Reconhecimento de Texto OCR
O recurso OCR do UPDF permite converter o texto digitalizado de documentos PDF em conteúdo pesquisável e editável. Com este recurso, os dados entre imagens também podem ser editados, tornando o documento interativo para o usuário.
(A versão Mac com Chip Apple do site oficial tem o recurso de OCR. Entretanto, a versão Mac com Chip Intel e a versão Mac App Store ainda não liberam o recurso de OCR).
Como baixar e instalar o OCR
Ao abrir o documento, navegue até o botão "Reconhecer texto usando OCR" na barra de ferramentas à direita.

Se você estiver usando este recurso pela primeira vez, você deve baixá-lo como um plugin UPDF. Continue o processo clicando no botão "Instalar" na janela pop-up.

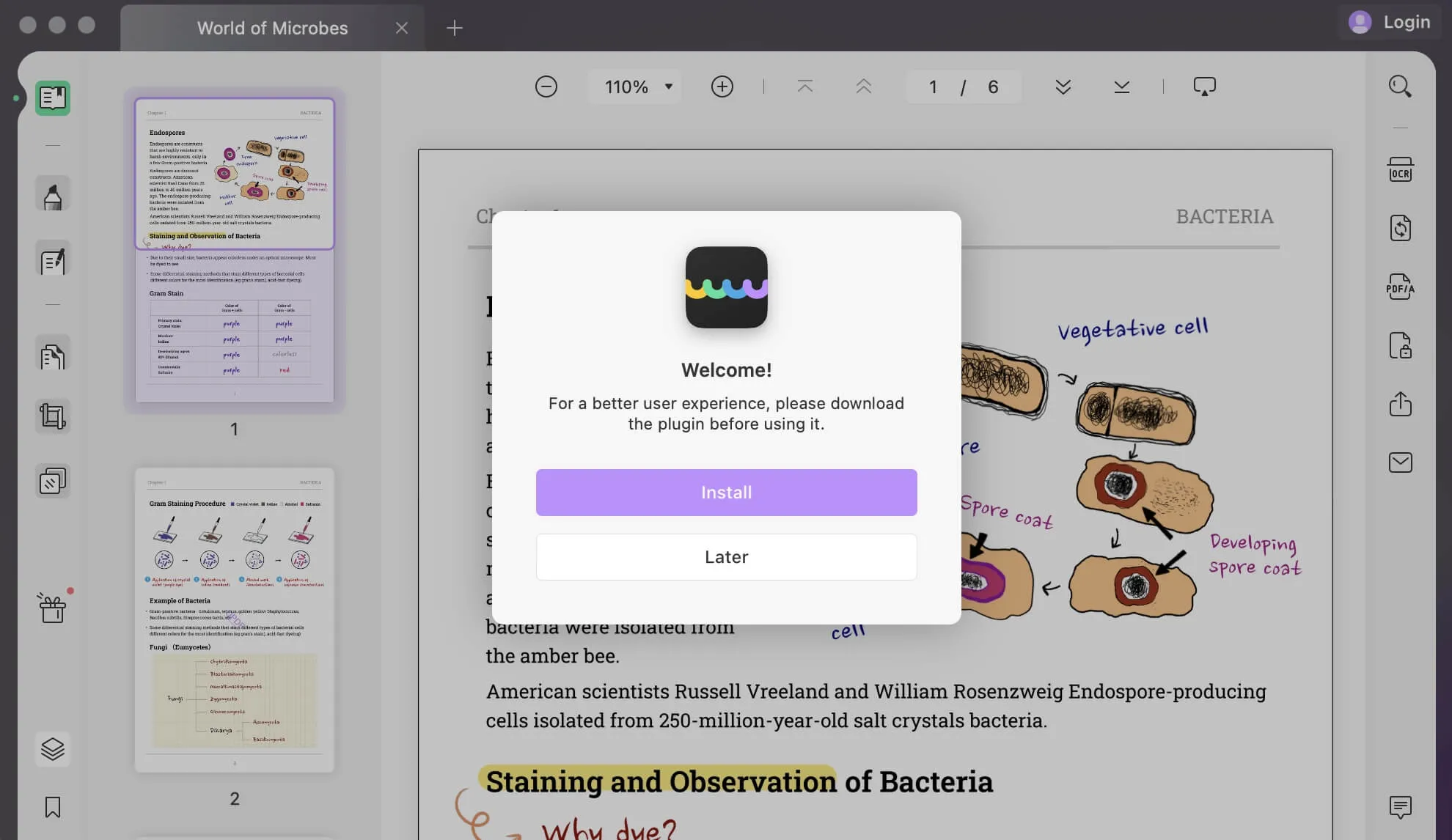
Você será automaticamente redirecionado para a próxima janela, que exibirá o progresso da instalação do recurso. Deixe o recurso se instalar com sucesso em seu dispositivo Windows antes de utilizá-lo.

