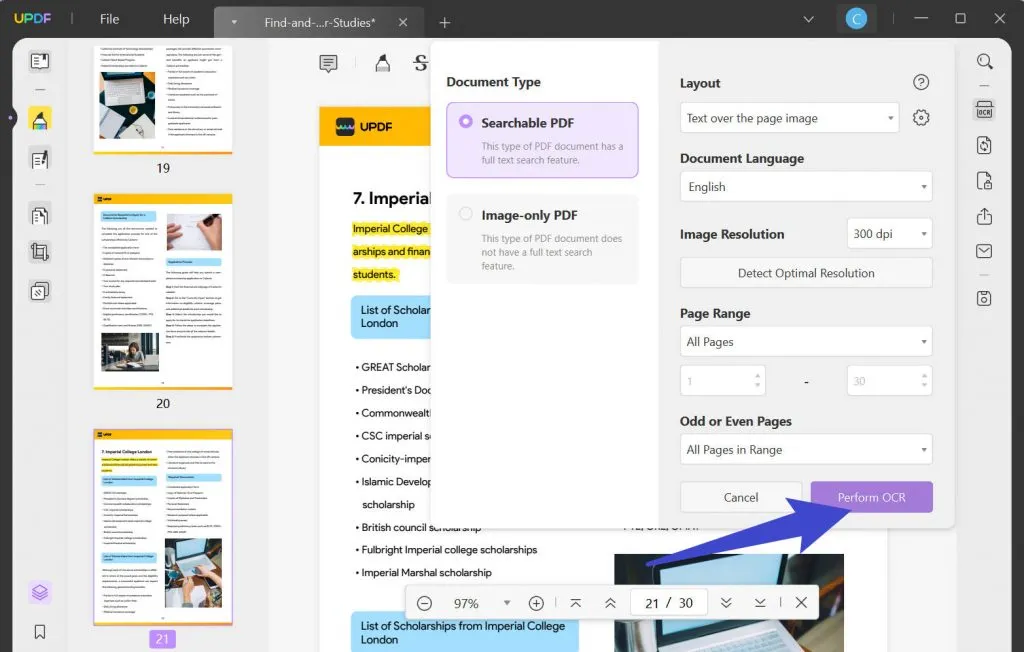
Krok 4. Wyodrębnij lub skopiuj tekst z pliku PDF
Teraz możesz kliknąć i zaznaczyć tekst, który chcesz skopiować i wyodrębnić w pliku PDF, a następnie skopiować go i wkleić w wybranym miejscu docelowym.
Przeczytaj także : Jak usunąć OCR z pliku PDF? (3 sposoby)
Sposób 2. Jak wyodrębnić tekst z pliku PDF do formatu Word/Excel/innego
Powyższa metoda może okazać się dobra, jeśli musisz skopiować tekst jednej części pliku PDF. Zajmie to dużo czasu, jeśli musisz wyodrębnić cały tekst z pliku PDF. Istnieje szybki sposób na użycie UPDF. Sprawdź, jak to zrobić tutaj.
Krok 1. Otwórz plik PDF i przejdź do opcji „Eksportuj PDF”
Uruchom UPDF na swoim komputerze, kliknij „Otwórz plik” i wybierz plik PDF na swoim komputerze, aby go otworzyć.
Przejdź do „ Eksportuj PDF ” w menu po prawej stronie i kliknij na niego. Wybierz żądany format, którego potrzebujesz. Na przykład wybierz „Word”.
