






















































Sie wissen nicht, wie Sie in einem gescannten PDF suchen können, bei dem ständig die Meldung ‚Diese Seite enthält nur Bilder‘ aufpoppt? Oder Sie haben versucht, mit der Windows-Suchfunktion oder “STRG + F” nach Wörtern zu suchen, und auch das geht nicht? Dann haben Sie wohl in einer gescannten PDF-Datei gesucht. Und wenn Sie sich jetzt fragen, wie Sie in einer solchen gescannten PDF-Datei suchen können, haben wir in diesem Artikel die Lösung für Sie! Lassen Sie uns also gleich eintauchen.
Wie Sie in einer gescannten PDF-Datei Wörter suchen
Das grundlegende Problem ist, dass gescannte Dokumente technisch gesehen keinen Text enthalten. Da es sich nur um ein Bild des Dokuments handelt, gibt es keinen echten Text, den Windows identifizieren könnte.
Um Ihr PDF durchsuchbar zu machen, müssen Sie eine Texterkennung durchführen, damit der Inhalt auf der Seite durchsuchbar und bearbeitbar wird. Dafür brauchen Sie eine Software mit OCR-Funktion (Optical Character Recognition), die das gescannte Dokument durchgeht, alles erkennt, was einem Buchstaben oder einem Wort ähnelt, und es dann in echten Text umwandelt.
Zwar bieten mehrere PDF-Editoren diese Funktion, aber wir würden Ihnen zu UPDF raten – Ihrer All-in-One PDF-Lösung! UPDF hat eine AI-gestützte OCR-Funktion, die Ihre gescannten PDFs, Papierdokumente und Bilder in bearbeitbare PDFs umwandelt und drei Ausgabelayouts bietet, um sie interaktiv zu gestalten. Laden Sie zunächst UPDF herunter, bevor wir mit der Anleitung beginnen.
Windows • macOS • iOS • Android 100% sicher


Hier finden Sie einige beeindruckende Funktionen dieser OCR-Software:
- Bis zu 99% Genauigkeit: Die fortschrittliche OCR-Technologie von UPDF bietet hochpräzise Ergebnisse!
- Höchste OCR-Geschwindigkeit: Wer will nicht Zeit sparen? UPDF ist sich dessen bewusst und konvertiert daher im Vergleich zu den Mitbewerbern superschnell.
- Kleine Ausgabegröße mit hoher Qualität: Die Größe des umgewandelten PDF-Dokuments ist viel kleiner als die des Originals!
- Unterstützt 38 Sprachen: Es unterstützt auch zweisprachige Dokumente und ermöglicht Ihnen die Auswahl mehrerer Sprachgruppen.
Darüber hinaus liest, organisiert und beschriftet es Ihre PDFs und kann gescannte PDFs jeder Größe umwandeln! Also, worauf warten Sie noch? Folgen Sie den einfachen Schritten unten, wie Sie Wörter in gescannten PDFs suchen können, und lösen Sie Ihr Problem kinderleicht und ohne Umschweife!
Schritt 1: PDF öffnen und auf das OCR-Icon zugreifen
Klicken Sie auf „Datei öffnen“, um das PDF zu importieren. Sie können auch die Tastenkombination Strg + oder Cmd + O verwenden.
Klicken Sie auf die Option „Text mit OCR erkennen“ in der rechten Symbolleiste. (Wenn Sie diese Funktion zum ersten Mal verwenden, werden Sie aufgefordert, dieses Plugin herunterzuladen. Laden Sie es im folgenden Fenster herunter und warten Sie, bis es installiert ist).


