






















































스캔한 PDF에서 검색할 때 '이 페이지에는 이미지만 포함되어 있습니다'라는 문구가 표시될 때, 어떻게 검색해야 할지 난감하신가요? 또는 Windows의 찾기 기능이나 CTRL + F를 사용해 단어를 검색해 보았지만 작동하지 않았나요? 아마도 스캔한 PDF에서 검색을 시도하셨을 겁니다. 스캔한 PDF 문서에서 단어를 검색하는 방법이 궁금하시다면, 지금부터 알아보세요!
스캔한 PDF에서 단어를 검색하는 방법은 무엇인가요?
스캔한 문서에는 실제 텍스트가 포함되어 있지 않습니다. 문서의 사진일 뿐이므로 Windows에서 색인화할 수 있는 텍스트가 없습니다.
PDF를 검색 가능하게 만들려면 OCR(광학 문자 인식) 기능을 통해 페이지의 내용을 인식하여 검색 및 편집할 수 있는 텍스트로 변환해야 합니다. 이 기능은 스캔된 문서를 분석해 문자나 단어를 식별하고 실제 텍스트로 변환합니다.
여러 PDF 편집기가 OCR 기능을 제공하지만, UPDF를 추천합니다. UPDF는 스캔된 PDF, 종이 문서 및 이미지를 세 가지 출력 레이아웃을 갖춘 편집 가능하고 검색 가능한 PDF로 변환할 수 있는 AI 기반 올인원 PDF 솔루션입니다. UPDF의 OCR 기능에 대해 더 자세히 알아보고 싶다면 이 링크를 참고하세요. 아래 사용법을 소개하기 전에 UPDF를 먼저 다운로드해보세요.
Windows • macOS • iOS • Android 100% 안전


UPDF OCR 소프트웨어의 주요 기능:
- 최대 99%의 정확도: UPDF의 고급 OCR 기술은 높은 정확도의 결과를 제공합니다.
- 빠른 OCR 속도: 시간을 절약하고 싶지 않은 사람이 있을까요? UPDF는 이를 잘 알고 있기 때문에 경쟁사에 비해 전환 속도가 매우 빠릅니다.
- 고품질의 작은 파일 크기: 변환된 PDF 문서의 크기는 원본보다 훨씬 작습니다.
- 38개 언어 지원: 다국어 문서 지원 및 여러 언어 세트 선택이 가능합니다.
이 모든 것 외에도 PDF를 읽고, 정리하고, 주석을 달 수 있으며 모든 크기의 스캔 PDF를 변환할 수 있습니다! 이제 무엇을 기다리시나요? 스캔한 PDF에서 단어를 검색하는 방법에 대한 아래의 간단한 단계를 따라 지금 바로 문제를 해결하세요! 몇 가지 간단한 단계만 거치면 금방 끝낼 수 있습니다!
1단계: PDF 열기 및 OCR 아이콘 사용
'파일 열기'를 클릭하여 PDF를 가져옵니다. Ctrl + O 또는 Cmd + O 단축키를 사용할 수도 있습니다.
오른쪽 도구 모음에서 'OCR을 사용하여 텍스트 인식' 옵션을 클릭합니다. (처음 사용하는 경우 플러그인을 다운로드하고 설치가 완료될 때까지 기다립니다.)