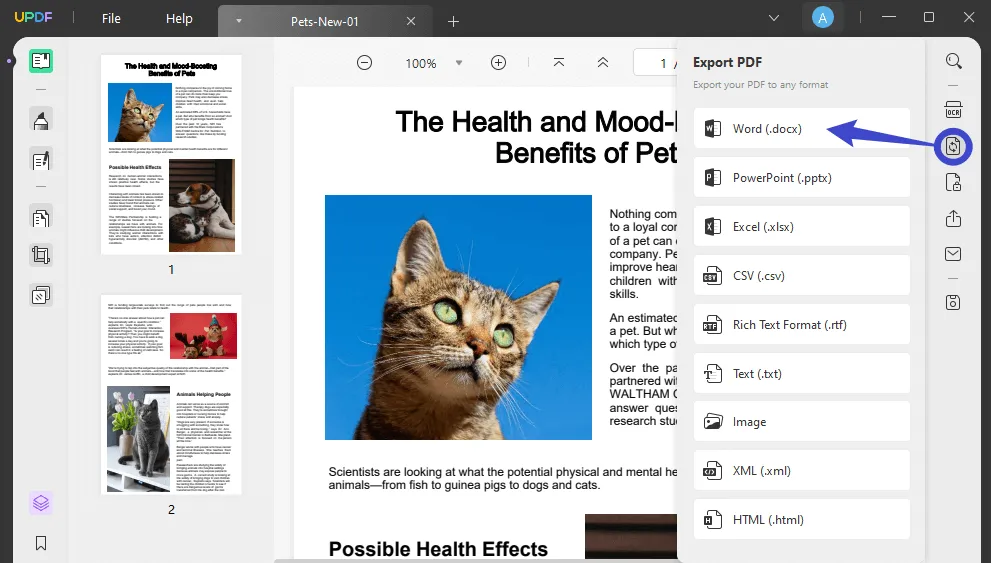
(Uwaga: Jeśli Twój dokument PDF jest zeskanowany, musisz najpierw wykonać OCR zgodnie z instrukcjami w Sposobie 1. Wykonany dokument OCR zostanie automatycznie otwarty w UPDF.)
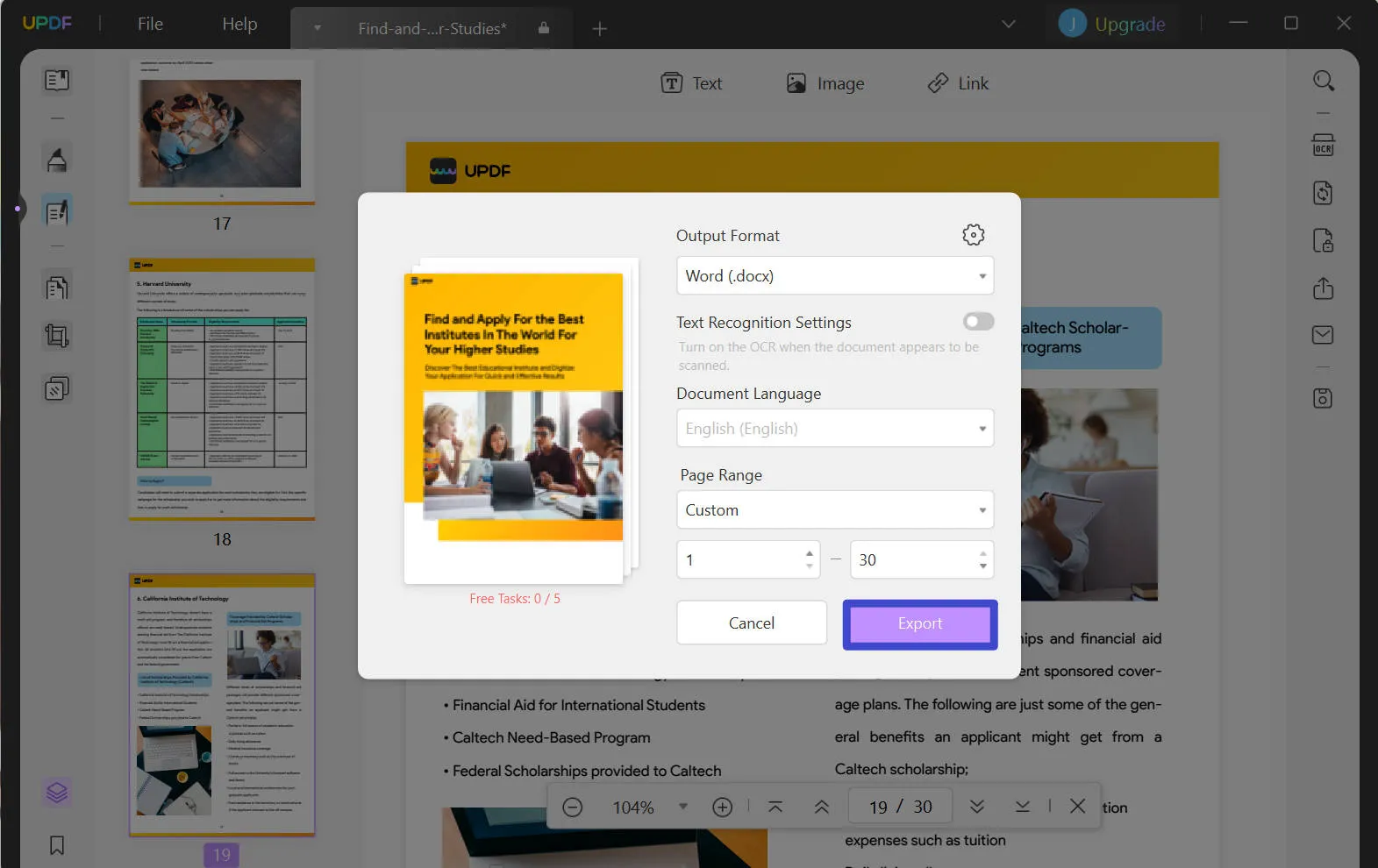
Krok 2. Konwertuj PDF do Excela/Worda/dowolnego formatu
Po wybraniu formatu możesz ustawić zakres stron, jeśli jest to potrzebne w nowym oknie. Gdy wszystko jest gotowe, kliknij przycisk „ Eksportuj ” i wybierz lokalizację, w której chcesz zapisać przekonwertowane pliki.
Po zakończeniu procesu, pomyślnie wyodrębnisz cały tekst ze zeskanowanego pliku PDF do Excela, Worda lub dowolnego