Schritt 2: Das gescannte PDF in eine durchsuchbare Datei verwandeln
Klicken Sie nach der Installation erneut auf die gleiche Schaltfläche „Text mit OCR erkennen“. Sie erhalten zwei verschiedene Optionen für den Dokumententyp. Wählen Sie die Option „Durchsuchbares PDF“, denn damit werden gescannte Dokumente in bearbeitbare und durchsuchbare Dateien umgewandelt.
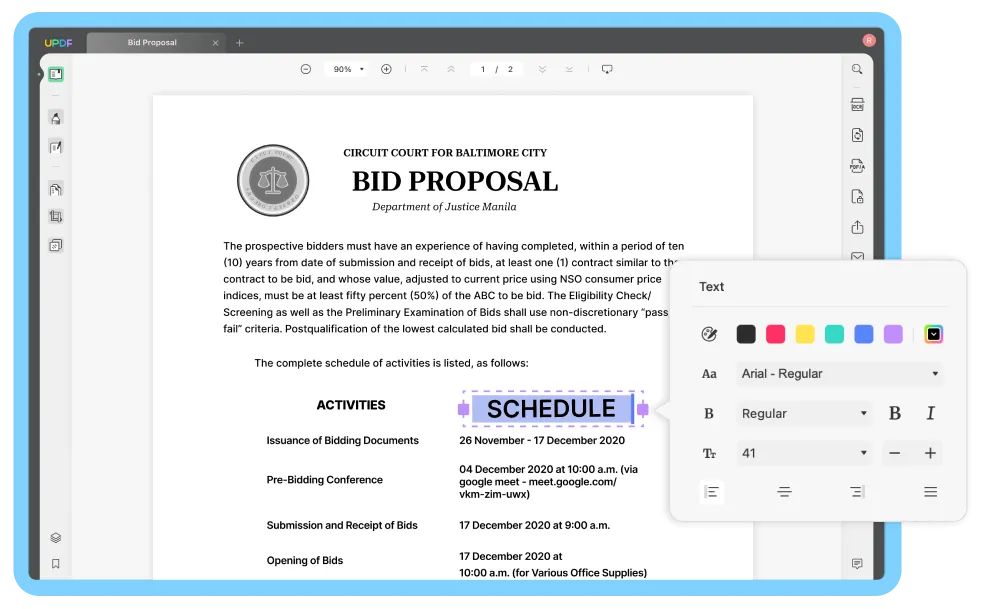
Wählen Sie die Optionen Layout und Erweitertes Layout für diese Dokument und stellen Sie die Dokumentsprache, die Bildauflösung und den Papierbereich ein.
Für erweiterte Layout-Optionen klicken Sie auf das ‚Zahnrad‘-Icon:
- Wenn Sie „Bilder behalten“ markieren, müssen Sie die Qualität festlegen („Niedrig“, „Ausgeglichen“ oder „Hoch“).
- Wenn Sie Bilder komprimieren möchten
- Wenn Sie andere Dokumentelemente (Kopf- und Fußzeilen, Seitenzahlen, Text und Hintergrundfarben) beibehalten wollen.
Klicken Sie dann auf die Option „OCR durchführen“, wählen Sie dann einen Ort, an dem Sie die Datei speichern möchten, und klicken Sie auf „Speichern“.


