Windows용 UPDF
Windows용 UPDF Mac용 UPDF
Mac용 UPDF iPhone/iPad용 UPDF
iPhone/iPad용 UPDF 안드로이드용 UPDF
안드로이드용 UPDF UPDF AI 온라인
UPDF AI 온라인 UPDF Sign
UPDF Sign PDF 읽기
PDF 읽기 PDF 주석 달기
PDF 주석 달기 PDF 편집
PDF 편집 PDF 변환
PDF 변환 PDF 생성
PDF 생성 PDF 압축
PDF 압축 PDF 구성
PDF 구성 PDF 병합
PDF 병합 PDF 분할
PDF 분할 PDF 자르기
PDF 자르기 PDF 페이지 삭제
PDF 페이지 삭제 PDF 회전
PDF 회전 PDF 서명
PDF 서명 PDF 양식
PDF 양식 PDF 비교
PDF 비교 PDF 보안
PDF 보안 PDF 인쇄
PDF 인쇄 일괄 처리
일괄 처리 OCR
OCR UPDF 클라우드
UPDF 클라우드 UPDF AI 소개
UPDF AI 소개 UPDF AI 솔루션
UPDF AI 솔루션 AI 사용자 가이드
AI 사용자 가이드 UPDF AI에 대한 FAQ
UPDF AI에 대한 FAQ PDF 요약
PDF 요약 PDF 번역
PDF 번역 PDF 설명
PDF 설명 PDF로 채팅
PDF로 채팅 이미지로 채팅
이미지로 채팅 PDF를 마인드맵으로 변환
PDF를 마인드맵으로 변환 AI 채팅
AI 채팅 사용자 가이드
사용자 가이드 기술 사양
기술 사양 업데이트
업데이트 FAQ
FAQ UPDF 활용 팁
UPDF 활용 팁 블로그
블로그 뉴스룸
뉴스룸 UPDF 리뷰
UPDF 리뷰 다운로드 센터
다운로드 센터 회사에 연락하기
회사에 연락하기
PDF 형식은 기업에서 가장 많이 채택하는 형식이 되었습니다. 기업의 중요한 데이터는 대부분 PDF 파일에 저장되어 있기 때문에 PDF에서 텍스트를 추출해야 하는 경우가 많습니다.
그러나 올바른 방법과 도구가 없으면 PDF에서 텍스트를 복사, 추출 및 편집할 수 없으며, 특히 PDF 파일을 스캔하거나 이미지로 만들면 이 작업을 수행하기가 어려울 수 있습니다.
OCR을 사용하여 PDF에서 텍스트를 추출할 수 있다는 것을 알고 계신 분도 계실 것입니다. 하지만 OCR을 사용하고 싶지 않다면 어떻게 해야 할까요? 다른 방법이 있나요? 대답은 "예"입니다.
이 문서에서는 사용자의 편의를 위해 OCR 기능을 사용하거나 사용하지 않고 PDF 파일에서 텍스트를 추출하는 방법에 대한 솔루션을 제공합니다. 끝까지 읽어보세요.
방법1. OCR로 PDF에서 텍스트를 추출하는 방법은 무엇입니까?
PDF 파일이 스캐너나 이미지로 생성된 경우, PDF에서 텍스트를 추출하는 가장 일반적인 방법은 OCR 도구가 있는 PDF 편집기를 사용하는 것입니다. 여기에서는 UPDF를 사용하여 스캔 또는 이미지 기반 PDF에서 텍스트를 추출하는 방법을 보여드리겠습니다. 아래 버튼을 클릭하여 UPDF를 다운로드하여 직접 사용해 보세요.
Windows • macOS • iOS • Android 100% 안전

UPDF는 대규모 조직부터 소규모 개인까지 모든 사용자의 요구를 충족하는 완벽한 PDF 파일 솔루션을 제공하는 혁신적인 PDF 편집기입니다. PDF 파일 편집, 변환, 병합, 주석 달기 등 필요한 모든 기능을 제공합니다.
스캔한 PDF에서 텍스트를 추출하려면 UPDF를 사용할 수 있습니다. UPDF는 스캔한 PDF 문서를 편집 및 추출 가능한 텍스트로 변환하는 전용 OCR 기능을 제공합니다. 아래 안내에 따라 진행하세요.
1단계. UPDF 다운로드 및 설치
이제 UPDF를 다운로드하고 아래 가이드에 따라 스캔한 PDF에서 텍스트를 추출하는 방법을 알아보세요.