Como fazer OCR em PDF
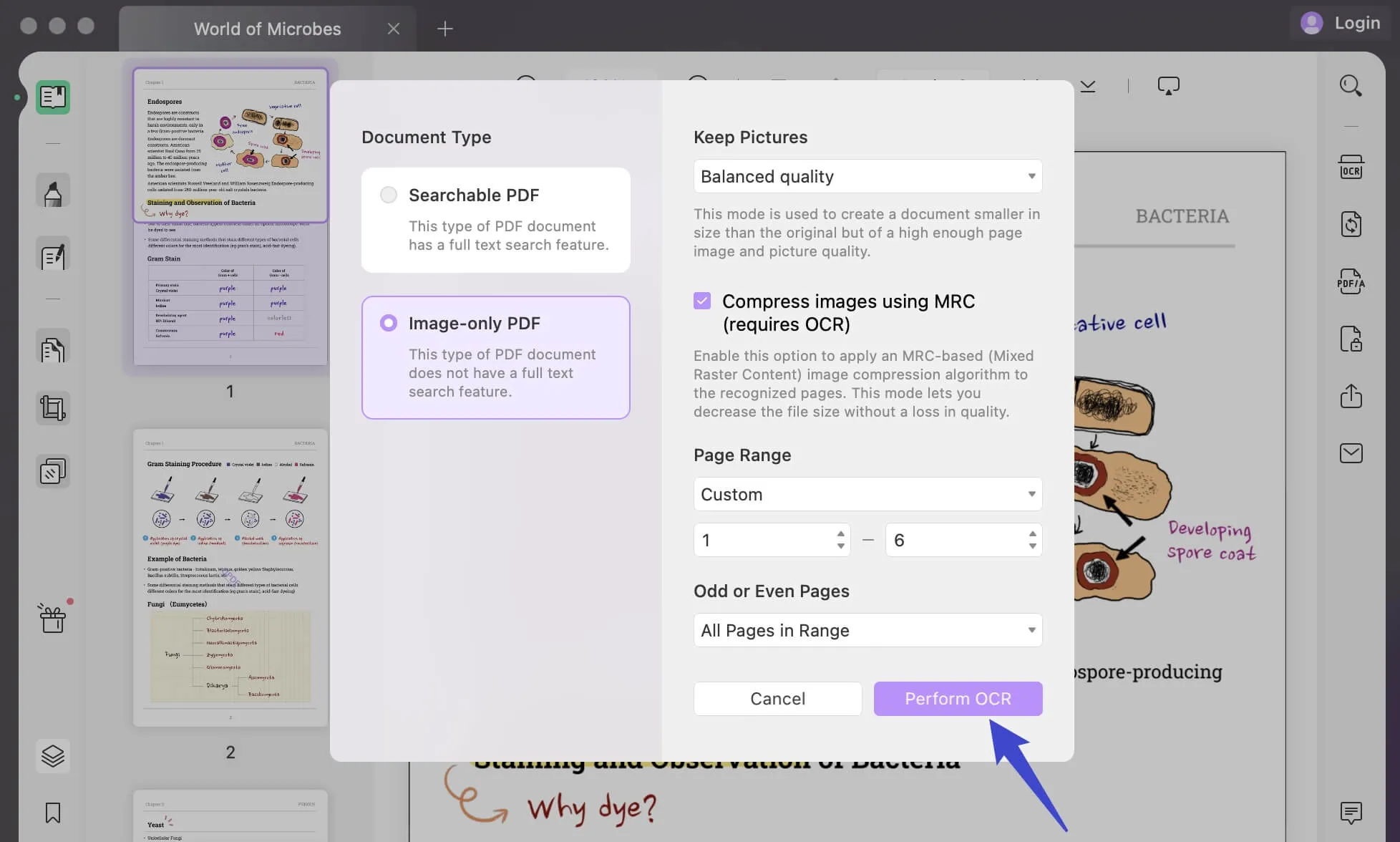
Após a instalação, feche a janela e navegue até o mesmo botão para acessar a ferramenta OCR via UPDF. Ao abrir, ele lhe dará duas opções diferentes de tipo de documento, incluindo "PDF pesquisável" e "PDF somente imagem".
