Windows용 UPDF
Windows용 UPDF Mac용 UPDF
Mac용 UPDF iPhone/iPad용 UPDF
iPhone/iPad용 UPDF 안드로이드용 UPDF
안드로이드용 UPDF UPDF AI 온라인
UPDF AI 온라인 UPDF Sign
UPDF Sign PDF 편집
PDF 편집 PDF 주석
PDF 주석 PDF 생성
PDF 생성 PDF 양식
PDF 양식 링크 편집
링크 편집 PDF 변환
PDF 변환 OCR
OCR PDF → Word
PDF → Word PDF → 이미지
PDF → 이미지 PDF → Excel
PDF → Excel PDF 정리
PDF 정리 PDF 병합
PDF 병합 PDF 분할
PDF 분할 PDF 자르기
PDF 자르기 PDF 회전
PDF 회전 PDF 보호
PDF 보호 PDF 서명
PDF 서명 PDF 민감 정보 가리기
PDF 민감 정보 가리기 PDF 민감 정보 제거
PDF 민감 정보 제거 보안 제거
보안 제거 PDF 보기
PDF 보기 UPDF 클라우드
UPDF 클라우드 PDF 압축
PDF 압축 PDF 인쇄
PDF 인쇄 일괄 처리
일괄 처리 UPDF AI 소개
UPDF AI 소개 UPDF AI 솔루션
UPDF AI 솔루션 AI 사용자 가이드
AI 사용자 가이드 UPDF AI에 대한 FAQ
UPDF AI에 대한 FAQ PDF 요약
PDF 요약 PDF 번역
PDF 번역 PDF 설명
PDF 설명 PDF로 채팅
PDF로 채팅 AI 채팅
AI 채팅 이미지로 채팅
이미지로 채팅 PDF를 마인드맵으로 변환
PDF를 마인드맵으로 변환 학술 연구
학술 연구 논문 검색
논문 검색 AI 교정기
AI 교정기 AI 작가
AI 작가 AI 숙제 도우미
AI 숙제 도우미 AI 퀴즈 생성기
AI 퀴즈 생성기 AI 수학 문제 풀이기
AI 수학 문제 풀이기 PDF를 Word로
PDF를 Word로 PDF를 Excel로
PDF를 Excel로 PDF를 PowerPoint로
PDF를 PowerPoint로 사용자 가이드
사용자 가이드 UPDF 팁
UPDF 팁 FAQ
FAQ UPDF 리뷰
UPDF 리뷰 다운로드 센터
다운로드 센터 블로그
블로그 뉴스룸
뉴스룸 기술 사양
기술 사양 업데이트
업데이트 UPDF vs Adobe Acrobat
UPDF vs Adobe Acrobat UPDF vs. EZPDF
UPDF vs. EZPDF UPDF vs. ALPDF
UPDF vs. ALPDF
스캔한 문서에서 텍스트를 복사하고 싶었던 적이 있으신가요? 아니면 스크린샷이나 손글씨 메모가 포함된 PDF에서 텍스트를 추출하고 싶으셨나요? 그렇다면 지금 이 글을 통해 PDF OCR 인식 기능으로 해결할 수 있습니다.
스캔이나 이미지에서 텍스트를 인식하면 모든 것을 수동으로 다시 입력하지 않고도 주요 세부 정보를 추출할 수 있습니다. 필요에 따라 텍스트를 쉽게 추출하거나 편집하고 특정 섹션을 검색할 수 있습니다.
하지만 PDF에서 텍스트를 어떻게 인식할까요? 이 글이 가이드가 될 것입니다. 스캔한 PDF와 손으로 쓴 노트에서 텍스트를 인식하는 방법을 보여드리겠습니다.
여러 솔루션이 있지만, UPDF를 사용하는 것이 좋습니다. 강력한 OCR 도구를 사용하면 약 38개 언어의 텍스트를 인식할 수 있습니다. 구조는 그대로 유지됩니다!
별도의 플랫폼으로 전환하지 않고도 UPDF 내에서 바로 텍스트를 검색하고 편집할 수 있습니다. 그리고 PDF에서 필기를 정확하게 추출하고 싶다면 UPDF는 강력한 AI 어시스턴트로 가능합니다!
직접 시도해보는 건 어떨까요? 지금 UPDF를 다운로드하세요! 그런 다음 아래 가이드를 따라 모든 PDF에서 텍스트를 손쉽게 추출하세요!