2단계: OCR 기능 액세스
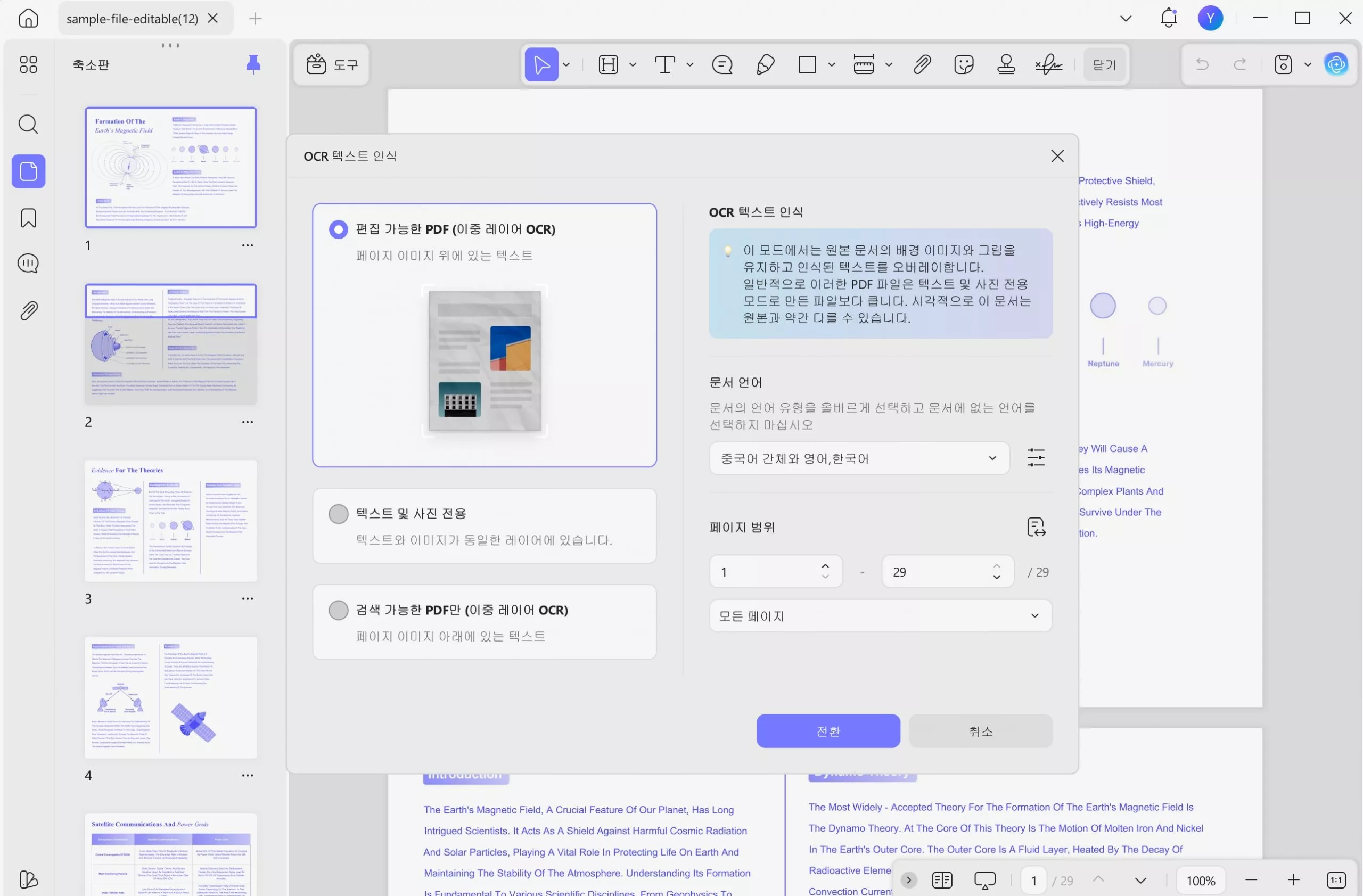
UPDF에서 PDF를 열고 " 도구 " > " OCR " 버튼을 눌러 시작할 수 있습니다.
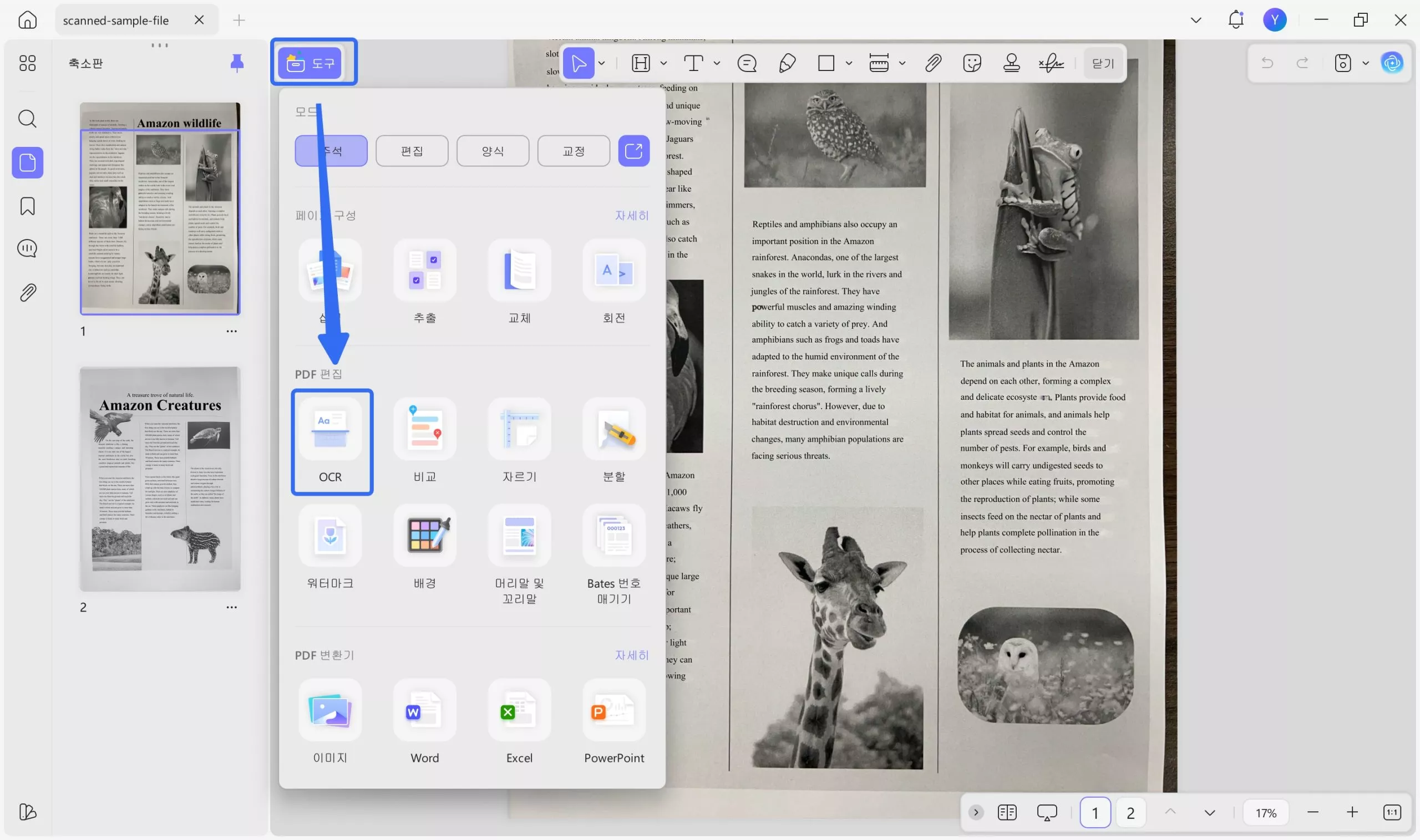
팝업 창에서 "편집 가능한 PDF"를 선택한 다음, 38개 언어 목록에서 문서 언어를 선택해야 합니다. 여기서는 "영어"를 선택했습니다. 필요한 경우 "레이아웃 설정"을 클릭하여 이미지 해상도, 이미지 유지, 페이지 번호, 머리말, 꼬리말 유지 여부 등을 설정할 수 있습니다. "전환" 버튼을 클릭하여 OCR 처리된 PDF를 저장할 위치를 선택하세요.