formatu, którego potrzebujesz. Możesz otworzyć edytowalny plik na swoim komputerze i wykonać dowolne operacje.
Przeczytaj także : Jak łatwo wyodrębnić wiadomości e-mail z pliku PDF (2 skuteczne metody)
Sposób 3. Jak wyodrębnić wsadowo tekst z pliku PDF
Wyodrębnienie tekstu z pojedynczego pliku można wykonać w kilku krokach za pomocą UPDF. Ale jak wyodrębnić tekst z wielu plików PDF? Nie martw się, tutaj również się tym zajmiemy.
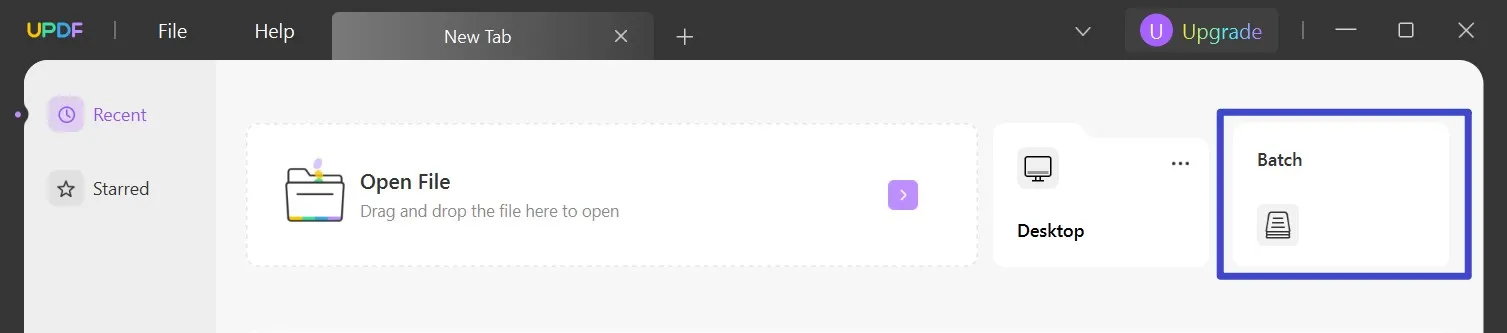
Krok 1. Uruchom UPDF
Kliknij dwukrotnie ikonę UPDF na pulpicie, aby ją uruchomić. Możesz znaleźć kilka opcji na ekranie głównym. Przejdź do kliknięcia ikony „ Batch ”.