Windows • macOS • iOS • Android 100% 안전
1부. 스캔한 PDF 문서에서 텍스트 인식
이미지나 스캔한 PDF에서 PDF 텍스트를 인식하고 싶다면 UPDF의 OCR 도구가 간단한 솔루션을 제공합니다. 문서의 텍스트를 빠르게 분석하여 놀라운 정확도로 편집 및 검색이 가능한 PDF로 변환합니다.
이 앱이 제공하는 몇 가지 뛰어난 기능은 다음과 같습니다.
- 3자기 유형을 지원합니다. (편집 가능한 PDF, 텍스트 및 사진 전용, 검색 가능한 PDF만)
- 레이아웃, 이미지 해상도, 페이지 범위 등의 설정을 사용자 정의할 수 있습니다.
- 다국어 문서에서 텍스트를 추출할 수 있습니다.
- 스캔한 문서와 이미지를 모두 지원합니다 .
스캔한 PDF 문서에서 텍스트를 인식할 준비가 되셨나요? 작동 방식은 다음과 같습니다.
1단계 : 장치에서 UPDF를 실행합니다. 그런 다음 "파일 열기"를 클릭하여 스캔한 PDF를 가져옵니다. 이미지 파일의 경우 UPDF 홈 인터페이스로 끌어서 열 수 있습니다.
2단계 : 파일이 열리면 도구에서 "OCR"을 클릭합니다.
3단계 : OCR 설정 메뉴가 열립니다. 문서 유형에서 "검색 가능한 PDF만"을 선택합니다.
4단계 : 원하는 레이아웃을 선택하고 문서 언어, 이미지 해상도, 페이지 범위 등의 다른 설정을 조정합니다.
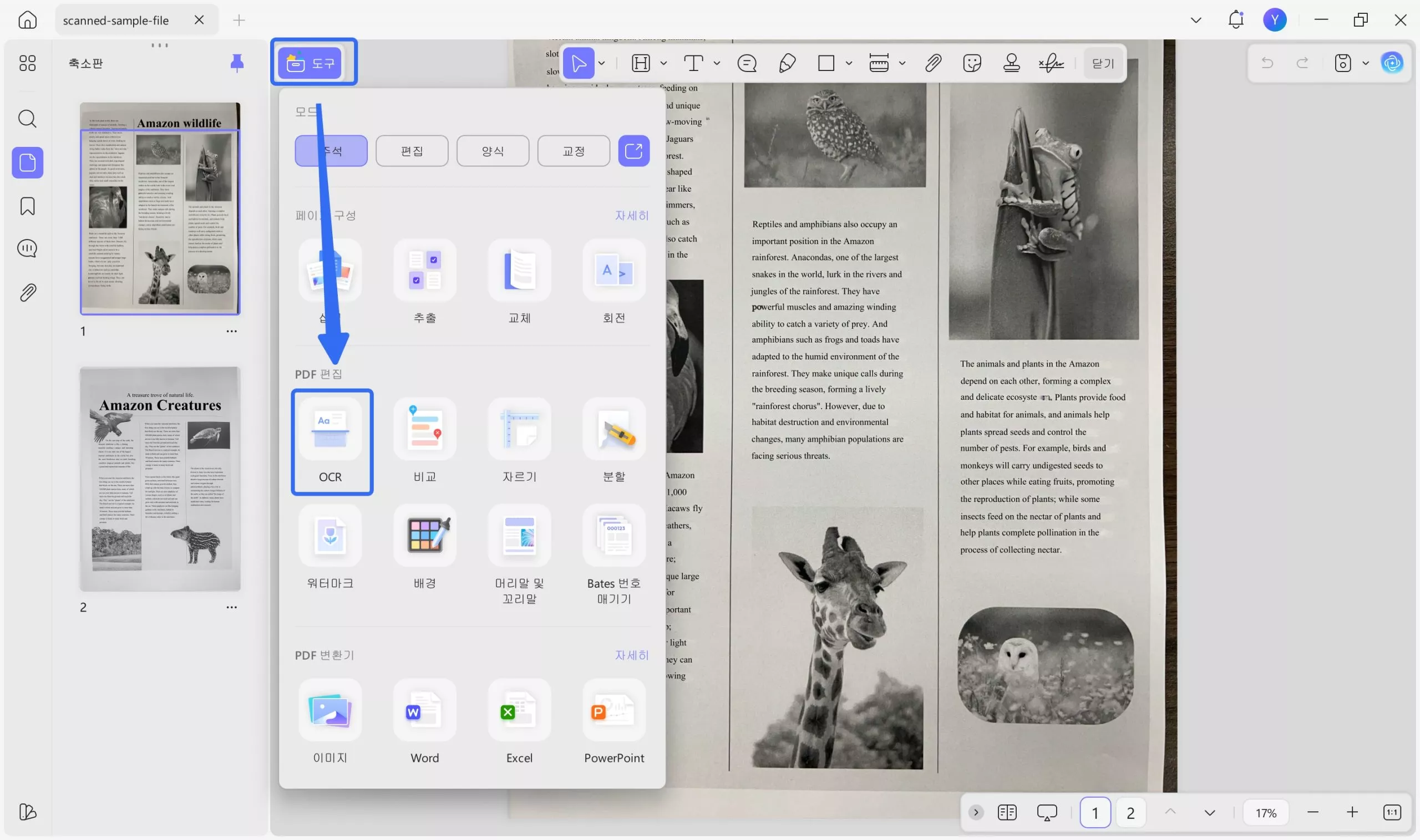
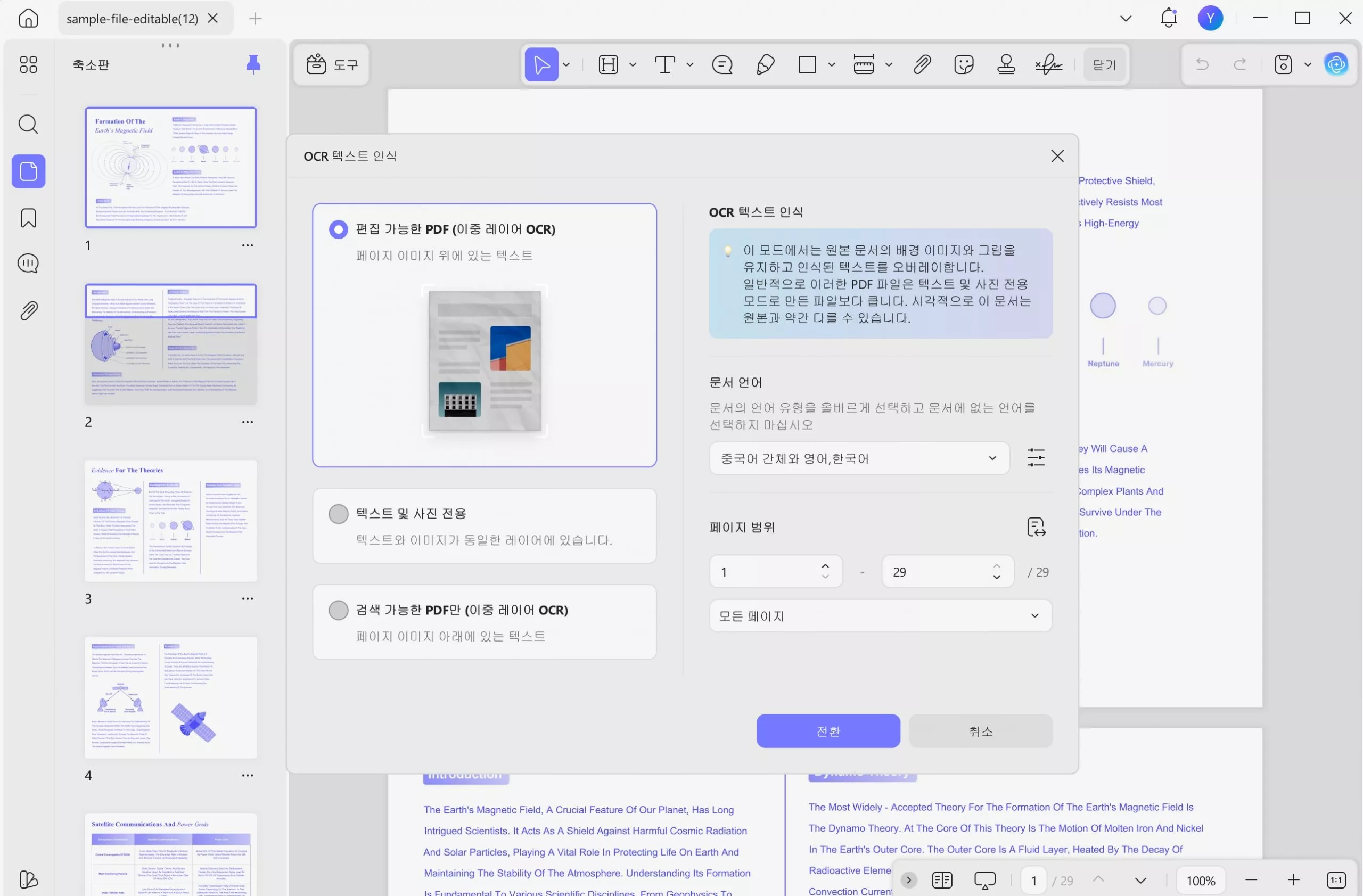
5단계 : 고급 레이아웃 설정을 위해 레이아웃 드롭다운 옆에 있는 기어 아이콘을 클릭합니다. 그러면 레이아웃 설정 메뉴가 열립니다. 여기서 MRC 압축 등의 옵션을 선택할 수 있습니다. 설정이 끝나면 "전환"을 클릭합니다.