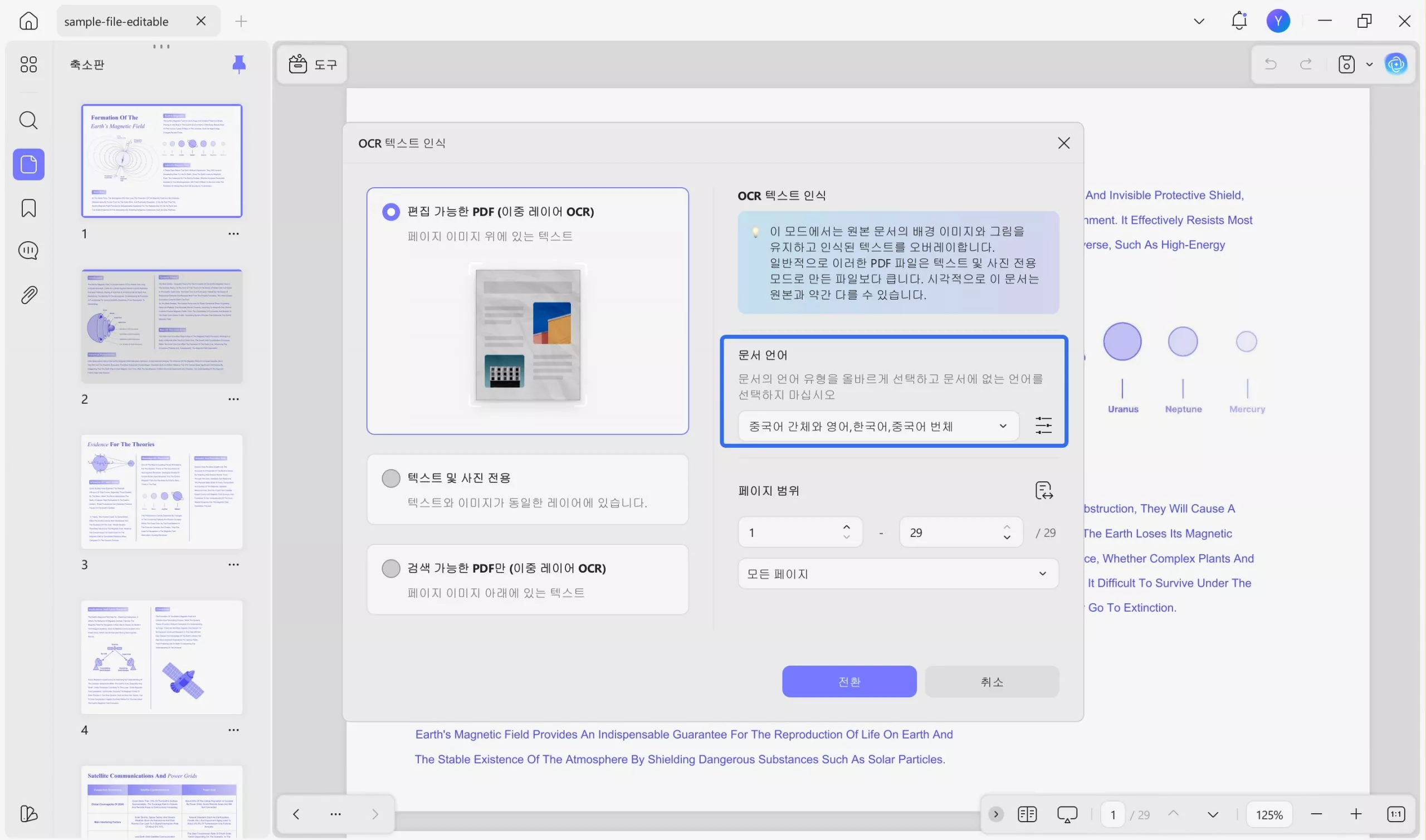
3단계. PDF에서 텍스트 추출 또는 복사
이제 원하는 텍스트를 클릭하고 선택하여 PDF로 추출한 다음 원하는 대상에 복사하여 붙여 넣을 수 있습니다.
또한 읽어보세요 : PDF에서 OCR을 제거하는 방법? (3가지 방법)
방법 2. 스캔한/이미지 PDF에서 엑셀/워드/모든 형식으로 모든 텍스트를 추출하는 방법
PDF에서 한 부분의 텍스트를 복사해야 하는 경우 위의 방법이 유용할 수 있습니다. 하지만 PDF의 모든 텍스트를 복사하여 붙여넣는 방식으로 추출해야 하는 경우 시간이 오래 걸릴 수 있습니다. 걱정하지 마세요. UPDF를 빠르게 사용할 수 있는 방법이 있습니다. 여기에서 사용 방법을 확인하세요. 아래 버튼을 클릭하여 UPDF를 다운로드하고 아래 가이드를 따르세요.
Windows • macOS • iOS • Android 100% 안전
1단계. "변환" 기능 찾기
OCR을 수행하면 편집 가능한 PDF가 UPDF에서 자동으로 열립니다. "도구"로 이동하여 "변환"을 선택하고 원하는 형식을 선택하세요. 예를 들어 "Word"를 선택하세요.