PDF pesquisável: Ao selecionar esta opção, ela converte documentos PDF digitalizados em documentos pesquisáveis e editáveis.
PDF apenas com imagem: Quando esta opção é selecionada, ela converterá seu documento pesquisável e editável em um documento PDF baseado em imagem, que não é pesquisável nem editável.
Tipo de documento: PDF pesquisável
Se você optar por "PDF pesquisável", ele converterá seus documentos PDF digitalizados em documentos editáveis e pesquisáveis.
Layout: Para configurar isso, é necessário primeiro determinar o "Layout" correto usando as opções disponíveis no menu suspenso. Ao configurar o layout do fluxo, você terá três opções diferentes:
Somente texto e fotos: O texto e as imagens reconhecidas serão salvas no documento PDF que será criado. O arquivo criado também é menor e pode ter uma estrutura visual diferente do original.
Texto sobre a página Imagem: Esta modalidade é responsável pela preservação das imagens de fundo e ilustrações no documento de origem onde o OCR foi realizado. Estes arquivos são maiores; entretanto, eles podem diferir visualmente do original.
Texto sob a imagem da página: Neste modo, a imagem em PDF é preservada; entretanto, o texto reconhecido é colocado sob uma camada invisível abaixo da imagem. Este tipo de arquivo é exatamente o mesmo que o arquivo PDF original.