6단계 : OCR이 완료되면 변환된 PDF가 새 탭에서 열립니다. 그런 다음 PDF에서 텍스트를 선택, 검색 및 편집할 수 있습니다.
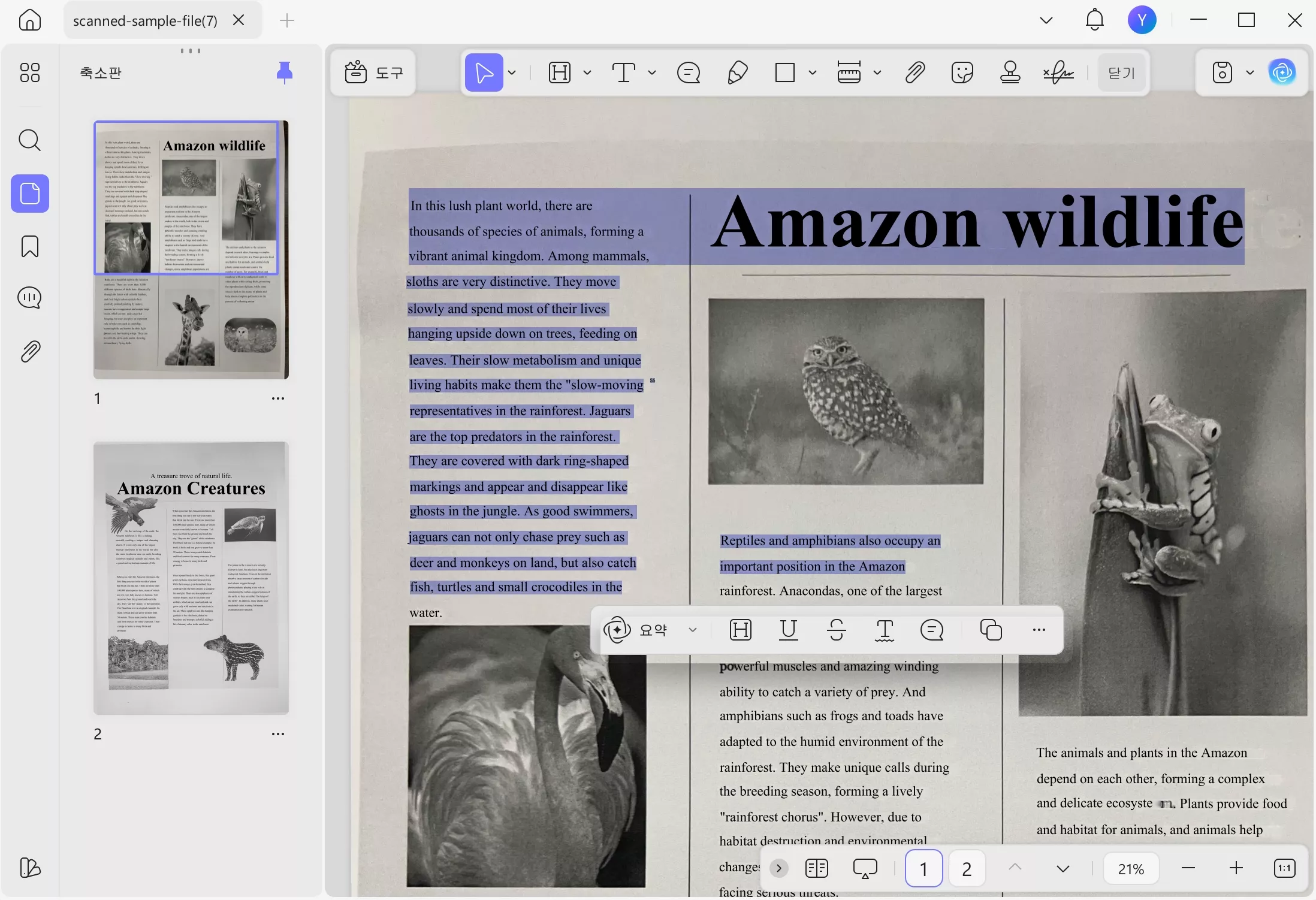
그게 다입니다. 이제 스캔한 이미지로 PDF의 텍스트를 인식하는 방법을 알게 되었습니다! 시각적 학습을 선호하신다면 아래 비디오를 시청하여 UPDF의 OCR 도구에 대한 쉬운 가이드를 확인하세요.
