





















































如何將掃描的 PDF 轉換為 Word格式,使其可在 Microsoft 軟體中編輯?轉換掃描或不可編輯的 PDF 檔案需要一個稱為 OCR 或光學字元辨識的特殊工具。使用 OCR 處理文件後,您可以繼續將 PDF 轉換為 Word 文件。有幾種不同的方法可以實現此目的,在本文中,我們將向您展示在 Windows 和 Mac 上將掃描的 PDF 轉換為 Word 的最有效、最便捷的方法。
如何使用 UPDF 將掃描的 PDF 轉換為可編輯的 Word?
UPDF的OCR工具支援超過 38 種語言,絕對是 Windows 和 Mac 的最通用、最強大的掃描 PDF 转 Word 轉換工具之一。
使用 OCR 轉換掃描文件需要很高的準確性,而 UPDF 的OCR 功能識別準確率很高,最終輸出將是與原始文件具有相同佈局和格式的 PDF 文件。此外,您可以選擇掃描的 PDF 中的特定頁面並將其轉換為 Word 文件。

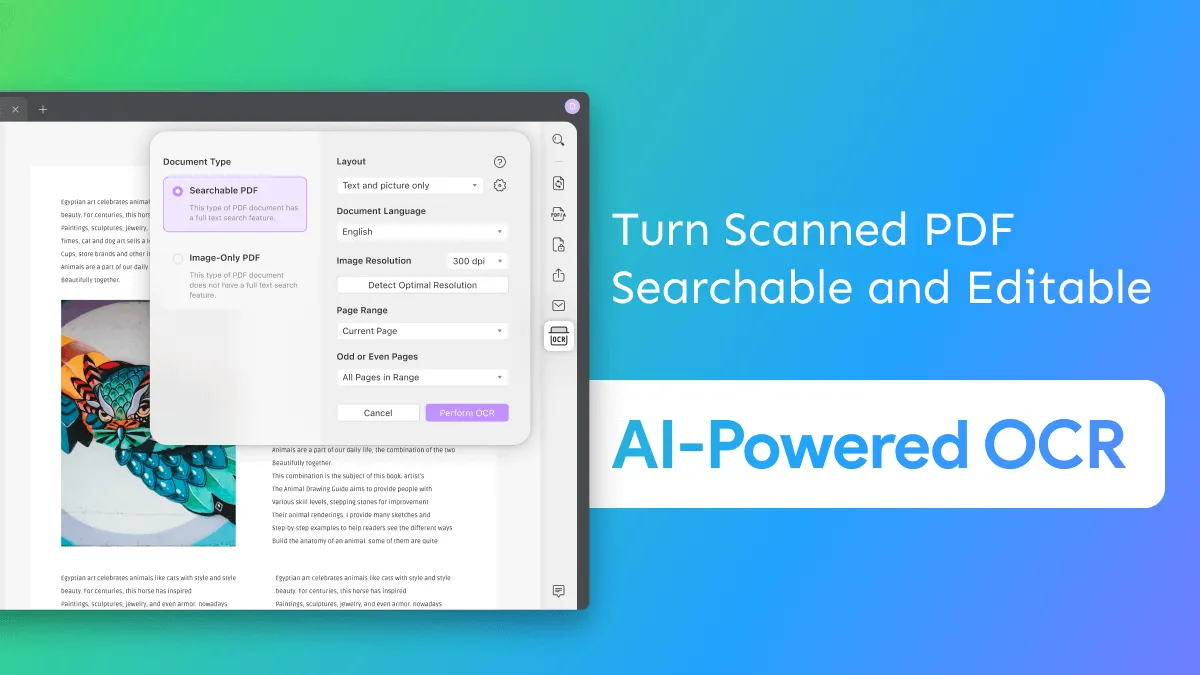
使用 UPDF 將掃描的 PDF 轉換為 Word 文件是一個快速且簡單的過程,只需幾個簡單的步驟。請按照以下說明操作:
第 1 步:設置 OCR 文檔類型
開啟 PDF 後,請前往右側面板上的「使用 OCR 識別文字」按鈕。從“文檔類型”部分中,選擇“可搜尋 PDF”並繼續流程。