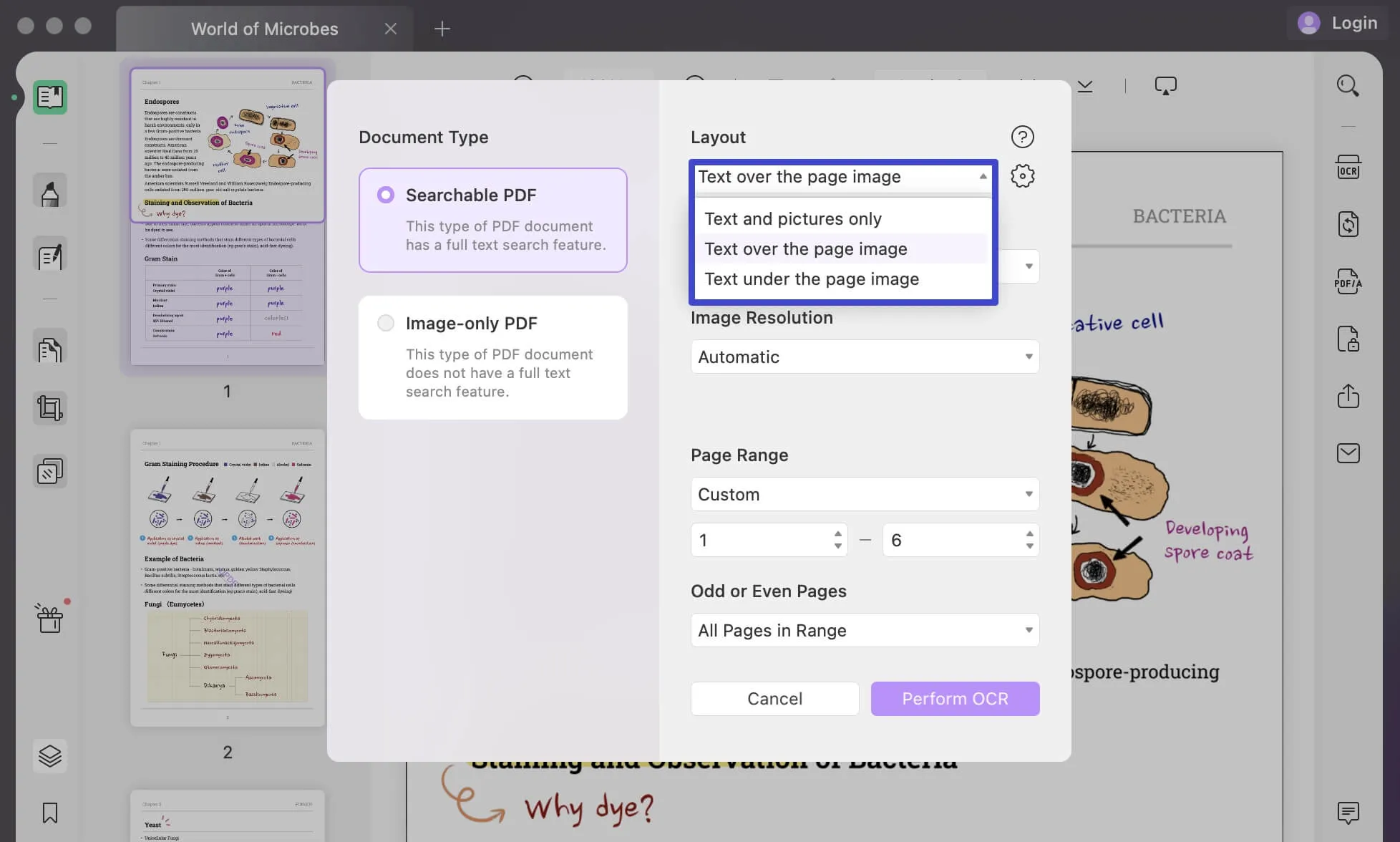
Clique no ícone "Equipamento" para acessar mais configurações de layout que você pode definir para o arquivo. Aqui você pode especificar se deseja "Manter Fotos" enquanto decide entre "Baixo", "Balanceado" ou "Alto" para salvar arquivos menores do que o original com imagem louvável e qualidade de imagem.

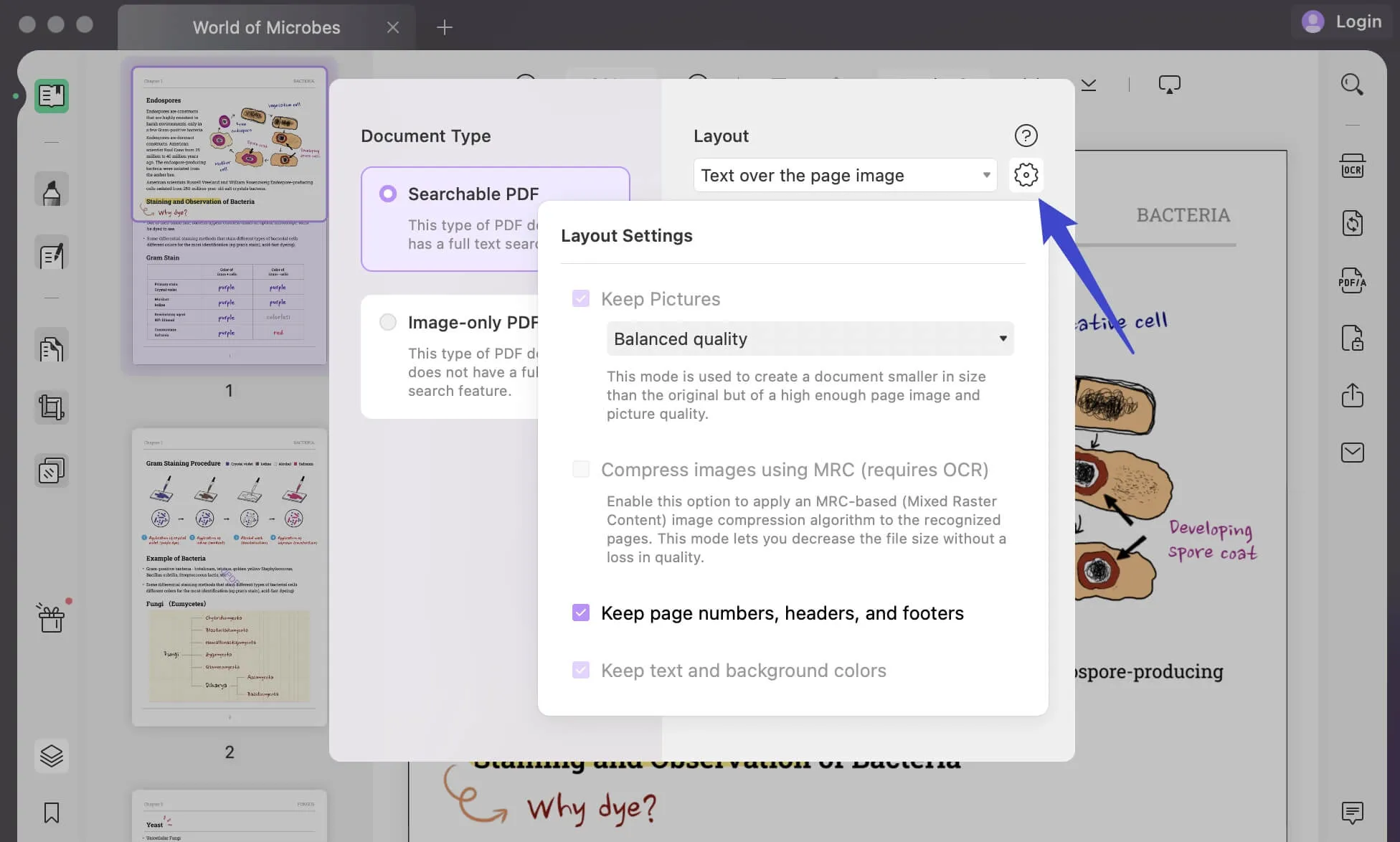
Linguagem do Documento, Resolução de Imagem e Gama de Páginas:
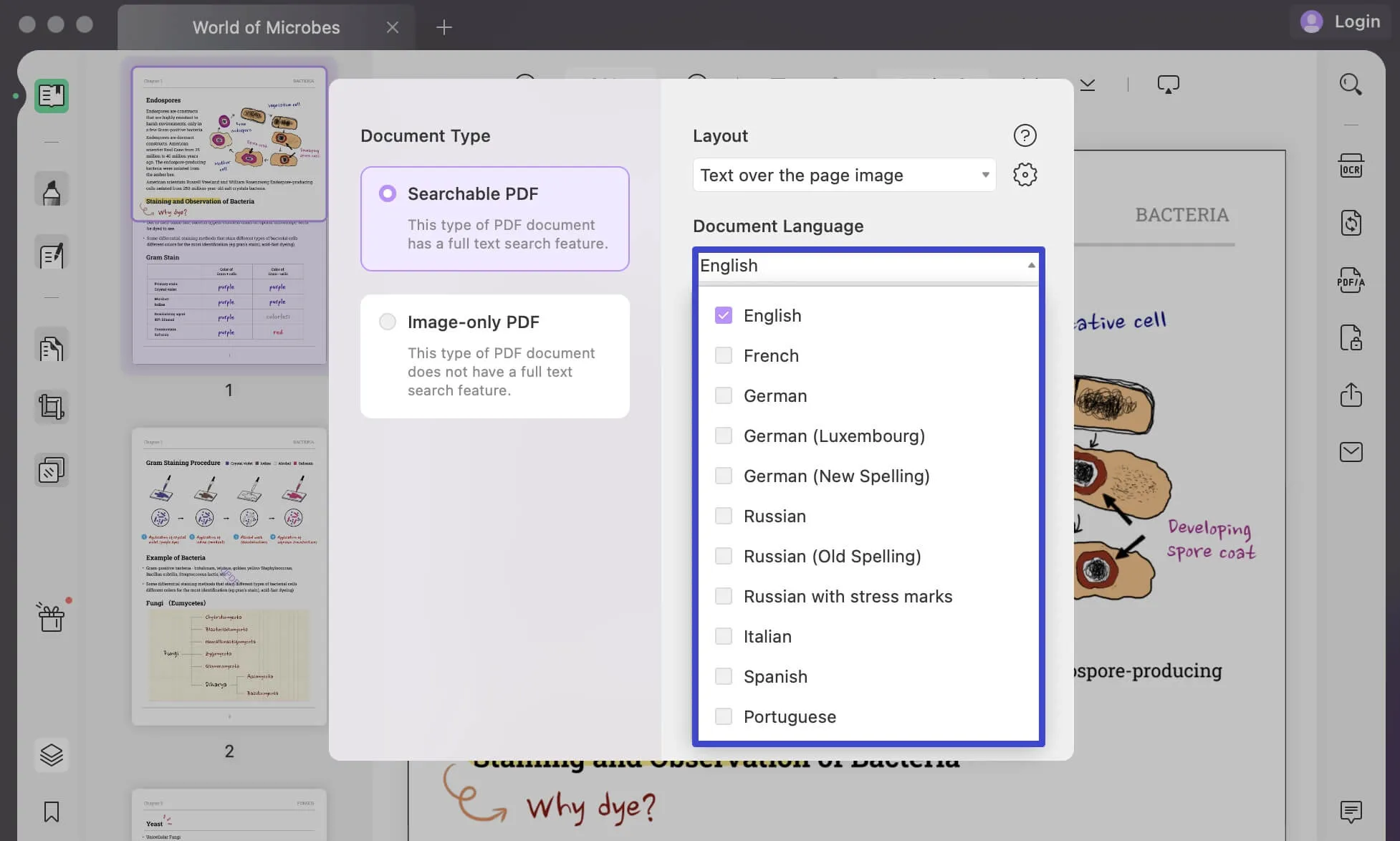
Defina o Idioma do Documento apropriado usando as 38 opções de idiomas diferentes no menu suspenso. Isto dá ao UPDF uma base melhor para identificar com precisão o texto nos documentos.