2부. PDF에서 손으로 쓴 텍스트 인식
때로는 PDF 파일에서 손으로 쓴 텍스트를 추출해야 할 수도 있습니다. OCR 도구는 인식하는 데 도움이 될 수 있지만, 특히 글씨가 불분명한 경우 부정확할 수 있습니다.
하지만 걱정하지 마세요. UPDF는 내장된 AI 어시스턴트로 쉬운 솔루션을 제공합니다. 필기의 스크린샷을 제공하면 몇 초 이내에 텍스트를 추출합니다. 그런 다음 수동 편집을 위해 모든 텍스트 편집기에 복사하여 붙여넣을 수 있습니다.
이것은 이미지 기능이 작동하는 채팅입니다! 이것으로 할 수 있는 다른 작업은 다음과 같습니다.
- 단일 프롬프트로 이미지와 스크린샷에서 텍스트를 추출할 수 있습니다.
- 손으로 쓴 텍스트와 디지털 텍스트 모두 모든 언어를 지원합니다.
- 데이터 차트와 복잡한 다이어그램에 대한 자세한 분석을 얻을 수 있습니다.
- 전문가의 피드백, 디자인 개선을 위한 제안 등을 제공할 수 있습니다.
- 해당 파일을 기반으로 소셜 미디어용 콘텐츠를 생성할 수 있습니다.
그럼, PDF에서 손으로 쓴 텍스트를 인식할 준비가 되셨나요? Windows 또는 Mac에 다운로드하여 설치하세요. 그런 다음 아래 가이드를 사용하여 손으로 쓴 텍스트를 빠르고 쉽게 추출하세요!
