 UPDF na Windows
UPDF na Windows UPDF na Mac
UPDF na Mac UPDF na iPhone/iPad
UPDF na iPhone/iPad UPDF na Android
UPDF na Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft Edytuj PDF
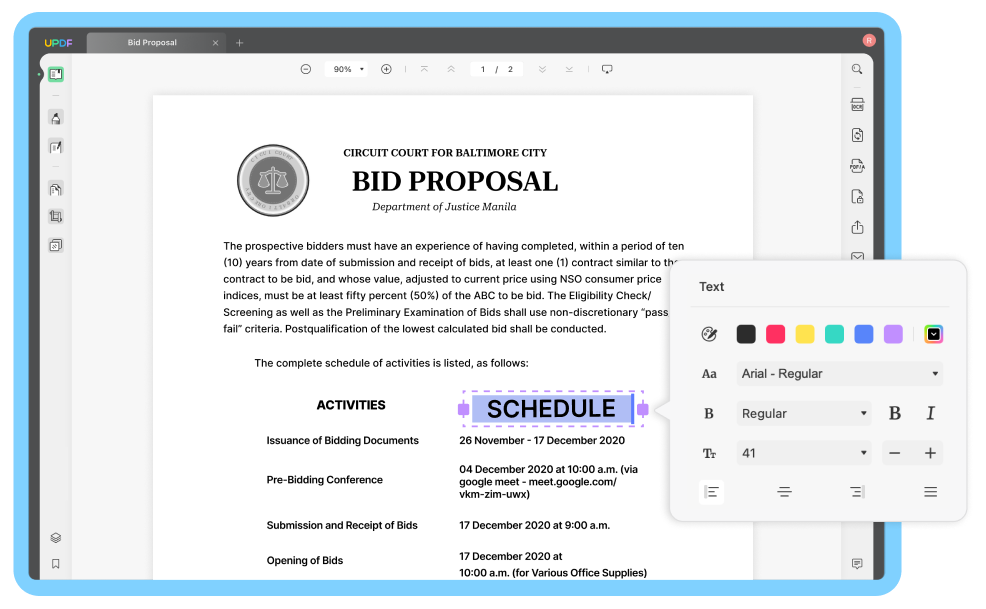
Edytuj PDF Zaznacz PDF
Zaznacz PDF Utwórz PDF
Utwórz PDF Formularz PDF
Formularz PDF Edytuj linki
Edytuj linki Przekonwertuj PDF
Przekonwertuj PDF OCR
OCR PDF do Word
PDF do Word PDF do obrazu
PDF do obrazu PDF do Excel
PDF do Excel Zarządzaj PDF
Zarządzaj PDF Scalać PDF
Scalać PDF Podziel PDF
Podziel PDF Przytnij PDF
Przytnij PDF Obróć PDF
Obróć PDF Zabezpiecz PDF
Zabezpiecz PDF Podpisz PDF
Podpisz PDF Redaguj PDF
Redaguj PDF Oczyść PDF
Oczyść PDF Usuń ochronę
Usuń ochronę Otwórz PDF
Otwórz PDF UPDF Chmura
UPDF Chmura Skompresuj PDF
Skompresuj PDF Drukuj PDF
Drukuj PDF Przetwarzanie wsadowe
Przetwarzanie wsadowe O UPDF AI
O UPDF AI Rozwiązania UPDF AI
Rozwiązania UPDF AI Podręcznik użytkownika AI
Podręcznik użytkownika AI FAQ dotyczące UPDF AI
FAQ dotyczące UPDF AI Podsumuj PDF
Podsumuj PDF Przetłumacz PDF
Przetłumacz PDF Porozmawiaj z PDF-em
Porozmawiaj z PDF-em Porozmawiaj z AI
Porozmawiaj z AI Porozmawiaj z obrazem
Porozmawiaj z obrazem PDF do mapy myśli
PDF do mapy myśli Wyjaśnij PDF
Wyjaśnij PDF Narzędzia PDF AI
Narzędzia PDF AI Narzędzia obrazu AI
Narzędzia obrazu AI Czat AI
Czat AI Pisanie AI
Pisanie AI Nauka z AI
Nauka z AI Praca z AI
Praca z AI Inne narzędzia AI
Inne narzędzia AI Generowanie Zakładek AI
Generowanie Zakładek AI Podsumowanie Zakładek AI
Podsumowanie Zakładek AI Generowanie Znaku Wodnego AI
Generowanie Znaku Wodnego AI Generowanie Tła AI
Generowanie Tła AI Generowanie Naklejek AI
Generowanie Naklejek AI Generowanie Pieczęci AI
Generowanie Pieczęci AI Pakiet do Pisania AI
Pakiet do Pisania AI UPDF Copilot
UPDF Copilot Zarządzanie Stronami AI
Zarządzanie Stronami AI Semantyczne Wyszukiwanie AI
Semantyczne Wyszukiwanie AI PDF to Word
PDF to Word PDF to Excel
PDF to Excel PDF do PowerPoint
PDF do PowerPoint Przewodnik użytkownika
Przewodnik użytkownika Sztuczki UPDF
Sztuczki UPDF FAQs
FAQs Recenzje UPDF
Recenzje UPDF Centrum pobierania
Centrum pobierania Blog
Blog Sala prasowa
Sala prasowa Specyfikacja techniczna
Specyfikacja techniczna Aktualizacje
Aktualizacje UPDF a Adobe Acrobat
UPDF a Adobe Acrobat UPDF a Foxit
UPDF a Foxit UPDF a PDF Expert
UPDF a PDF Expert
Nie wiesz, jak wyszukiwać w zeskanowanym pliku PDF , który mówi: „Ta strona zawiera tylko obrazy”? Albo próbowałeś wyszukiwać słowa za pomocą funkcji Znajdź systemu Windows lub CTRL + F, ale nic nie działało? Musiałeś wyszukiwać w zeskanowanym pliku PDF. Jeśli zastanawiasz się, jak wyszukiwać w zeskanowanych dokumentach PDF, mamy dla Ciebie rozwiązanie! Zanurz się, aby dowiedzieć się, jak to zrobić.