2단계: 스캔한 PDF를 검색 가능 상태로 전환
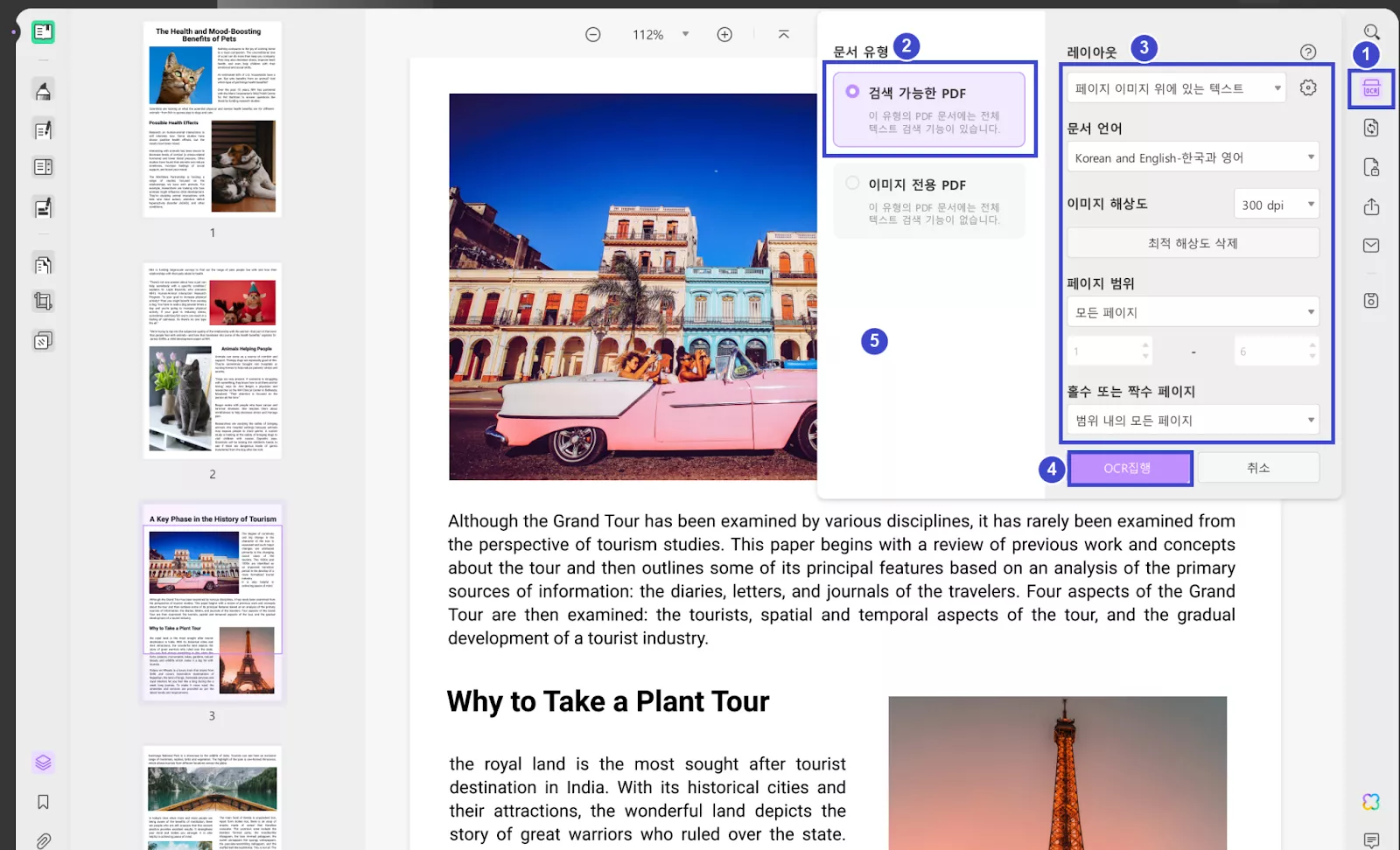
설치가 완료되면 'OCR을 사용하여 텍스트 인식' 버튼을 다시 클릭합니다. '검색 가능한 PDF'를 선택하여 스캔한 문서를 편집 및 검색할 수 있도록 변환합니다.
'텍스트 및 그림만', '페이지 이미지 위에 텍스트', '페이지 이미지 아래에 텍스트' 중에서 레이아웃을 선택합니다. 문서 언어, 이미지 해상도, 용지 범위도 설정합니다.
추가 설정은 '기어' 아이콘을 클릭하여 확인할 수 있습니다.
- '사진 보관'을 선택하면 화질('낮음' '균형' 또는 '높음')을 결정해야 합니다.
- 사진 압축
- 다른 문서 요소(머리글, 바닥글, 페이지 번호, 텍스트 및 배경색) 유지
'OCR 수행' 옵션을 클릭한 다음 파일을 저장할 위치를 선택하고 '저장'을 클릭합니다.