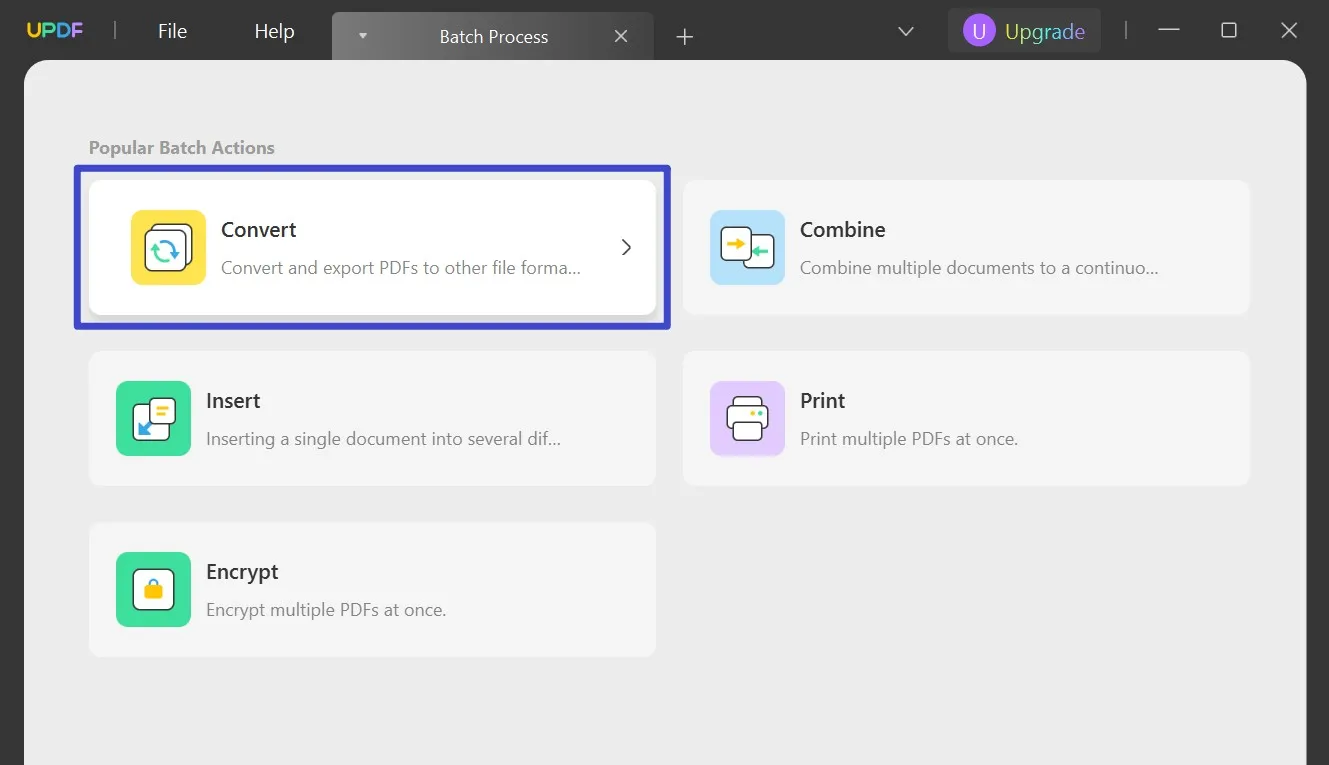
A potem znajdziesz kilka opcji. Wybierz opcję „ Konwertuj ”.