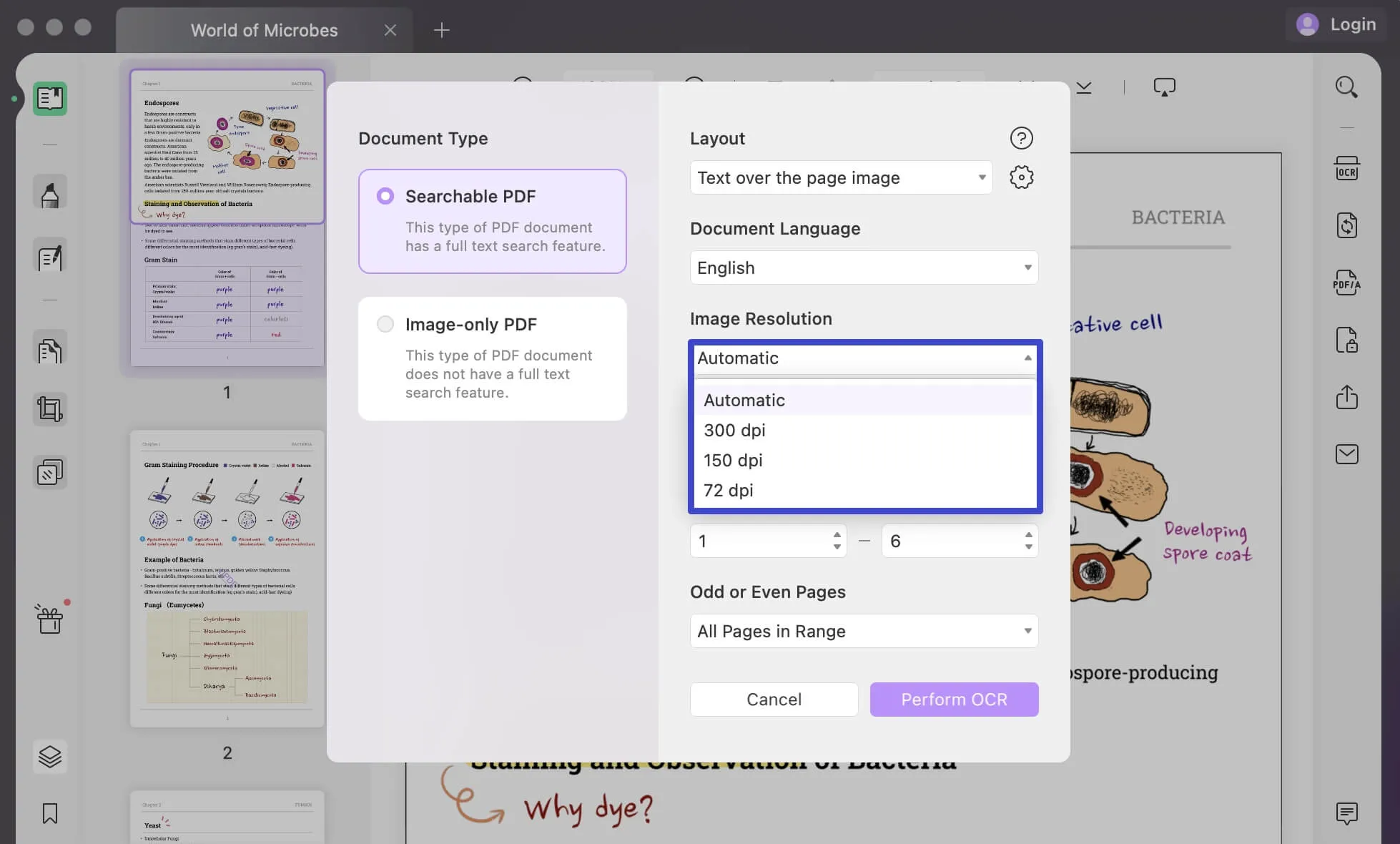
Você também pode usar a opção Resolução da imagem para especificar uma configuração de resolução apropriada para a imagem. Processe a "Faixa de páginas" e clique em "Executar OCR" para executar OCR no arquivo usando as configurações definidas.

