 UPDF voor Windows
UPDF voor Windows UPDF voor Mac
UPDF voor Mac UPDF voor iPhone/iPad
UPDF voor iPhone/iPad UPDF voor Android
UPDF voor Android Nomostar
Nomostar UPDF AI Online
UPDF AI Online UPDF Sign
UPDF Sign IvyCraft
IvyCraft PDF bewerken
PDF bewerken PDF annoteren
PDF annoteren PDF maken
PDF maken PDF-formulier
PDF-formulier Links bewerken
Links bewerken PDF converteren
PDF converteren OCR
OCR PDF naar Word
PDF naar Word PDF naar afbeelding
PDF naar afbeelding PDF naar Excel
PDF naar Excel PDF organiseren
PDF organiseren PDF samenvoegen
PDF samenvoegen PDF splitsen
PDF splitsen PDF bijsnijden
PDF bijsnijden PDF roteren
PDF roteren PDF beveiligen
PDF beveiligen PDF ondertekenen
PDF ondertekenen PDF bewerken
PDF bewerken PDF opschonen
PDF opschonen Beveiliging verwijderen
Beveiliging verwijderen Lees PDF
Lees PDF UPDF Cloud
UPDF Cloud PDF comprimeren
PDF comprimeren PDF afdrukken
PDF afdrukken Batch Process
Batch Process Over UPDF AI
Over UPDF AI UPDF AI-oplossingen
UPDF AI-oplossingen AI Gebruikersgids
AI Gebruikersgids FAQ over UPDF AI
FAQ over UPDF AI PDF samenvatten
PDF samenvatten PDF vertalen
PDF vertalen Chatten met PDF
Chatten met PDF Chatten met afbeelding
Chatten met afbeelding PDF naar Mindmap
PDF naar Mindmap Chatten met AI
Chatten met AI PDF uitleggen
PDF uitleggen PDF AI-tools
PDF AI-tools Afbeeldings-AI-tools
Afbeeldings-AI-tools AI-chattools
AI-chattools AI-schrijftools
AI-schrijftools AI-studietools
AI-studietools AI-werktools
AI-werktools Overige AI-tools
Overige AI-tools AI Bladwijzer Generatie
AI Bladwijzer Generatie AI Bladwijzer Samenvatting
AI Bladwijzer Samenvatting AI Watermerk Generatie
AI Watermerk Generatie AI Achtergrond Generatie
AI Achtergrond Generatie AI Sticker Generatie
AI Sticker Generatie AI Stempel Generatie
AI Stempel Generatie AI Schrijfsuite
AI Schrijfsuite UPDF Copilot
UPDF Copilot AI Paginabeheer
AI Paginabeheer AI Semantisch Zoeken
AI Semantisch Zoeken PDF naar Word
PDF naar Word PDF naar Excel
PDF naar Excel PDF naar PowerPoint
PDF naar PowerPoint Gebruikershandleiding
Gebruikershandleiding UPDF-trucs
UPDF-trucs Veelgestelde Vragen
Veelgestelde Vragen UPDF Beoordelingen
UPDF Beoordelingen Downloadcentrum
Downloadcentrum Blog
Blog Nieuwsruimte
Nieuwsruimte Technische Specificaties
Technische Specificaties Updates
Updates UPDF versus Adobe Acrobat
UPDF versus Adobe Acrobat UPDF versus Foxit
UPDF versus Foxit UPDF versus PDF Expert
UPDF versus PDF Expert
Weet je niet hoe je moet zoeken in een gescande PDF met de tekst 'Deze pagina bevat alleen afbeeldingen'? Of heb je geprobeerd te zoeken naar woorden met de Windows-zoekfunctie of CTRL + F, maar niets werkte? Dan heb je waarschijnlijk gezocht in een gescande PDF. Als je je afvraagt hoe je in gescande PDF-documenten kunt zoeken, hebben wij de oplossing voor je! Duik erin en ontdek hoe.
Hoe zoek ik naar woorden in een gescande PDF?
Het probleem is dat gescande documenten geen tekst bevatten! Omdat het slechts een afbeelding van het document is, is er geen tekst die Windows kan indexeren.
Om uw PDF doorzoekbaar te maken, moet u tekstherkenning gebruiken om de inhoud op de pagina doorzoekbaar en bewerkbaar te maken. U kunt hiervoor OCR-software (Optical Character Recognition) gebruiken. Deze software doorzoekt het gescande document, herkent alles wat lijkt op een letter of woord en zet het om in daadwerkelijke tekst.