Windows • macOS • iOS • Android 100% 안전
1단계 : 데스크탑에서 UPDF를 엽니다. "파일 열기"를 클릭하고 손으로 쓴 텍스트가 있는 PDF를 선택합니다.
2단계 : PDF가 열리면 오른쪽에서 "UPDF AI"를 클릭합니다. 그런 다음 위에서 "채팅" 모드를 선택합니다.
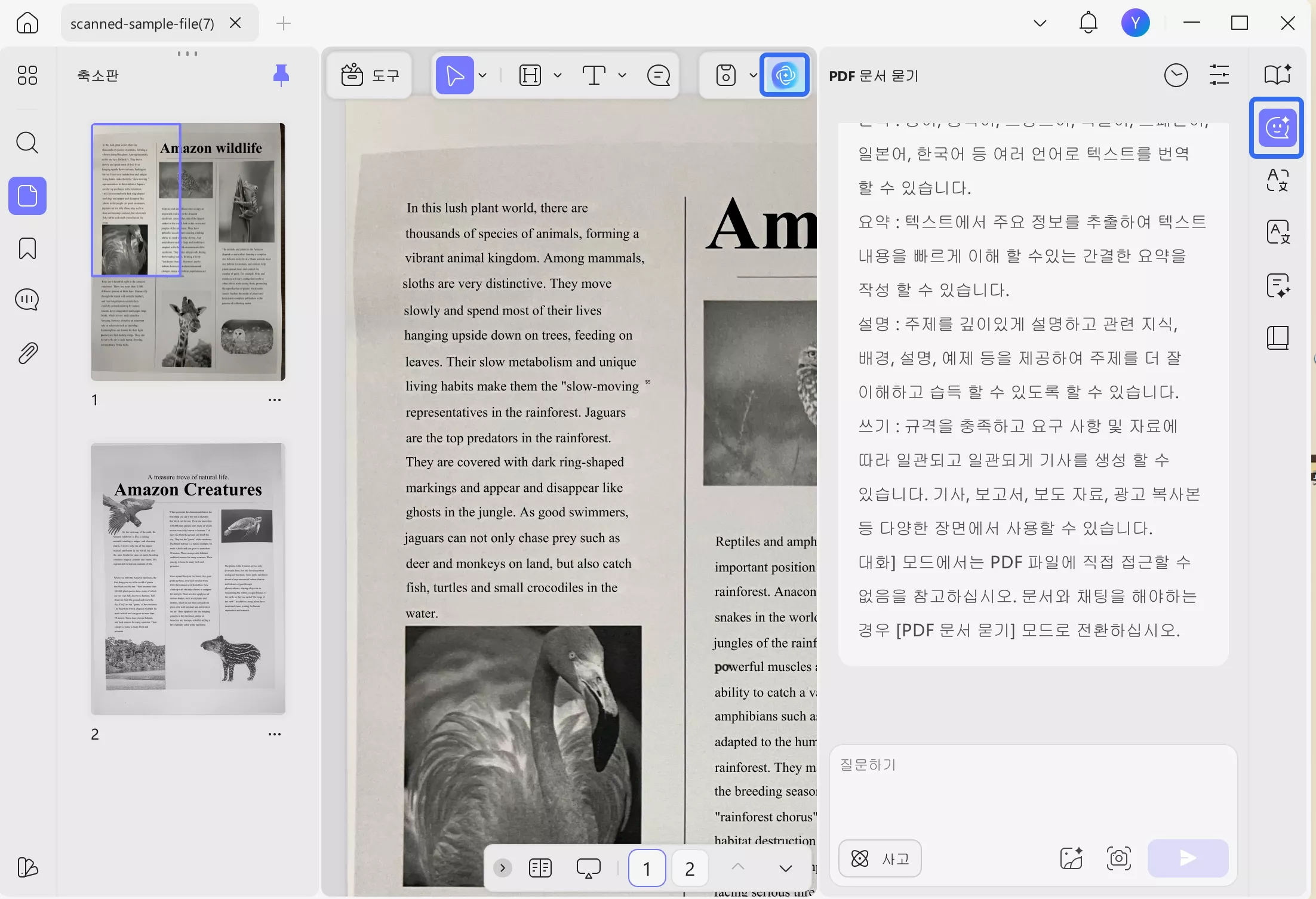
3단계 : 손으로 쓴 텍스트가 있는 PDF 페이지로 이동합니다. 그런 다음 오른쪽 하단에서 "자르기" 도구를 선택합니다.
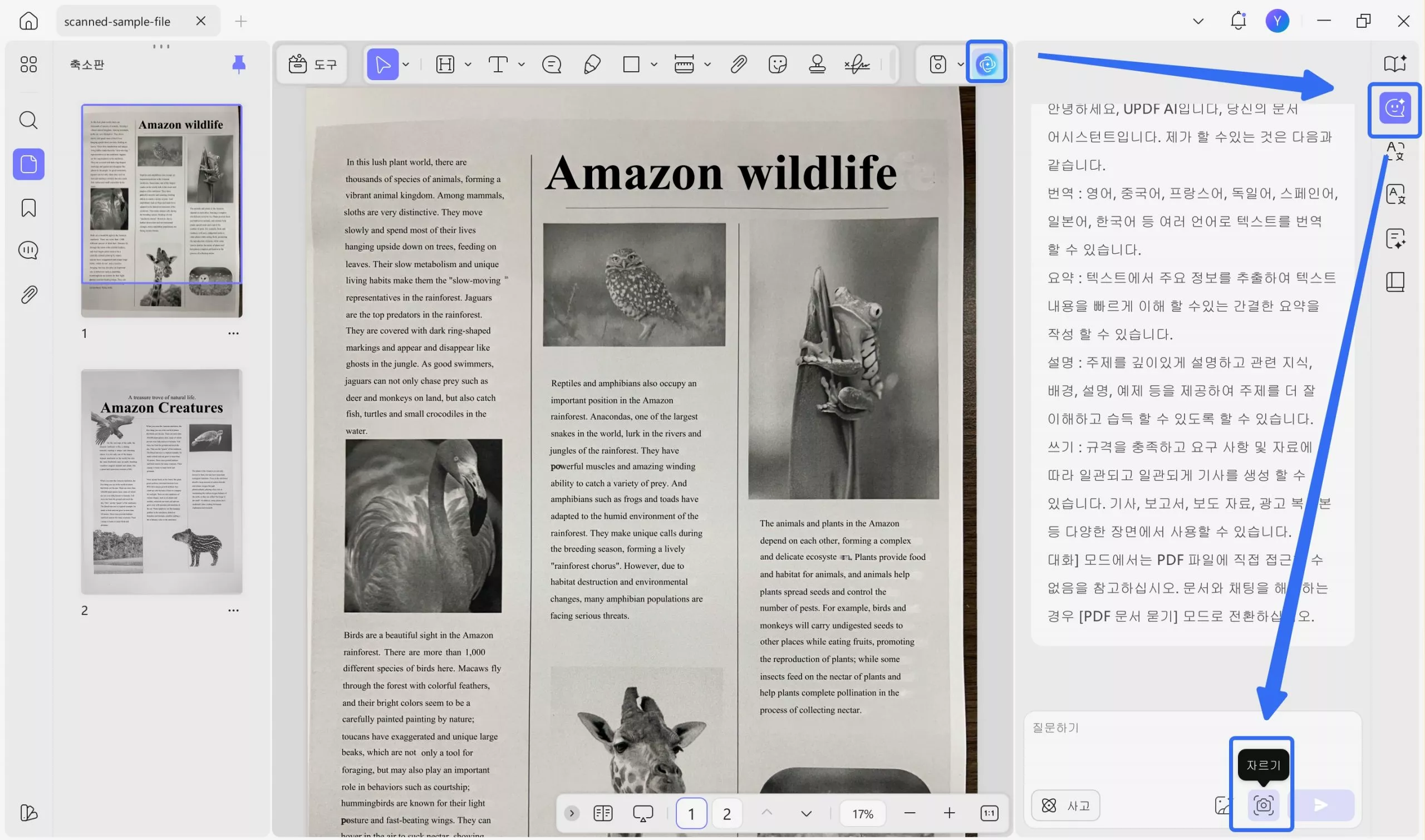
4단계 : 손으로 쓴 텍스트가 있는 영역 위로 커서를 클릭하고 드래그합니다. 놓으면 스크린샷이 UPDF AI에 업로드됩니다.
5단계 : UPDF AI에 이미지에서 필적을 추출해 달라고 요청하는 프롬프트를 작성합니다. 그런 다음 "보내기" 버튼을 누릅니다. UPDF AI가 필적을 빠르게 분석하여 디지털 형태로 추출합니다.
프롬프트: 이 이미지에서 손으로 쓴 텍스트를 추출합니다.
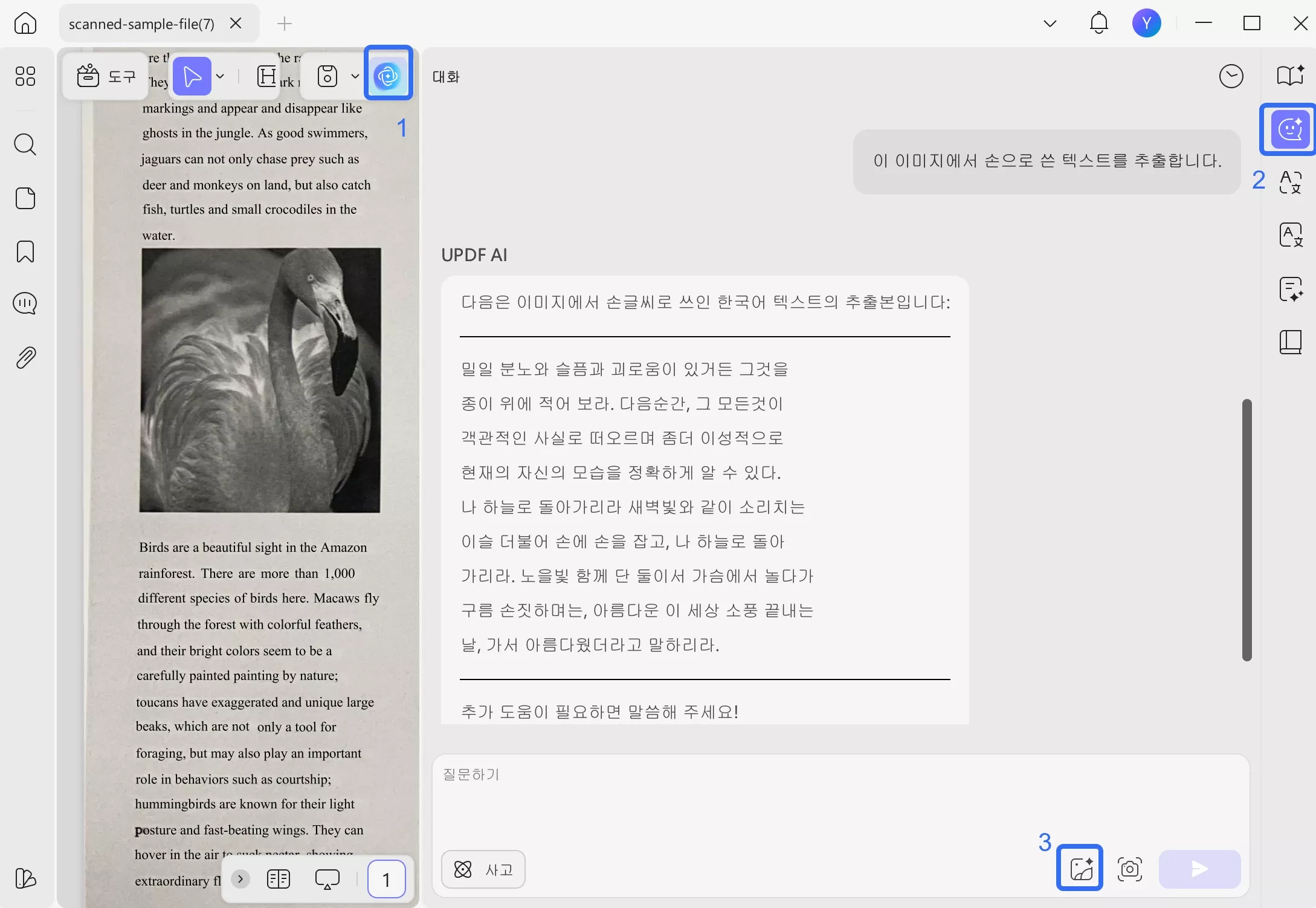