第 2 步:設定佈局設定
從設定 OCR 工具的參數開始,您必須設定此程序的「佈局」設定。為此,將為您提供三種不同的佈局設置,解釋如下:
- 僅文字和圖片:此版面配置將所有文字和圖像保存在 PDF 文件中。建立的文件比原始文件小,並且沒有遵循特定的格式。
- 頁面圖像上的文字: 雖然是 OCR PDF 過程中設定的預設佈局,但此特定模式包含根據原始文件的圖像和插圖。雖然它們很大,但與原始 PDF 文件沒有太大區別。
- 頁面影像下的文字: 在此特定模式下保留原始 PDF 文件中的完整影像結構。文字存在於文件的圖像圖層下,因此不可編輯;但是,它是可以搜尋的。
完成後,進入“文檔語言”部分,您必須在其中選擇要檢測的特定語言。您可以從選單中的 38 種可用選項中選擇任何合適的語言。
繼續進入“影像解析度”部分,並使用選單中的可用值設定正確的值。如果不確定,您可以點擊“檢測最佳解析度”按鈕並繼續。
步驟 3:將掃描的 PDF 轉換為可編輯的文字
繼續指定要執行該功能的頁面範圍,然後按一下「執行 OCR」。為轉換後的文件設定正確的位置,以便將其轉換為可編輯的文字。之後,UPDF將自動為您開啟OCRed PDF。
如果您的目標是直接編輯轉換後的 PDF 中的文本,您現在可以使用 UPDF 的 PDF 編輯工具進行編輯,而無需將其轉換為 Word 文件。 UPDF 是一款多功能 PDF 工具,提供多種 PDF 相關功能,包括 PDF OCR、PDF 編輯、PDF 轉換等。

但是,如果您希望將其轉換為 Word 文件以用於其他目的,UPDF 仍然可以滿足您的要求。以下是將 PDF 轉換為 Word 的步驟:
- 在UPDF上開啟PDF文件,然後按一下右側工具列上的「匯出PDF」。
- 選擇“Word”格式,然後在彈出視窗中按一下“匯出”。
- 為檔案命名並將其保存在裝置上的資料夾中。