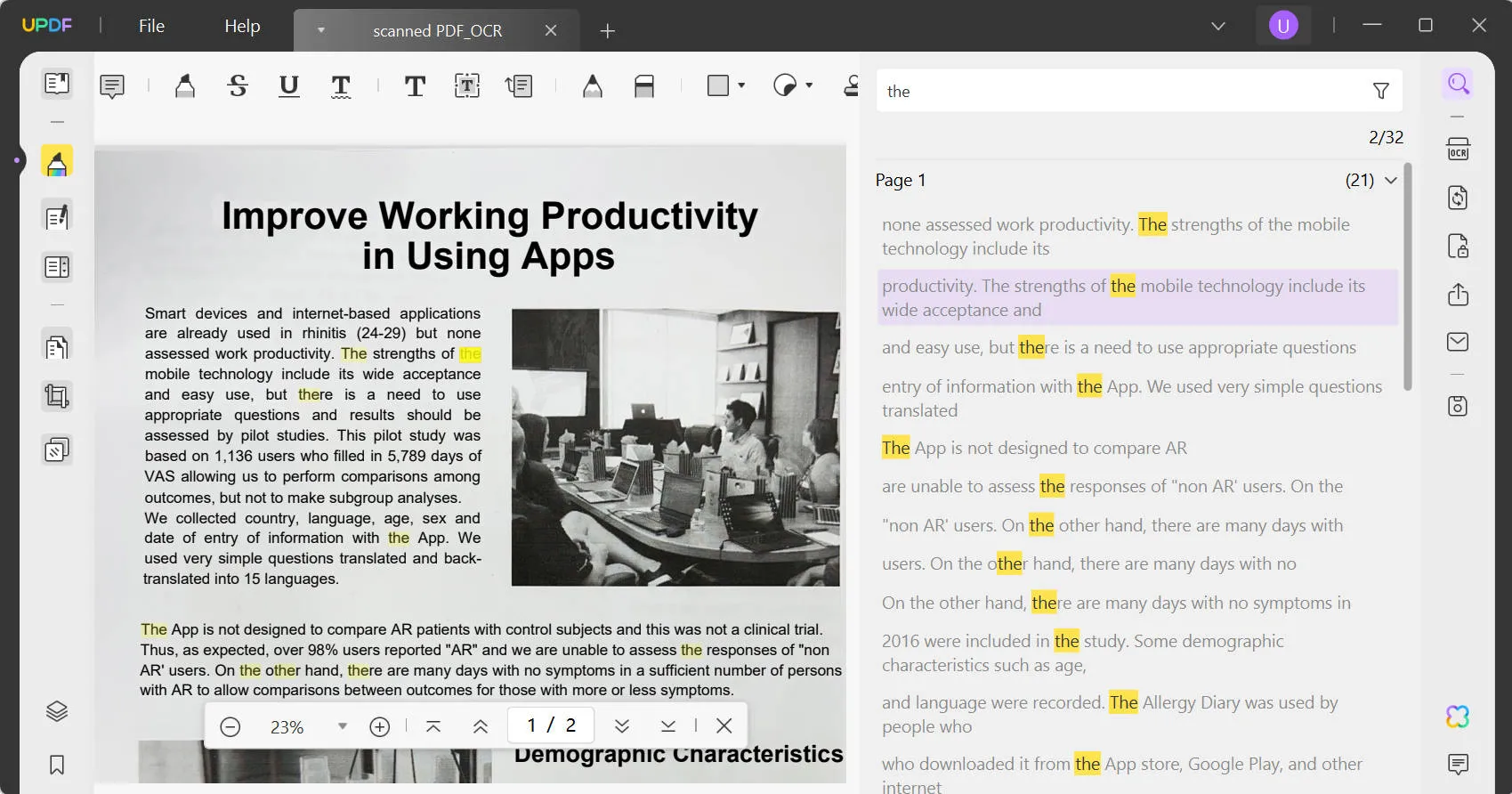
Schritt 3: Nach Wörtern in der gescannten PDF-Datei suchen
Nach Durchführung der OCR wird die durchsuchbare PDF-Datei automatisch in UPDF geöffnet. Jetzt können Sie in der gescannten PDF-Datei nach den gewünschten Wörtern suchen, indem Sie auf Strg + F oder das Icon Suchen in der oberen linken Ecke klicken.
Geben Sie das Wort ein, das Sie suchen möchten, und es werden alle Ergebnisse im Dokument angezeigt. Sie können auf ein beliebiges Ergebnis klicken, um direkt zu der entsprechenden Seite zu springen. Das war es auch schon – so können Sie ganz einfach Wörter in PDFs finden.

Tipp: Welches Layout sollten Sie bei der OCR wählen?