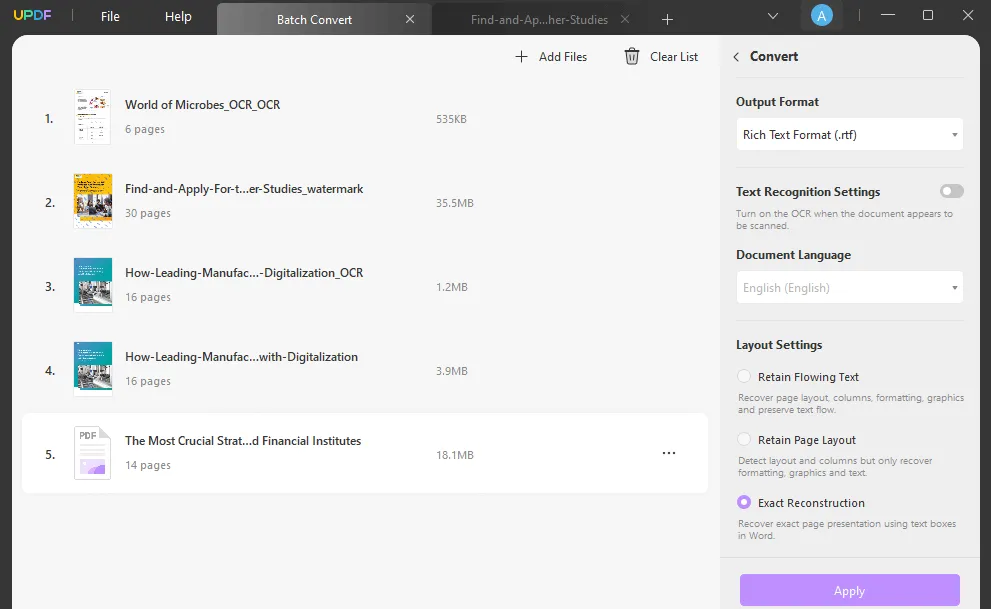
Krok 2. Wyodrębnianie wsadowe tekstu z wielu plików PDF
W nowym oknie wybierz format wyjściowy, zmień inne ustawienia, kliknij „ Zastosuj ”, wybierz lokalizację do zapisania i kliknij „Zapisz”, aby wykonać proces. Po wykonaniu tej czynności możesz znaleźć edytowalne pliki w wyskakującej lokalizacji.
Sposób 4. Jak wyodrębnić tekst z pliku PDF bez OCR?
OCR to świetny sposób na wyodrębnienie tekstu z plików PDF. Jednak możesz mieć zwykły plik PDF i chcieć wyodrębnić tekst lub po prostu nie chcieć korzystać z funkcji OCR. Bez względu na powody, szukasz sposobu na wyodrębnienie tekstu z pliku PDF bez OCR. Znamy Twoje scenariusze i oto trzy skuteczne sposoby dla Ciebie.
Jeśli używasz normalnego pliku PDF zamiast tych utworzonych przez skanery lub obrazy, możesz użyć funkcji edycji UPDF, aby wyodrębnić tekst z pliku PDF. Oto jak to zrobić.
Krok 1: Przejdź do trybu edycji
Pierwszy krok polega na otwarciu pliku PDF w UPDF, z którego chcesz wyodrębnić tekst. Aby to zrobić, kliknij przycisk „Otwórz plik” w centrum interfejsu UPDF.
Po zaimportowaniu pliku PDF do UPDF przejdź do paska narzędzi i kliknij kartę „ Edytuj PDF ”, aby zastosować tryb edycji do pliku.
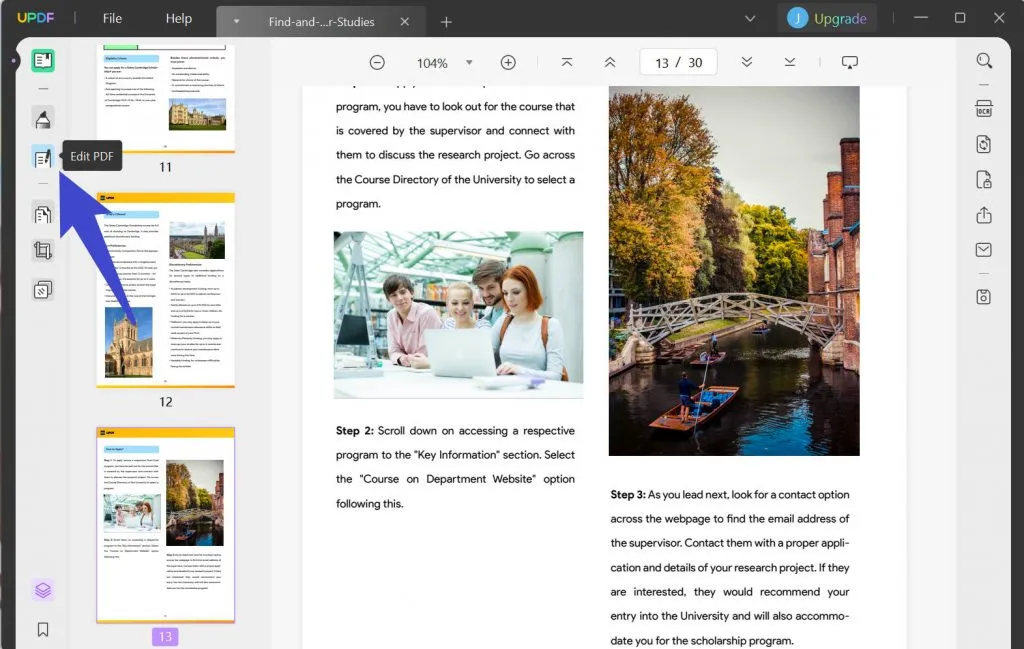
Krok 2: Wyodrębnij słowa z pliku PDF
Wybierz tekst, który chcesz wyodrębnić z pliku PDF, klikając go prawym przyciskiem myszy i klikając opcję „ Kopiuj ” lub używając skrótu „Ctrl + C”. Po skopiowaniu tekstu możesz wkleić wyodrębniony tekst do pliku Word lub innych formatów plików.