3단계: 스캔한 PDF에서 단어 검색
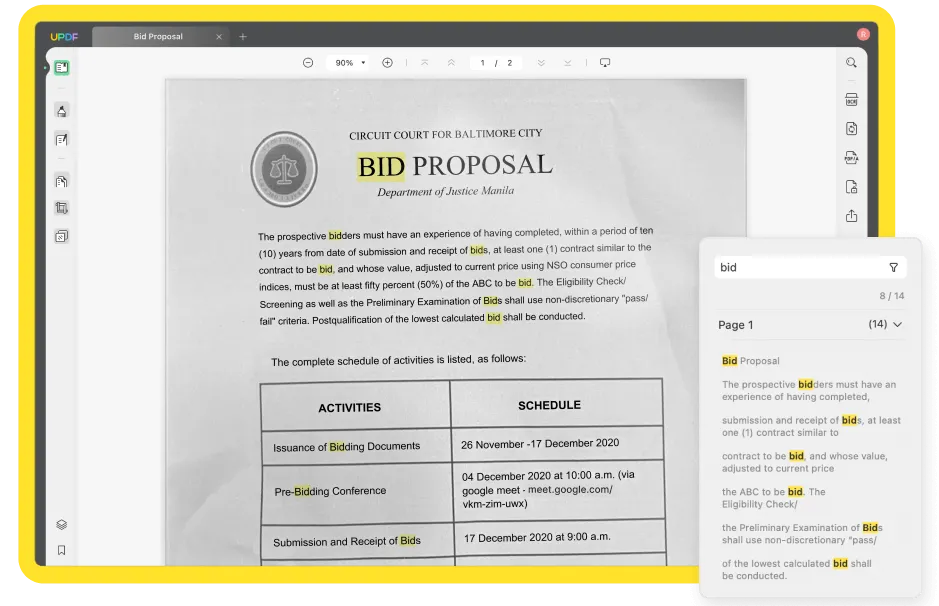
OCR을 수행하면 검색 가능한 PDF 파일이 UPDF에서 자동으로 열립니다. 이제 스캔한 PDF에서 Ctrl + F 또는 오른쪽 상단의 검색 아이콘을 클릭하여 원하는 단어를 검색할 수 있습니다.
검색하려는 단어를 입력하면 해당 문서에 대한 모든 결과가 표시됩니다. 결과를 클릭하면 해당 페이지로 바로 이동할 수 있습니다. 이 방법으로 스캔한 PDF에서 검색이 가능합니다.


더 자세한 사용법은 아래 동영상 가이드를 참조하세요.

팁: OCR 수행 시 어떤 레이아웃을 선택해야 하나요?
검색 가능한 PDF를 만들 때는 사용 목적이나 상황에 맞게 적절한 레이아웃을 선택해야 합니다. 다음 옵션 중 하나를 선택할 수 있습니다.
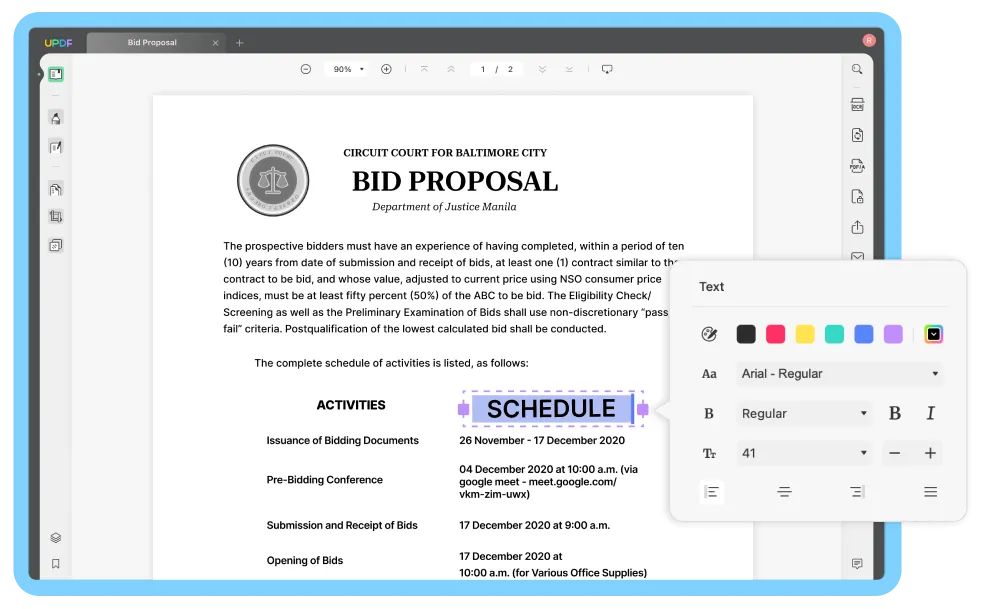
텍스트 및 그림만:
OCR은 PDF의 텍스트와 그림을 인식하여 작은 파일로 저장합니다. 서식을 유지하기 위한 투명 이미지 레이어는 포함되지 않으므로, 변환된 파일의 시각적 모습이 원본과 다를 수 있습니다.