그리고 이것이 AI로 PDF에서 손으로 쓴 텍스트를 인식하는 방법입니다! UPDF AI는 빠르고 간단하게 만듭니다. 긴 단계나 복잡한 탐색이 필요 없습니다. 그리고 더 좋은 점은, 시작하는 데 도움이 되는 100개의 무료 작업을 제공한다는 것입니다.
AI 어시스턴트 외에도 UPDF는 워크플로에 생산적인 PDF 도구의 전체 제품군을 제공합니다. 이 UPDF 리뷰를 읽고 더 많은 기능과 그 기능이 어떻게 도움이 될 수 있는지 알아보세요!
3부. PDF에서 내 텍스트가 인식되지 않는 이유는?
때로는 OCR이 텍스트를 인식하지 못해 부정확한 변환이 발생할 수 있습니다. 이 문제가 발생하면 당황하지 마십시오. 몇 가지 가능한 이유와 해결 방법은 다음과 같습니다.
- 낮은 품질의 스캔: 텍스트가 흐릿하거나 정렬이 잘못된 스캔은 OCR이 인식하기 어렵습니다.
- 지저분한 필기체: OCR 도구는 엉성한 필기 텍스트를 식별하는 데 어려움을 겪습니다.
- 양식화된 글꼴: PDF에는 OCR을 혼란스럽게 할 수 있는 장식적이거나 복잡한 텍스트가 포함되어 있을 수 있습니다.
- 대비가 낮음: 텍스트와 배경의 대비가 충분하지 않으면 문자를 구분하는 것이 까다로울 수 있습니다.
- 보호된 PDF: PDF에는 OCR 수행 및 텍스트 편집에 제한이 있을 수 있으며, 이로 인해 텍스트 인식이 제한될 수 있습니다.