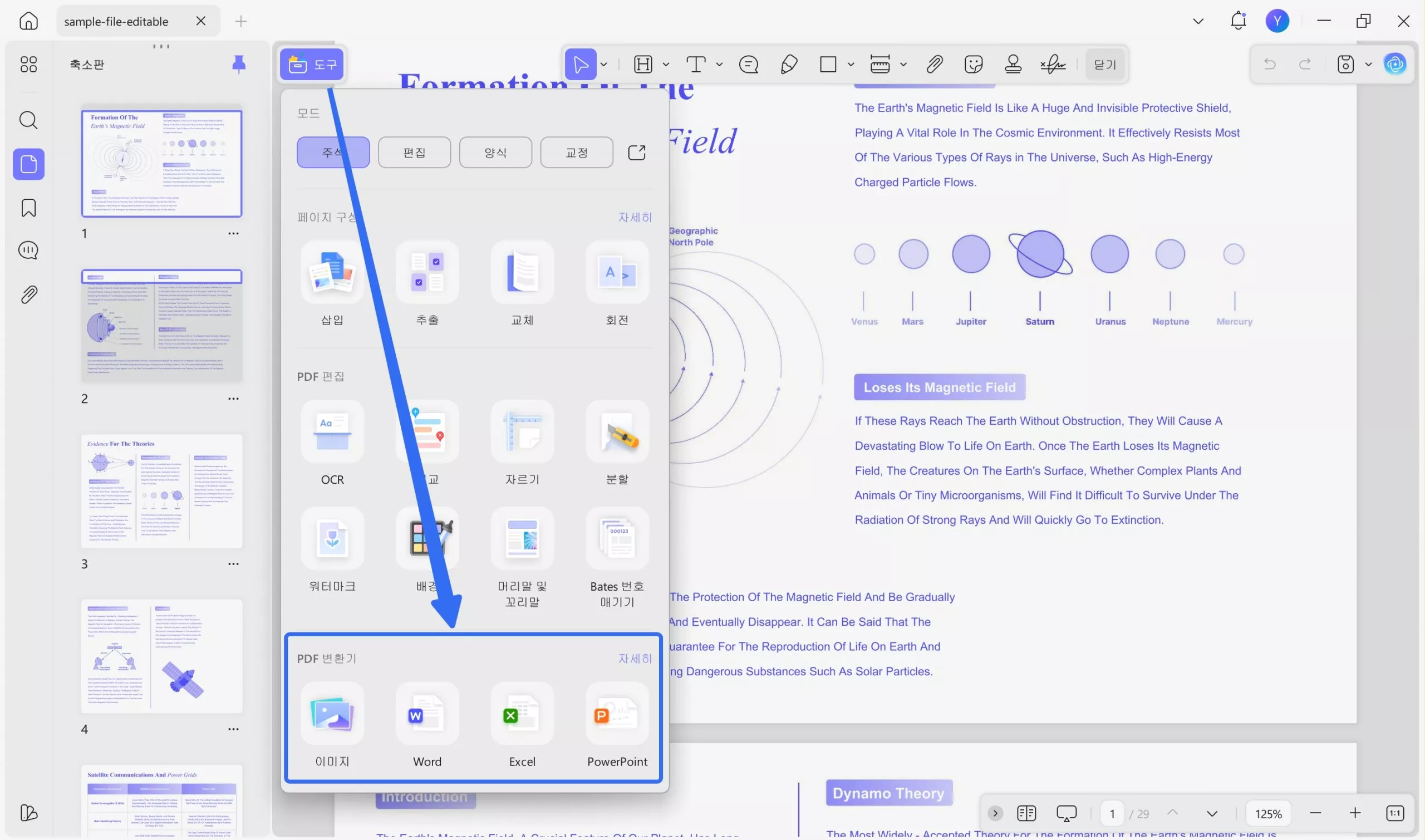
2단계. PDF를 Excel/Word/모든 형식으로 변환
형식을 선택한 후, 필요에 따라 새 창에서 페이지 범위를 설정할 수 있습니다. 모든 설정이 완료되면 "적용" 버튼을 클릭하고 변환된 파일을 저장할 위치를 선택하세요.
이 과정이 완료되면 스캔한 PDF의 모든 텍스트를 Excel, Word 또는 원하는 형식으로 추출할 수 있습니다. 컴퓨터에서 편집 가능한 파일을 열어 원하는 작업을 수행할 수 있습니다.
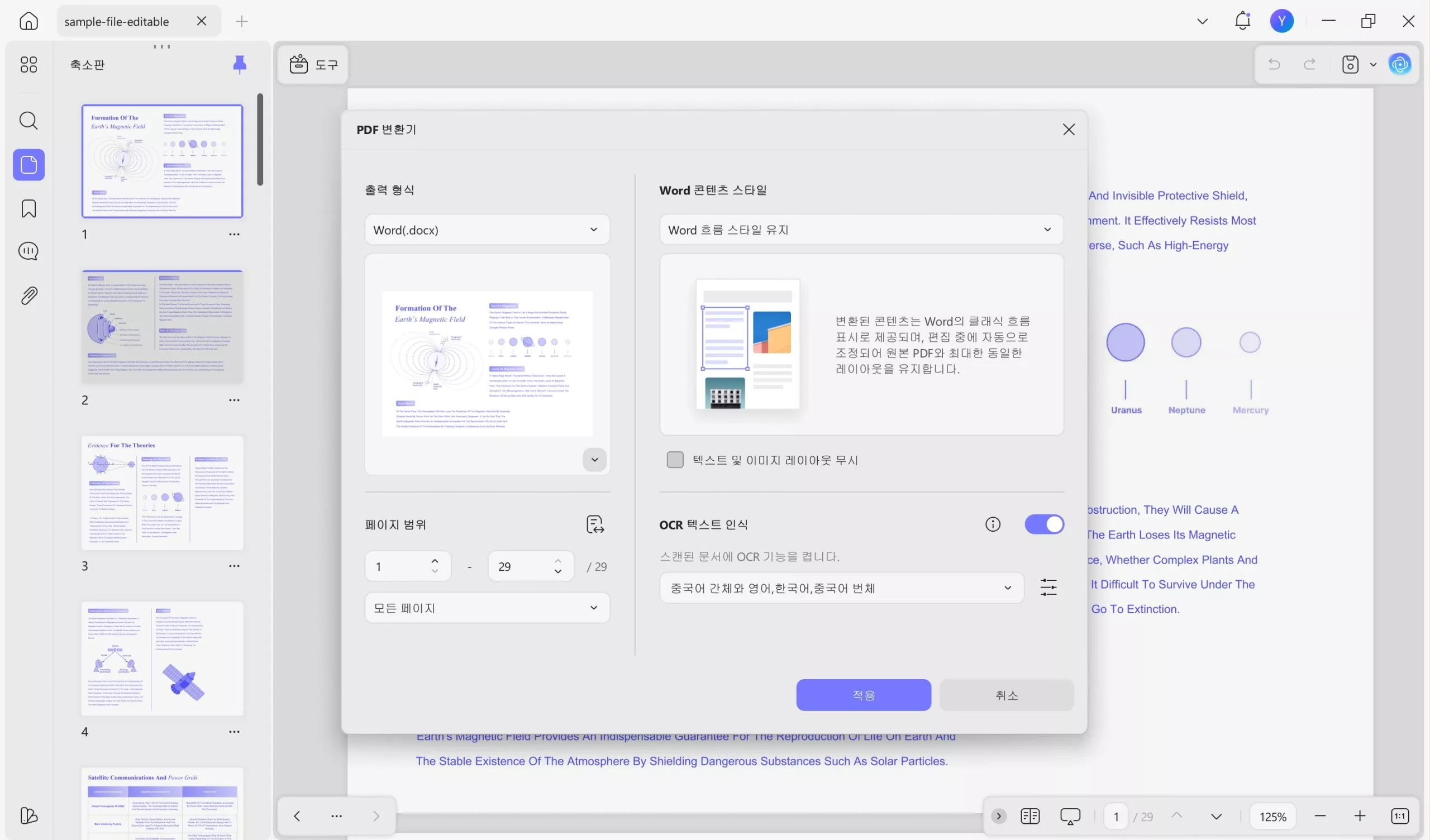
또는 변환 기능을 사용하여 OCR을 미리 수행하지 않고도 스캔한 PDF를 다른 형식으로 직접 변환할 수 있습니다. 자세한 내용은 여기를 참조하세요. UPDF로 스캔한 PDF를 열고 "도구" > "변환"을 클릭한 후, 형식과 페이지 범위를 선택하고 스타일을 설정한 후 OCR 텍스트 인식을 활성화하고 문서 언어를 선택한 후 "적용"을 클릭하면 스캔한 PDF가 편집 가능한 형식으로 변환됩니다. 변환 과정이 완료되면 변환된 PDF에서 모든 텍스트를 추출할 수 있습니다.