Tipo de documento: Somente imagem em PDF
Se você continuar a usar "PDF somente imagem", ele converterá seus documentos pesquisáveis e editáveis em documentos PDF baseados em imagem que não são pesquisáveis nem editáveis.
Defina a qualidade da imagem na seção "Manter imagem", selecionando qualquer uma das opções disponíveis para "Baixa", "Balanceada" ou "Alta".

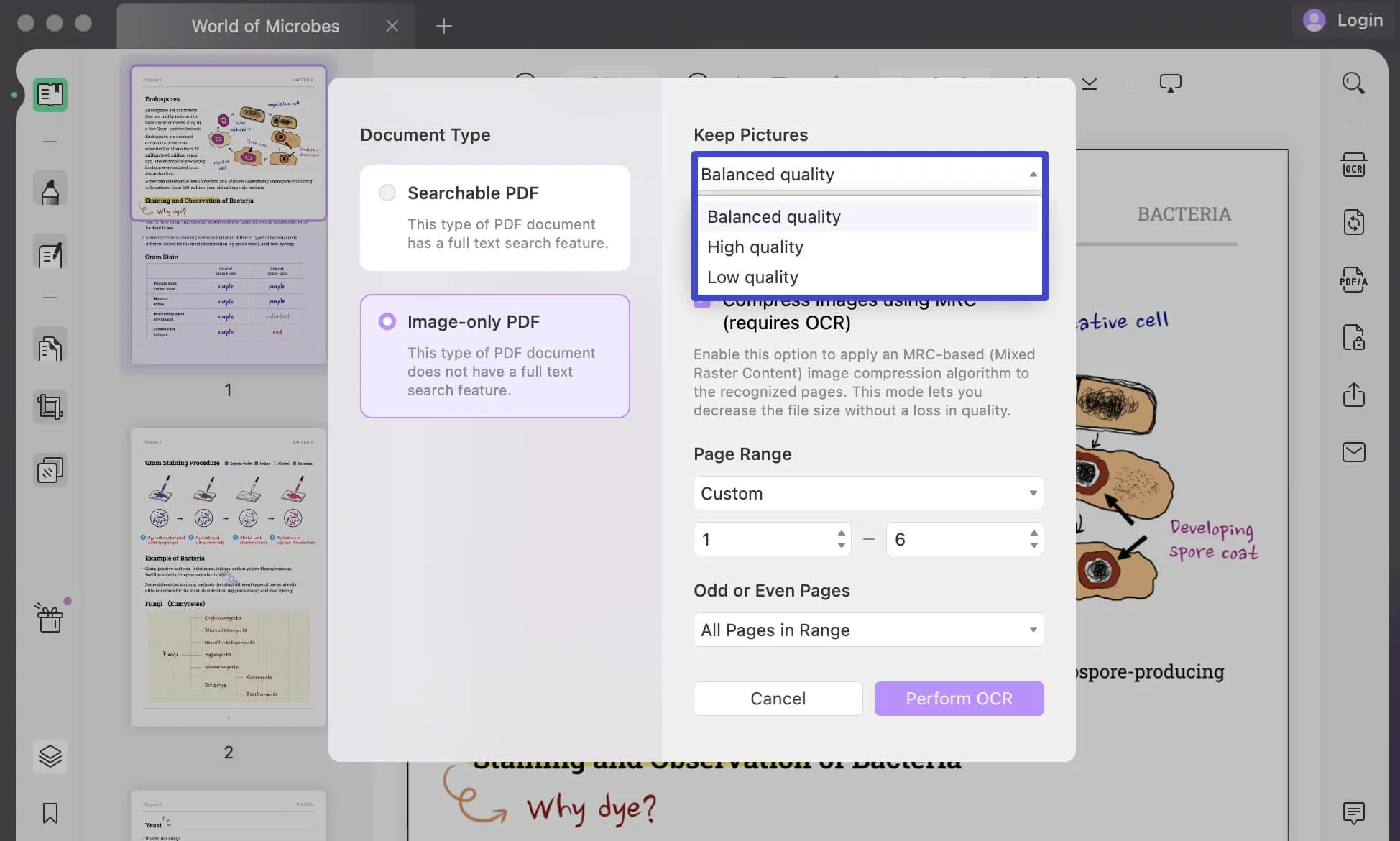
Decida se deseja comprimir suas imagens usando MRC.