Jak wyszukiwać słowa w zeskanowanym pliku PDF?
Rzecz w tym, że zeskanowane dokumenty nie mają w sobie żadnego tekstu! Ponieważ jest to tylko zdjęcie dokumentu, nie ma żadnego tekstu, który Windows mógłby zindeksować.
Aby uczynić Twój plik PDF przeszukiwalnym, musisz uruchomić rozpoznawanie tekstu, aby uczynić treść na stronie przeszukiwalną i edytowalną. Możesz użyć dowolnego oprogramowania z funkcją OCR (Optical Character Recognition). Przechodzi ono przez zeskanowany dokument, identyfikuje wszystko, co przypomina literę lub słowo, i zamienia to na rzeczywisty tekst.
Wiele edytorów PDF oferuje tę możliwość, ale my polecamy UPDF - Twoje kompleksowe rozwiązanie PDF! To funkcja OCR oparta na sztucznej inteligencji, która konwertuje zeskanowane pliki PDF, dokumenty papierowe i obrazy na przeszukiwalne i edytowalne pliki PDF z trzema układami wyjściowymi, aby uczynić je interaktywnymi i spełnić wszystkie Twoje potrzeby. Dowiedz się więcej o funkcji OCR UPDF, czytając ten artykuł. Najpierw pobierz UPDF, zanim zaczniemy przedstawiać instrukcje.
Windows • macOS • iOS • Android 100% bezpieczne

Oto kilka imponujących funkcji tego oprogramowania OCR :
- Dokładność do 99%: zaawansowana technologia OCR UPDF zapewnia wyniki o wysokiej dokładności!
- Najwyższa prędkość OCR: Kto nie chce oszczędzać czasu? UPDF to rozumie, dlatego jego konwersja jest super szybka w porównaniu z konkurencją.
- Mały rozmiar wydruku i wysoka jakość: Rozmiar przekonwertowanego dokumentu PDF jest znacznie mniejszy niż oryginału!
- Obsługuje 38 języków: Obsługuje także dokumenty dwujęzyczne i umożliwia wybór wielu zestawów językowych.
Oprócz tego wszystkiego, czyta, organizuje i adnotuje Twój plik PDF i może konwertować zeskanowane pliki PDF o dowolnym rozmiarze! Więc na co czekasz? Wykonaj poniższe proste kroki, aby dowiedzieć się, jak wyszukiwać słowa w zeskanowanych plikach PDF i rozwiązać swój problem już teraz! Wystarczy kilka prostych kroków, a szybko skończysz!
Krok 1: Otwórz plik PDF i uzyskaj dostęp do ikony OCR
Kliknij „ Otwórz plik ”, aby zaimportować plik PDF. Możesz również użyć skrótu Ctrl + lub Cmd + O.
Kliknij opcję „ Rozpoznaj tekst za pomocą OCR ” na pasku narzędzi po prawej stronie. (Jeśli używasz tej funkcji po raz pierwszy, zostaniesz poproszony o pobranie wtyczki. Pobierz ją w następnym oknie i poczekaj na jej zainstalowanie.)