방법 3. 스캔 또는 이미지 PDF에서 텍스트를 일괄 추출하는 방법은 무엇입니까?
UPDF를 사용하면 단일 파일에서 텍스트를 추출하는 작업을 여러 단계로 수행할 수 있습니다. 그렇다면 여러 PDF 파일에서 텍스트를 추출하려면 어떻게 해야 할까요? 걱정하지 마세요. 여기에서도 도움을 받으실 수 있습니다.
1단계. UPDF 실행
바탕화면에서 UPDF 아이콘을 두 번 클릭하여 실행합니다. 홈 화면에서 "도구">"전환"을 찾을 수 있습니다.
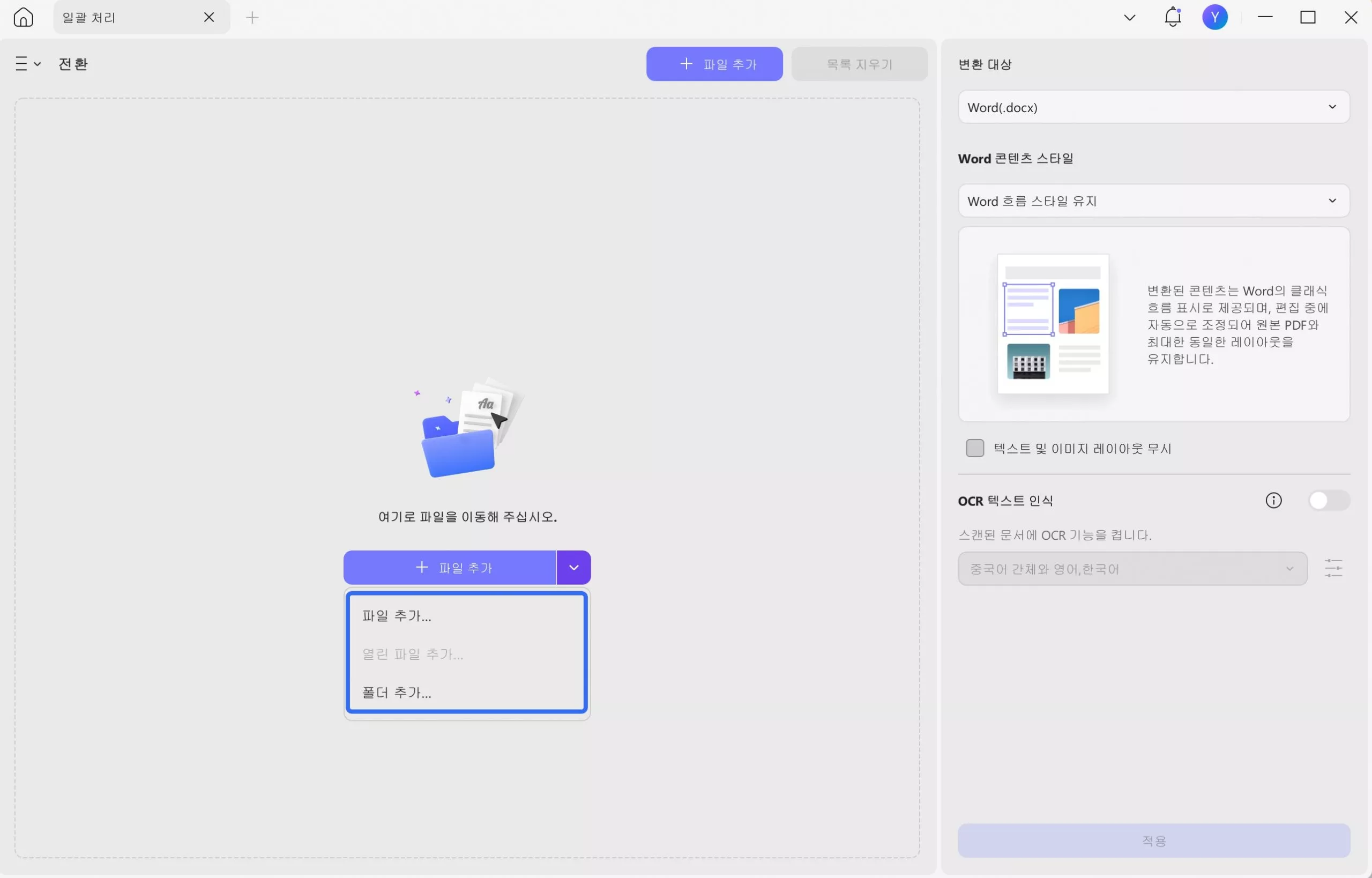
2단계. 여러 PDF 파일에서 텍스트 일괄 추출
새 창에서 출력 형식을 선택하고, "OCR 텍스트 인식"을 활성화하고, 다른 설정을 변경하고, "적용"을 클릭한 다음 저장할 위치를 선택하고, "저장"을 클릭하여 프로세스를 수행합니다. 완료되면 팝업 위치에서 편집 가능한 PDF 파일을 찾을 수 있습니다.