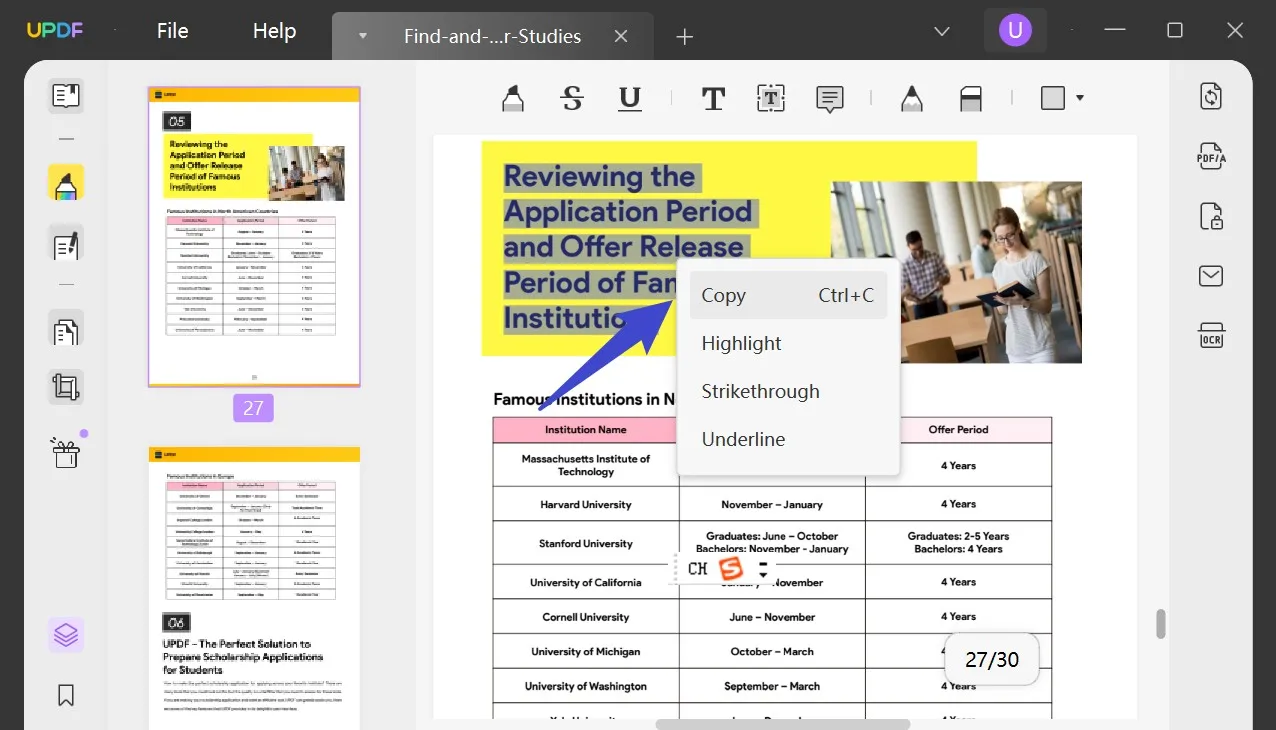
Ponadto UPDF jest dostępny na urządzeniach Mac, Windows, iOS i Android i obsługuje jedną licencję dla wszystkich platform, co czyni go idealnym rozwiązaniem dla użytkowników w różnych systemach operacyjnych. Oprócz wyodrębniania tekstu z PDF, UPDF ma również wiele innych funkcji. Oto niektóre z jego kluczowych funkcji:
Główne cechy przyjaznego użytkownikowi edytora PDF UPDF :
UPDF oferuje swoim użytkownikom różne kluczowe funkcje, dzięki czemu jest centrum rozwiązań dla codziennych edytorów PDF. Niektóre z tych funkcji są wymienione poniżej:
- Konwertuj PDF na obraz, Word, Excel, PPT i dowolny format, którego potrzebujesz : UPDF obsługuje funkcję konwersji PDF na dowolny format pliku. Jeśli musisz wyodrębnić tekst z PDF bezpośrednio do Word, Excel lub innych formatów, możesz to zrobić bez problemu, używając go.