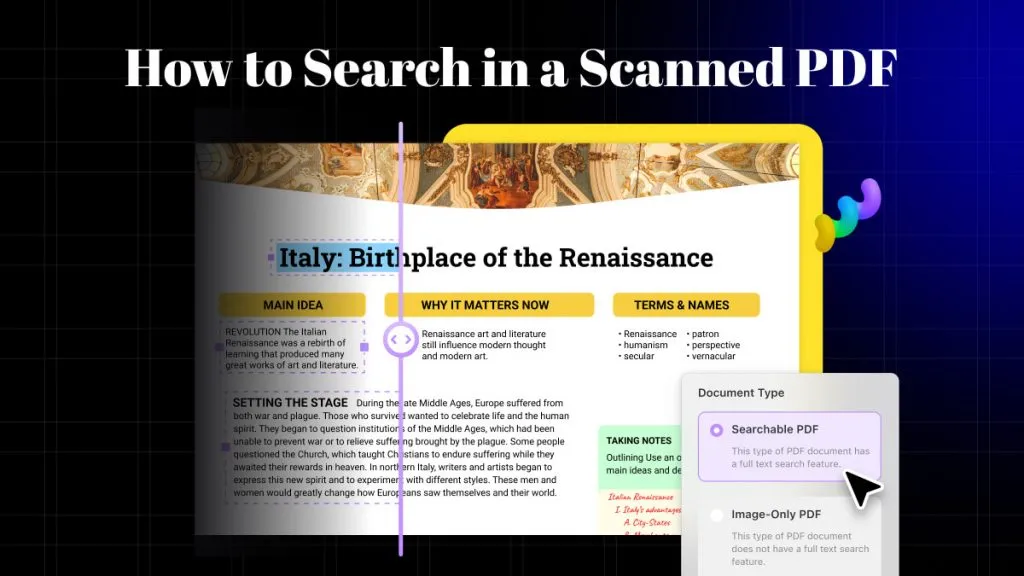
Krok 2: Przekształć zeskanowany plik PDF w plik z możliwością wyszukiwania
Po zainstalowaniu kliknij ponownie ten sam przycisk „Rozpoznaj tekst za pomocą OCR”. Otrzymasz dwie różne opcje typu dokumentu. Wybierz „ Przeszukiwalny PDF ”, ponieważ konwertuje on zeskanowane dokumenty na dokumenty edytowalne i przeszukiwalne.
Musisz wybrać układ z opcji „Tylko tekst i obrazy”, „Tekst na obrazie strony” i „Tekst pod obrazem strony”. Musisz również wybrać język dokumentu, rozdzielczość obrazu i zakres papieru.
Aby uzyskać dostęp do zaawansowanych opcji układu, kliknij ikonę koła zębatego, aby uzyskać dostęp do większej liczby ustawień układu, takich jak:
- Jeśli zaznaczysz opcję „Zachowaj zdjęcia”, będziesz musiał zdecydować o ich jakości („Niska”, „Zrównoważona” lub „Wysoka”)
- Kompresuj zdjęcia
- Zachowaj inne elementy dokumentu (nagłówki, stopki, numery stron, tekst i kolory tła)
Kliknij opcję „ Wykonaj OCR ”, następnie wybierz lokalizację, w której chcesz zapisać plik i kliknij „Zapisz”.

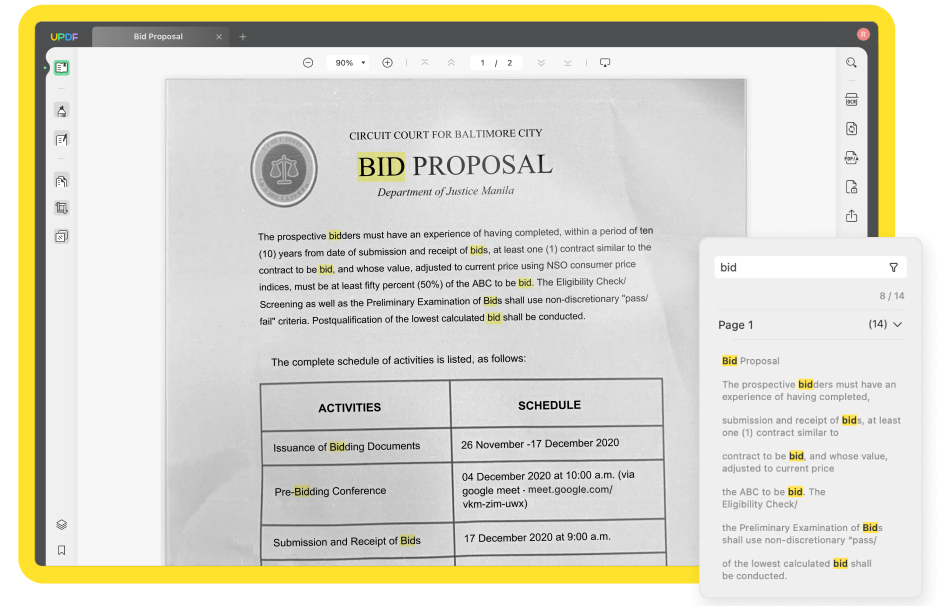
Krok 3: Wyszukaj słowa w zeskanowanym pliku PDF
Po wykonaniu OCR, wyszukiwalny plik PDF zostanie automatycznie otwarty w UPDF. Teraz możesz wyszukiwać w zeskanowanym pliku PDF żądane słowa, klikając Ctrl + F lub ikonę Szukaj w prawym górnym rogu.