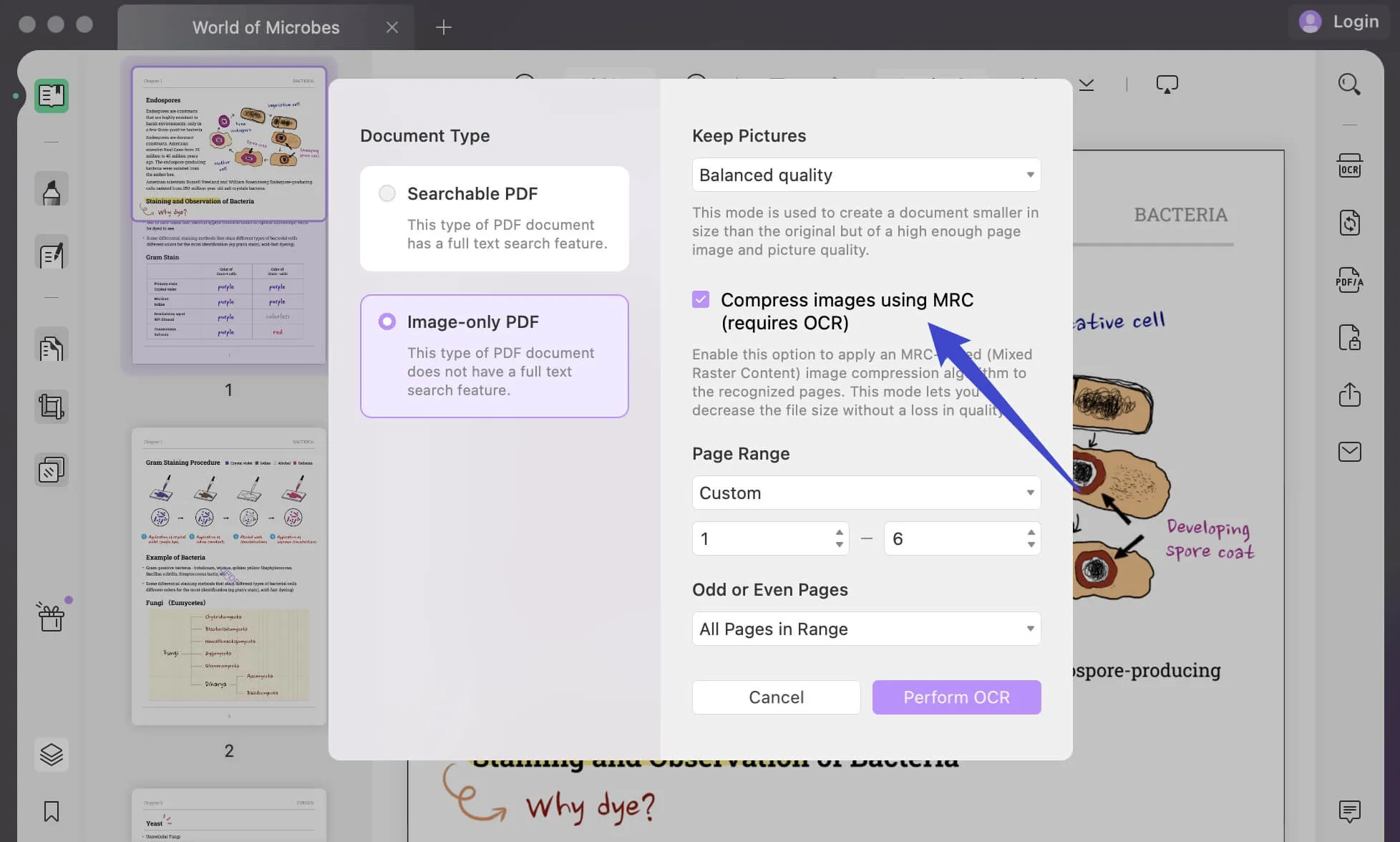
Forneça a "faixa de páginas" apropriada e clique em "Executar OCR" para executar a ação no documento. Selecione a pasta e você receberá o documento PDF digitalizado imediatamente.