Windows • macOS • iOS • Android 100% 안전
방법 4. OCR 없이 PDF에서 텍스트를 추출하는 방법은 무엇입니까?
OCR은 PDF에서 텍스트를 추출하는 좋은 방법입니다. 하지만 일반 PDF 파일에서 텍스트를 추출하고 싶거나, OCR 기능을 사용하고 싶지 않을 수도 있습니다. 어떤 이유든 OCR 없이 PDF에서 텍스트를 추출하는 방법을 찾고 계실 겁니다. 저희는 여러분의 상황을 잘 알고 있으며, 여러분에게 효과적인 세 가지 방법을 소개합니다.
스캐너나 이미지로 만든 PDF 파일 대신 일반 PDF 파일을 사용하는 경우, UPDF의 복사 기능을 사용하여 PDF에서 텍스트를 추출할 수 있습니다. 방법은 다음과 같습니다.
방법 1. 스캔되지 않은 PDF에 대한 복사
첫 번째 단계는 UPDF에서 텍스트를 추출할 PDF 파일을 여는 것입니다.
UPDF 인터페이스에서 "파일 열기" 버튼을 클릭하세요.
PDF를 UPDF로 가져온 후 추출하려는 콘텐츠를 강조 표시하고 팝업 메뉴에서 "복사"를 클릭한 다음 콘텐츠를 저장하려는 위치에 붙여넣습니다.
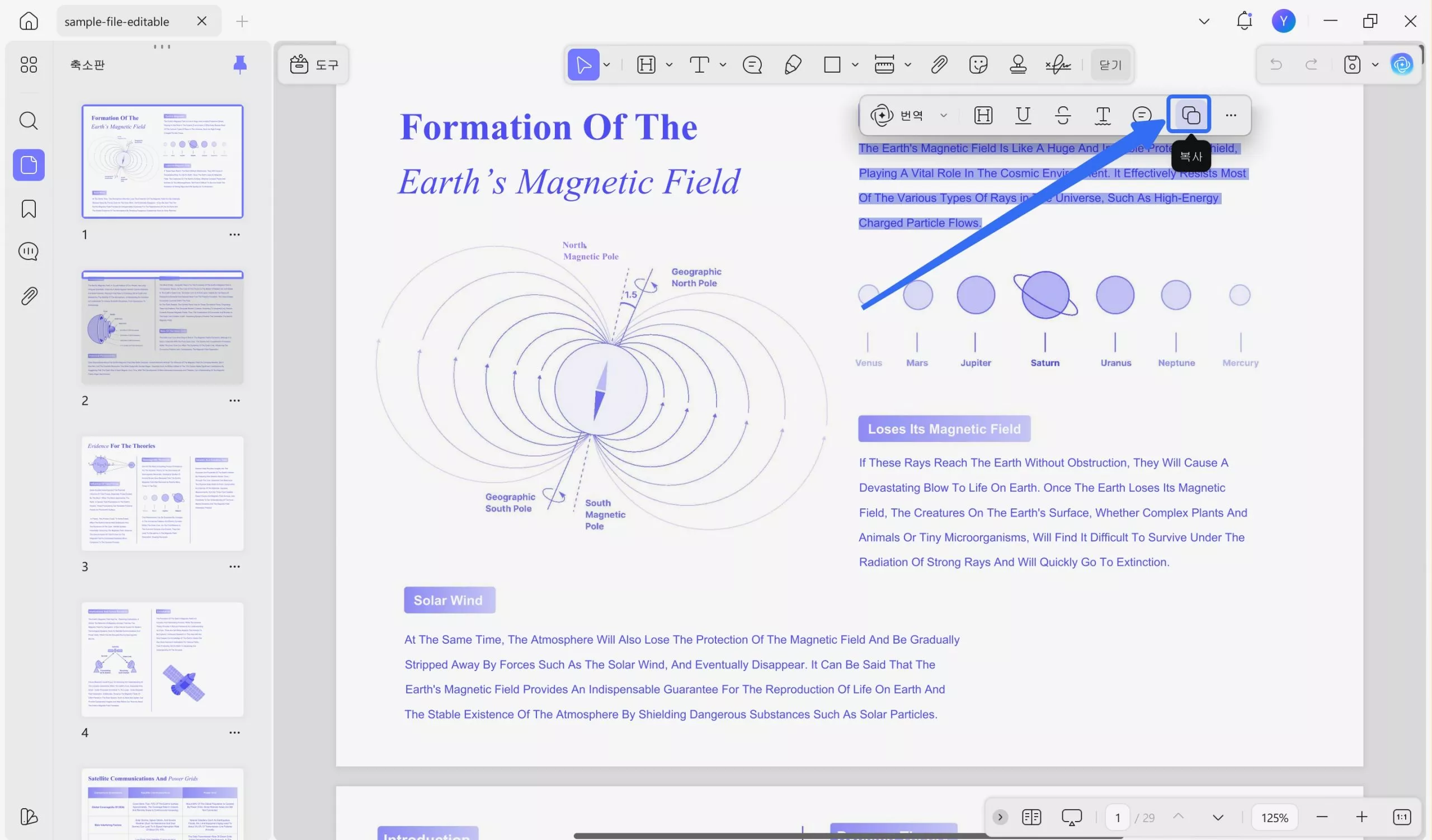
방법 2: 스캔된 PDF에 AI 적용
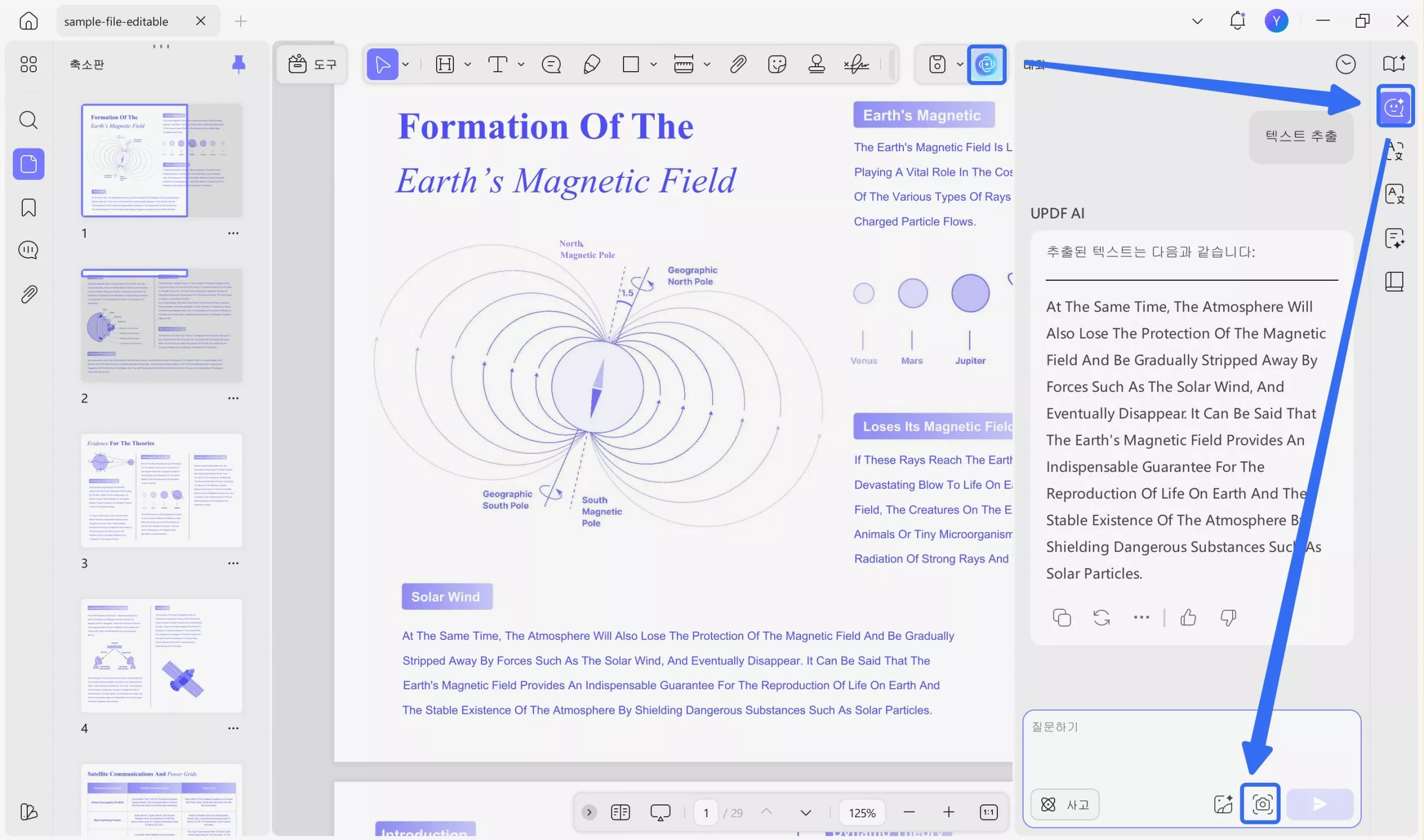
스캔한 PDF가 있는데 OCR을 사용하고 싶지 않거나 OCR이 정확한 결과를 제공하지 못하는 경우, AI 기능을 사용하여 텍스트를 추출할 수 있습니다. "UPDF AI" 아이콘을 클릭하고 "채팅" 모드에서 "스크린샷" 아이콘을 클릭한 후, 스캔한 PDF에서 추출할 내용을 선택하고 "텍스트 추출" 프롬프트를 입력한 후 "보내기" 키를 누르면 결과가 표시됩니다.