Verschillende PDF-editors bieden deze mogelijkheid, maar wij raden UPDF aan - uw alles-in-één PDF-oplossing! Het is een AI-aangedreven OCR-functie die uw gescande PDF's, papieren documenten en afbeeldingen omzet naar doorzoekbare en bewerkbare PDF's met drie uitvoerindelingen voor een interactieve interface die aan al uw behoeften voldoet. Lees dit artikel voor meer informatie over de OCR-functie van UPDF. Download UPDF eerst voordat we de instructies introduceren.
Windows • macOS • iOS • Android 100% veilig

Hier zijn enkele indrukwekkende kenmerken van deze OCR-software :
- Tot 99% nauwkeurigheid: de geavanceerde OCR-technologie van UPDF biedt zeer nauwkeurige resultaten!
- De hoogste OCR-snelheid: wie wil er nou geen tijd besparen? UPDF begrijpt dit; de conversie is dan ook supersnel vergeleken met de concurrentie.
- Kleine uitvoer met hoge kwaliteit: het geconverteerde PDF-document is veel kleiner dan het origineel!
- Ondersteunt 38 talen: Het ondersteunt ook tweetalige documenten en u kunt meerdere talen selecteren.
Daarnaast leest, organiseert en annoteert het ook je PDF en kan het gescande PDF's van elk formaat converteren! Dus waar wacht je nog op? Volg de onderstaande eenvoudige stappen om te zoeken naar woorden in gescande PDF's en je probleem is nu opgelost! Het kost slechts een paar eenvoudige stappen en je bent snel klaar!
Stap 1: Open PDF en krijg toegang tot het OCR-pictogram
Klik op ' Open bestand ' om de PDF te importeren. U kunt ook de sneltoets Ctrl + of Cmd + O gebruiken.
Klik op de optie ' Tekst herkennen met OCR ' in de rechterwerkbalk. (Als dit de eerste keer is dat u deze functie gebruikt, wordt u gevraagd een plug-in te downloaden. Download deze in het volgende venster en wacht tot deze is geïnstalleerd.)
Stap 2: Maak van de gescande PDF een doorzoekbaar bestand
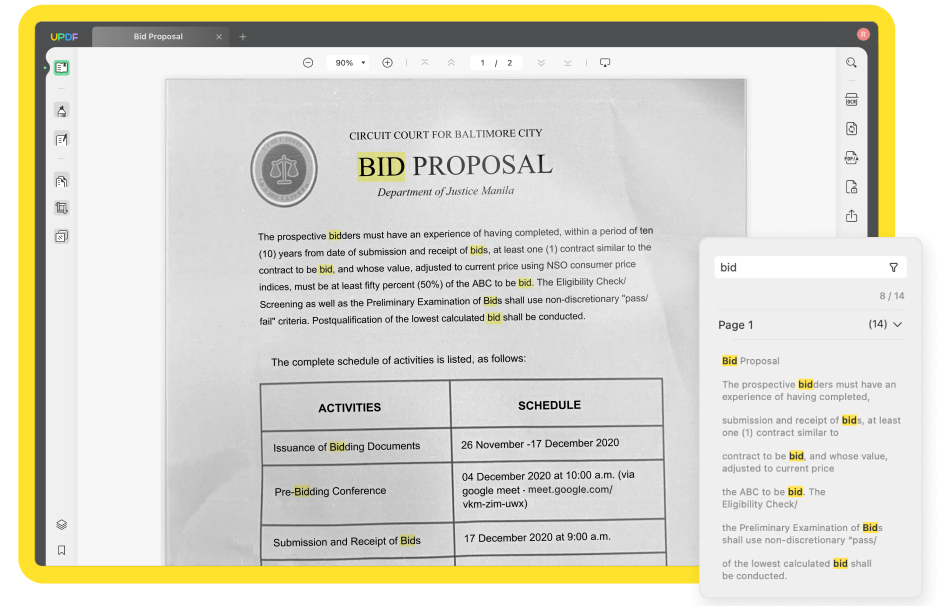
Na de installatie klikt u nogmaals op dezelfde knop "Tekst herkennen met OCR". U krijgt twee verschillende documenttypen. Kies " Doorzoekbare PDF ", omdat deze gescande documenten omzet in bewerkbare en doorzoekbare documenten.
U moet de lay-out kiezen uit de opties 'Alleen tekst en afbeeldingen', 'Tekst over de pagina-afbeelding' en 'Tekst onder de pagina-afbeelding'. U moet ook de documenttaal, de afbeeldingsresolutie en het papierbereik kiezen.