Für durchsuchbare PDFs müssen Sie ein geeignetes Layout wählen, je nachdem, für welchen Zweck oder in welcher Situation Sie es brauchen. Mithilfe der verfügbaren Optionen können Sie eine der folgenden Möglichkeiten wählen:
Nur Text und Bilder:
Die OCR erkennt und speichert den Text und die Bilder im gesamten PDF in einer kleineren Datei. Es wird keine transparente Bildebene vorhanden sein, um die Formatierung zu erhalten. Die konvertierte Datei kann sich also optisch von der Originalversion unterscheiden.

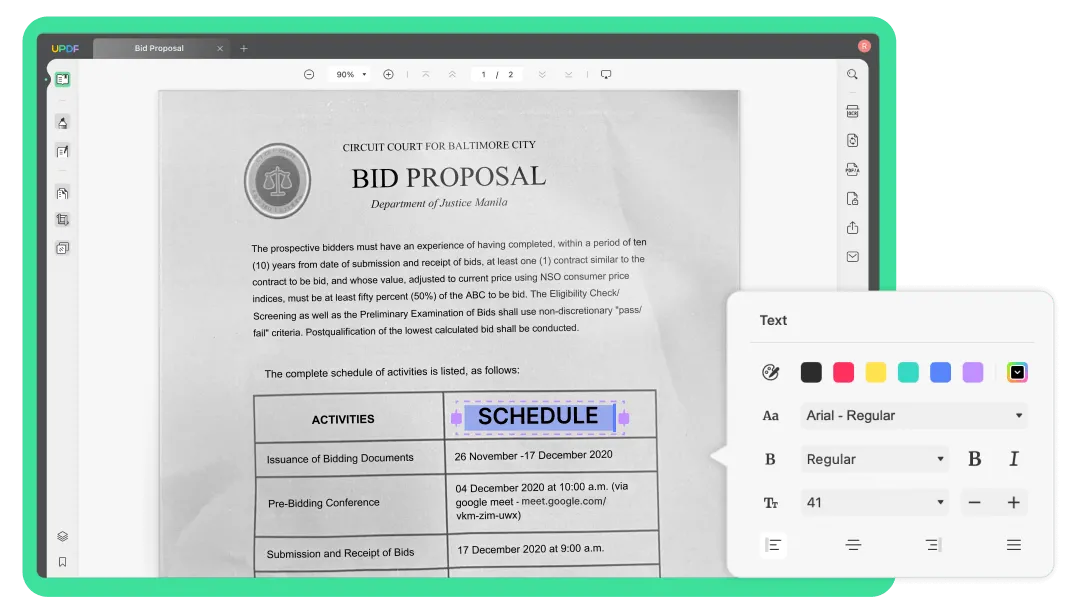
Text über dem Seitenbild:
In diesem Modus bleiben die Illustrationen und Hintergrundbilder in der Quelldatei als Ebene unter dem Text des Dokuments erhalten. Das ursprüngliche Format des Dokuments wird ebenfalls beibehalten. Diese Dateien sind zwar umfangreicher, sehen aber optisch anders aus als die Originaldateien.