Wpisz słowo, którego chcesz szukać, a zostaną wyświetlone wszystkie wyniki w tym dokumencie. Możesz kliknąć dowolny wynik, aby przejść bezpośrednio do strony. W ten sposób z łatwością znajdziesz słowa w PDF .

Aby dowiedzieć się więcej na temat rozpoznawania znaków (OCR) w plikach PDF, obejrzyj poniższy film instruktażowy.
Bonus
Wskazówka: Jaki układ wybrać do wykonania OCR?
W przypadku przeszukiwalnych plików PDF musisz wybrać odpowiedni układ w zależności od celu lub sytuacji, w której używasz układu. Korzystając z dostępnych opcji, możesz wybrać jedną z następujących opcji:
Tylko tekst i zdjęcia:
OCR rozpozna i zapisze tekst i obrazy w całym pliku PDF w mniejszym pliku. Nie będzie żadnej przezroczystej warstwy obrazu, aby zachować nienaruszone formatowanie. Tak więc wizualizacje przekonwertowanego pliku mogą różnić się od wersji oryginalnej.
Tekst nad obrazem strony:
Ten tryb zachowa ilustracje i obrazy tła w pliku źródłowym jako warstwę pod tekstem dokumentu. Zachowuje oryginalny format dokumentu. Chociaż te pliki są bardziej rozbudowane, wizualnie różnią się od oryginalnych.

Tekst pod obrazem strony:
Obrazy PDF są zachowywane, ale tekst jest umieszczony pod obrazami pod niewidoczną warstwą. Tak więc formatowanie dokumentu jest utrzymywane poprzez umieszczenie warstwy nad tekstem. Ten typ pliku jest identyczny z oryginalnym. Tekst można przeszukiwać, ale nie można go edytować.
Najczęściej zadawane pytania dotyczące wyszukiwania w zeskanowanym pliku PDF
Masz jednak pytania dotyczące wyszukiwania słów w zeskanowanym pliku PDF. Nie martw się. Mamy dla Ciebie rozwiązanie.
Dlaczego nie mogę wyszukać zeskanowanego pliku PDF?
Podczas skanowania dokumentu skaner przechwytuje strony jako płaski obraz, co oznacza, że nie ma tekstu, który system Windows może zindeksować lub który może odczytać jakakolwiek przeglądarka plików PDF. Musisz użyć funkcji OCR programu UPDF, aby przekonwertować zeskanowany dokument do formatu czytelnego, jak wyjaśniliśmy powyżej w tym artykule.
Czy mogę użyć klawisza Ctrl F w zeskanowanych dokumentach?
Nie. Ta funkcja wyszukiwania systemu Windows działa tylko w dokumentach zawierających czytelny tekst. Możesz użyć tej funkcji tylko po pobraniu oprogramowania obsługującego technologię OCR, takiego jak UPDF, które konwertuje skan do przeszukiwalnego pliku PDF.
Dlaczego nie mogę użyć Ctrl F w moim pliku PDF?
Funkcja Znajdź nie działa w przypadku dokumentów lub plików PDF zawierających wyłącznie obrazy, jak w przypadku zeskanowanych dokumentów. Obrazy te nie zawierają tekstu rozpoznawanego przez system Windows.
Wniosek
Więc nie wiesz, jak wyszukać słowo w zeskanowanym dokumencie PDF? Nie ma problemu - UPDF jest Twoim ostatecznym rozwiązaniem. Jego funkcja OCR jest łatwo dostępna i prosta w użyciu, a nawet może wykryć tekst w rozmazanym zeskanowanym dokumencie, z czym zmaga się nawet inne oprogramowanie! Możesz przekonwertować dowolny obraz na wykrywalny tekst dzięki zaawansowanemu algorytmowi kompresji obrazu opartemu na MRC lub zmienić plik PDF na dokument zawierający wyłącznie obrazy!
Na co czekasz? Pobierz UPDF już teraz, aby bez wysiłku wchodzić w interakcje z plikami PDF i mieć o wiele płynniejsze doświadczenie dzięki jego genialnym narzędziom AI. Możesz również dokonać uaktualnienia do wersji premium, aby odblokować wszystkie funkcje bez żadnych ograniczeń. To uzupełnia nasze wytyczne dotyczące wyszukiwania w zeskanowanym pliku PDF.
Windows • macOS • iOS • Android 100% bezpieczne






 Placyd Kowalski
Placyd Kowalski 