- Edytuj teksty PDF, dodawaj obrazy, teksty i linki do plików PDF : UPDF umożliwia edycję tekstów PDF, zmianę czcionek, kolorów i rozmiarów, zmianę rozmiaru obrazu oraz dodawanie tekstów, obrazów i linków do plików PDF.
- Adnotacje do plików PDF: dodawaj notatki samoprzylepne, komentarze tekstowe, wyróżnienia, przekreślenia, podkreślenia, kształty, naklejki i inne funkcje komentowania do swoich plików PDF.
- Zarządzanie i organizowanie plików PDF : UPDF obsługuje wstawianie, usuwanie, wyodrębnianie, dzielenie stron i obracanie stron.
- Dodaj hasło otwierania i uprawnień : UPDF umożliwia użytkownikom dodawanie hasła do plików PDF w celu zapewnienia dodatkowej warstwy bezpieczeństwa ważnym dokumentom i formularzom PDF.
- Odtwórz plik PDF w formie pokazu slajdów .
Po zapoznaniu się ze wszystkimi niesamowitymi funkcjami UPDF, możesz się zastanawiać, gdzie możesz pobrać to potężne oprogramowanie. Kliknij przycisk „Darmowe pobieranie” poniżej i zainstaluj je teraz!
Windows • macOS • iOS • Android 100% bezpieczne
Aby dowiedzieć się więcej na temat rozpoznawania znaków (OCR) w plikach PDF, obejrzyj poniższy film instruktażowy.
Sposób 5. Jak wyodrębnić tekst z pliku PDF online za pomocą Dysku Google
Jeśli chcesz wyodrębnić tekst z pliku PDF, możesz też wypróbować Dysk Google, o ile nie przeszkadza ci uszkodzenie formatowania.
Użytkownicy mogą łatwo wyodrębnić tekst i inne elementy z pliku PDF bez pobierania lub instalowania oprogramowania. Jest to łatwa, wygodna i niezawodna metoda w porównaniu z innymi metodami wyodrębniania tekstu z plików PDF. Poniżej opisano kroki wyodrębniania informacji z pliku PDF online za pomocą metody Google Drive:
Krok 1: Uzyskaj dostęp do Google Drive w przeglądarce internetowej i kliknij kartę „Nowy”. Następnie kliknij „Prześlij plik” z menu rozwijanego, aby przejrzeć plik PDF ze swojego komputera i przesłać go na Google Drive.