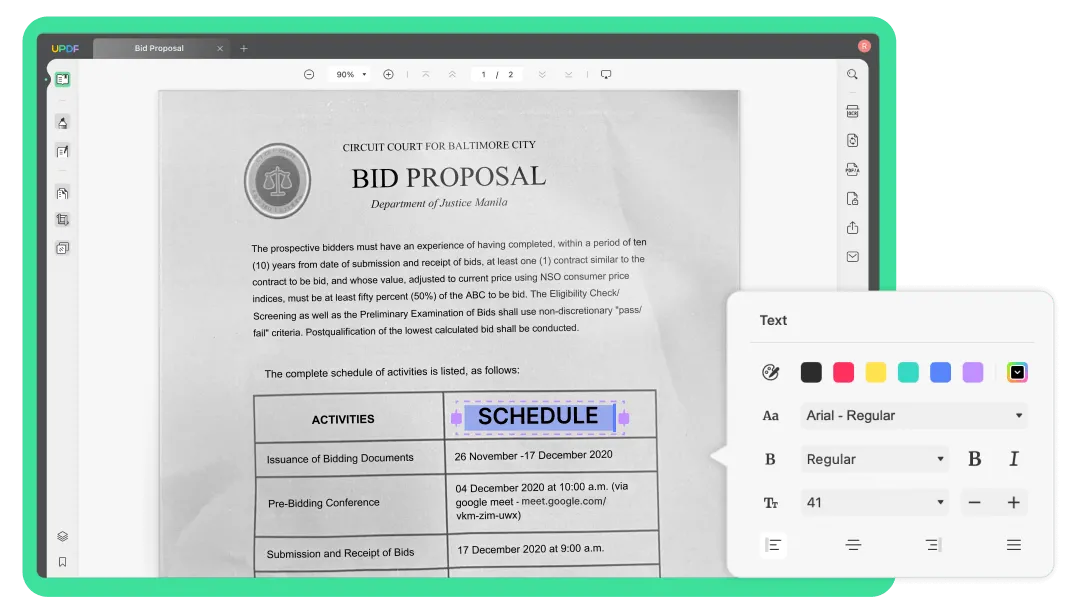
페이지 이미지 위에 텍스트
이 모드는 문서의 텍스트 아래에 원본 파일의 일러스트레이션과 배경 이미지를 레이어로 유지합니다. 문서의 원본 형식은 유지되지만, 이 파일은 더 크며 원본과 약간 다르게 보일 수 있습니다.

페이지 이미지 아래에 텍스트
PDF 이미지는 유지되며, 텍스트는 보이지 않는 레이어 아래에 위치합니다. 문서의 서식은 텍스트 위에 레이어를 추가하여 유지됩니다. 이 파일 형식은 원본과 동일하며 텍스트는 검색할 수 있지만 편집은 불가능합니다.

스캔한 PDF에서 검색에 대한 FAQ
아직 스캔한 PDF에서 단어를 검색하는 방법에 대해 궁금한 점이 있으신가요? 걱정하지 마세요. 여기에 자주 묻는 질문과 답변을 정리했습니다.
왜 스캔한 PDF에서 검색이 안 되나요?
스캔한 문서는 스캐너가 페이지를 평면 이미지로 캡처하기 때문에 Windows나 PDF 뷰어가 인식할 수 있는 텍스트가 없습니다. 이 문서에서 설명한 대로 UPDF의 OCR 기능을 사용해 스캔한 문서를 읽을 수 있는 형식으로 변환해야 합니다.
스캔한 문서에서 Ctrl + F를 사용할 수 있나요?
아니요. Windows의 찾기 기능은 읽을 수 있는 텍스트가 포함된 문서에서만 작동합니다. UPDF와 같은 OCR 기술을 지원하는 소프트웨어를 다운로드하여 스캔한 문서를 검색 가능한 PDF로 변환해야 이 기능을 사용할 수 있습니다.
내 PDF에서 Ctrl + F가 작동하지 않는 이유는 무엇인가요?
찾기 기능은 이미지만 포함된 문서나 PDF에서는 작동하지 않는 이유는 스캔한 문서의 경우 이미지에 텍스트가 포함되어 있지 않기 때문입니다.
결론
스캔한 PDF에서 검색하는 방법을 찾고 계셨나요? UPDF가 최고의 솔루션입니다. 사용이 간편한 OCR 기능은 흐릿하게 스캔된 문서의 텍스트도 감지할 수 있습니다. UPDF의 고급 MRC 기반 이미지 압축 알고리즘을 통해 이미지를 감지 가능한 텍스트로 변환하거나 PDF를 이미지 전용 문서로 바꿀 수 있습니다.
지금 UPDF를 다운로드하여 PDF 작업을 더 간편하게 하고, 강력한 AI 도구로 더 매끄러운 경험을 누리세요. 프리미엄 버전으로 업그레이드하면 모든 기능을 제한 없이 사용할 수 있습니다. 이로써 스캔한 PDF에서 단어를 검색하는 방법에 대한 가이드를 마칩니다.
Windows • macOS • iOS • Android 100% 안전