某些字體可能無法準確轉換,特別是當您的掃描文件上有手寫內容時,但內容會非常接近掃描副本,因為 UPDF 的OCR功能很強大。立即下載,並親自體驗這個功能!
Windows • macOS • iOS • Android 100% 安全性
有關如何將掃描的 PDF 轉換為 Word 的影片教學
為了進一步幫助您無縫地完成轉換過程,我們在下面準備了逐步教學影片。觀看影片以了解詳細的演練,提供每個步驟的介紹。
在先前的影片中掌握了掃描 PDF 的轉換之後,現在讓我們來了解一下 UPDF 中更強大的功能。觀看我們展示用於無縫 PDF 管理的高級工具:
- 強大的PDF轉換工具,支援許多常見的輸出格式,例如Word、Excel、PPT、影像格式、HTML、XML、文字和RTF。
- OCR 功能可將掃描的 PDF 轉換為可編輯的 Word 格式。
- 格式在轉換過程中保持一致 - 需要最少的手動修正。
- 多合一解決方案。它還允許您編輯PDF文件、評論PDF文件、保護PDF文件等。
- UPDF AI功能可協助您在幾秒鐘內總結、翻譯和解釋 PDF 文件!
準備好將您的體驗提升到新的水平了嗎?升級至 UPDF Pro即可獨享進階功能,徹底改變您的 PDF 工作流程。
將掃描的 PDF 檔案轉換為 Word 時有哪些常見問題?
一般來說,OCR引擎可以轉換大多數掃描的PDF檔案。然而,並非所有掃描文件都是一樣的。首先,如果您正在處理掃描的文件,請確保您已在程式中啟用 OCR 選項。
在開啟和轉換掃描檔案之前,請前往 OCR 設定並選擇使用 OCR 進行轉換。如果文件未轉換,原因可能是:文件中字元之間的間隙太近,OCR 無法偵測到每個字元。
掃描文件的影像品質不佳、掃描文件中使用的字體混合、斜體和下劃線字體,所有這些都會使單個字元的清晰度和形狀變得模糊,這些問題都會影響 OCR 結果。因此,確認 OCR 軟體「辨識」的字元與掃描紙張上的字元相對應更具挑戰性。
最重要的是,您應該知道,使用 UPDF OCR,您無需擔心任何這些問題,因為它將為您提供完美的結果和準確性。現在就試試看。
Windows • macOS • iOS • Android 100% 安全性
有關將掃描的 PDF 轉換為 Word 的常見問題解答
Q1.什麼是OCR(光學字元辨識)?
OCR(即光學字元辨識)是將文字影像轉換為機器可讀文字的過程。掃描的表格和收據通常保存為圖像文件,限制了它們在文字編輯器中的實用性。透過 OCR,這些圖像可以轉換為可編輯的文字文件。在業務工作流程中,處理表格、發票和合約等印刷材料可能非常耗時。將這些文件數位化通常會產生影像文件,OCR 技術將其轉換為可供各種業務應用程式使用的資料。這種簡化的流程有利於分析、營運效率和生產力的提升。
Q2.什麼是掃描版 PDF?
可以透過將紙本文件掃描成電子版本來建立 PDF 文件。這是透過選擇掃描器或類似機器來捕獲紙本文件的圖像並將其儲存為電子 PDF 文件來執行的。當掃描器製作此掃描影像時,它不會複製每個單字的每個字元。它只需要紙質文件的“快照”。然後,掃描器隨附的軟體會將照片轉換為 PDF 文件。結果,產生了「掃描的」PDF 文件。
無法搜尋或修改掃描的 PDF 內容。OCR 軟體需要以電子方式識別頁面上的每個字符,然後將其轉換為可用的格式以搜尋或編輯掃描的 PDF。本質上,它從圖像中識別並提取文字。
Q3.什麼是原生 PDF 檔?
原生 PDF 是「天生數位化」文件的 PDF,這意味著它是由文件的電子版本而不是列印版本製作的。另一方面,列印文件的掃描 PDF,就像您掃描列印日記中的頁面並將文件另存為 PDF 一樣。
Q4.掃描 PDF 和原生 PDF 有什麼不同?
掃描的 PDF 是文件的圖像,阻礙了文字搜尋功能。原生 PDF 源自 Word 文件等電子資源,可實現無縫文字搜尋。 ProQuest 的資料庫越來越多地包含原生數位內容,擴大了 PDF 格式的原生 PDF 的可用性。 ProQuest 資料庫中固有數位資訊的比例每年持續成長。
Q5.掃描的 PDF 有哪些類型?
掃描的 PDF 分為三類:
- 圖像 PDF - 最常見的 PDF 類型是圖像 PDF。當硬拷貝文件掃描成 PDF 文件時,情況就是如此。
- 具有可搜尋文字的可掃描 PDF - 此掃描 PDF 文件可能在圖像後麵包含隱藏文字。
- 具有混合內容的掃描 PDF - 此 PDF 可能包含掃描照片和電子產生的 PDF 元素。
結論
從上面將掃描PDF轉換為Word的介紹,我們可以知道UPDF是最好的掃描PDF到Word轉換器。它經濟實惠、準確、專用、多功能,可用於 Windows、Mac、iOS 和 Android 系統。此外,您還可以將 PDF 轉換為各種其他格式,以便可以在其本機應用程式中編輯文件。
Windows • macOS • iOS • Android 100% 安全性





