UPDF는 Mac, Windows, iOS, Android 기기에서 사용 가능하며 모든 플랫폼에 단일 라이선스를 지원하여 다양한 운영체제 사용자에게 이상적인 솔루션입니다. PDF에서 텍스트를 추출하는 것 외에도 UPDF는 다양한 기능을 제공합니다. 주요 기능은 다음과 같습니다.
UPDF 사용자 친화적 PDF 편집기의 주요 기능 :
UPDF는 사용자에게 다양한 주요 기능을 제공하여 일상적인 PDF 편집을 위한 솔루션 허브 역할을 합니다. 이러한 기능 중 일부는 다음과 같습니다.
- PDF를 이미지, Word, Excel, PPT 등 원하는 형식으로 변환 : UPDF는 PDF를 모든 파일 형식으로 변환하는 기능을 지원합니다. PDF에서 텍스트를 추출하여 Word, Excel 또는 기타 형식으로 바로 변환해야 하는 경우에도 UPDF를 사용하면 번거로움 없이 작업할 수 있습니다.
- PDF 텍스트를 편집하고 PDF에 이미지, 텍스트, 링크를 추가하기: UPDF를 사용하면 PDF 텍스트를 편집하고, 글꼴, 색상, 크기를 변경하고, 이미지 크기를 변경하고, PDF에 텍스트, 이미지, 링크를 추가할 수 있습니다.
- PDF에 주석 달기: PDF에 스티키 노트, 텍스트 주석, 강조 표시, 취소선, 밑줄, 도형, 스티커 등 다양한 주석 기능을 제공됩니다.
- PDF 관리 및 구성 : UPDF는 페이지 삽입, 삭제, 추출, 분할, 페이지 회전을 지원합니다.
- 열기 및 권한 암호 추가 : UPDF를 사용하면 사용자가 PDF 파일에 암호를 추가하여 중요한 PDF 문서와 양식에 보안 계층을 추가할 수 있습니다.