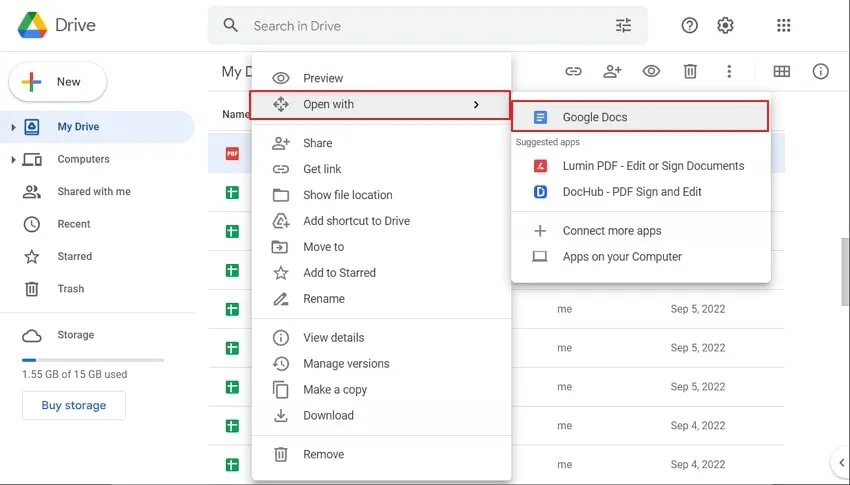
Krok 2: Gdy tylko plik PDF zostanie przesłany, zostanie on wyświetlony na Twoim dysku My Drive. Kliknij prawym przyciskiem myszy przesłany plik PDF, stuknij „Otwórz za pomocą”, a następnie wybierz „Dokumenty Google”, aby otworzyć plik PDF w Dokumentach Google.
Krok 3: Po otwarciu pliku PDF w Dokumentach Google tekst w pliku PDF automatycznie stanie się edytowalny, a Ty będziesz mógł łatwo wyodrębnić tekst z pliku PDF online i to bezpłatnie.
Sposób 6. Jak wyodrębnić tekst z pliku PDF za pomocą Pythona
Kto by pomyślał, że Python może być również źródłem do wyodrębniania tekstu z pliku PDF? Jeśli jesteś na swoim komputerze i często używasz Pythona, możesz skorzystać z pakietu PyPDF2 do wykonania tego zadania. Musisz postępować zgodnie ze skryptem podanym poniżej, aby dowiedzieć się więcej o tej metodzie:
z importu PyPDF2 PdfReader
czytelnik = PdfReader("przyklad.pdf")
strona = czytelnik.pagers[0]
tekst = strona.extract_text()
Często zadawane pytania dotyczące wyodrębniania tekstu z pliku PDF
1. Czy można wyodrębnić tekst z obrazu PDF?
Tak, możesz wyodrębnić tekst z obrazów PDF za pomocą funkcji OCR oferowanej przez UPDF. Zaimportuj obraz PDF do UPDF i kliknij ikonę „Rozpoznaj tekst za pomocą OCR” w prawym panelu okna UPDF. Po kliknięciu „Rozpoznaj tekst za pomocą OCR” wybierz opcję „Wykonaj OCR”, aby rozpocząć proces konwersji obrazu PDF do edytowalnego i przeszukiwalnego pliku PDF. Możesz wyodrębnić tekst z plików PDF OCR zaraz po zakończeniu konwersji.
2. Jak mogę wyodrębnić tekst z pliku PDF bez programu Acrobat?
Możesz wyodrębnić tekst z pliku PDF za pomocą UPDF zamiast Adobe Acrobat, ponieważ jest to bardziej opłacalne, szybsze i intuicyjne rozwiązanie. Działa na komputerach Mac, Windows, Android i iOS.
3. Czy mogę wyodrębnić tekst z pliku PDF w systemie Linux?
Tak, możesz wyodrębnić zawartość pliku PDF w systemie Linux, korzystając z różnych narzędzi online dostępnych na rynku, takich jak metoda Google Drive lub funkcja OCR narzędzia PDF24 w systemie operacyjnym Linux.
Wniosek
Podczas gdy na rynku dostępnych jest wiele opcji wyodrębniania tekstu z PDF z OCR i bez, najrozsądniejszym i najbardziej niezawodnym wyborem jest użycie dedykowanego i znanego narzędzia do plików PDF. W tym względzie UPDF jest najlepszym wyborem, ponieważ oprócz wydajnego i dokładnego wykonywania zadania, obsługuje on również zabezpieczanie danych, edycję PDF, konwersję PDF i wiele więcej. Teraz ma ekskluzywną ofertę i możesz uaktualnić do UPDF Pro już teraz. Możesz również pobrać UPDF już dziś na swój komputer z systemem Windows lub MacBook i skorzystać z satysfakcjonującego doświadczenia użytkownika.
Windows • macOS • iOS • Android 100% bezpieczne