PDF에서 텍스트 인식 불가에 대한 솔루션
'PDF에서 텍스트를 인식할 수 없음' 문제를 해결하려면 다음 사항을 고려하세요.
- 고품질 스캔을 사용: 더 높은 해상도로 문서를 스캔해 선명하고 읽기 쉬운 텍스트를 표현합니다.
- 다국어 OCR 사용: PDF에 여러 언어가 포함되어 있는 경우, 다국어 문서를 지원하는 OCR 도구를 사용합니다
- OCR 설정 확인: 올바른 문서 언어, 레이아웃 및 출력 유형을 선택합니다. 잘못된 설정은 텍스트 인식에 문제를 일으킬 수 있습니다.
- AI 활용: 원하는 결과가 나오지 않으면 스캔한 PDF를 이미지로 변환하거나 스크린샷을 찍은 후 UPDF AI와 같은 AI 도구를 사용하여 텍스트를 추출해 보세요.
마지막으로
PDF에서 텍스트를 인식하는 방법에 대한 모든 내용입니다. UPDF의 다양한 텍스트 인식 기능을 사용하면 프로세스가 간편합니다. OCR 도구를 사용하여 스캔한 문서에서 텍스트를 인식하거나 AI 어시스턴트를 사용하여 최소한의 노력으로 텍스트를 추출할 수 있습니다. 시도해 보세요. 오늘 데스크톱에 UPDF를 다운로드하세요! 스캔한 PDF 등을 처리하는 효율적인 방법을 찾을 수 있습니다!
Windows • macOS • iOS • Android 100% 안전