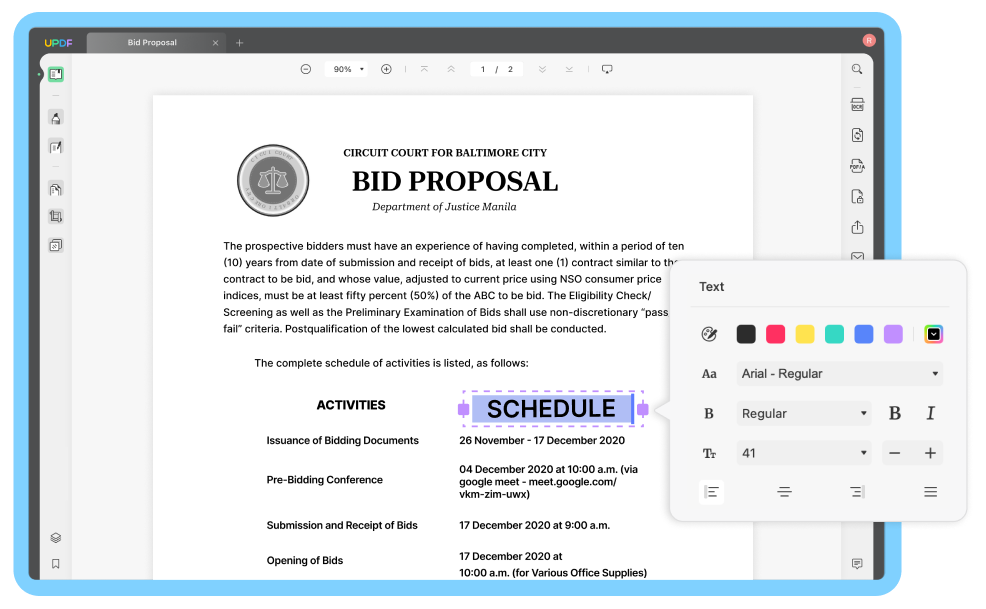
Voor geavanceerde lay-outopties klikt u op het tandwielpictogram om toegang te krijgen tot meer lay-outinstellingen, zoals:
- Als u 'Afbeeldingen behouden' aanvinkt, moet u de kwaliteit ervan bepalen ('Laag', 'Gebalanceerd' of 'Hoog')
- Afbeeldingen comprimeren
- Andere documentelementen behouden (kopteksten, voetteksten, paginanummers, tekst en achtergrondkleuren)
Klik op de optie ' OCR uitvoeren ', selecteer de locatie waar u het bestand wilt opslaan en klik op 'Opslaan'.

Stap 3: Zoek naar woorden in de gescande PDF
Na het uitvoeren van OCR wordt het doorzoekbare PDF-bestand automatisch geopend in UPDF. U kunt nu in de gescande PDF zoeken naar de gewenste woorden door te klikken op Ctrl+F of op het zoekpictogram in de rechterbovenhoek.
Voer het woord in waarnaar je wilt zoeken en alle resultaten in dit document worden weergegeven. Je kunt op een resultaat klikken om direct naar de pagina te gaan. Zo vind je gemakkelijk woorden in een PDF .
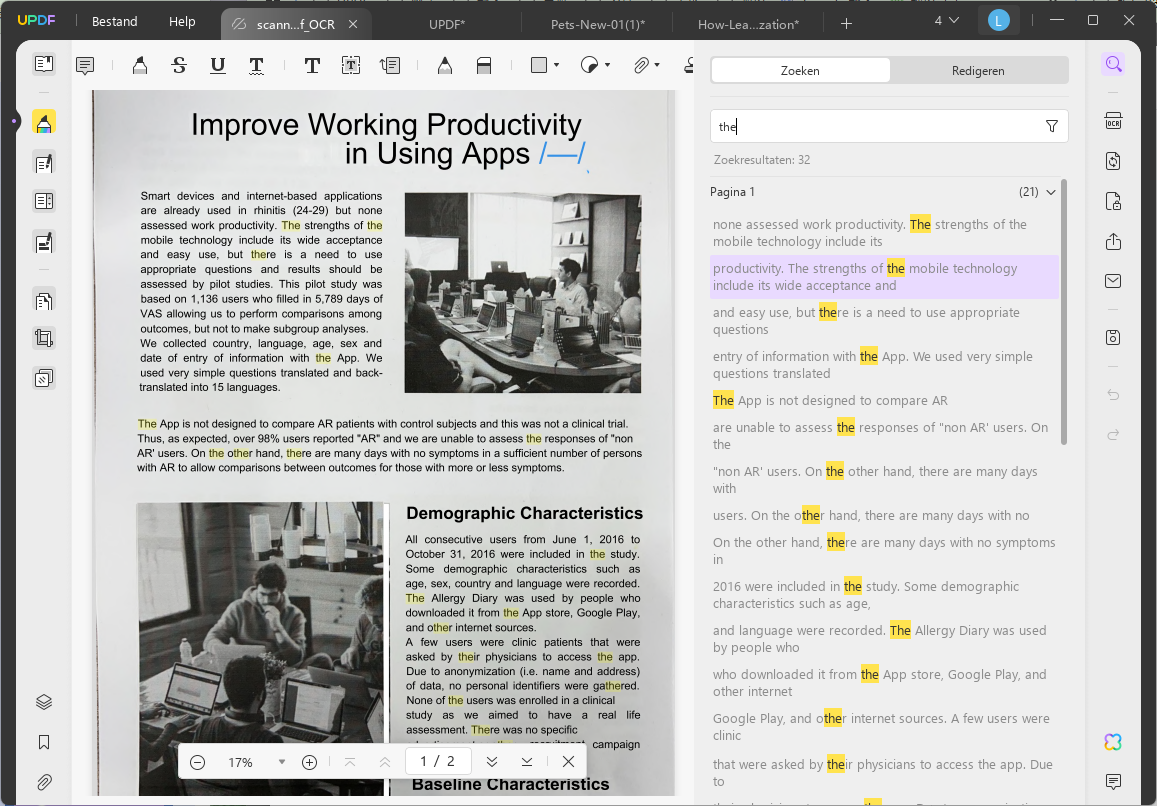
Bekijk onderstaande video voor meer informatie over het OCR-en van een PDF.