- PDF를 슬라이드쇼로 재생합니다.
UPDF의 놀라운 기능을 모두 알아본 후, 이 강력한 소프트웨어를 어디서 다운로드할 수 있는지 궁금하실 겁니다. 아래 "무료 다운로드" 버튼을 클릭하여 지금 바로 설치하세요!
Windows • macOS • iOS • Android 100% 안전
UPDF에 대해 자세히 알아보려면 아래 비디오 가이드를 시청하세요.
방법 5. Google 드라이브를 사용하여 온라인 PDF에서 텍스트 추출
스캔본 PDF에서 OCR 없이 텍스트를 추출할 경우, Google Drive 사용을 추천합니다.
사용자는 소프트웨어를 다운로드하거나 설치하지 않고도 PDF에서 텍스트 및 기타 요소를 쉽게 추출할 수 있습니다. PDF 파일에서 텍스트를 추출하는 다른 방법에 비해 쉽고 편리하며 신뢰할 수 있는 방법입니다. 다음은 Google 드라이브 방법을 사용하여 온라인에서 PDF 파일에서 정보를 추출하는 단계에 대해 설명해드립니다:
1단계: 인터넷 브라우저에서 Google 드라이브에 액세스하고 "새로 만들기" 탭을 클릭합니다. 그런 다음 드롭다운 메뉴에서 "파일 업로드"를 클릭하여 컴퓨터에서 PDF 파일을 찾아 Google 드라이브에 업로드합니다.
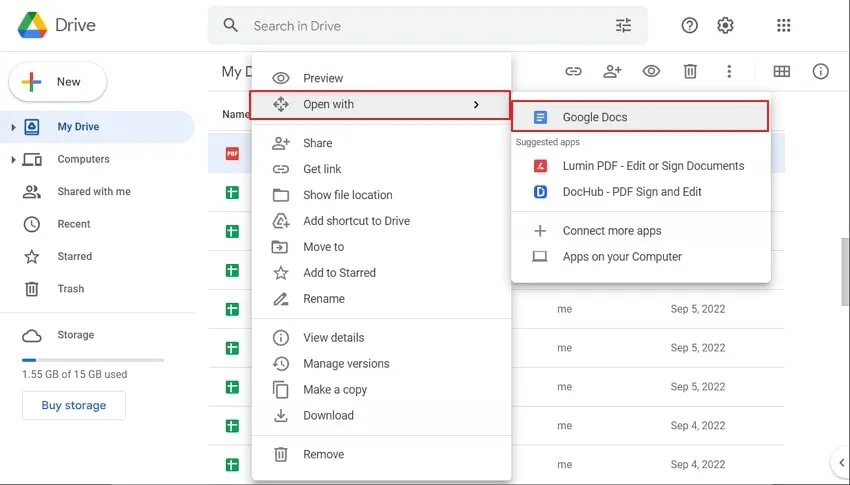
2단계: PDF 파일이 업로드되는 즉시 내 드라이브에 표시됩니다. 업로드한 PDF 파일을 마우스 오른쪽 버튼으로 클릭하고 "연결 프로그램"을 탭한 다음 "Google 문서도구"를 선택해 Google 문서도구에서 PDF를 엽니다.
3단계: Google 문서 도구에서 PDF 파일을 열면 PDF 파일의 텍스트가 자동으로 편집 가능해지며, 온라인에서 무료로 PDF에서 텍스트를 쉽게 추출할 수 있습니다.
방법 6. Python을 사용하여 PDF에서 텍스트 추출
Python이 PDF에서 텍스트를 추출하는 소스가 될 수 있을 거라고 누가 생각이나 했겠습니까? 컴퓨터에서 Python을 자주 사용하는 경우 PyPDF2 패키지를 사용하여 이 작업을 실행할 수 있습니다. 이 방법에 대한 자세한 내용은 아래 제공된 스크립트를 참조하세요.
from PyPDF2 import PdfReader
reader = PdfReader("example.pdf")
page = reader.pagers[0]
text = page.extract_text()
print(text)
PDF에서 텍스트 추출에 관한 자주 묻는 질문
1. PDF 이미지에서 텍스트를 추출할 수 있나요?
예, UPDF에서 제공하는 OCR 기능을 사용하여 PDF 이미지에서 텍스트를 추출할 수 있습니다. UPDF에서 PDF 이미지를 가져온 후 UPDF 창의 도구패널에서 "OCR"을 클릭한 후 "전환" 옵션을 선택하여 PDF 이미지에서 편집 및 검색 가능한 PDF로 변환 프로세스를 시작하세요. 변환이 완료되는 즉시 OCR PDF에서 텍스트를 추출할 수 있습니다.
2. Acrobat 없이 PDF에서 텍스트를 추출하려면 어떻게 합니까?
Mac, Windows, Android 및 iOS에서 작동하는 더 안정적이고 강력하며 호환성이 뛰어난 솔루션인 Adobe Acrobat 대신 UPDF를 사용하여 PDF에서 텍스트를 추출할 수 있습니다.
3. Linux에서 PDF에서 텍스트를 추출할 수 있나요?
예, Linux 운영 체제에서 Google 드라이브 방식 또는 PDF24 도구 OCR 기능과 같이 시중에 나와 있는 다양한 온라인 도구를 사용하여 Linux의 PDF에서 콘텐츠를 추출할 수 있습니다.
결론
OCR을 사용하거나 사용하지 않고 PDF에서 텍스트를 추출할 수 있는 다양한 옵션이 시중에 나와 있지만, 가장 현명하고 신뢰할 수 있는 선택은 PDF 파일 전용으로 잘 알려진 도구를 사용하는 것입니다. 그런 점에서 UPDF는 작업을 효율적이고 정확하게 완료하는 것 외에도 데이터 보안 유지, PDF 편집, PDF 변환 등을 지원하므로 최고의 선택입니다. 지금 바로 UPDF Pro로 업그레이드할 수 있는 특별 혜택이 있습니다. 지금 바로 Windows 컴퓨터나 MacBook에 UPDF를 다운로드하여 만족스러운 사용자 경험을 누리세요.
Windows • macOS • iOS • Android 100% 안전