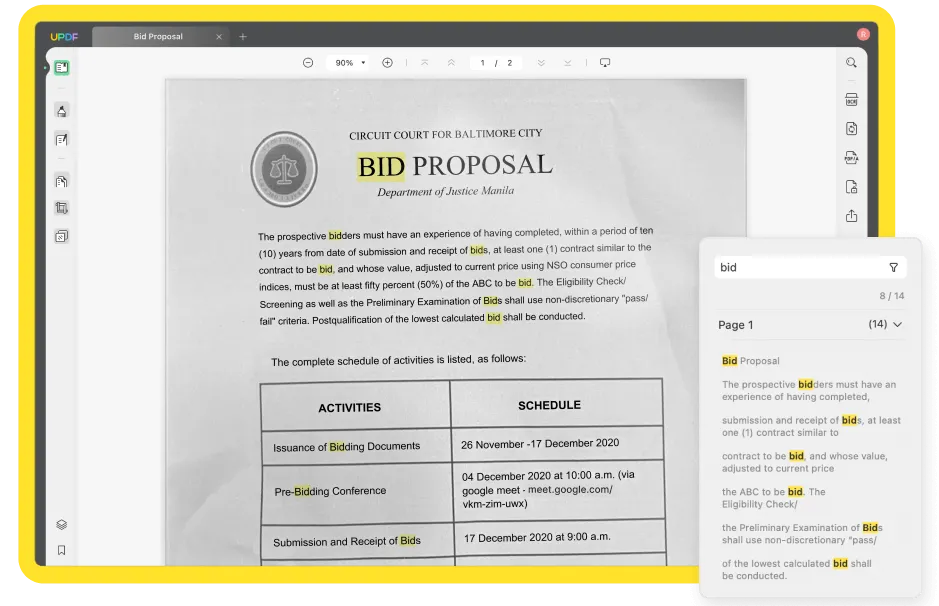
Text unter dem Seitenbild:
Die PDF-Bilder werden beibehalten, aber der Text wird unter den Bildern auf einer unsichtbaren Ebene platziert. Die Formatierung des Dokuments wird also beibehalten, indem eine Ebene über den Text gelegt wird. Dieser Dateityp ist mit dem des Originals identisch. Der Text kann durchsucht, aber nicht bearbeitet werden.

FAQs
Sie haben immer noch Fragen, wie Sie in einem gescannten PDF nach Wörtern suchen können? Dann lassen Sie uns die gängigsten kurz durchgehen:
1. Warum kann ich nicht nach einer gescannten PDF-Datei suchen?
Wenn Sie ein Dokument scannen, erfasst Ihr Scanner die Seiten als flaches Bild, sprich es gibt keinen Text, den Windows erkennen oder ein PDF-Viewer lesen kann. Sie müssen zunächst die OCR-Funktion von UPDF verwenden, um Ihr gescanntes Dokument in ein lesbares Format umzuwandeln, wie wir oben in diesem Artikel erklärt haben.
2. Kann ich “Strg F” für gescannte Dokumente verwenden?
Nein. Diese Windows Suchfunktion funktioniert nur bei Dokumenten, die lesbaren Text enthalten. Sie können diese Funktion nur nutzen, wenn Sie eine Software herunterladen, die die OCR-Technologie unterstützt, z.B. UPDF, die den Scan in ein durchsuchbares PDF umwandelt.
3. Warum kann ich in meinem PDF nicht Strg F verwenden?
Die Suchfunktion funktioniert nicht bei Dokumenten oder PDFs, die nur Bilder enthalten, wie z.B. bei gescannten Dokumenten. Diese Bilder enthalten keinen Text, den Windows erkennen kann.
Fazit
Sie wissen nicht, wie Sie in einem gescannten PDF-Dokument nach Wörtern suchen können? Kein Problem, denn UPDF ist Ihre ultimative Lösung. Seine OCR-Funktion ist leicht zu verstehen und einfach zu bedienen und kann sogar Text in einem unscharfen gescannten Dokument erkennen – damit haben so manch andere Softwares ihre Schwierigkeiten! Mit seinem fortschrittlichen MRC-basierten Bildkomprimierungsalgorithmus können Sie jedes Bild in erkennbaren Text umwandeln oder das PDF in ein reines Bilddokument verwandeln!
Worauf warten Sie noch? Laden Sie UPDF jetzt herunter, damit Sie problemlos mit Ihren PDFs interagieren können und mit seinen brillanten AI-Tools effizienter mit Ihren Dateien arbeiten. Sie können auch gerne auf die Premium-Version upgraden, um alle Funktionen ohne Einschränkungen freizuschalten!
Windows • macOS • iOS • Android 100% sicher