Bonus
Tip: Welke lay-out moet ik kiezen bij het uitvoeren van OCR?
Voor doorzoekbare pdf's moet u een geschikte lay-out kiezen, afhankelijk van het doel of de situatie waarvoor u de lay-out wilt gebruiken. Met de beschikbare opties kunt u kiezen uit de volgende opties:
Alleen tekst en afbeeldingen:
De OCR herkent en slaat de tekst en afbeeldingen in de PDF op in een kleiner bestand. Er is geen transparante afbeeldingslaag aanwezig om de opmaak intact te houden. De visuele weergave van het geconverteerde bestand kan dus afwijken van de originele versie.
Tekst boven de pagina-afbeelding:
In deze modus worden de illustraties en achtergrondafbeeldingen in het bronbestand als een laag onder de documenttekst bewaard. De oorspronkelijke opmaak van het document blijft behouden. Hoewel deze bestanden uitgebreider zijn, zien ze er visueel anders uit dan de originele bestanden.

Tekst onder de pagina-afbeelding:
De PDF-afbeeldingen blijven behouden, maar de tekst wordt onder de afbeeldingen geplaatst, onder een onzichtbare laag. De opmaak van het document blijft dus behouden door een laag boven de tekst te plaatsen. Dit bestandstype is identiek aan het origineel. De tekst kan worden doorzocht, maar niet worden bewerkt.
Veelgestelde vragen over het zoeken in een gescande pdf
Heb je nog vragen over het zoeken naar woorden in een gescande pdf? Geen zorgen. Wij helpen je verder.
Waarom kan ik niet zoeken naar een gescande pdf?
Wanneer je een document scant, legt je scanner de pagina's vast als een platte afbeelding. Dit betekent dat er geen tekst is die Windows kan indexeren of die een pdf-viewer kan lezen. U moet de OCR-functie van UPDF gebruiken om uw gescande document naar een leesbaar formaat te converteren, zoals we hierboven in dit artikel hebben uitgelegd.
Kan ik Ctrl-F gebruiken op gescande documenten?
Nee. Deze Windows-zoekfunctie werkt alleen op documenten met leesbare tekst. U kunt deze functie alleen gebruiken door software te downloaden die OCR-technologie ondersteunt, zoals UPDF, die de scan converteert naar een doorzoekbare PDF.
Waarom kan ik Ctrl-F niet gebruiken op mijn PDF?
De zoekfunctie werkt niet op documenten of PDF's met alleen afbeeldingen, zoals bij gescande documenten. Deze afbeeldingen bevatten geen tekst die Windows herkent.
Conclusie
Dus, weet u niet hoe u naar een woord moet zoeken in een gescand PDF-document? Geen probleem - UPDF is de ultieme oplossing. De OCR-functie is gemakkelijk toegankelijk en gebruiksvriendelijk, en het programma kan zelfs tekst detecteren in een wazig gescand document, iets waar zelfs andere software moeite mee heeft! U kunt elke afbeelding converteren naar detecteerbare tekst met het geavanceerde MRC-gebaseerde beeldcompressiealgoritme of de PDF omzetten naar een document met alleen afbeeldingen!
Waar wacht je nog op? Download UPDF nu, zodat je moeiteloos met je PDF's kunt werken en een veel soepelere ervaring hebt dankzij de briljante AI-tools. Je kunt ook upgraden naar de premiumversie om alle functies zonder beperkingen te ontgrendelen. Hiermee zijn onze richtlijnen voor het zoeken in een gescande PDF voltooid.
Windows • macOS • iOS • Android 100% veilig







 Nls Jansen
Nls Jansen 
